
前一阵Intel Arc B580显卡发布时,我们就评价说这才有了甜品卡该有的样子——主要是相较上一代Arc A750(代号Alchemist)而言的。整理Intel官方推出的这两张公版卡的规格,如下表:
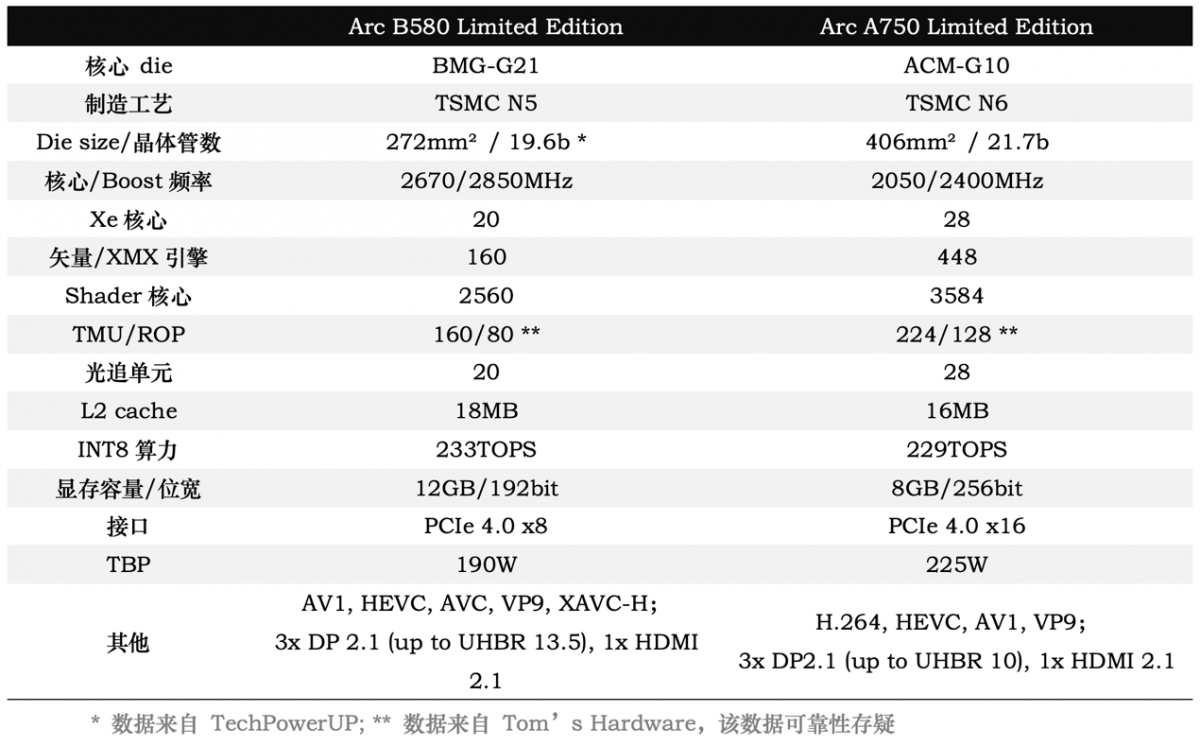


虽然其中很多数字并不能直接代表GPU的确切堆料,比如两代Xe核心的架构就不一样,所以即便在Xe核心数方面B580只有20个,A750有28个,实际还是更进一步观察内部才行;但从这张规格表就能明确发现Arc A750的旗舰定位,供电、接口、显存位宽、晶体管数量、TBP功耗、标称算力等各方面,B580还是不及老大哥A750的。
乃至从晶体管数量的角度来看,Arc A750所用这片ACM-G10 die堆了217亿个晶体管,可是比同期的GeForce RTX 3070(GA104)还要阔气的。但从实际游戏角度来看,Arc A750也就是略好于RTX 3060:这堆料实在是对不起用户层面的体验。而且当时我们也非常惊讶Intel把如此堆料的显卡卖到了1999元——从半导体设计和制造成本的角度,这真能回本吗?......
着眼于这样的基础再看前不久新发布的Arc B580(代号Battlemage),这片BMG-G21 die作为中端甜品卡定位的GPU芯片是不是就合适多了?少于前代旗舰卡的晶体管数量,起码是纸面上看起来更少的算力单元堆料(虽然存储单元整体是加量了)和TBP功耗、略低的显存位宽、8-pin供电口…
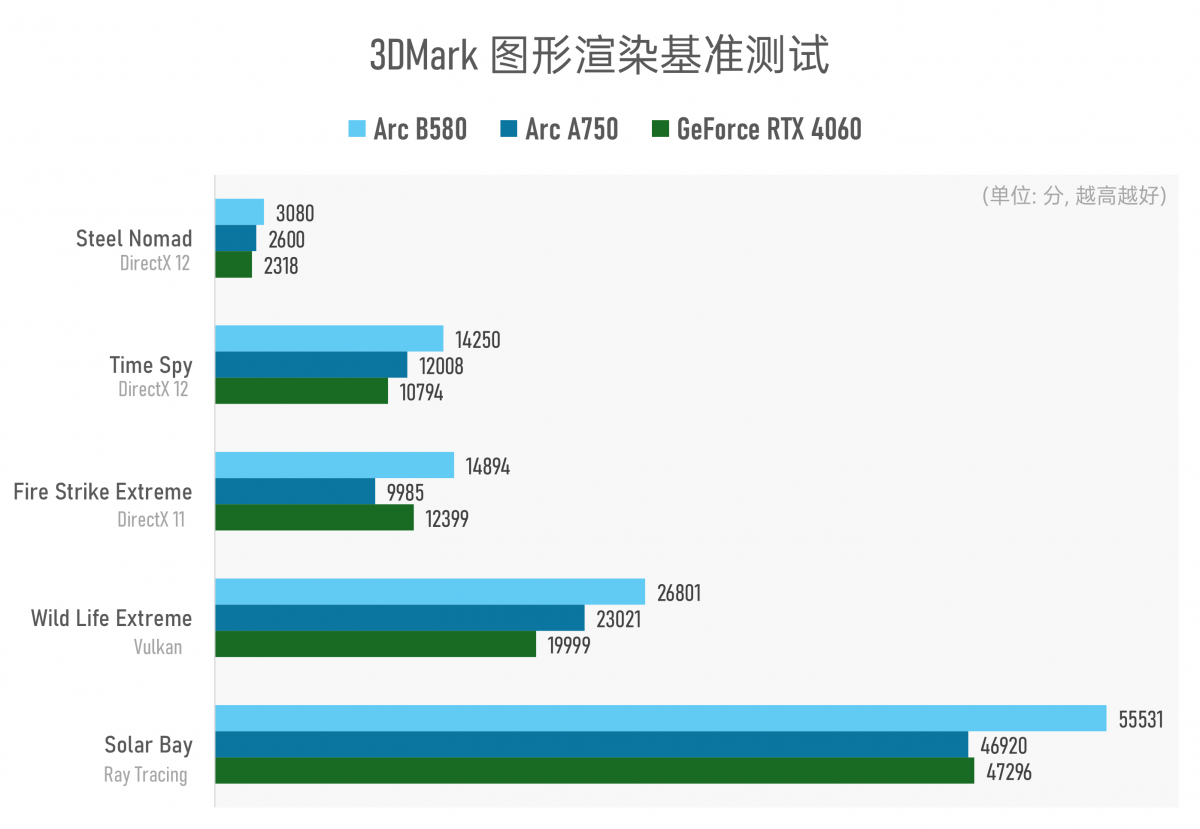
更关键的是,从3DMark图形渲染测试的理论成绩来看,Arc B580还实现了相比A750的全面领先——从不同图形API的针对性测试到Steel Nomad这类更为现代的图形渲染,及Solar Bay专项光线追踪测试,B580都略胜一筹。
虽然从异常值来看,不清楚基于DirectX 11的Fire Strike Extreme测试中,为何A750落败这么多——反复测试都如此;但B580相比A750的理论图形性能优势都在18%左右。
另一方面,理论跑分和实际性能还是可能存在较大差异的,所以Arc B580是否也能如图形渲染理论测试那样,以中端甜品卡的身份打败上代旗舰;以及比起隔壁绿厂的当代甜品卡GeForce RTX 4060,从图形渲染和AI两个角度相较,又做到了何种程度?
