
随着大语言模型(LLMs)的参数量已跨越万亿大关,并持续呈现增长态势,在此背景下,突破内存带宽与容量的固有瓶颈,对于满足AI在训练和推理过程中对实时性能的迫切需求,显得尤为关键。为了更好更快的帮助客户在其最先进的处理器与加速器中应用HBM4,Rambus日前率先推出业界首款HBM4控制器IP解决方案。
AI计算对高性能内存需求迫切
AI通常可以分为AI训练和AI推理这两个不同的过程。在AI训练阶段,不但需要给AI提供大量的数据,让它对这些数据进行分析,提取出其中的规律,形成一个AI模型。而且训练周期往往是数以周计,甚至数以月计,才可以实现完整的AI模型训练。
AI训练可以说是目前计算领域中最具挑战性和最难完成的任务之一,因为在这个阶段需要管理和处理的数据量极为庞大。如果训练过程能够越快完成,就意味着AI模型能够更早投入使用,从而帮助投资者尽早获得回报,并最大化投资回报率。

一旦模型完成了基于大量数据的训练,就可以将其应用于实际场景,并提供新的、模型未曾见过的案例进行推理,这就是AI推理阶段。在这一阶段,对性能也有较高要求,尤其是在推理速度和准确性上。毕竟,在通过大量真实案例对模型进行训练之后,我们期望它能够快速且准确地得出正确的结果。
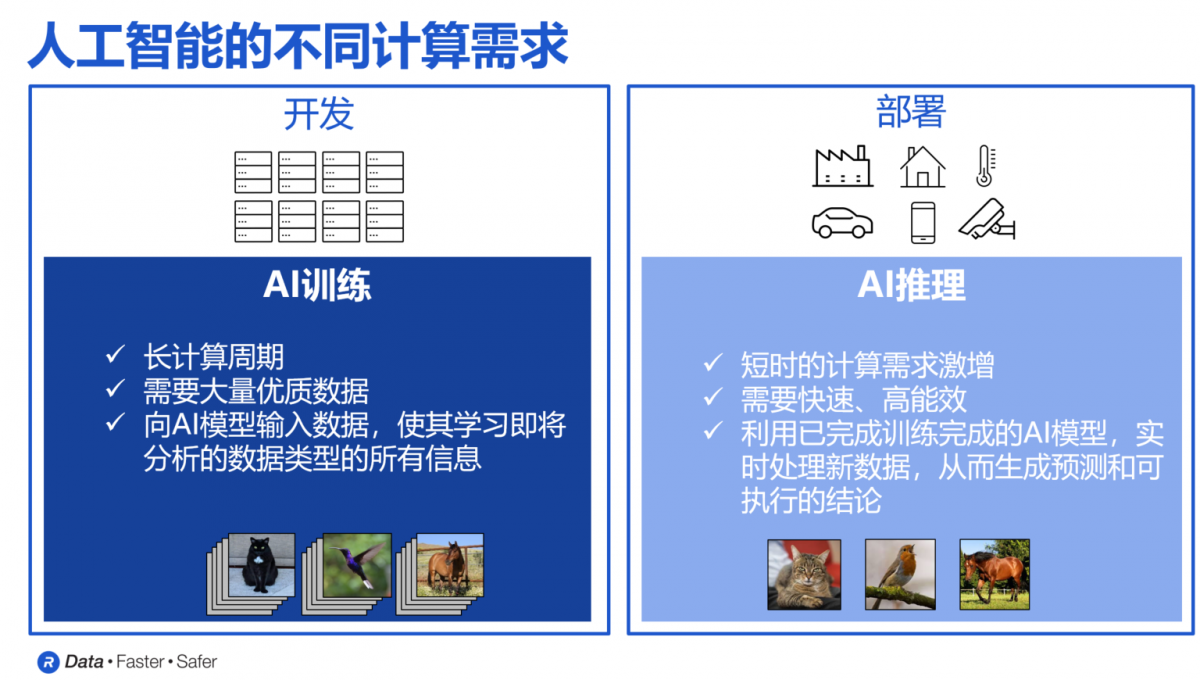
