
内存计算(存算一体化)会议热门
在现代AI技术中,随着数据量越来越大和计算量越来越多,原始的冯洛伊曼结构已经快撑不住了;而过去一味的堆砌内存和扩展CPU已经不能满足高效AI计算了。所以有着很多的计算机专家在研究新的架构和计算方式,会议上有一项来自于惠普实验室的研究十分有趣:惠普实验室首席研究专家Catherine Graves描述了CAMs(模拟数字信号可寻址存储器)在信息安全、基因组和决策树中的广泛应用。(CAM其实就是随机存储器的反例,你可以指定你的内存地址,然后把地址发到RAM中,就可以读出存储在该地址的数据,如果你对于数据进行搜索,那么搜索的内容和存储的内容一旦匹配,CAM就能输出匹配的对应地址)。而这种内容寻址器是为了提升数据的吞吐量而设计的。
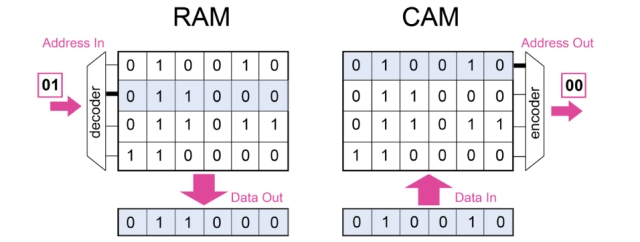
模拟和数字 CAMs 可以应用于安全、基因组学和决策树,并绘制各种计算模型。(来源: 惠普实验室)
他们采用25nm制程制作了记忆电阻器并直接在集成CMOS上,可以用来演示完整的数据读取、编程和计算等复杂操作。不仅功耗低,程序控制算法优良,而且该团队成功部署了一个MNIST分类准确率高达95.3%的多层卷积神经网络,并且还展示了模拟-数字信号混合计算体系的探究,给业界带来全新的计算机体系架构的概念。
IBM也有类似研究
IBM研究院内存计算小组的研究人员也称,多维计算也是受大脑启发的,它使用内存来克服当前深度学习计算的一些挑战;虽然目前半导体发展已经实现了多维计算,但是仍旧没有人脑高效,并且能耗也是一大挑战。之前仅是用于跑一次训练模型所消耗的能量,就相当于普通家庭半个月的电量。不光光是能耗,另一个巨大挑战是设备的复杂度,如今的AI和神经网络模型基本部署在大型服务器上,在可靠性、网络安全和控制方面都有着各种各样的要求,这些要求都让系统的复杂度陡升。所以,未来的AI一定是超越现有的冯诺依曼体系的,应该是有“内存计算”(存算一体化)来进行多维计算。
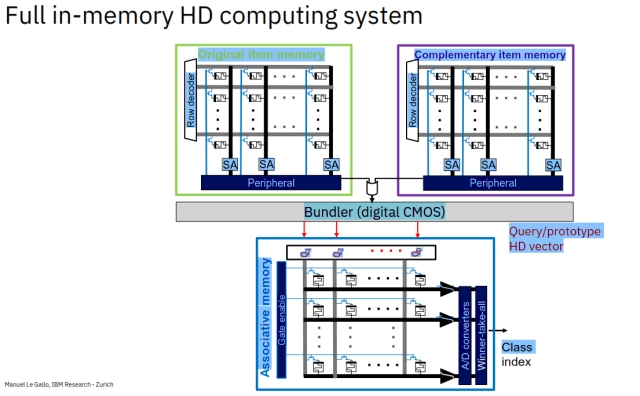
多维计算以内存为中心,这使得它非常适合使用存算一体硬件来实现(来源: IBM Research)
多维度计算的整体思想就是利用超维度向量来展示数据,超维向量不是按照一定序列表示的32bit或者64bit的数据流,而是在1维到10000维之间的随机bit流。矢量运算速度非常快,通常以内存为中心来构建一个通用的可扩展的计算模型,所以非常适合内存计算硬件来实现。高维向量计算结合了内存存储的编码结构,数据流在相变内存设备上编码(用高阻低阻状态来表示0或者1)。并且IBM的一个小组使用PCM实现了一套完整的系统并且产生了精确的数据,而且实现了内存超维计算的能源效率是传统CMOS的6倍。
但是IBM也对外称,整套系统还有很大的改进空间,但是无论如何,设计一个内存超维计算系统是可能的,可以使用比较老的芯片制程设计并制造一套PCM系统,来实现高能效和速度快的软件系统。
各家大厂摩拳擦掌,内存计算或将成为主流
不仅如此,在去年的IMW 2020大会上,来自Renesas电子的R&D团队给业界分享了基于闪存的内存处理器(flash-PIM),该结构不仅可以在节点进行计算推理,还能自我学习。这种新型结构不仅共享了存储单元的闪存阵列,还使得总面积减少了25%
Processing In-Memory Architecture with On-Chip Transfer Learning Function for Compensating Characteristic Variation(图源:IEEE)
随着摩尔定律不断延伸,计算机处理数据的能力在短短十年内已经翻了数倍,但是存储和数据库的发展却有些跟不上脚步了,tb级别的数据可能需要数小时乃至几天来完成。而内存计算(process in-memory)能够在低成本下部署和维护,目前也已经有部分大数据厂商选择内存技术来替代传统的BI,也许下一个新型计算机的架构就是内存计算,大规模商业化也是指日可待。
责编:我的果果超可爱
编译自:
IMW Highlights 3D Architectures, In-Memory Computing
参考:
AI Needs Memory to Get Cozier with Compute
Processing In-Memory Architecture with On-Chip Transfer Learning Function for Compensating Characteristic Variation
CMOS-integrated nanoscale memristive crossbars for CNN and optimization acceleration