Xe2新架构前置说明和测试平台
需要多提一嘴的是,本文仅关注Arc B580与另外两款显卡的系统性能差距——因为体验时间短,本文不会深入到微架构层面去尝试追溯系统应用层面表现出的差距根因——即便这或许才是更多读者关注的。
年中我们也已经撰文大致谈过这代Xe2核心架构具体是什么样的,以及组成更大单元的渲染切片相较前代的差异,本文不做过多赘述。
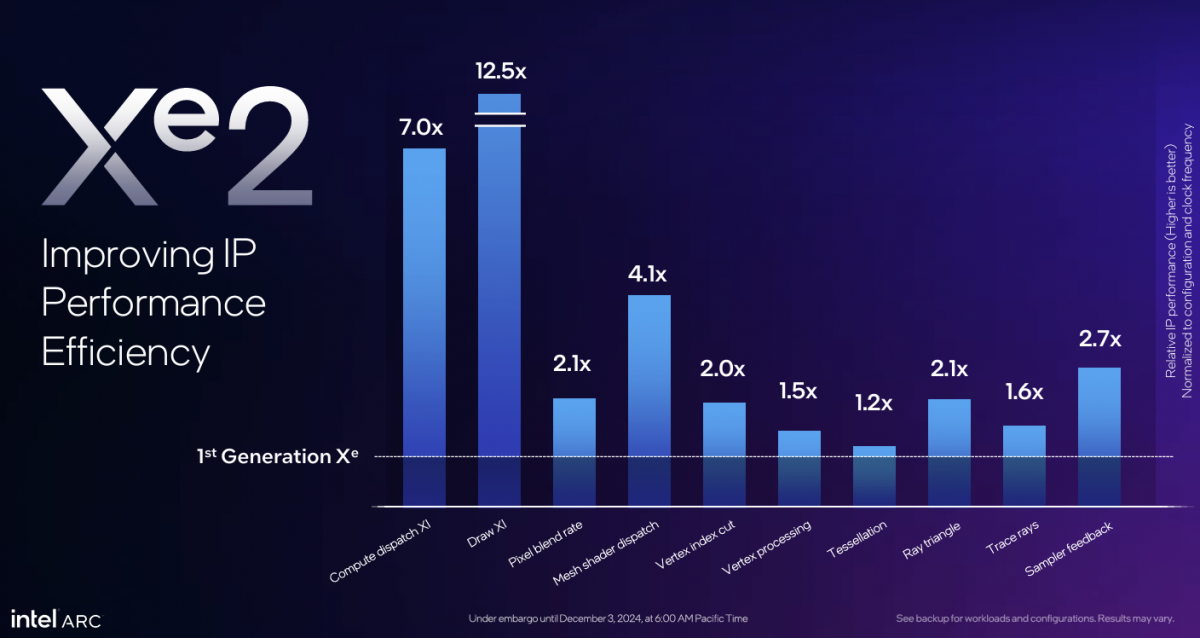
Intel自己给出过偏考察核心IP层面的microbenchmark(上图),能比较抽象地理解Xe核心改进,以及大方向上为什么Arc B580在看起来Xe核心数相对少的情况下,仍在3DMark图形渲染测试中胜过了Arc A750。简单来说就是核心宽度加宽,固定功能单元增配。
每个Xe2核心里面的8个矢量引擎和XMX矩阵扩展引擎个数看起来减半了(XVE矢量引擎似乎是以前的两个合并成了1个,下图右),但数据宽度翻倍,且原生SIMD16 ALU提升了效率——Intel说这么做“更适配现在的游戏和AI应用”。主要强调AI计算的XMX引擎也做了大幅改进——所以同样采用Xe2核心的Lunar Lake的核显才敢说高AI算力。

Intel给出的数据是每个Xe2核心性能相比上代提升70%,每瓦性能提升50%。从渲染切片render slice(4个Xe核心构成一个渲染切片)的角度来看,也有相关图形单元的大幅改进,比如“Execute Indirect”硬件支持;vertex fetch吞吐、mesh shading性能大幅提升;cache纹理压缩率、pixel后端blending吞吐提升...还有RTU光线追踪单元的整体加强等等...
所以文首表中的Xe核心及矢量引擎、TMU/ROP等的差异,也绝不是标注的个数变化那么简单。前置说明讲完,正式进入对比测试阶段。
为搭配Arc B580的中端和甜品卡定位,这次搭的平台也基本契合中端定位,配置详情如下表:


CPU方面,本次测试选择了酷睿i5-13490F——这颗中国特供酷睿13代处理器在去年曾一度被称为“千元神U”,目前在京东平台的售价是949元。其基本配置为6 P-core + 4 E-core总共10核心16线程,核心最高睿频4.8GHz;不带核显。的确是玩游戏的高性价比之选了。对应的,按照这代U的官方规格,选配了4800MT/s的DDR5内存,而没有上更高频率。
用于作为基线进行观察的GeForce RTX 4060,此处选择的显卡是这个系列的丐版卡:七彩虹战斧DUO——特点主打的就是“够用”就行。IIC Shenzhen 2024活动上,我们还拆过这款显卡:其供电和散热设计就讲究一个“环保”...
不过实际上,采用相同GPU die的不同显卡,即便可能存在双风扇/三风扇、双热管/五热管、不同TIM导热界面材料、GPU核心与闪存散热接触方式等差异,但这些显卡理论性能差距最多大约也就在8%-10%左右,落到系统性能层面这个值至少还要折半。所以不同显卡型号的选择多少应当都是能够表现性能大方向的。
游戏性能很惊喜
