
自ChatGPT引爆新一轮的AI和生成式AI话题以后,AI芯片的热度过去1-2年一浪高过一浪。抓住了这波机会,更早就在AI芯片中注入Transformer模型算子支持的企业,都纷纷在强调AI芯片设计“前瞻”的重要性。
因为以芯片12-18个月的设计周期,更专用的加速器如果没有在设计之初就“压对宝”,那么很可能在芯片上市的时候就过时了。近期在接受电子工程专辑采访时,芯易荟创始人、董事长汪人瑞博士说:“AI技术的迭代速度比传统半导体行业快得多。”

前不久的ICCAD上,芯易荟研发副总裁张卫航也在演讲中说:“CNN时代的AI模型就层出不穷,现在的大语言模型、多专家模型等不断出现。要面向某个模型、某个应用领域定制一款高能效的芯片,现在的绝大部分工具都赶不上这样的速度。”
“快速响应市场需求,以工具为核心技术是我们的立足点。”汪人瑞表示,“我们也意识到AI未来将是个无处不在的技术,以后大部分芯片都会有AI的影子。”“靠设计标准IP无法跟上速度和满足客户需求。所以立足于工具,可以为特定场景量身定制IP乃是立身之本。”
在AI发展速度快、市场卷的前提下,什么样的芯片设计工具能在AI时代跟上AI的速度呢?
从GOPS到TOPS
芯易荟去年发布旗下首款EDA工具FARMStudio之时,就说这是个能够自动生成NPU、DSP等DSA处理器的工具,而且是“分钟级”。简单来说,这是个用户输入基础核和超级指令(SIMD/VLIW自定义指令)、选择预置模板以后,就能一键生成DSA软硬件和工具链的EDA工具。
FARMStudio生成的硬件包括有RTL、综合脚本、测试套件、FPGA开发测试环境、RTL验证环境等;生成的软件则有编译器、ISS、性能仿真器、调试器、应用库等。
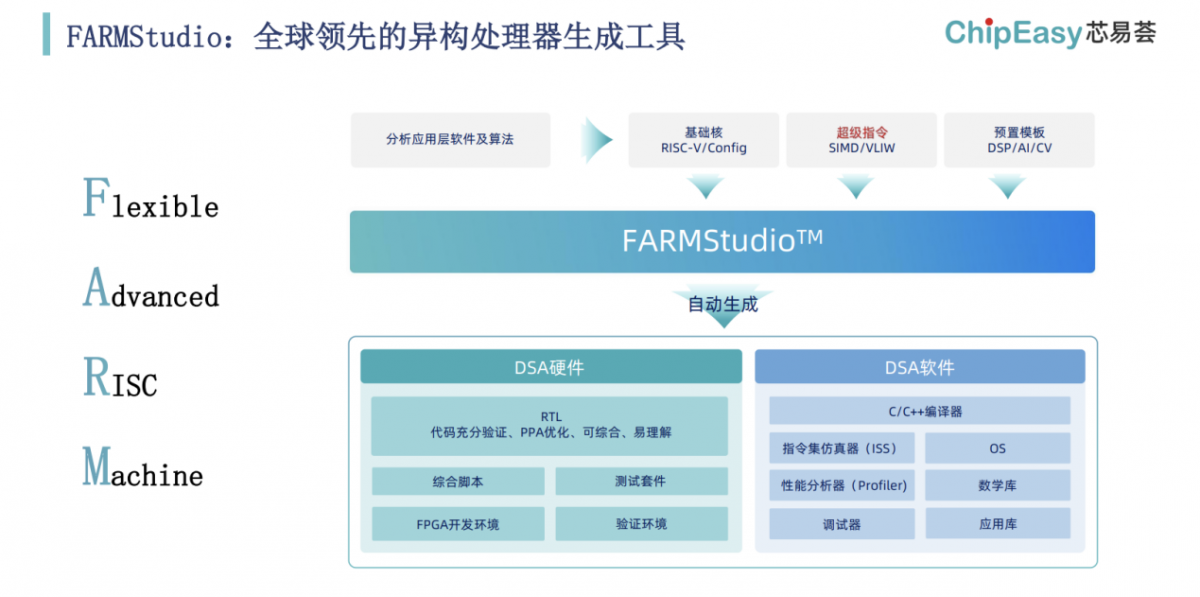
