AI大模型迈向多模态,助力具身智能与机器人实现创新
时间:2024-10-25 14:02:26
作者:Arm物联网事业部业务拓展副总裁马健
分享
 扫码分享到好友
扫码分享到好友
你听过莫拉维克悖论 (Moravec's paradox) 吗?该悖论指出,对于人工智能 (AI) 系统而言,高级推理只需非常少的计算能力,而实现人类习以为常的感知运动技能却需要耗费巨大的计算资源。实质上,与人类本能可以完成的基本感官任务相比,复杂的逻辑任务对 AI 而言更加容易。这一悖论凸显了现阶段的 AI 与人类认知能力之间的差异。
人本来就是多模态的。我们每个人就像一个智能终端,通常需要去学校上课接受学识熏陶(训练),但训练与学习的目的和结果是我们有能力自主工作和生活,而不需要总是依赖外部的指令和控制。
我们通过视觉、语言、声音、触觉、味觉和嗅觉等多种感官模式来了解周围的世界,进而审时度势,进行分析、推理、决断并采取行动。
经过多年的传感器融合和 AI 演进,机器人现阶段基本上都配备有多模态传感器。随着我们为机器人等边缘设备带来更多的计算能力,这些设备正变得愈加智能,它们能够感知周围环境,理解并以自然语言进行沟通,通过数字传感界面获得触觉,以及通过加速计、陀螺仪与磁力计等的组合,来感知机器人的比力、角速度,甚至机器人周围的磁场。
在 Transformer 和大语言模型 (LLM) 出现之前,要在 AI 中实现多模态,通常需要用到多个负责不同类型数据(文本、图像、音频)的单独模型,并通过复杂的过程对不同模态进行集成。
而在 Transformer 模型和 LLM 出现后,多模态变得更加集成化,使得单个模型可以同时处理和理解多种数据类型,从而产生对环境综合感知能力更强大的 AI 系统。这一转变大大提高了多模态 AI 应用的效率和有效性。
虽然 GPT-3 等 LLM 主要以文本为基础,但业界已朝着多模态取得了快速进展。从 OpenAI 的 CLIP 和 DALL·E,到现在的 Sora 和 GPT-4o,都是向多模态和更自然的人机交互迈进的模型范例。例如,CLIP 可理解与自然语言配对的图像,从而在视觉和文本信息之间架起桥梁;DALL·E 旨在根据文本描述生成图像。我们看到 Google Gemini 模型也经历了类似的演进。
2024 年,多模态演进加速发展。今年二月,OpenAI 发布了 Sora,它可以根据文本描述生成逼真或富有想象力的视频。仔细想想,这可以为构建通用世界模拟器提供一条颇有前景的道路,或成为训练机器人的重要工具。三个月后,GPT-4o 显著提高了人机交互的性能,并且能够在音频、视觉和文本之间实时推理。综合利用文本、视觉和音频信息来端到端地训练一个新模型,消除从输入模态到文本,再从文本到输出模态的两次模态转换,进而大幅提升性能。