这一代Battlemage显卡——也就是所谓的Intel二代显卡,来的速度比预想得稍慢了一点,但总算是赶在了隔壁RTX 50系发布之前。我们对Arc B580的预期,原本是能以这一代的中端定位,达成上代旗舰GPU性能即可的。毕竟加速器类型的芯片,即便投入大量研发精力和时间,一般情况下也需要几代产品的迭代与沉淀才有机会看见市场老大的影子。
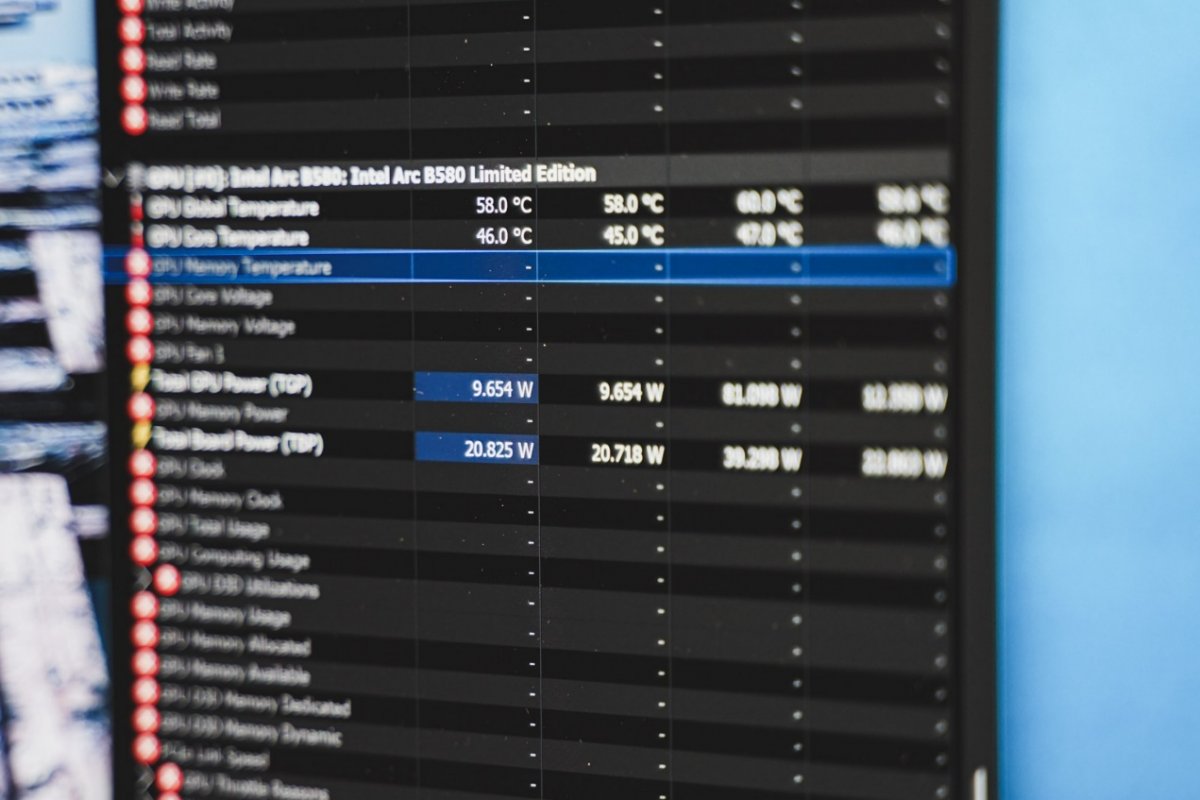
从文首给出的3DMark图形测试可知,图形渲染和游戏性能达成或超过上代旗舰同水平大概率是做到了。实际上就理论测试来看也不仅于此:基于架构和工艺迭代,B580也获得了能效方面的显著提升。追踪三款显卡跑3DMark Steel Nomad期间的TGP功耗情况如下:

需要注意,这张图要结合文首的性能成绩一起看,毕竟三者在不同功耗下达成的性能也是不一样的。
从三张卡跑测试的TGP功耗变化来看,此图有两个亮点。其一是Arc B580以高出Arc A750约18%的性能,达成了TGP功耗近30%的下降,测试期间的平均功耗为135W;虽然功耗还是些微高于RTX 4060(+11%),但单纯就这项测试看,性能也领先RTX 4060超过30%。
其二,在闲置状态、不运行任何大型程序,显示器仅显示静止画面时,Arc B580的TGB功耗约在10W左右(注意该值受到显示器规格、显示输出方式的影响),远低于另外两款显卡。不过这也不是什么新奇技术。
从Intel的资料来看,这一代Arc显卡开始应用ASPM(Active-State Power Management),一种用于PCIe设备的电源管理机制——在笔记本上用得比较多,台式机上不多见。简单来说,这是一种能够将链路PHY置于低功耗模式,并引导链路上的其他设备跟随的特性。
只不过似乎由于从低功耗模式的唤醒会增加延迟,于性能大概也存在些许弊端。Intel具体是怎么实施这套机制的暂不清楚。或许在Battlemage上应用该方案是在为其后续进入笔记本设备做准备。无论如何,Arc B580整体功耗的降低还是显著的。
游戏测试环节,我们从Steam库里随机选了16款游戏,测试三款显卡跑1080p及2k分辨率下,最高或次高(Ultra)画质下的游戏平均帧数,主要是基于DirectX 11/12 API的游戏,也有《CS:GO》和《彩虹六号:围攻》这类基于DirectX 9或Vulkan的游戏:
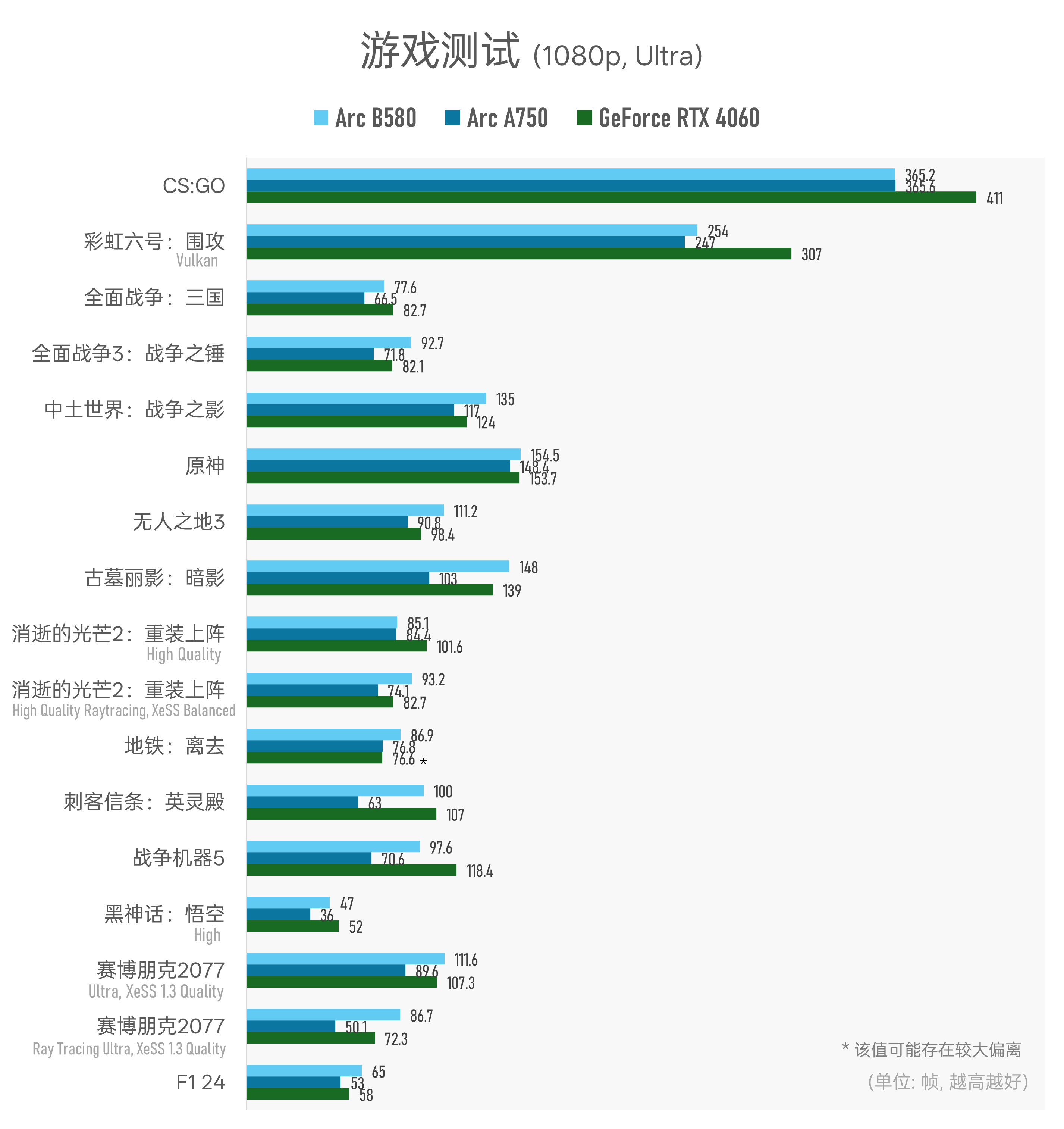
 ▲ *《地铁:离去》的对比数据可能不准确,因为该游戏的benchmark程序无法关闭光追;而该游戏极可能不是基于DirectX 12标准 API接口来实现光追的,所以无法保证采用Arc显卡跑测试时光追一定为有效状态——这可能会大幅影响到测试结果;
▲ *《地铁:离去》的对比数据可能不准确,因为该游戏的benchmark程序无法关闭光追;而该游戏极可能不是基于DirectX 12标准 API接口来实现光追的,所以无法保证采用Arc显卡跑测试时光追一定为有效状态——这可能会大幅影响到测试结果;
另:2k分辨率相比1080p分辨率,多测了一款游戏《崩坏:星穹铁道》;