芯片设计者不需要接触处理器微架构和RTL层级,就能快速完成DSA处理器生成和设计。这套方案初见时令人惊艳。芯易荟将其总结为“软件的设计效率”+“硬件的运算效率”;不必像传统设计方案那样在设计灵活性和芯片运算效率间取舍,而能够两者兼得。
此前我们就撰文提过“分钟级”“自动生成”工具的易用性特色,比如所谓的“超级指令”,是软硬件架构师对应用做出分析之后,针对算法热点、重复使用的C语言函数,设计好基于C的指令,用C函数描述指令集功能,输入到工具中。FARMStudio的硬件编译器能够将这里的定制指令集直接部署到处理器的流水线中,并进行功能优化、资源共享等操作。
今年初更新的FARMStudio V2.0版新增了(1)FTOS“多层次开发验证平台”—— “快速验证芯片架构功能性、PPA及电路一致性”,也就是各层次放到同一软件环境中实现归一化,不需要在每个层级——即功能级、性能级、RTL、FPGA,逐一配置和对比;(2)也开始提供云虚拟FPGA用以支撑最后一步验证;(3)及异构多核心设计验证平台,针对需要跑在不同架构、多核心上的复杂负载支持。
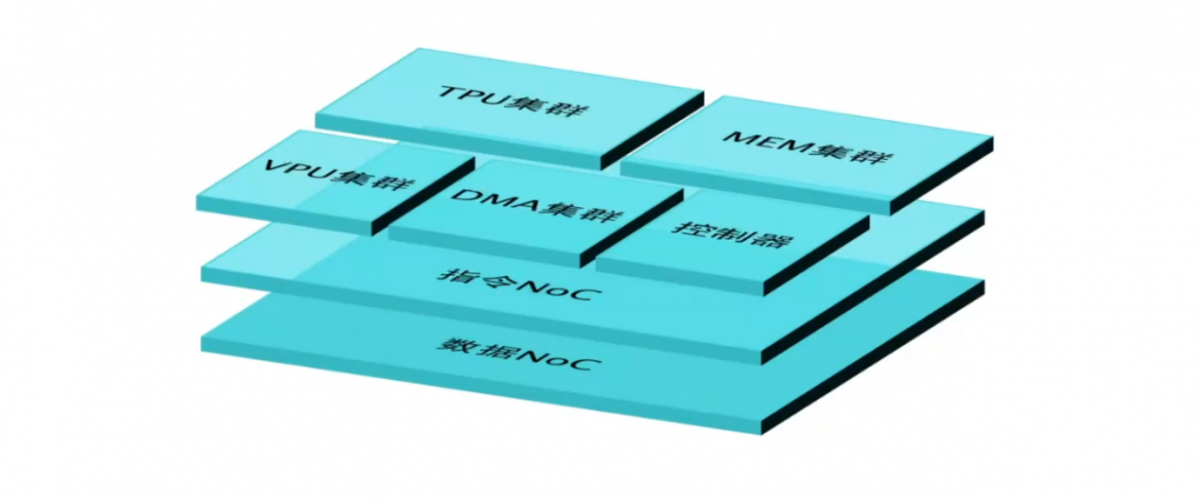
不过FARMStudio主要是用来设计定制核心的,主要面向单核系统。“但凡有点规模的AI系统都是异构多核,要用到各种基础库IP,整合到一起形成规模才能执行大语言模型推理之类的复杂任务负载”,“用FARMStudio设计的很多核心连接起来,构成多核集群SoC。”张卫航解释芯易荟EDA设计工具的AI芯片设计规模化扩展。
“中间还需要添加包括指令NOC(Network on a Chip)、数据NOC等创新构成要素,最终组成高效的NPU。我们就需要对应的设计平台,于是DSSStudio就诞生了。”“而在AI领域,还需要比如NPU的AI compiler/部署及量化工具,以及支撑AI应用的系统工具,用于开发、验证等。所以在DSSStudio之上,再加上AI工具包,形成更完整的有机组合,也就是AIStudio。”
