如何在保证带宽的前提下从统计收集中解放NPU
时间:2006-07-20
作者:Jeremy Bicknell
分享
 扫码分享到好友
扫码分享到好友
产品经理
流量控制管理部门
IDT公司
How to free up NPU for statistics gathering in the era of guaranteed bandwidth
在不远的将来,随着统计运算处理和存储需求的爆炸性增长,网络设备设计师将面临计算危机。用依赖于外部存储缓冲器的传统架构来解决这个问题将最终导致性能瓶颈。在高性能的网络环境里,许多设计师将发现使用专用的、为统计功能而优化的现成的协处理器将为满足整体性能的需求提供一个简单而方便的设计选择。
随着统计运算处理和存储需求的爆炸性增长,网络设备设计师将面临计算危机。用依赖于外部存储缓冲器的传统架构来解决这个问题将最终导致性能瓶颈。在高性能的网络环境里,许多设计师将发现使用专用的、为统计功能而优化的现成的协处理器将为满足整体性能的需求提供一个简单而方便的设计选择。
过去几年里,业务提供商推出了广泛的差异化业务来创造新的收入来源,并满足网络应用日益增长的业务和用户需求。这些业务的级别从VoIP到VPN,常常需要业务提供商能满足比过去更为苛刻的性能要求。为了支持这些新的应用,业务提供商已经快速转变到使用服务水平协议(SLA)来定义各方之间的合同关系,规定提供的流量类别和发送给每个流量类别的数据总数,并保证网络的性能水平。
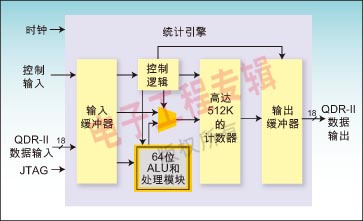
这种趋势对网络设备设计有相当大的影响。为了支持越来越多的业务分类和验证协议,业务提供商现在必须计算数据包,并扩展有关网络性能和使用方面不断增加的统计量。在IP网络中,通常是对TCP、UDP、ICMP、IPSec、IPv4、IPv6及所有联网电脑或苹果计算机的以太网接口的跟踪统计,只要在命令提示符中键入“netstat-s”就很容易显示出来。尽管用来执行该类统计收集的电脑系统资源可以被忽略,但是汇聚了大量用户的网络设备的开销就非常不同了(见表1)。
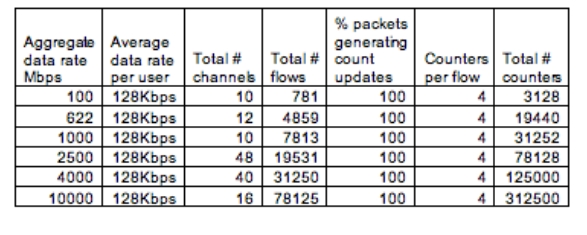
随着线速率从OC-48(2.5Gbps)增加到10Gbps的汇聚速率和OC-192,超量开通(oversubscription)技术和网络的使用在快速增加,而且任务的大小已经开始超出核心数据包处理器的能力范围。
除了满足流量和流量参数计算方面计数器数量的要求,还要考虑对总数据率和计数器更新率的流量类型的影响。使用相同的设定,计数器更新率可以计算(见表1)。
假设快速过渡到10Gbps数据率,伴随着从简单文件下载过渡到基于会话层的数据流,网络设备开发商就需要一种新的方法来执行统计运算。长期以来,统计功能的大小和范围限制了线卡核心数据包处理器处理数据包和维持网络传输率的能力。
网络设备设计师的挑战就是找到一种新的、更为有效的方法,来跟踪增量的数据,而不影响数据包驱动操作。通过从主要数据包处理器卸载这项主要任务,网络设备设计师可释放用来执行深层数据包分类的这些处理器周期,以支持更高级别的封包和更长关键字检索的下一代网络应用需求。
设计选择
传统来说,网络设备设计师都是选择用软件来完成统计运算。这个任务常常由通用CPU或NPU核心数据包处理器来管理,并由外部SRAM支持。
只要数据率保持相对慢一些,该方法就可很好地执行。但是,随着网络线速率的提高,传统的加载/储存架构的局限性也显著增加了。在这个拓扑结构中,核心数据包处理器必须从片外存储器找取数据,执行包括增量、减量或添加一个计数器等适当的算术运算,然后将数据回写到外部存储器。这个复杂的过程占用了数据包处理器周期,并使CPU和外部存储器之间的整个存储器总线带宽紧张。随着线速率的增加,统计运算的数量和存储器总线的使用可能超过上下文或数据处理器核心的负荷,导致处理器停止运行并降低线卡性能。
网络设备设计师试图通过从核心数据包处理器卸载所有或部分统计任务来解决这个问题。例如,一些设计师把统计功能转移到FPGA的专用逻辑中,或将该功能集成到ASIC中。但是,这两种解决方案都带来了许多不利影响。FPGA不能满足当今的线速率下高速统计运算所需的片上存储密度。而且,设计师还必须用一个外部SRAM支持FPGA,同时也面临与传统寻址和SRAM配置相关的读/改/写延迟的问题。专用ASIC虽然可以提供高性能,并增加大量片上存储能力,但是,由于ASIC平均NRE费用超过百万美元,对专门完成统计计算的ASIC进行设计、验证和确认的任务昂贵得令人难以接受。
网络设备设计师所面临的问题已经成为:如何以一种具有成本效益的方式解决这个问题?如何“解放”核心数据包处理器,不论是NPU、ASIC还是FPGA,使其专注于解决最初设计时打算解决的数据包分类功能的问题?
