
2019冠状病毒疾病肆虐全球,但是也加速了全球数字化转型,并且也改变了存储类半导体的发展模式。随着人工智能、物联网和大数据等相关技术的发展,远程办公、视频会议和在线课程等实时应用大量涌现,需要处理的数据量也随之激增。根据 IDC 2017年发布的数据,预计到2025年,全球产生的数据量将达到163 zettabyte(1 zettabyte= 2^70个字节),并且其中5.2 zettabytes 将需要进行数据分析。
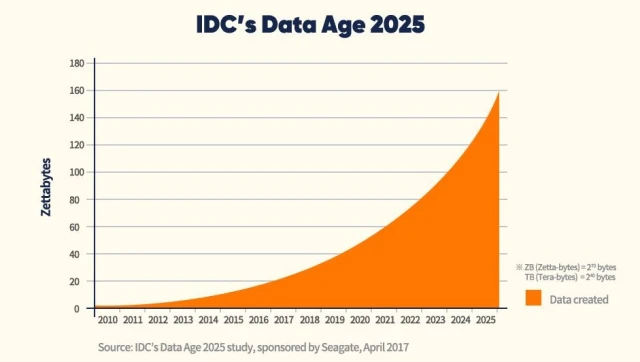
图1.2025年 IDC预测的数据量
目前的计算机系统采用冯·诺伊曼结构,当 CPU 处理来自 DRAM 芯片外的数据时,频繁使用的数据被存储缓存中(L1级、L2级和L3级),这样不仅速度快和功耗低,还能够获得最大性能。然而在需要处理大量数据的应用程序中,绝大部分数据是从内存中读取的,因为与缓存的容量相比起来,要处理的数据则大的多。
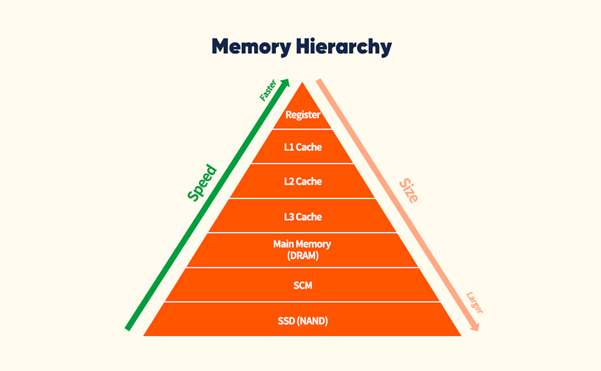
图2. 计算机中内存架构
在这种情况下,CPU 和内存之间数据通道的带宽成为限制性能发挥的瓶颈 ,在 CPU 和内存之间传输数据也消耗了巨大能量。为了突破这一瓶颈,CPU 和内存之间的通道带宽需要扩展,但是如果当前 CPU 的管脚数量已经达到极限,进一步的带宽改进将面临技术上难以逾越的困难。在现代计算机结构中,数据存储和数据计算是分开的,这样的“数据墙”问题是不可避免的。我们不妨假设处理器用于乘法运算的功耗约为1个单位,而从 DRAM 中获取数据到处理器需要消耗的能量是数据的实际计算的650倍,也就是说减少数据移动对于性能和功耗的提升是巨大的。
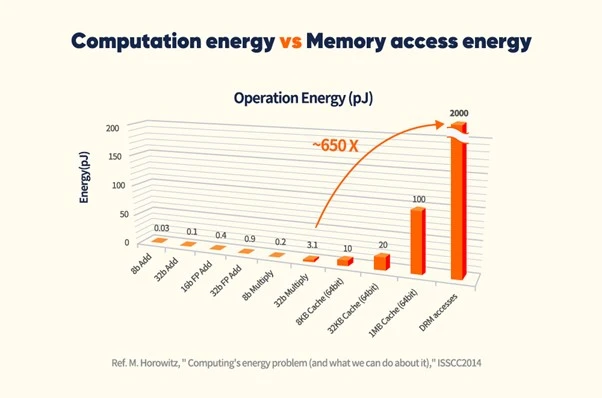
图3. 数据计算与数据内存传递功耗对比图
深层神经网络(DNN)是一种机器学习(ML) ,其中以用于计算机视觉(CV)的卷积神经网络(CNN)和用于自然语言处理(NLP)的递归神经网络(RNN)为大家所熟知,并且最近大热的推荐模型(RM)等新的应用程序也趋向于使用 DNN。对于RNN而言,其主要运算是矩阵向量乘法运算,由于其具有低数据重用特性,内存访问次数越多,通过内存通道的数据移动就越多,而性能瓶颈就约明显。
