
自酷睿11代(Rocket Lake)起,电子工程专辑就开始同步做面向台式机的酷睿处理器体验了。今年的酷睿Ultra二代,传说中的Arrow Lake-S(酷睿Ultra 200S系列),自然也不能免俗。
有所不同的是,在Arrow Lake处理器发布报道文章里,我们就提到这一代处理器的亮点在能效和更低的功耗上。这大概也是自酷睿11代以来,Intel首次在台式机处理器的发布会上,把注意力重点放在功耗和能效上。


为本次体验Arrow Lake,斥巨资打造的新主机…
我们猜测在同一套核心架构覆盖多应用场景的思路下,面向轻薄本的Lunar Lake(酷睿Ultra 200V系列)在诞生之初,其设计理念就影响到了Arrow Lake(或者未来服务器版Lion Cove也加入了考量)。
虽然两者的芯片级系统架构差异较大,但CPU核心保持了设计思路上的一致。这可能是Arrow Lake达成更低功耗的初始原因;也是Arrow Lake最终一切表现,包括这段时间讨论热度较高的游戏性能不济的最根本逻辑。
那么我们本次体验的关键点,除了性能提升之外,就在于功耗和能效表现了;当然还有Intel对于Arrow Lake赋予的期望:普及AI PC,则其AI性能表现也会是我们的关注点。
有关两套测试平台的前置说明
过去几年我们为体验酷睿处理器搭建的平台整体都比较寒碜,今年算是认真了一把的,包括几何未来的厚皮机箱、240水冷散热,以及特别添置的底部反转风扇。也是恰逢把玩《黑神话:悟空》的契机,把三年没换的Z690主板,和4800MT/s的内存换了新...
只不过也不算太认真,散热、内存、显卡都没上顶配(主要还是没钱)。尤其是前不久的酷睿Ultra 200S处理器发布会上,眼见OEM厂商给Arrow Lake配的内存都是8000MT/s起步,我们就感觉搭的这个配置也就是个丐版方案......但起码从外观看来,它更好看了。
今年对比的这两套测试平台具体如下图:旧版基本沿用了我们前两年的配方。

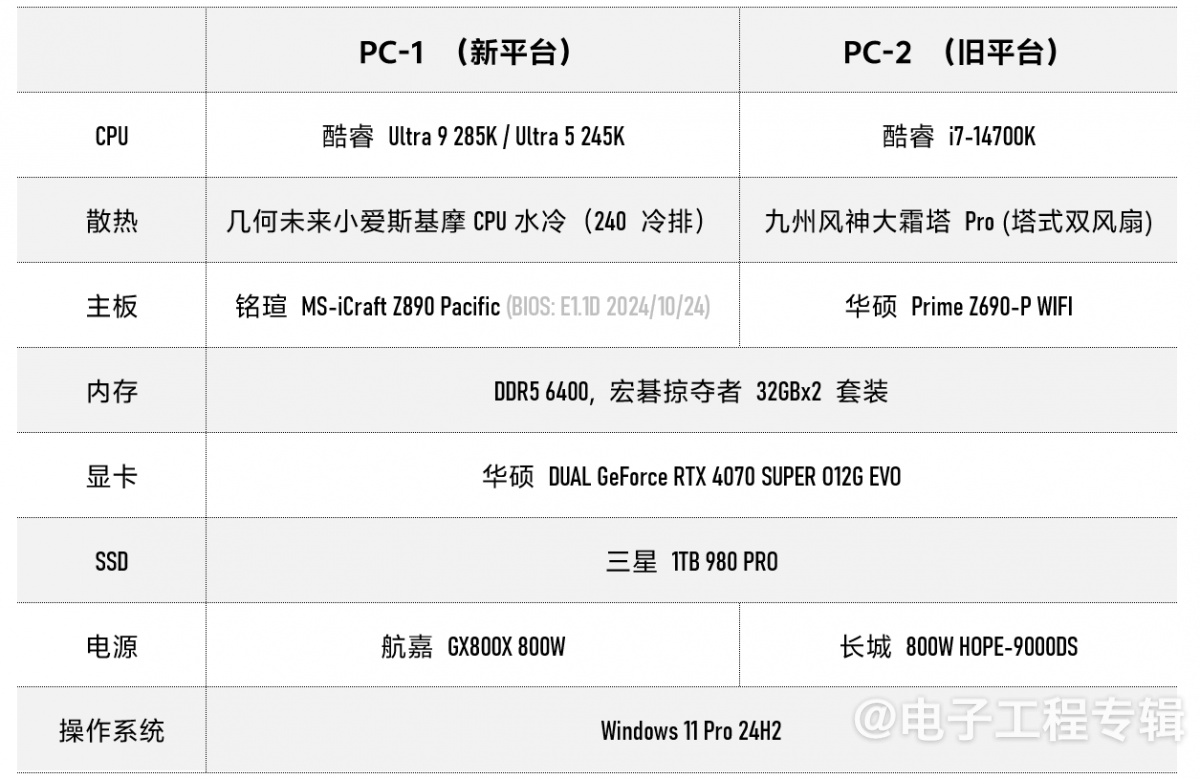
针对这两个平台有几点值得一提。其一是我们在旧平台上选择了酷睿i7-14700K,虽然一方面是因为穷,但也在于酷睿i7-14700K与最新的酷睿Ultra 9 285K依旧有对抗的价值。
因为前者基于8 P-core + 12 E-core核心配方,P-core支持超线程,总共能同时跑28个线程;与后者8 P-core + 16 E-core但不支持超线程共24线程;这有助于我们从高抽象层级了解Intel以能效核取代超线程这一思路是否真的合理。