理想的情况是,该解决方案由现成的低成本协处理器组成,这种协处理器是特别为此功能而优化的,可消除上面提到的阻塞问题。作为一个解决方案,还要求具有高性能和行业标准的接口,以简化线卡的设计和支持不断增加的NPU阵列以及目前流行的专用数据包处理器。最后,任何解决方案都应具有高度的软件可配置性,以满足各种不同的应用需求。
会话边界控制器(SBC)
一种可说明统计引擎是如何帮助解决统计运算卸载的方法就是观察它在一个SBC里的实现方法。随着VoIP部署的不断增加,当数据穿过网络和网络段之间的边界时,通过信令层、呼叫控制层和数据包层里的实时会话,SBC在这些网络中扮演非常重要的角色。这些设备通常设置在可信任私有网络(像私营公司LAN)与非信任公共网络(像互联网)之间,或者两个业务提供商网络之间。这些设备可提供对发送到网络核心的VoIP信令信息的访问,并通过控制到网络的媒体数据包的存取,支持不同媒体流的差异化业务,例如计费和服务质量。用来保护网络边界的SBC在穿越网络之间的防火墙方面扮演了至关重要的角色,而且有助于实施对数据包化语音进行合法侦听这类的常规命令。
SBC开发者面对的主要挑战之一就是简单且有效地升级网络来缓解快速攀升的运营商之间VoIP流量的巨大压力。目前大部分的设备都设计支持1Gbps的线速率,但许多网络都在升级,以支持10Gbps的以太网线速率。随着线速率的提高,与计费、负载平衡、防火墙保护和其它业务需要的统计运算相关的处理开销将呈指数增长。
一个SBC设计以高达5Gbps的速率、3微秒的延迟来过滤数据包,可支持多达32,000个同时会话。安装在一个紧凑的1U板上的控制器可支持多种安全和地址保存特性,包括具有只为授权的媒体流而创建的防火墙针孔,以及经过双重网络地址和端口转换而隐藏在3层和5层下的网络拓扑结构的网络存取控制。
在SLA性能方面,控制器可支持建立在存取或转接链路上可用的实时带宽上的会话许可控制。信号媒体的2层和3层服务质量数据包标记可优化网络内的流量段和优先权,并可防止服务质量的盗取。SBC也为SLA报告、问题警告、隔离及会话许可控制提供每个会话的服务质量统计。
随着线速率的增加,统计运算将从核心SBC数据包处理器中“窃取”更多的处理周期百分比。设计师可以解决这个问题,并通过把统计运算卸载到一个统计引擎协处理器的方式来延长目前设计的生命周期。
统计引擎接口是经过一个行业标准网络处理器论坛(NPF)LA-1接口(兼容QDR-II)接入到核心数据包处理器的。这个基于标准的总线缩短了开发时间,并通过与各种NPU、FPGA和ASIC的无缝连接简化了线卡设计。目前LA-1标准的规定速率为167MHz,但是接口统计引擎可支持超过200MHz的时钟速率。
与支持标准QDR-II接口的其它芯片一样,统计引擎也使用独立的端口进行读写数据存取。总线是单向的,而且是以高总线速度为信号完整性而优化的,并可利用具有多读写地址的单DDR地址总线。读取地址可在时钟周期的前半期接收,写入地址则在时钟周期的后半期接收。当字节写入信号与其在数据输入总线上所控制的数据在时钟周期的两个半期同时接收时,读写使能在时钟周期的前半期进行接收。