这两个步骤对内存的高性能需求各自提出了独特的挑战,既需要确保其既足够快速,性能足够强大,尺寸足够小。在推理阶段,还需要更短的延迟和更高的带宽,因为推理结果必须几乎实时地快速给出。
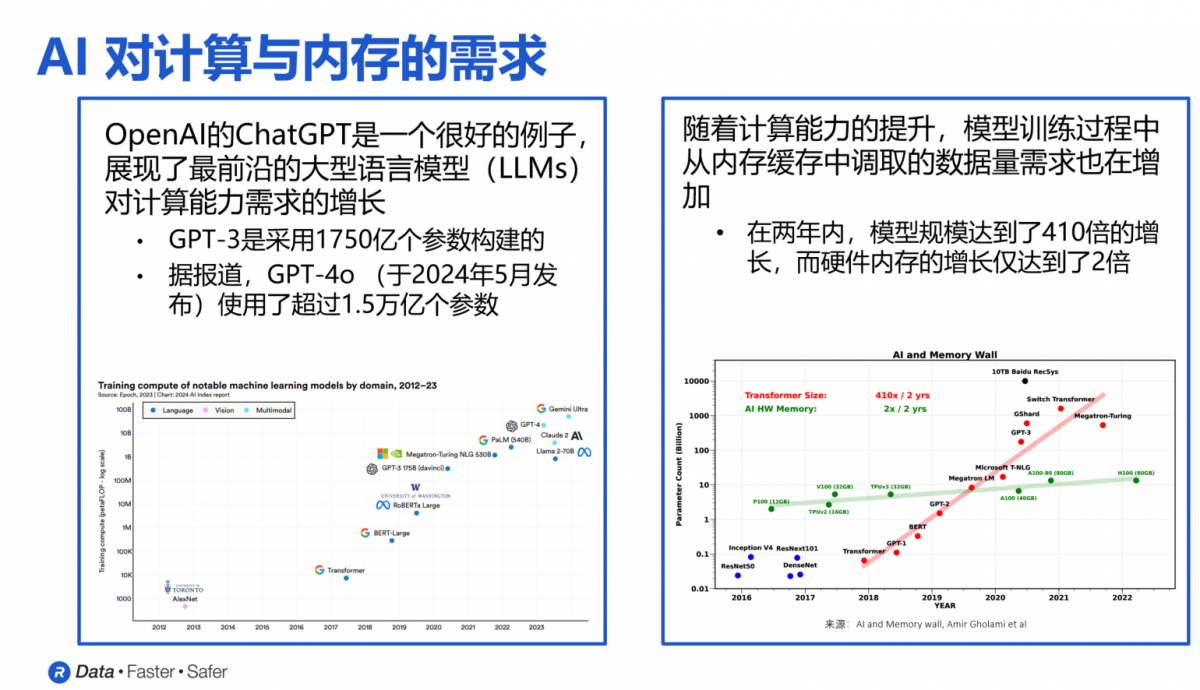
Rambus研究员兼杰出发明家Steven Woo博士用下图直观展现了内存市场需求快速增长和变化的趋势。可以看到,自2012年以来,内存对速度、容量和尺寸的要求每年都在以超过10倍的速度增长,且没有减缓的迹象。以大语言模型GPT为例,2022年11月发布的GPT-3使用了1750亿个参数,而今年5月发布的最新版本GPT-4o则使用了超过1.5万亿个参数。

Rambus研究员兼杰出发明家Steven Woo博士
“过去几年里,这些大语言模型的规模增长了超过400倍,但在相同时间内硬件内存的规模仅增长了2倍。”Steven Woo博士指出,这就意味着,要完成这些AI模型的任务,就必须投入额外数量的GPU和AI加速器,才能满足对内存容量和带宽的需求。
HBM异军突起
与DDR、LPDDR、GDDR相比,HBM凭借远高于普通DRAM的带宽和密度,得到了AI训练、高性能计算和网络应用等场景的垂青。
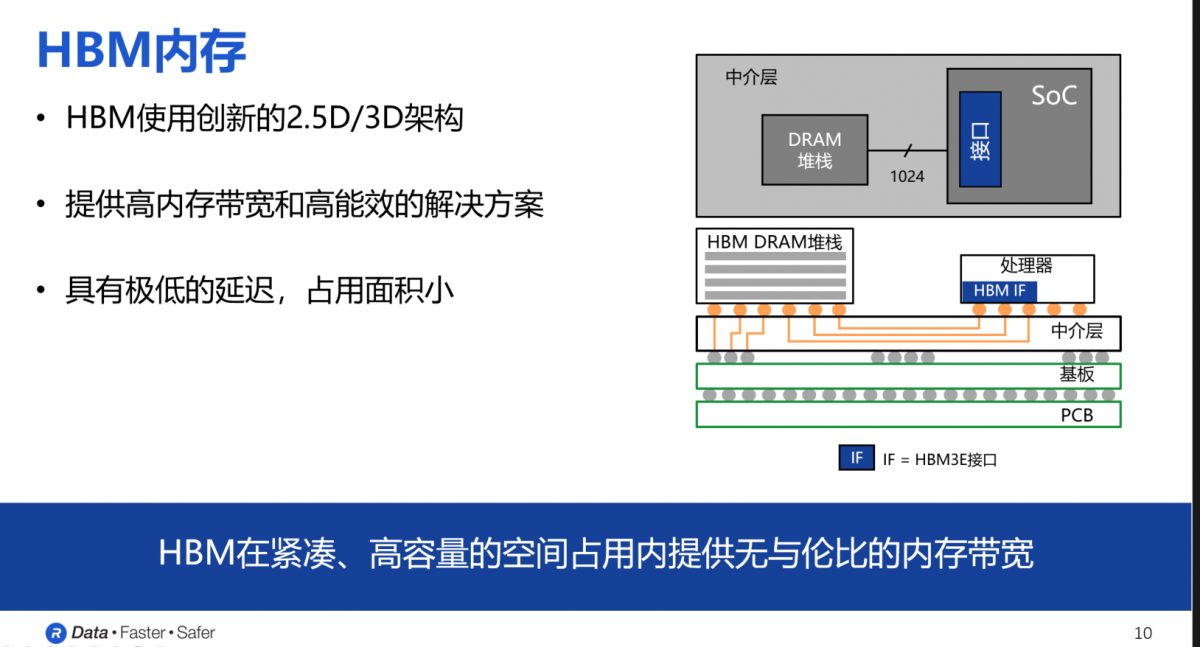