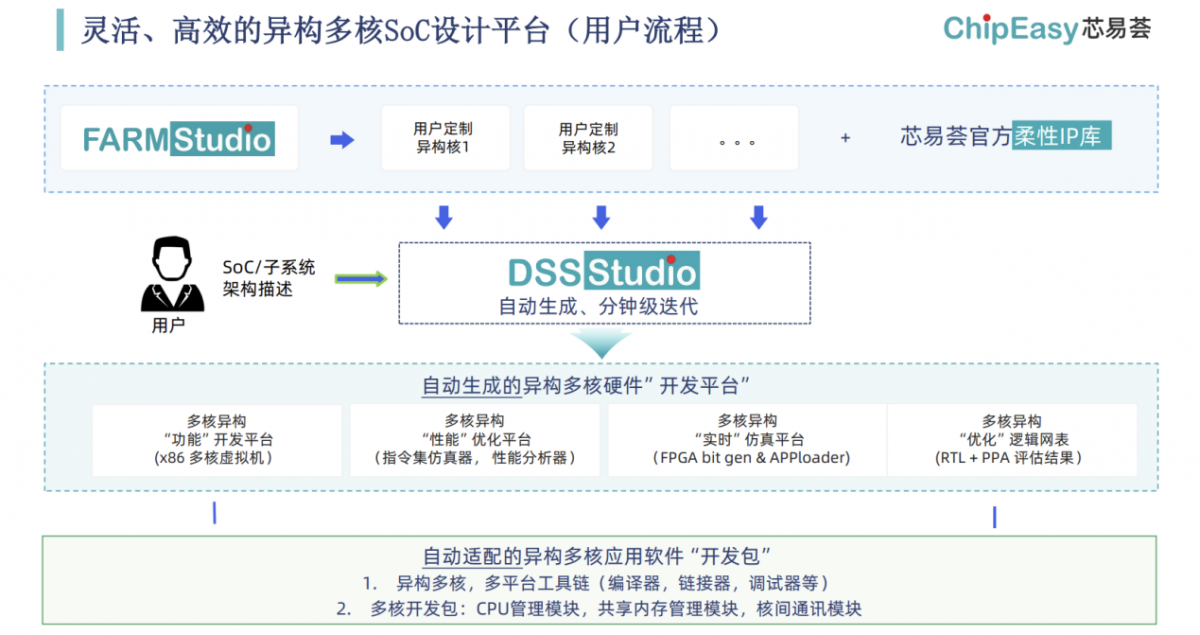
DSSStudio的输入与输出简单示意:输入为不同的核心,可以是来自芯易荟官方IP库,也可以是事先用FARMStudio定制好的;架构设计工程师通过子系统架构描述,在DSSStudio工具中进行各个核心的互联与配置;工具自动生成不同层级的“开发平台”,及RTL与综合PPA评估脚本,和配套的软件开发包(涵盖编译器等工具链及多核资源管理和通信相关的开发包)
简而言之,芯易荟在FARMStudio的基础上,构建起多核异构多核SoC设计平台DSSStudio,异构核心、互连模块等同样自动生成;尔后特别面向AI芯片目标设计用户,搭配对应的AI工具包形成了AIStudio。
汪人瑞总结说,AIStudio是包含有NPU设计软件包、NPU生成工具、AI编译器(部署工具)、基础IP库(如TPU, GMV, VPU, DMA, 指令NoC, 数据NoC等)、基础IP扩展工具的平台。“如果客户想要设计NPU,或者有算法或应用、在寻求硬件方案,借助我们的工具就能快速打造个量身定制的高效NPU。”
AIStudio作为一款EDA工具时,输出完整的硬件设计、应用软件开发工具链,以及多层次验证环境。
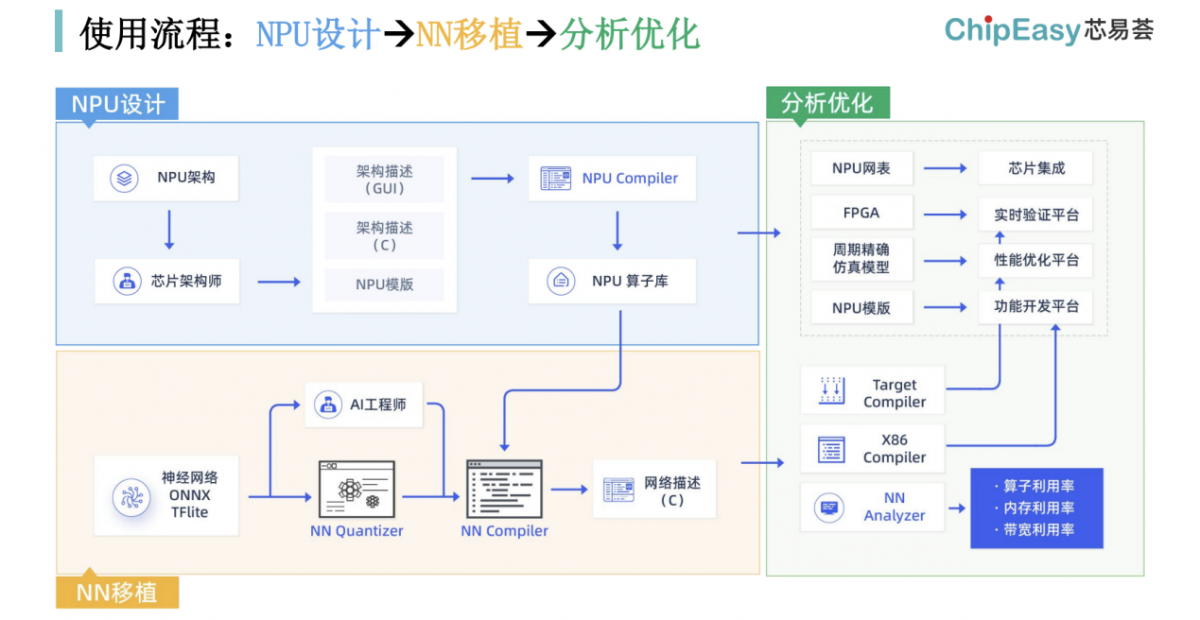
左上:以C语言描述NPU架构;
左下:进行AI模型量化后,协同NPU算子库,使用芯易荟的NN Compiler优化、编译到芯片中;
右:多层次仿真验证,基于性能分析工具做调试和迭代;
基于上述逻辑,芯易荟定位AIStudio覆盖GOPS到TOPS不同算力水平的NPU或AI处理器;应用则从小型AIoT,CV类智能摄像头、端侧个人计算设备,到智能驾驶和生成式AI大模型。据说目前基于AIStudio“设计的NPU逻辑门数可以到几亿、十几亿门的规模”。
分钟级生成和一周一迭代