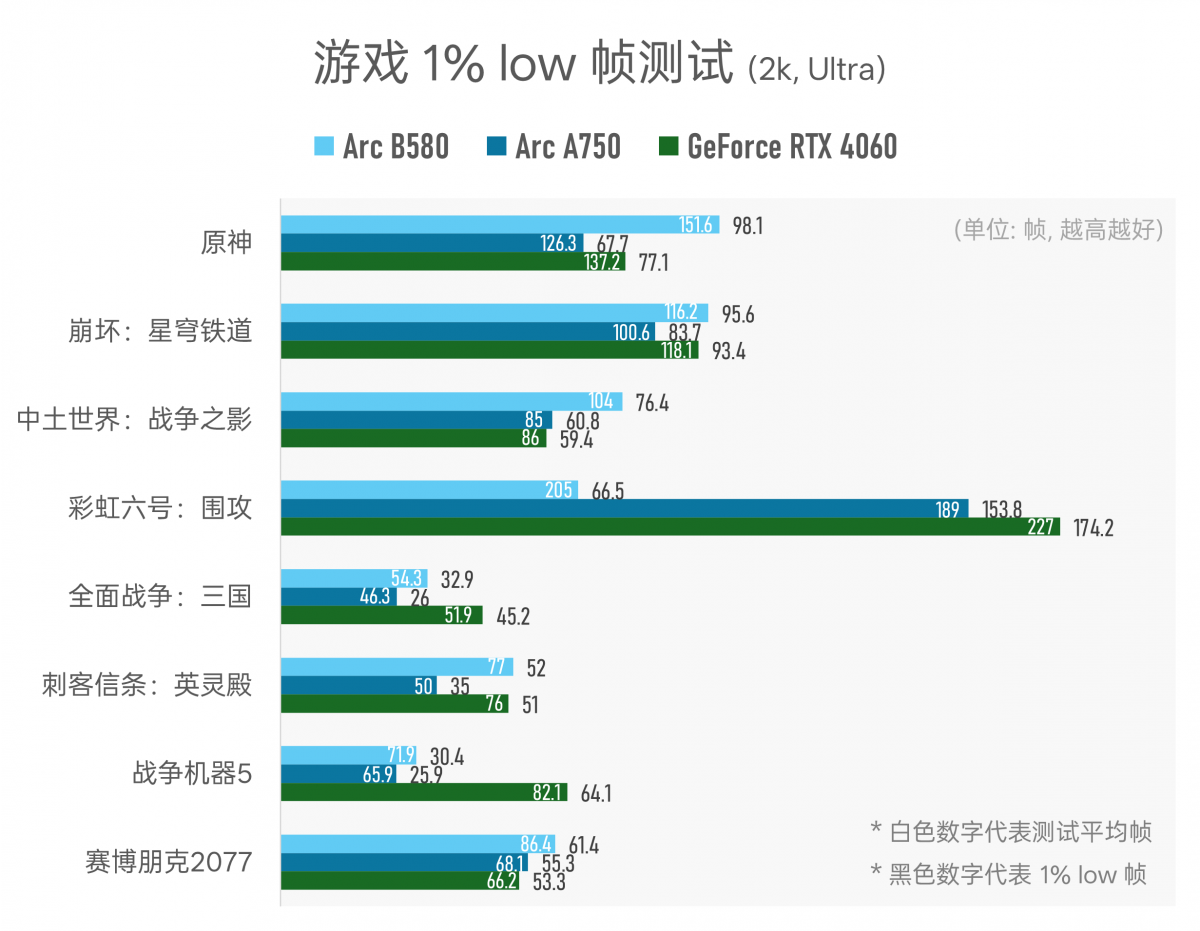
▲ 由于测试时间关系,此处只选了几款游戏做1% low帧测试,供参考;注意其中有个高偏离值:《彩虹六号:围攻》游戏中B580的1% low帧明显低于另外两款显卡,测了好多遍皆如此,原因未知;
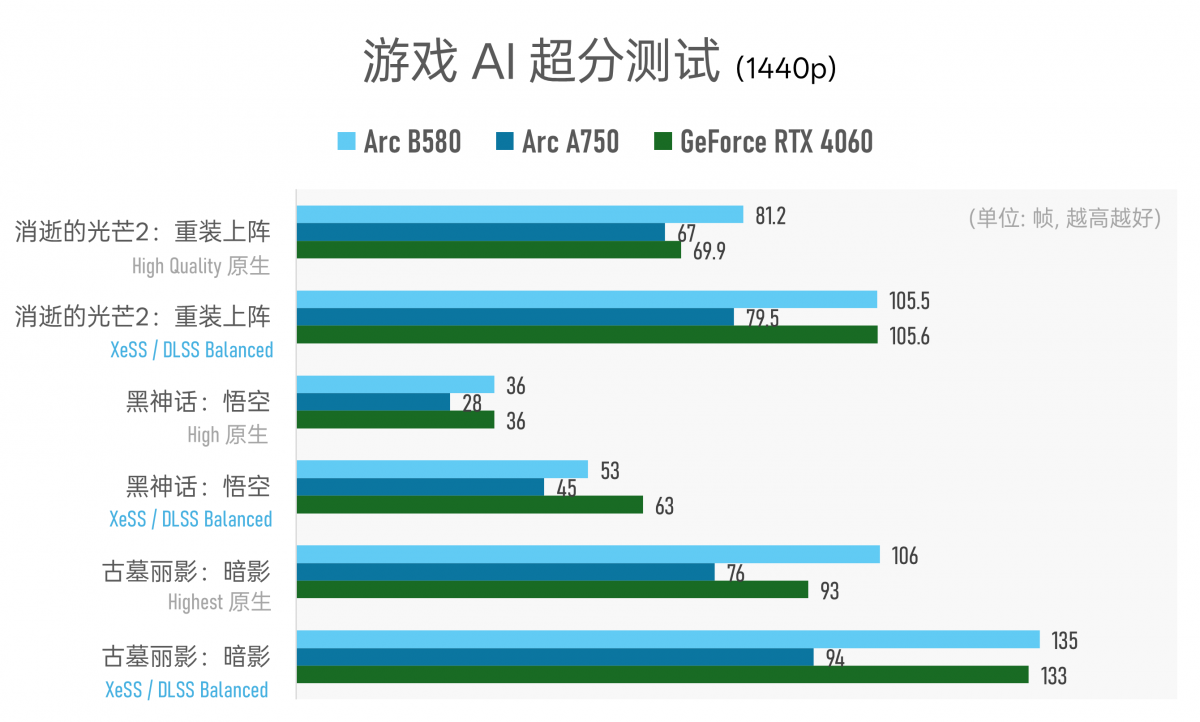
▲ 针对Intel和NVIDIA的AI超分方案,即XeSS与DLSS的简单对比。AI超分的确能够极大程度提升帧率,是个必将在未来大范围铺开的特性;值得一提的是,看起来在同档AI超分设定(平衡档)下,DLSS相比XeSS都更为激进。当下无法判断两者的优劣,帧率只能表现两种技术的偏向性,因为超分后的画质差异暂无量化对比方法…
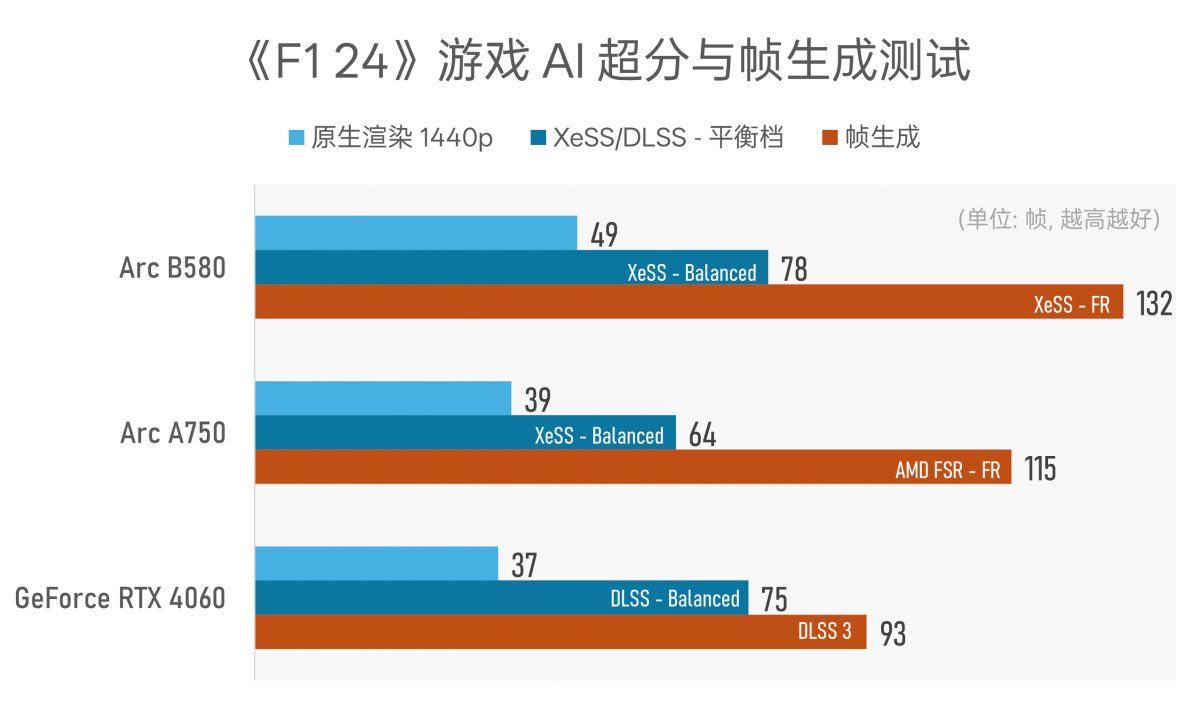
▲ 这次更新的XeSS2技术新增了AI帧生成能力,我们在测试版《F1 24》游戏中率先体验了该特性。相较原生渲染2k分辨率画面,XeSS超分首先提升了大约60%的帧率,在加上帧生成特性后,帧率提升幅度170%(2.7倍)——现在还真是AI的时代啊,GPU生成的像素比渲染的像素多了那么多…
多提一句,AMD FSR的帧生成在《F1 24》游戏中的画质效果有些惨不忍睹,所以此处AI帧生成的帧率对比没有意义——如前所述,它未能反映画质这一变量;
Intel有更新驱动、游戏帧率就涨的“优良传统”,所以还是需要注意前文中“测试平台”表格标注的GPU驱动版本。这些测试结果可能仅代表当前驱动版本的优化水平。就在结束测试的当天,Intel又面向Arc A750推送了驱动更新。本测试仍基于截止2024年12月20日的驱动版本。
另外,本次测试中我们也发现,对于某些游戏而言,不管在显示选项中选择何种渲染分辨率,显示器的物理分辨率都会对游戏帧率产生大幅影响,比如《黑神话:悟空》。
所以测试平台表格也列出了本次测试所用的是一台5k分辨率显示器。它也事实上大幅拉低了某些游戏的帧率。所以就实际体验层面,上述帧率数字还是需要依据玩家设备的详细配置做斟酌。
不过就横向对比而言,这些数字仍然是有意义的。

可能是个巨大的巧合,从测试数据来看,Arc B580的实际游戏性能相较Arc A750提升幅度约24%(所有参测游戏的性能差距取平均)——这恰好和Intel官方给出的宣传数字一致。更巧合的是,就2k分辨率下的游戏性能测试来看,Arc B580比GeForce RTX 4060高出约10%,也和官方宣传数字完全一致。
因为测试结果受到游戏样本的影响,我们的样本量应当远不及Intel官方测的多。而且我们所测的游戏,有相当一部分也不在Intel官方测试列表中;样本选择主打一个随机。所以这应该是个纯纯巧合了。
这里说几个关键数据。除了《CS:GO》这种属于Intel的老大难游戏,Arc B580相较Arc A750基本是游戏性能的全面领先。
其中领先幅度最大的项目,是在《赛博朋克2077》采用1080p分辨率、Ray Tracing Ultra(光线追踪超级画质) + XeSS 1.3平衡档预设画质的情况下,B580的性能领先幅度超过了70%。在《古墓丽影:暗影》《全面战争3:战争之锤》《黑神话:悟空》等游戏中,B580也有~30%的性能优势。