从构造结构来看,HBM中的DRAM内存首先通过中介层的物理连接与处理器相连,之后所有组件再连接到基板上,最终焊接在PCB上。HBM的DRAM堆栈采用多层堆叠架构,其中一个内存芯片可以直接连接处理器,每个HBM内存设备与处理器之间的数据通路由1024根“线”或信号路径组成,因此这种设计带来了极高的内存带宽、大容量和高能效。
下图展示了不同代际的HBM内存在数据传输速度、单个堆栈带宽、堆栈厚度以及最大设备容量等方面的具体参数。
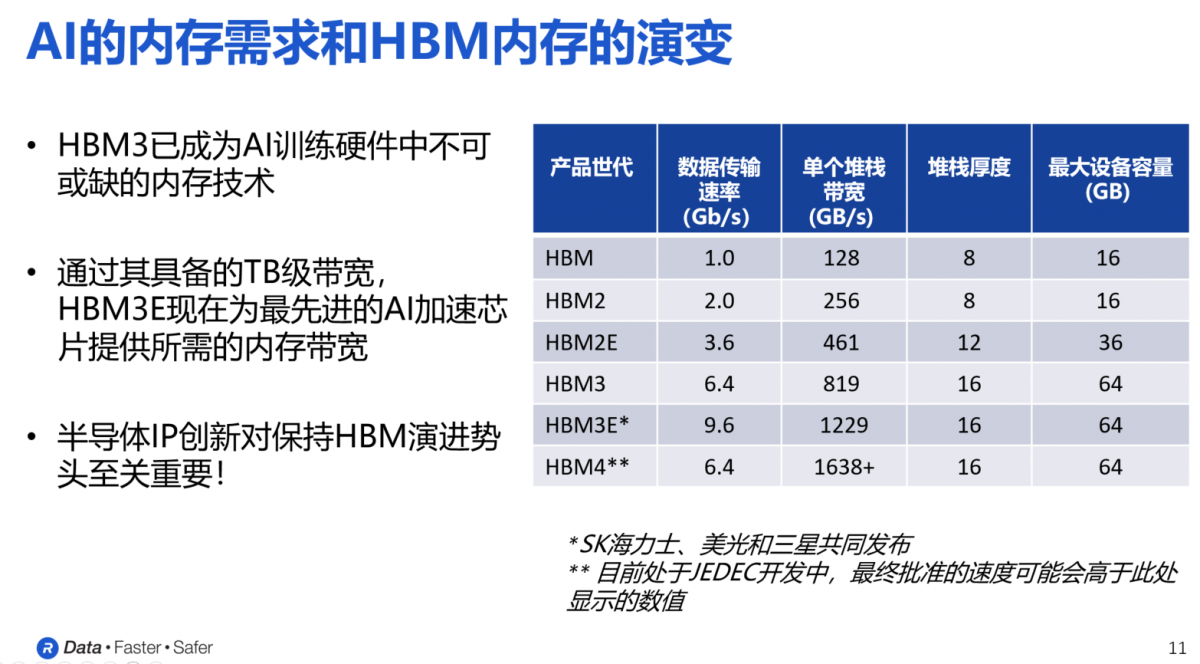
可以看出,从HBM第一代到第二代、2E、3E,每一代的最明显变化就是单个堆栈带宽的急剧增加。以HBM3为例,随着命令、地址、时钟和其他附加信号的加入,HBM3所需的信号路径数量增加到约1700条,HBM3E单个设备的带宽超过了1.2TB/s,上千条信号路径远远超出了标准PCB所能支持的范围。因此,采用硅中介层作为桥梁,将内存设备和处理器连接起来,用类似于集成电路的工艺在硅中介层上蚀刻出间距非常小的信号路径,从而实现所需的信号线数量以满足HBM接口的要求。
目前,主要的DRAM制造商,如SK海力士、美光和三星,已经宣布推出HBM3E设备,数据传输速率最高可达9.6Gbps。正是由于这种精巧的结构设计和HBM DRAM的堆叠方式,HBM内存才能提供极高的内存带宽、优异的能效、极低的延迟,同时占用最小的面积。