在今年二月的同一周,谷歌发布了 Gemini 1.5,将上下文长度大幅扩展至 100 万个词元 (Token)。这意味着 1.5 Pro 可以一次性处理大量信息,包括一小时的视频、11 小时的音频、包含超过三万多行代码或 70 万个单词的代码库。Gemini 1.5 基于谷歌对 Transformer 和混合专家架构 (MoE) 的领先研究而构建,并对可在边缘侧部署的 2B 和 7B 模型进行了开源。在五月举行的 Google I/O 大会上,除了将上下文长度增加一倍,并发布一系列生成式 AI 工具和应用,谷歌还探讨了 Project Astra 的未来愿景,这是一款通用的 AI 助手,可以处理多模态信息,理解用户所处的上下文,并在对话中非常自然地与人交互。
作为开源 LLM Llama 背后的公司,Meta 也加入了通用人工智能 (AGI) 的赛道。
这种真正的多模态性大大提高了机器智能水平,将为许多行业带来新的范式。
例如,机器人的用途曾经非常单一,它们具备一些传感器和运动能力,但一般来说,它们没有“大脑”来学习新事物,无法适应非结构化和陌生环境。
多模态 LLM 有望改变机器人的分析、推理和学习能力,使机器人从专用转向通用。PC、服务器和智能手机都是通用计算平台中的佼佼者,它们可以运行许多不同种类的软件应用来实现丰富多彩的功能。通用化将有助于扩大规模,产生规模化的经济效应,价格也能随着规模扩大而大幅降低,进而被更多领域采用,从而形成一个良性循环。
Elon Musk 很早就注意到了通用技术的优势,特斯拉的机器人从 2022 年的 Bumblebee 发展到 2023 年三月宣布的 Optimus Gen 1 和 2023 年年底的 Gen 2,其通用型和学习能力不断提高。在过去的 6 至 12 个月里,我们见证了机器人和人形机器人领域所取得的一系列突破。
毋庸置疑的是我们在具身智能达到量产方面还有很多工作要做。我们需要更轻便的设计、更长的运行时间,以及速度更快、功能更强大的边缘计算平台来处理和融合传感器数据信息,从而做出及时决策和控制行动。
而且我们正朝着创造人形机器人的方向发展,人类文明数千年,产生出无处不在的专为人类设计的环境,而人形机器人系统由于形体与人们类似,有望能够在人类生存的环境中驾轻就熟地与人类和环境互动并执行所需的操作。这些系统将非常适合处理脏污、危险和枯燥的工作,例如患者护理和康复、酒店业的服务工作、教育领域的教具或学伴,以及进行灾难响应和有害物质处理等危险任务。此类应用利用人形机器人类人的属性来促进人机自然交互,在以人为中心的空间中行动,并执行传统机器人通常难以完成的任务。
许多 AI 和机器人企业围绕如何训练机器人在非结构化的新环境中更好地进行推理和规划,展开了新的研究与协作。作为机器人的新“大脑”,预先经过大量数据训练的模型具有出色的泛化能力,使得机器人能做到见怪不怪,更全面地理解环境,根据感官反馈调整动作和行动,在各种动态环境中优化性能。
举一个有趣的例子,Boston Dynamics 的机器狗 Spot 可以在博物馆里当导游。Spot 能够与参观者互动,向他们介绍各种展品,并回答他们的问题。这可能有点难以置信,但在该用例中,比起确保事实正确,Spot 的娱乐性、互动性和细腻微妙的表演更加重要。