另一个可观察到的亮点是,针对《消逝的光芒2:重装上阵》和《赛博朋克2077》这两款游戏,特别测了开关光线追踪选项(及AI超分)不同画质下的游戏帧率。可能是受惠于RTU单元的架构改进及XMX单元增配,Arc B580在开启光追和XeSS的情况下,相比不开光追,游戏性能的领先幅度会明显更大。

较之GeForce RTX 4060,2k分辨率下,Arc B580在《中土世界:战争之影》《消逝的光芒》《无人之地3》《赛博朋克2077(Ultra超级画质,光追Off)》等游戏中有着约20%的性能领先;在《F1 24》游戏里的领先幅度则达到了32%;当然也有像《彩虹六号:围攻》《战争机器5》等不尽如人意、相比RTX 4060落后的游戏。
不过我们观察到一个有趣现象:Arc B580与RTX 4060在不同游戏中是互有胜负的。在测试的全部17个项目中(《消逝的光芒2:重装上阵》与《赛博朋克2077》皆基于不同画质分了2个测试项),1080p分辨率下,RTX 4060有5项胜出,Arc B580胜出12项;而在2k分辨率下,RTX 4060就只有3项胜出了。
2K分辨率下的游戏性能更好?
我们也特别统计了1080p和2k两个分辨率下,Arc B580与RTX 4060的游戏性能差距。如前文所述,在上述测试样本中,2k分辨率下Arc B580性能优势约10.6%;但如果换到1080p分辨率,Arc B580就优势就只剩下不到2%了。
Arc A750也存在这样的情况。在2k分辨率下,RTX 4060相较Arc A750的游戏性能领先约11%;但在1080p分辨率下,RTX 4060的领先优势会扩大到18%。
从实际使用体验层面来看,这应该不是什么大问题,因为Arc B580本身就定位于以2k分辨率畅玩大部分3A游戏。测试结果也证实了这一点。可以说,这次Arc B580做得的确非常棒,远优于一代Alchemist显卡;也终于首次以更低的显卡售价,在游戏性能上真正超越了竞争对手的同级竞品。

不过这里还是想稍稍掰扯下1080p分辨率游戏性能不及2k环境的问题。前两年我们撰文提过,Arc A750或者说初代Alchemist显卡在算力单元使用率不高时面临存储性能不理想,或者说存储并行能力弱的问题。
所以2k分辨率下,Arc初代显卡的实际游戏性能会表现出更大的优势;换句话说1080p分辨率下的游戏性能不够理想。当时外媒Chips and Cheese猜测是L1 cache和存储子系统的设计不够合理所致。
2023年的采访中,Tom Petersen(Intel Fellow)说猜测是以前的Arc驱动对CPU负载比较敏感(CPU-heavy),“在更低分辨率下,会有更高的CPU负载需求,更加受到CPU工作的限制。随着分辨率的提升,平衡会发生偏移,GPU会干更多的活儿,CPU所占比重更低。我觉得这是主要原因。”且在后续驱动更新上,也总是“更高分辨率下达成更高的性能扩展水平”。