不过AIStudio也并非芯易荟为迎合AI的临时起意。如前所述FARMStudio V2.0版本中已经出现了“异构多核心设计验证平台”。“这个平台就是DSSStudio的前身,是最初原型。DSSStudio在此基础上增加了设计、丰富了验证环境。”
“推进产品,技术要先行。在architecture exploration的过程中,验证和模型也是我们工具里的重中之重。先实现这样的基础模块,基于此再做进一步的架构。”“FARMStudio是我们所有技术和产品的基石。”
建立在传说中分钟级输出的FARMStudio的基础上,DSSStudio和AIStudio工具的“philosophy没有改变”,“对FARMStudio熟悉的用户能很快上手,逻辑是一样的。”“还是基于应用工程师熟悉的C/C++开发,立刻就能看到结果去实现快速的软硬件迭代。”随多核异构子系统的规模扩展及芯片设计复杂度指数级提升,以分钟级生成为基础,更大规模的AI芯片架构设计据说也能做到一周迭代一次。
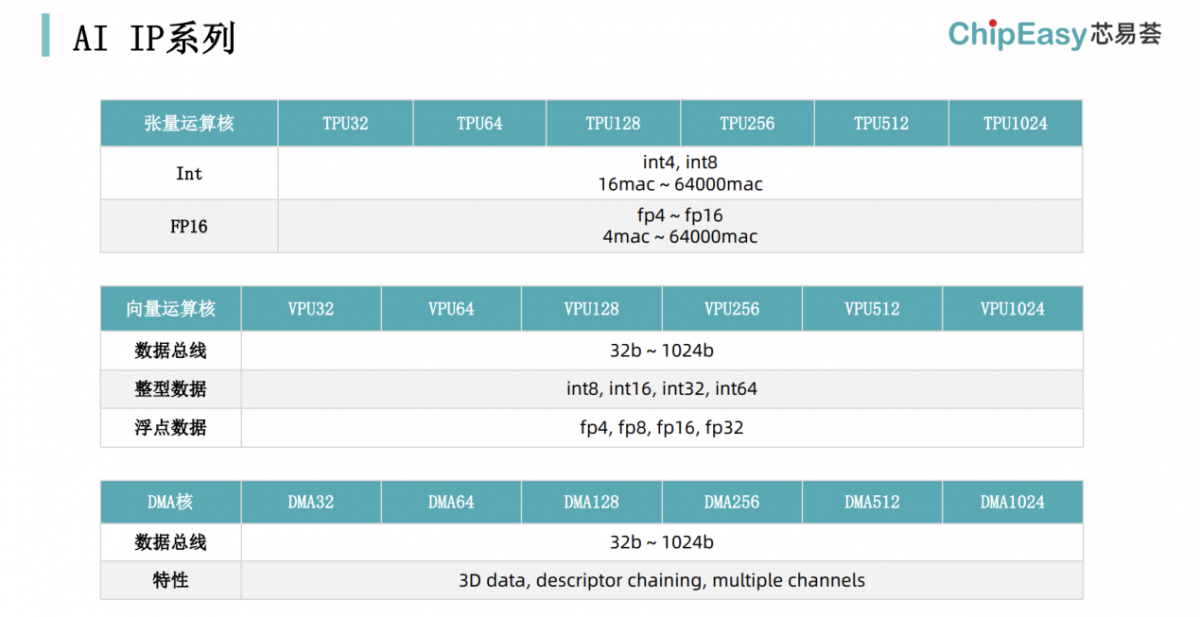
芯易荟柔性IP库中的的部分TPU, VPU, DMA选择,据说这些IP也是用FARMStudio生成的;这些IP也给客户预留了扩展空间
汪人瑞谈到,一周能迭代一次是“经历了好几个案例”以后预期的设计迭代周期。“多个VPU, GMV,TPU或者DMA要怎么分布,彼此之间怎么互连,用芯易荟的设计软件包描述出来是很快的。要做迭代其实也就半天甚至可能1小时就写完了。我们的工具还是能分钟级生成软硬件。”
“后续跑通模型,再做性能分析。根据指令集仿真的性能分析结果,再去看瓶颈在哪儿,去做调整。我们的经验是一周内就能够在新架构上跑完,生成新的PPA结果实现迭代。”
“很多客户有各种不同的想法,每种想法都想去试试。”芯易荟市场总监徐明说,“用传统方案,或许就只能拍脑袋选一个可能是最好的,一路走下去。用我们的方案,一周做这个方案,另一周做另外一套方案,时间和开发成本也是完全可接受的。”