Robotics Transformer (RT) 正在快速发展,它可以将多模态输入直接转化为行动编码。在执行曾经见过的任务时,谷歌 DeepMind 的 RT-2 较上一代的 RT-1 表现一样出色,成功率接近 100%。但是,使用 PaLM-E(面向机器人的具身多模态语言模型)和 PaLI-X(大规模多语言视觉和语言模型,并非专为机器人设计)训练后,RT-2 具有更出色的泛化能力,在未曾见过的任务中的表现优于 RT-1。
微软推出了大语言和视觉助手 LLaVA。LLaVA 最初是为基于文本的任务设计的,它利用 GPT-4 的强大功能创建了多模态指令遵循数据的新范式,将文本和视觉组件无缝集成,这对机器人任务非常有用。LLaVA 一经推出,就创下了多模态聊天和科学问答任务的新纪录,已超出人类平均能力。
正如此前提到的,特斯拉进军人形机器人和 AI 通用机器人领域的意义重大,不仅因为它是为实现规模化和量产而设计的,而且因为特斯拉为汽车设计的 Autopilot 的强大完全自动驾驶 (FSD) 技术基础可用于机器人。特斯拉也拥有智能制造用例,可以将 Optimus 应用于其新能源汽车的生产过程。
Arm 认为机器人脑,包括“大脑”和“小脑”,应该是异构 AI 计算系统,以提供出色的性能、实时响应和高能效。
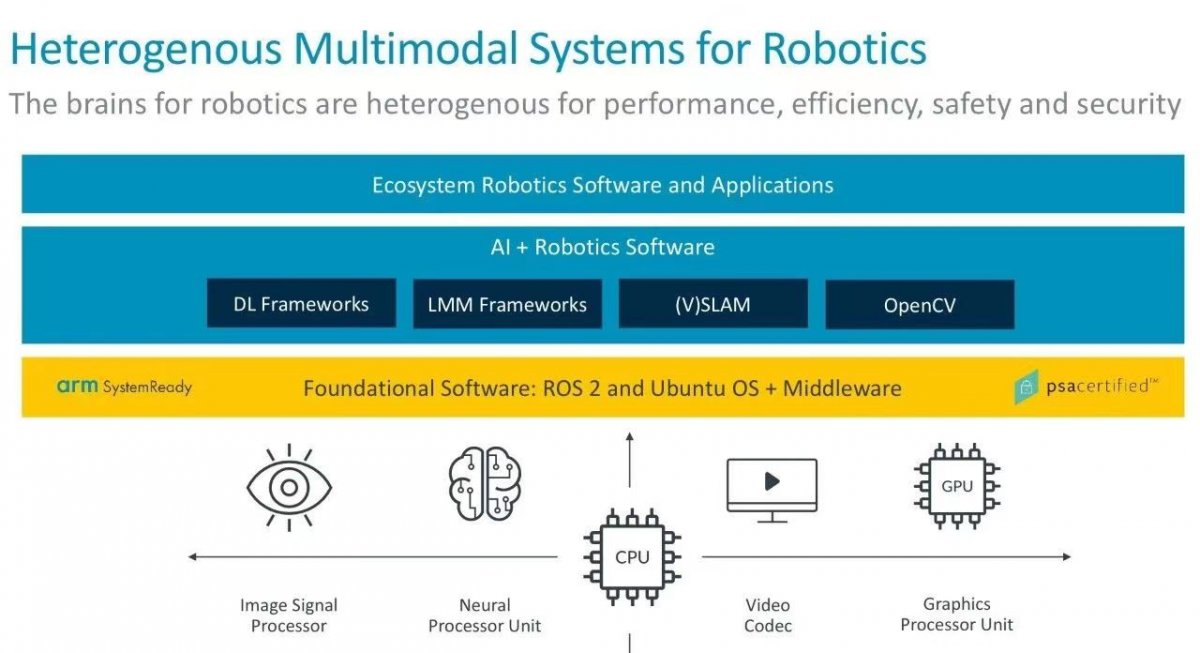
机器人技术涉及的任务范围广泛,包括基本的计算(比如向电机发送和接收信号)、先进的数据处理(比如图像和传感器数据解读),以及运行前文提到的多模态 LLM。CPU 非常适合执行通用任务,而 AI 加速器和 GPU 可以更高效地处理并行处理任务,如机器学习 (ML) 和图形处理。还可以集成图像信号处理器和视频编解码器等额外加速器,从而增强机器人的视觉能力和存储/传输效率。此外,CPU 还应该具备实时响应能力,并且需要能够运行 Linux 和 ROS 软件包等操作系统。
当扩展到机器人软件堆栈时,操作系统层可能还需要一个能够可靠处理时间关键型任务的实时操作系统 (RTOS),以及针对机器人定制的 Linux 发行版,如 ROS,它可以提供专为异构计算集群设计的服务。我们相信,SystemReady 和 PSA Certified 等由 Arm 发起的标准和认证计划将帮助扩大机器人软件的开发规模。SystemReady 旨在确保标准的 Rich OS 发行版能够在各类基于 Arm 架构的系统级芯片 (SoC) 上运行,而 PSA Certified 有助于简化安全实现方案,以满足区域安全和监管法规对互联设备的要求。
大型多模态模型和生成式 AI 的进步预示着 AI 机器人和人形机器人的发展进入了新纪元。在这个新时代,要使机器人技术成为主流,除了 AI 计算和生态系统,能效、安全性和功能安全必不可少。Arm 处理器已广泛应用于机器人领域,我们期待与生态系统密切合作,使 Arm 成为未来 AI 机器人的基石。