本文无意于对此做深入,不过看起来Battlemage也并未改进该问题——即便可能在2024年的当下,这已经不是个问题了。而且从Tom的说法来看,Intel可能也并不觉得这是个问题。
另外,这次的测试样本量仍然太小,大概不足以确切呈现问题。这里只是提出一种微架构潜在探讨的可能性。
媒体创作、通用计算与AI,也都很不错
对于当代GPU而言,光能玩游戏和图形渲染是不够的,还需要在媒体创作、通用计算加速和AI方面样样在行才行。尤其当前热门的AI、生成式AI,又大幅提升了显卡厂商卷的空间,软件部门的工作更是马不停蹄——所以NVIDIA几年前就说自己不是个芯片厂商了。
针对这三个项目,我们也做了简单测试。首先是媒体创作,主要是视频编辑:
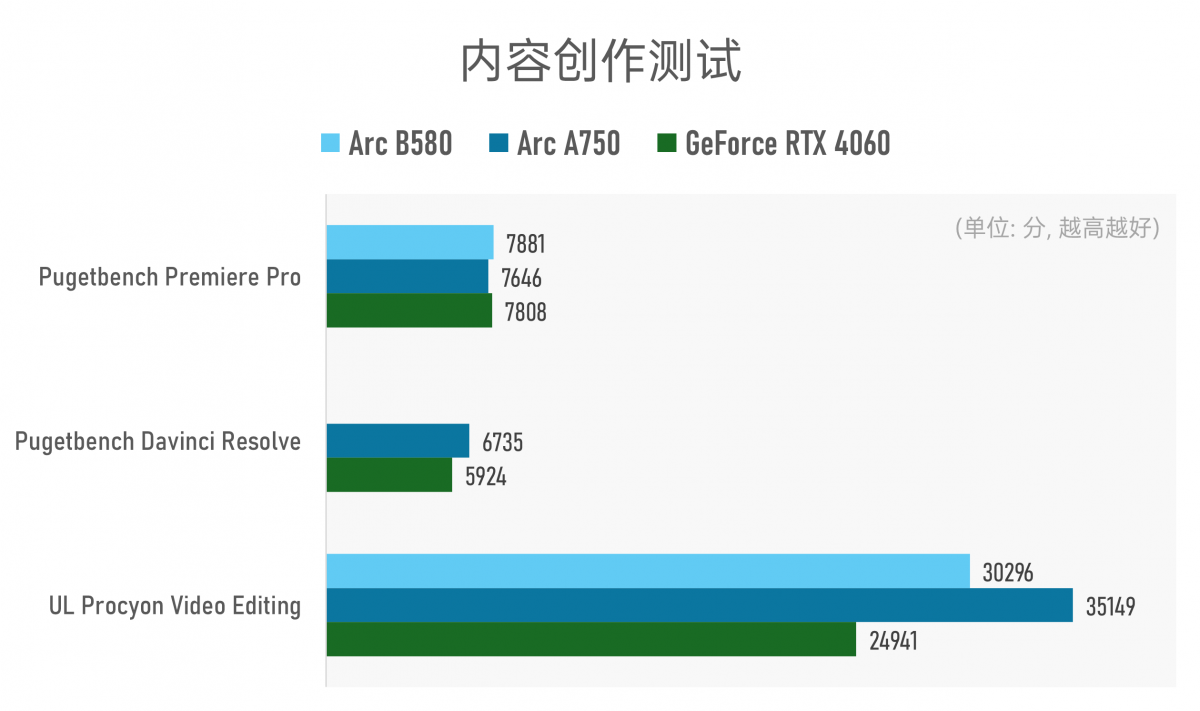
Arc B580的驱动可能还不够完善:针对Pugetbench Davinci Resolve的视频编辑测试中,Arc B580跑不完全流程:始终卡在digital glitch这一测试步骤(应该是模拟视频回放中的错误与失真效果测试),测试软件提示测试超时——猜测可能是未能有效调用GPU加速。
除此之外的其他测试,可见Arc显卡在多媒体创作能力上的优势。记得当年Arc A380刚发布时,有不少人都建议拿它来当经济型视频剪辑加速显卡,既便宜又划算——看来也是体现在了Arc系列的其他显卡产品上。
不过需要注意,受到测试项目的影响,这些测试多少还是存在偏向性的。比如说这里选用的UL Procyon视频编辑测试(2.8旧版)基本就是在测面向YouTube的1080p和4K H.264/H.265格式视频输出/编码能力。这是个非常有失偏颇的测试。
Pugetbench的测试会全面很多,涵盖了视频编辑中大量现代格式的编解码、常见的视频格式与效果处理、图形相关的合成测试;新版还加了AI测试——如超分、人物抠像、光流、音频转写等。从测试结果来看,基本可以说Davinci Resovle用户可以在此价位段无脑选择Arc显卡。
从Pugetbench的Premiere Pro测试来看,虽说三块显卡的总分差不多,但实际上其分项差异很大。所以特别对这项测试做个子项拆分:
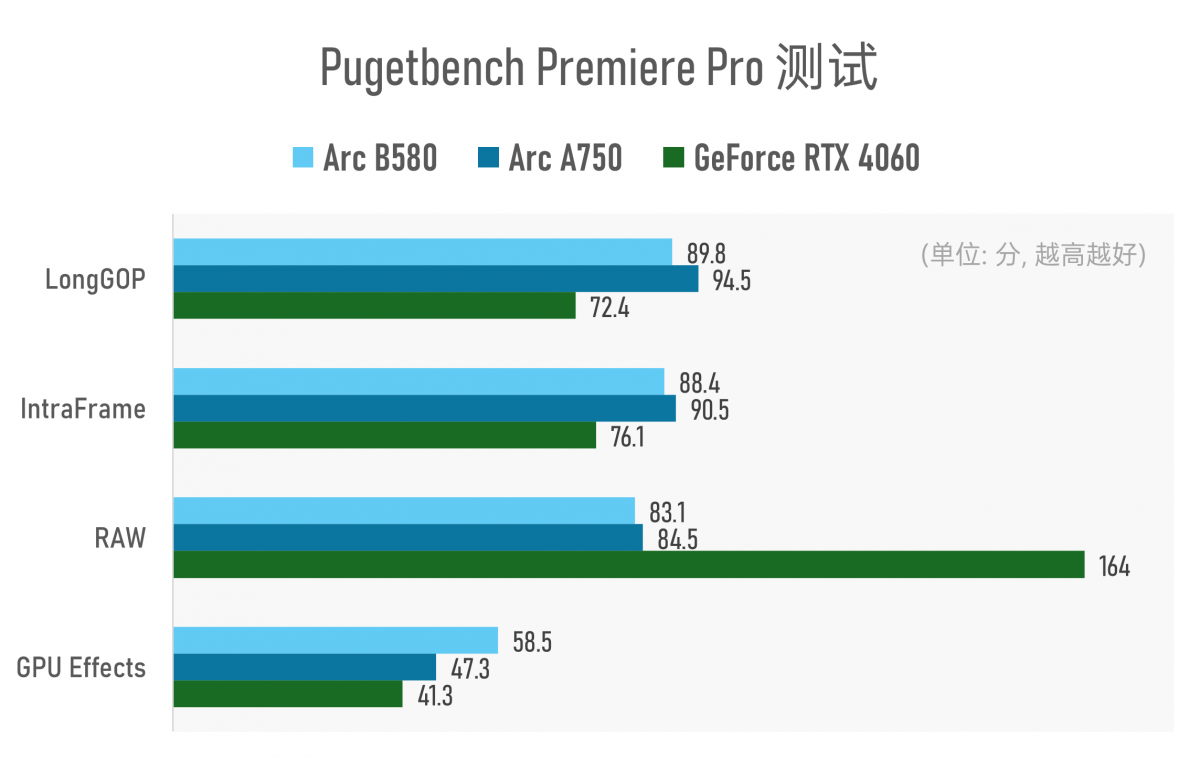
RTX 4060看起来有个“RAW”子项的长板。Puget Systems官网说明中提到该子项是对4K Cinema RAW Light ST, 4K ARRIRAW, 5K Sony X-OCN, 4K/8K RED的RAW格式所做的测试(不过我们测试的免费标准版似乎只对4K RED RAW做了处理测试)。其他项目上,RTX 4060的表现就不及两款Arc显卡了。
不得不说,Arc A750还是在多媒体创作测试上表现出了上代旗舰该有的样子的;即便在GPU Effects这类由GPU加速的特效实现上,Arc B580也如预期般在shader核心迭代加成下获得了不错的成绩。
需要补充说明的是,多媒体创作测试的任务负载有很大一部分是CPU完成的。所以以上是个更偏系统的测试,而并非单纯针对GPU的测试。