所以为了改进这一点,有很多人提出应用PIM技术重新构建DRAM内存,PIM正如其定义的那样,其操作和计算是在内存中执行的,也就是说,PIM的预期效果是通过在内存中执行操作而不将数据移动到 CPU,从而最小化数据移动,用来提升性能。从20世纪90年代末到21世纪初,学术界积极研究这一概念,但由于 DRAM 处理和逻辑计算的技术难度大,以及使用 DRAM 处理实现内存中 CPU 的成本太高,导致PIM 的竞争力大大削弱,并且也没有商业化。但是现今对于性能的需求使得这一概念的商业化提上了日程。
如果想要理解 PIM,首先我们是要知道 AI究竟进行了什么样的操作,下图给我们展示了神经网络中的完全连接(FC)层,单输出神经元Y1节点链接到X1,X2,X3和X4节点上,每个节点突触上的权重分别为w11,w12,w13和w14。AI为了处理这个全连接层需要将每个计算节点和权重相乘然后再进行求和,然后再应用一个激活函数,如RELU等。更复杂的情况是有几个输入(X1...Xn)和输出(Y1...Yn)的情况下,AI将每个单元分别乘以其对应输出的权重然后再分别求和,而这也就是数学上的矩阵乘法和加法运算。
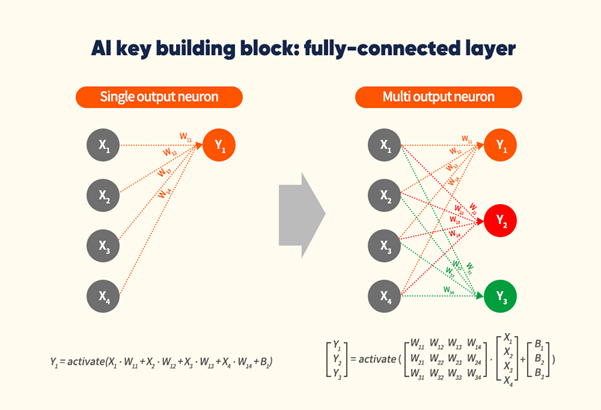
图4. AI的完全连接的层样例
同样的在图5中,如果我们把这些运算用的电路全部设计到存储单元中,则完全不需要将数据搬运和传输,只需要在存储单元中完成计算并且把结果告知CPU即可;这样不仅能够显著减少功耗,还能尽可能的处理更加复杂的操作。目前SK Hynix公司正在大力开发采用这一技术的PIM DRAM,对于RNN 等内存瓶颈的应用来说,如果在 DRAM 中使用计算电路执行应用程序,预计性能和功耗将有显著提高。而未来CPU需要处理的数据还在不断增多,PIM有望成为计算机提升性能最强有力的方案。
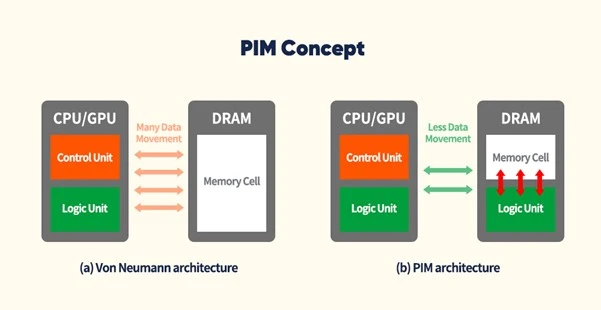
图5. SK hynix的PIM 概念
责编:我的果果超可爱
编译自:The prospect of Processing In Memory (PIM) in memory systems for AI applications ----EEtimes