如此一来也就解决了文首提到的芯片设计赶不上AI算子、AI技术发展的现实问题,可以更任性地去设计、优化想要的芯片。不过还有个关键问题是,生成的NPU或其他AI芯片效率具体能够达到什么水平。
大模型推理效率45 tokens/s/TOPS
结合上述快速迭代的优势,针对NPU进行PPA优化,汪人瑞展示了某个与客户合作项目的运算效率成果:Llama2-7b模型FP16推理能够做到45 tokens/s/TOPS,也就是每TOPS算力达到45 tokens/s的推理效率。

“当天我们在新闻稿中宣布这个数字,就立刻有芯片公司发来消息询问。他们说这个数字完全可以称得上惊艳,进而也对我们的技术实现特别感兴趣。”徐明说45 tokens/s/TOPS是全球领先水平,“表明我们的方案达到了很高的效率。”
汪人瑞则就这个数字解释说,不少芯片企业往往喜欢强调芯片的TOPS算力和MAC乘加操作数,但“我们认为衡量NPU更好的方法,是看在一定时间内一定MAC(操作数)情况下,芯片到底能做多少具体的事情。这就是MAC利用率”——“也间接说明了芯片PPA”。
今年8月的MCU生态发展大会上,芯易荟具体谈到过其E32 DSP IP在特定ML负载下,MAC乘加运算时钟数在总时钟数中的占比,相比竞品有明确优势。可见这方面的优势是延续到了更大规模的系统之上的。对于45 tokens/s/TOPS这个数字,“按照MAC利用率来算,应当是达到了60%以上,这在行业内是很高的数字。”
“经过特别的定制就能做到这么高效。”芯易荟研发副总裁石贤帅在ICCAD主题演讲中谈到基于芯易荟的EDA工具,高度可配置的NPU基础架构,“整个系统包含有控制器、TPU集群、VPU集群、memory集群,还有数据搬运的DMA等,这些都是可配置的。”
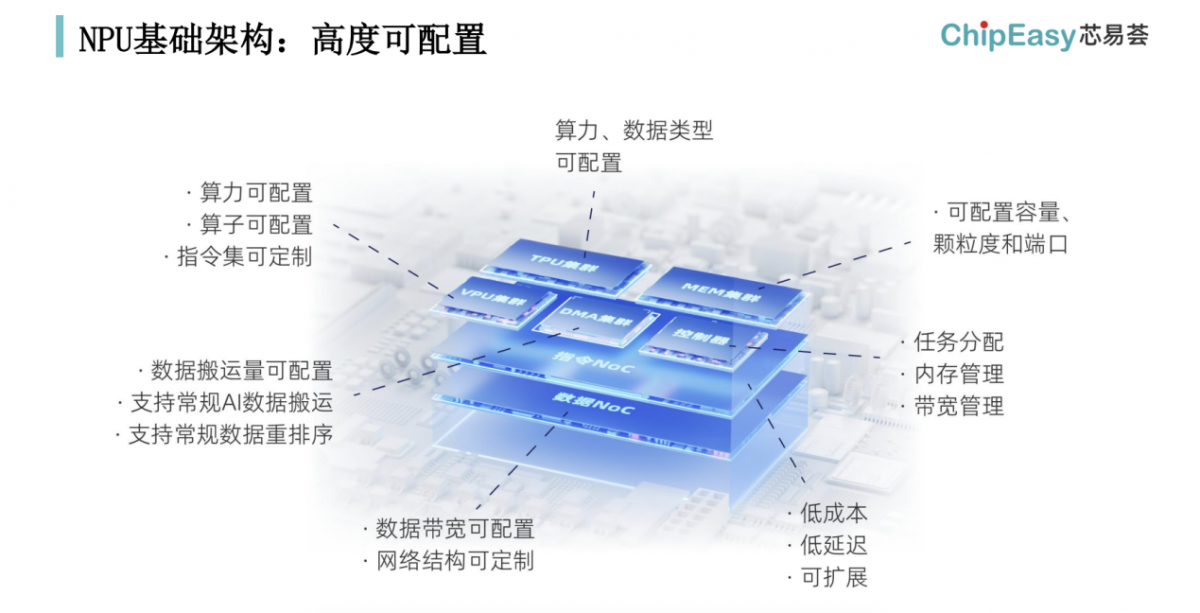