在这一趋势推动下,HBM4正成为由JEDEC制定的下一代内存技术标准。从已知的资料来看,HBM4每个堆栈的带宽达到了1.6TB/s,将超过HBM3E,也使得最终的实际带宽会更高。
业内首款HBM4控制器IP
为了帮助处理器厂商和开发人员更轻松地集成和使用HBM4内存,Rambus日前宣布推出业内首款HBM4控制器IP,可以支持新一代HBM内存的部署,适用于最先进的处理器,包括AI加速器、图形处理器和高性能计算应用。
如前文所述,Rambus HBM4的控制器IP提供了32个独立通道的接口,总数据宽度可达2048位。基于这一数据宽度,当数据速率为6.4Gbps时,HBM4的总内存吞吐量将比HBM3高出两倍以上,达到1.64TB/s。与Rambus HBM3E控制器一样,HBM4内存控制器IP也是一个模块化、高度可配置的解决方案。
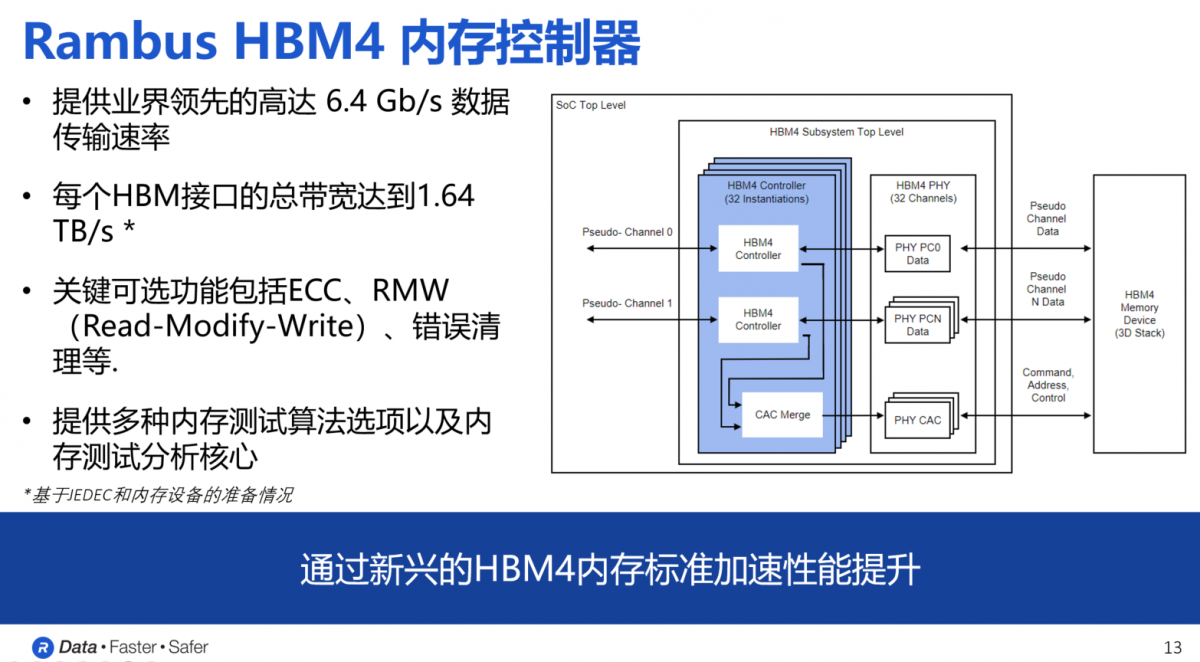
根据客户在应用场景中的独特需求,Rambus还提供定制化服务,涵盖尺寸、性能和功能等方面,关键的可选功能包括ECC、RMW和错误清理等。此外,为了确保客户能够根据需要选择各种第三方PHY并应用于系统中,Rambus还与领先的PHY供应商在匹配、认证和验证等环节开展了合作,确保客户在开发过程中能够一次流片成功。