接下来是通用计算加速测试,自然就要搬出Geekbench GPU Compute测试了:

Geekbench的GPU compute并不是个图形渲染测试——这是个早于当代流行的AI专项测试之前,就出现的针对GPU的通用加速计算测试,其中包含有机器学习、计算机视觉等应用。
不过这个测试相当不稳定:比如Arc A750基于Vulkan实现通用计算加速的性能得分,不同轮次测试的成绩波动可以来去±20%。所以这个测试也就权当个参考吧。
自通用计算加速延伸的,就是现在流行的AI专项测试了——这原本也是Geekbench GPU Compute测试中的子项。基于现在AI PC的流行趋势,Geekbench也特别向市场推出了Geekbench AI测试:
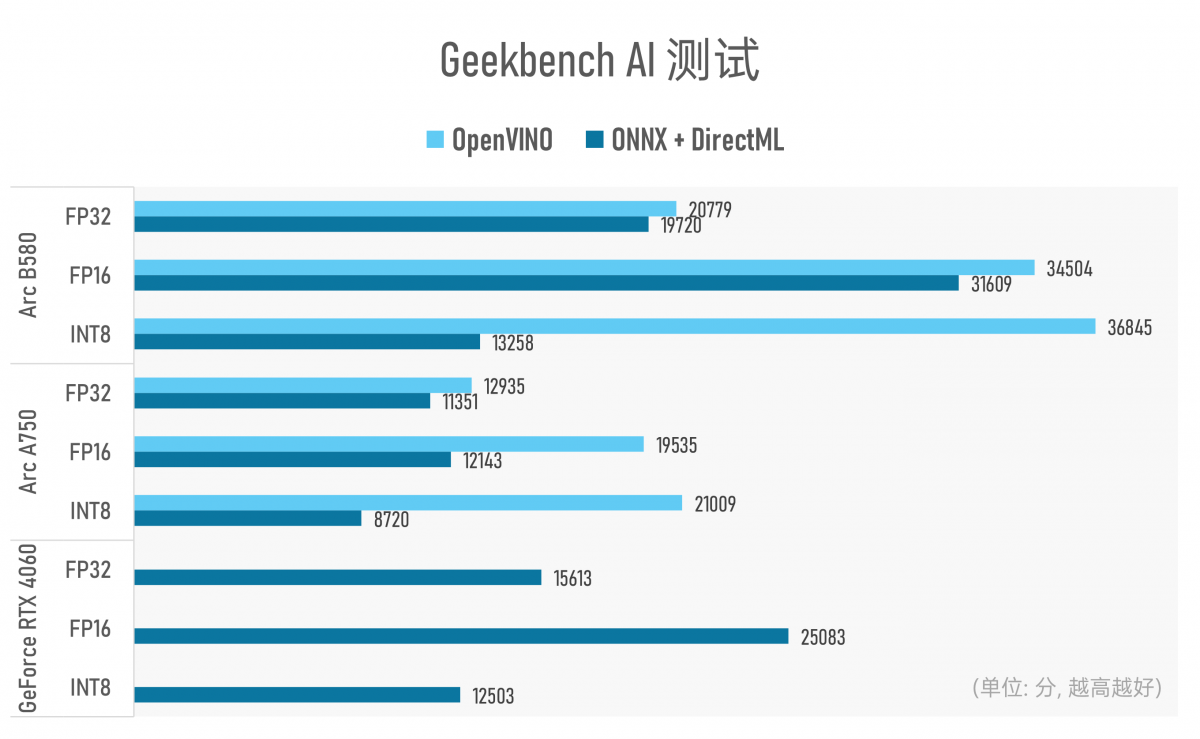
很奇特的是,Geekbench AI到现在竟然也还不支持TensorRT推理引擎。所以针对GeForce RTX 4060的测试,只能依托于ONNX加上DirectML后端去跑。如果单纯看加上微软中间件以后的AI性能测试,不同数据精度下,Arc B580也仍然有很大优势。
从官方标称的AI TOPS理论峰值算力来看,Arc B580和RTX 4060应当是同一水平线的竞争对手(233TOPS)。不过看FP32, FP16, INT之类的理论峰值算力价值也不大,系统层面跑模型的所谓“有效MAC”,以及当代GPU还有Tensor core/XMX引擎之类的加速单元,测试能不能全面用上这些加速单元都很不好说。
某种程度上,AI测试的对比更像是比各家的软件和优化水平(以及测试软件能不能快速跟进…)。但至少就硬件层面来看,最初确立Xe核心架构时,每个矢量引擎都配套一个XMX引擎就能看出Intel对AI的重视。Intel在这种中端GPU的AI加速用料上,也还是比NVIDIA更舍得花钱的。
另外看这个结果,基于Intel自己的OpenVINO做AI推理,这效率也远高于标准API那一套——所以未来端侧AI推理标准收敛之时,到底谁说了算还是未知之数。
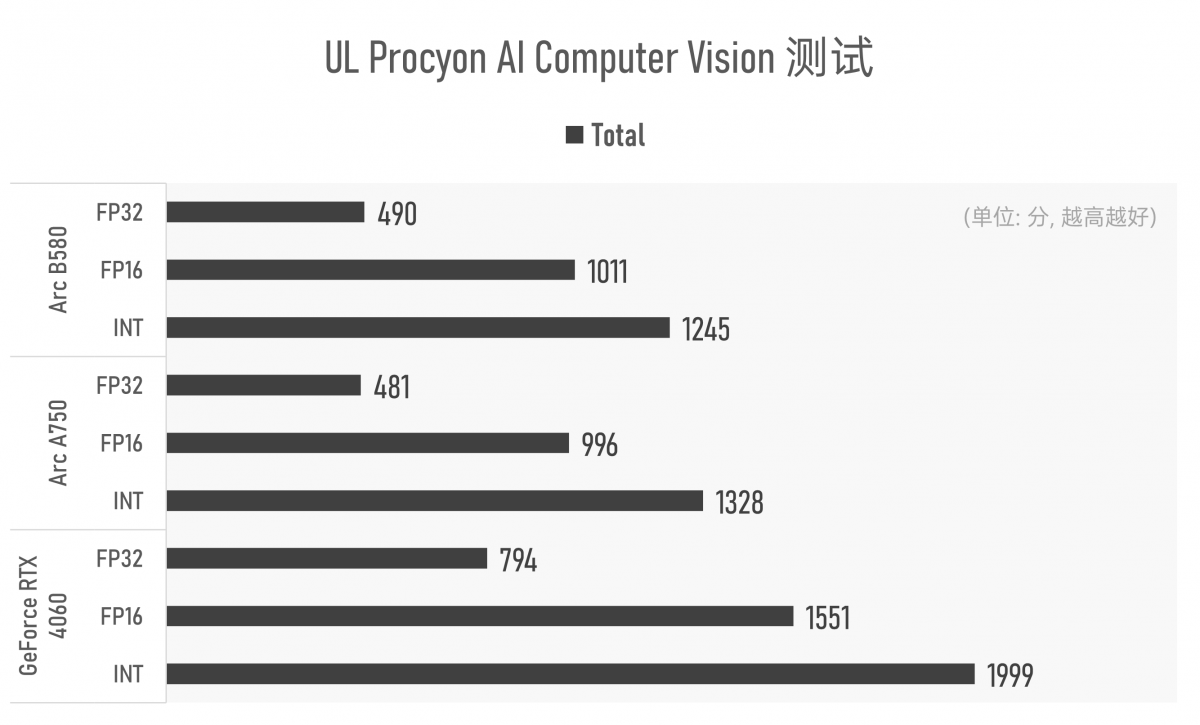
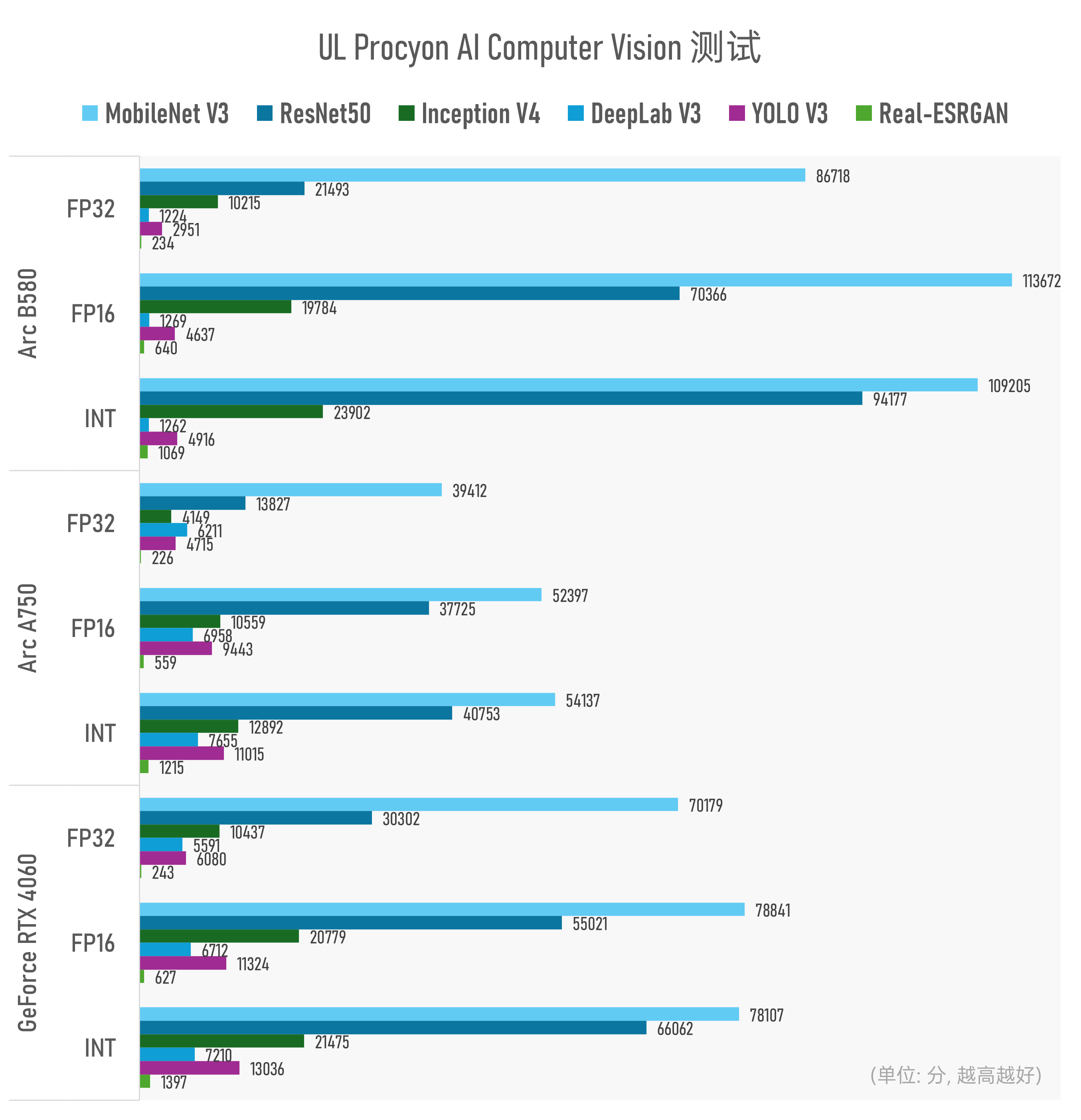
不过似乎上了TensorRT的强度以后,RTX 4060还是在UL Procyon的AI CV测试中表现出了总分上的优势的。
但从这项测试的子项来看,也只能说是互有胜负:看起来Arc B580在MobileNet V3, ResNet50, Inception V4这三个模型的推理性能上优势特别明显;但在DeepLab V3, YOLO V3这两个网络的推理表现上又明显弱于Arc A750和RTX 4060。有兴趣的同学可以去追溯下原因。
最后是现在很流行的生成式AI测试。目前应该还没有一个特别靠谱的基准测试,能够集合众多大模型实现相对综合与系统的性能呈现:比如说Intel和国内几乎所有主流的大模型厂商都进行了合作,以期实现以Intel处理器为算力底座的大模型接入。毕竟AI技术离真正收敛可能还很远。