“比如memory集群的容量、颗粒度和端口;TPU的算力也可配置——这就决定了MAC数量,数据类型可配置——是INT还是浮点;VPU的指令集都是可定制的”,“连DMA都可以用C来写。”石贤帅补充说,“所以数据搬运量可配置,也支持常规AI数据搬运、常规数据重排序。”
“下面的数据NOC,带宽和网络结构都是可配置的。所以这样一套系统能够做到极高的MAC利用率、很低的延迟。”可能芯易荟在宣传材料中提到“架构快速探索”,“根据应用场景算法特点适配不同存储方案”,乃至“打破存储墙”就体现在这里。
“对AI处理器而言,运算是一方面,还需要出色的总线方案去解决数据存储、访问效率低的问题。”石贤帅在采访中提到,“这里面的关键技术是数据NOC相关的。比如我们有个定制的DIO直连模块,处理器和处理器直接通信。”
FARMStudio V2.0新增异构多核心设计验证平台,芯易荟其时就提过指令定制调用的异构多核核心直连模块DIO。“通过这样高效的数据传输、低延迟的总线,加上memory存储对应的适配,设计出来的处理器就能做到更高的效率。”
汪人瑞也再度确认了数据NOC在实现高MAC利用率,“打破存储墙”问题上的重要性:“数据NOC是做到高效率、降低带宽需求很重要的部分。包括数据自动排列,以数据流形式传输等等,都是获取高PPA的手段。”
这些应该都是达成高效AI运算,或者高MAC利用率的组成要素。我们自己总结,这个过程的实现就建立在设计可快速迭代、架构可快速探索,并进行性能分析与优化的基础之上;对设计者而言高抽象层级、相对简单的组件定制;以及工具自身的核心技术优势与效率,真正实现了AI芯片的PPA优化;也就有了45 tokens/s/TOPS这样的成果。
AI生态层面的持续耕耘
“现在我们接触到的客户几乎都有AI方面的需求。”汪人瑞在谈芯易荟的EDA和IP产品着重向AI转向时说,“所以根据行业发展趋势和客户需求,我们就对产品做了相应调整。也是基于我们的核心技术,现在我们的产品可以直接助力各类AI应用。”