HBM 4的种种变化给Rambus带来的挑战是多方面的:一是确保控制器不会影响处理器上周围的其他模块;二是确保芯片时序收敛的挑战,以便能够拥有能够以所需速度工作的成功的芯片;第三,通道数增加还带来了实施挑战,例如封装复杂性、功率密度增加以及散热和DRAM刷新管理挑战;第四,如何确保Rambus的IP能够与系统的其他部分(如PHY和处理器的其余部分)无缝连接。
“我们花费了大量时间来确保我们的HBM4控制器IP的兼容性,并能够实现快速集成和首次硅片成功。这些是任何IP提供商都将面临的最困难的挑战。“Steven Woo博士说。
依托于多年来在HBM内存领域积累的丰富经验,Rambus目前已经成功完成了超过100次的HBM设计,并成功交付了业界领先的HBM3E内存控制器,以及业界最高数据传输速率的HBM2E内存控制器(速率达到每秒4Gbps)。
为帮助客户实现一次流片成功,Rambus在控制器测试平台、验证IP和物理中介层PHY三方面与生态伙伴展开合作。例如长期与西门子旗下的Avery Design Systems公司合作,并提供多种BFM,包括内存模块BFM、主机内存控制器BFM和PHY BFM。同时,对于客户所需要在控制器上进行的测试,Rambus提供非常广泛的测试序列,也可以执行特定控制器和PHY的测试序列,还使用了基于功能覆盖率的验证计划,确保完整性。