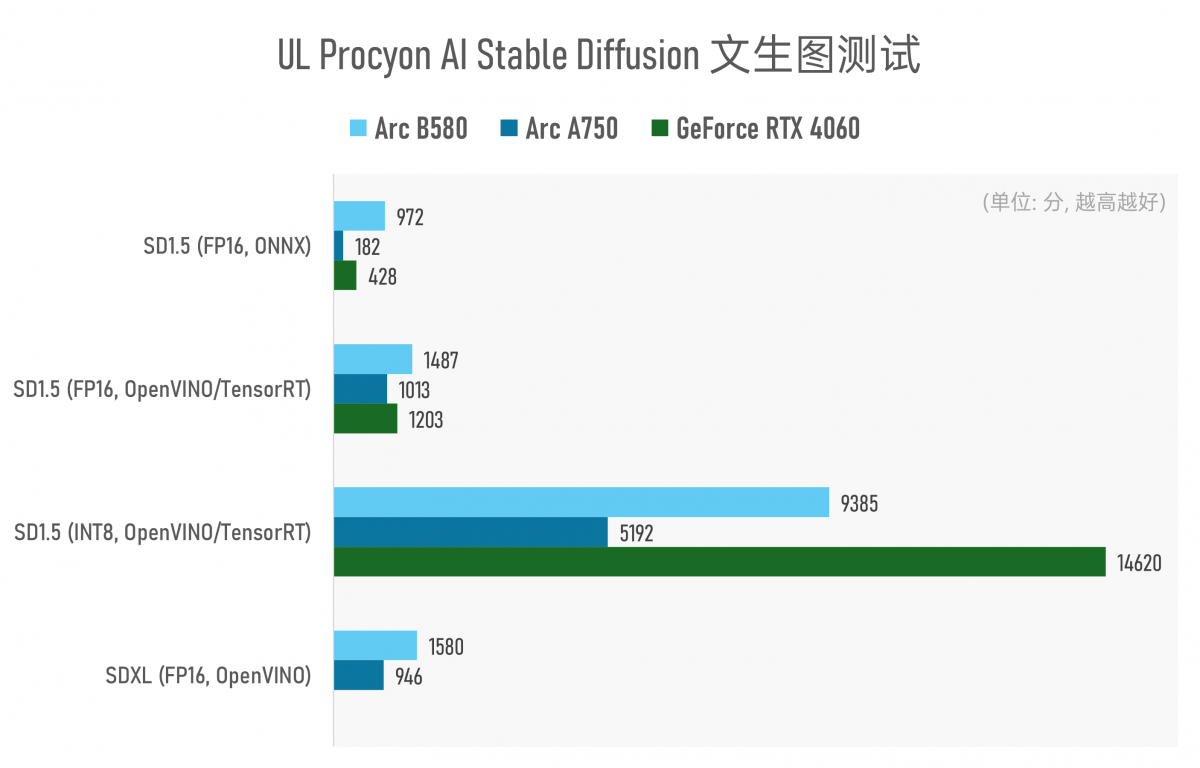
所以也只好继续选择UL Procyon的Stable Diffusion文生图测试来做个简单的考察了(2025.1.2补充:我们发现UL Procyon更新了LLM大语言模型测试,将在后续的测试中增加该测试项)。
在现有测试版本中,不知道是NVIDIA的Efficient AI研究压根没打算让RTX 4060凭借8GB VRAM跑得了Stable Diffusion XL,还是UL Procyon没有积极更新测试所用的中间件,RTX 4060在这个测试环节中跑Stable Diffusion XL一言难尽:跑了8小时,都还缺几张图没生成出来,我们就放弃了。
另外测试结果有个异常值:Arc A750在跑基于ONNX框架的Stable Diffusion 1.5时,得分低得有些离谱。而且此时生成的图全部糊成一片——谈不上可用,大概率是存在测试BUG的。所以上述测试也仅供参考。
至少从上述测试结果来看,除了RTX 4060基于TensorRT做INT8精度的图片生成有速度上的显著优势外,其他测试基本都是Arc B580领先。Intel的软件团队还是应该要加鸡腿的——Arc A750凭借8GB VRAM,Stable Diffusion XL这种规模较大的系统也是能跑得起来的,速度也算可接受(A750 39.602s/image,B580 23.728s/image);相信Arc B580的12GB VRAM也是立了大功的。
只不过我们认为在AI技术尚未走向完全收敛的高速发展期,这些测试主要也就图一乐罢了。或许现阶段更关键的,还是在于开发者、ISV、模型厂商对哪家更满意…

我们很高兴能看到Battlemage二代显卡的问世——Intel没有在一代产品遇冷的市场状况下放弃桌面显卡市场,并且还在持续、大量投入。
总的来说,Intel Arc B580是在发布伊始,成熟度就远高于其上代产品的一块显卡——当然这也是建立在初代Alchemist前期试错,驱动程序高频率反复更新,及与软件合作伙伴、开发者深度合作的基础上;如今还得兼顾AI加速。
更重要的是,Arc B580也是一块真正对得起市场主流中端/甜品卡定位的显卡产品,能够与同档竞品在性能和效率上掰腕子,且性价比还明显更高——即便在我们看来,这还是在相比竞争对手更进一步压缩利润的基础上达成的。
从企业盈利及可持续发展的角度来看,硬件层面更多的晶体管堆料及更大的显存投入,都表明Intel的GPU业务仍有很大的进步空间。而从消费者的角度来看,这就是一块非常值得购买的显卡。
基于Arc B580的表现,一方面这让人非常期待看到Intel未来在Battlemage这代显卡产品上,能够推出堆料更充沛的高端和旗舰卡Arc B7xx;另一方面,传言NVIDIA很快也要在即将到来的CES发布GeForce RTX 50系显卡。GeForce显卡迭代产品的最终表现,也会成为Battlemage面临市场压力的关键因素。

- 过两天给你跑一个
- 能跑下specviewperf 2020 3.1看看吗
- 在显卡领域,Intel就是个弟弟,还是得靠性价比