在此过程中,芯易荟要做的除了FARMStudio/DSSStudio/AIStudio,及其积累的柔性IP库等为芯片设计客户提供的工具以外,涉及到生态要求更高、且覆盖不同算力需求的AI应用,甚至在先进制造工艺下,设计与工艺更为强相关时,要做的工作自然就更多了。
“于前端,一个AI应用的模型通常是ONNX, TFLite等格式;它需要不断下沉,逐步转换进入到NPU芯片内部。我们了解生态的重要性,以及和合作伙伴共同解决问题的必要性。所以模型到芯片接口处,我们专门定义了C的开发包。”
“我们的AI编译器,或者叫部署工具支持模型量化、AI优化的相关功能。但与此同时,我们特别加了个标准接口,让大模型合作伙伴能够和我们一起开发,他们可以从C的层面来接入。这是我们为打造生态所做的一部分工作。”汪人瑞说芯易荟的AI架构团队正在“和前端做大模型的客户交流,理解客户需求与痛点,打通模型到芯片的通道”。
后端则涉及到底层电路的物理实现,“某些AI芯片的规模非常大,后端设计是存在挑战的——逻辑综合、布局布线等等。所以我们正在和后端芯片设计工具和服务公司一起,联合起来把这条路打通,为客户解决更多的问题。”

“这前后两端我们都有生态上的考量,也正在和越来越多的合作伙伴接触”。看来芯易荟更进一步转向AI市场的决心是不小的。“因为我们认为,AI最终必然是无处不在的,需要各种规模、各种类型的AI芯片,绝大部分应用都需要。”“AIStudio能够针对特定应用来配置、优化,能够快速设计和迭代,我想我们在现在的市场环境下,竞争优势是很大的。”
在汪人瑞看来,AI会在“未来数年内持续高速发展“,而芯易荟的AIStudio和基础IP库是AI技术快速发展时期的正解,也是更多芯片设计企业解决问题、跟上时代脉搏的选择。“真正缩短设计时间的工具才为客户提供了价值。”