回声时钟输出可作为数据的下行时钟输出。HSTL外部接口可支持高于SRAM使用的传统TTL接口的速度。统计处理器可同时保持输入和输出端口的全带宽。所有的数据都是具有突发级寻址能力的两字脉冲格式。
不同的是,地址线不是用来支持平面地址映射的,而是用作统计引擎的控制输入,把算术运算代码(OPCODES)和指针转移到位于统计引擎的计数器中。
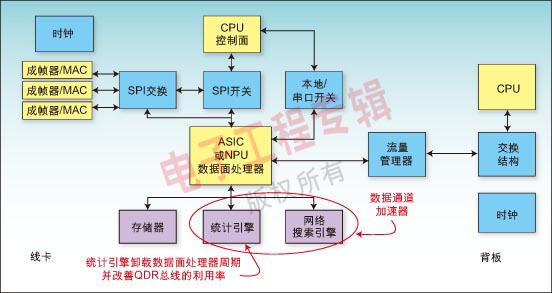
作为从头设计电路板的一种替代方法,线卡使用的硬件可以是现有的设计或基于模块的、现成的板卡,如ATCA板卡(见图2)。
统计引擎快速执行统计运算的大部分能力可归因于其“即发即弃”(Fire and Forget)模式。该功能允许设备以一个命令在多达4个计数器上执行自动的读-改-写操作,并以QDR-II速度维持更新。该性能增强的关键在于它能同时传输32位的数据和地址,以及在ALU的36位总线上传输4行操作代码的能力。
操作代码可以包括一个增量、添加一个补偿或指令集中的任何一个指令。例如,对典型的计费应用来说,一组4位OPCODES可能包括:
1. Set Register(设置寄存器);
2. INC/SUM(操作数:+1/32位输入);
3. SUM/SUM(操作数:16位输入/16位输入);
4. SUM/SUM缺省(操作数:32位输入/32位缺省);
5. DEC/SUB(操作数:-1/32位输入);
6. SUB/SUB缺省(操作数:32位输入/32位缺省);
7. NOP/SUB(操作数:0/32位输入);
8. SUB/NOP(操作数:32位输入/0)。
当设备接收一个伴随有统计使能(STEN)位启动和适当的统计OPCODE以及数据的写入命令时,统计运算开始执行。对于一个通用数据包处理器/SRAM配置,必须先从SRAM读取数据,完成一次运算后,再用一个传统的读-改-写周期将数据回写到SRAM中,这就需要4次QDR-II操作。而“即发即弃”功能则允许处理器向统计引擎发送一个命令,仅在一个周期里就能对全部4个计数器完成更新。
通过把这些所有的操作压缩为一个命令,“即发即弃”模式可释放QDR-II带宽并显著改善SBC的性能。图3显示了前面所讨论的计数器更新例子在经过统计引擎卸载后所用的处理器周期(表示为线速率的函数)。
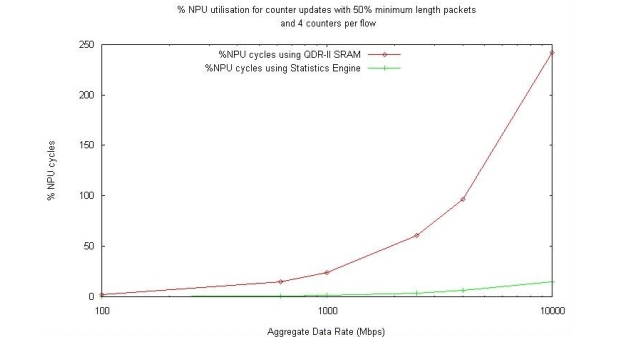
在这个简单的例子中,接收到的50%的数据包是64字节长度的最小以太网数据包,50%的数据包长度为1,518字节。NPU使用的计数器可同时跟踪所有接收到的数据包和字节。在这个例子中,接收到的字节最初由NPU分成256字节一组,并由计数器更新运算SUM把这个值加到一个字节计数器的当前存储值上。当NPU接收到一个完整的数据包时,就可以递增相关数据包计数器的数值。
这种用于统计引擎中的技术可使QDR-II带宽提高87%,使线卡数据包处理器周期缩短90%。在SBC应用中,专用统计引擎的增加可使数据通道处理器比其它架构的统计收集更为有效。效率的提高使得可用处理能力可被重新配置,从而提供额外的网络特性(如更高的总吞吐量或更多的会话)。这些额外的收益,可有效地为更多用户提供更丰富的业务,从而增加业务提供商的收入。