而且两者P-core最高睿频也十分相似(5.7GHz vs 5.6GHz)~从这两个角度来看,是否有一种今年酷睿Ultra 9其实与去年酷睿i7对标更合理的即视感?
其二,近些年的CPU产品体验也让我们愈发意识到,媒体所做的第三方处理器体验,体验和测试的对象始终是整个系统,而非处理器或任何组件单体。所以我们没有将旧平台的散热方案换成水冷,而是继续沿用了塔式双风扇的风冷方案。
一方面,这本身也成为整套系统在性能、功率、温度诸方面成长的组成部分——反正双方的变量也不止这一个;另一方面,这让我们有机会了解中端水冷散热,相较还不错的风冷散热,是否在CPU代差的前提下构成另一个性能飞跃要素。

其三,稍谈一谈新平台搭配的主板:铭瑄Z890 Pacific。除了16+1+1相DrMOS供电,支持内存超频至8800MT/s,充足的散热装甲用料——典型像是直连CPU compute tile的M.2 SSD位置给足了上下两片相变硅脂片,以及Z890芯片组、2条PCIe 5.0 x16插槽,这些关键要素之外,这款主板的核心卖点应该在颜值上。
酷睿Ultra 200S发布会上,铭瑄在现场特别谈到了Z890 Pacific主板上带的小屏幕;并且说这是行业内,第一次把带小屏幕(铭瑄称之为锐影屏)的主板打到了2000+的价格。

基于铭瑄的Maxsun View软件,可对这块小屏幕显示的内容做自定义:包括官方提供的方案显示CPU/GPU温度、内存占用等硬件资源使用情况;以及用户定制像素风图案等玩法…还是能够给侧透或海景房机箱方案增色不少的。


只不过我们认为,截止到测试结束,这块主板的E1.1D版BIOS(10月24日更新)是有优化余地的——部分基准测试的成绩表现出不稳定或不及预期。最近铭瑄更新了E1.2D版BIOS(11月5日更新),理论上会获得更优、更稳定的系统性能。以下所有测试结果基于E1.1D版本的BIOS,及同期所有驱动。
另外,所有基准测试基于铭瑄BIOS新版UI下的“性能模式”(PL1 = 350W, PL2 = 420W, CPU PWM LoadLine 1.2, 虽然后文会提到其实这个设定对我们搭建的这套系统而言并没有什么软用),以及Windows操作系统控制面板功耗选项下的高性能模式。
新旧两套平台的性能发挥
评价系统性能前,有必要先搞清楚系统的极限能力。所以先来看看新旧两套方案的性能发挥水平如何,毕竟双方的散热、供电条件是不同的。
需要多提一嘴的是,此前酷睿14代遭遇了缩缸事件。如果按照Intel官方推荐的功耗限制来设定系统(Intel Default Setting),则我们的旧平台就只有150W+的性能释放水平。
所以针对旧平台(酷睿i7-14700K)的测试,我们仍然选择了放开所有功耗限制,强加华硕的多核加强,以及XMP内存超频等特性。不过BIOS也已经打上了最新的0x12B微码更新补丁…
用AIDA64进行FPU单烤对两套系统进行10分钟的压力测试,得到如下CPU封装功耗与封装温度曲线(横轴为时间,纵轴为温度/功耗):


比较出人意料的是,采用风冷散热的旧平台,其CPU(酷睿i7-14700K)瞬时封装功耗能摸到315W,虽然只有1-2秒;后续在温度墙的封锁下,又在270W附近坚持了一小会儿,缓缓下落并稳定在255W。
而新平台虽然用上了水冷散热,但CPU(酷睿Ultra 9 285K)也基本秒速撞到温度墙,CPU封装功耗在292W处坚持了3-4秒,后续几乎全程稳定在286-287W——封装温度是顶着103-104℃在跑的。看来这240水冷虽然在持续性能发挥上有提升,但也不过如此。
所以铭瑄主板BIOS设定中的性能模式策略(PL1 = 340W, PL2 = 420W)在我们的新平台下基本不会发挥作用(泪奔〒_〒可能主机内部的风道设计多少还是有点问题。
此外,我们也追踪了两个平台各自在跑5轮Cinebench R23多线程测试时的CPU封装功耗与温度变化情况(横轴为时间,纵轴为温度/功耗):
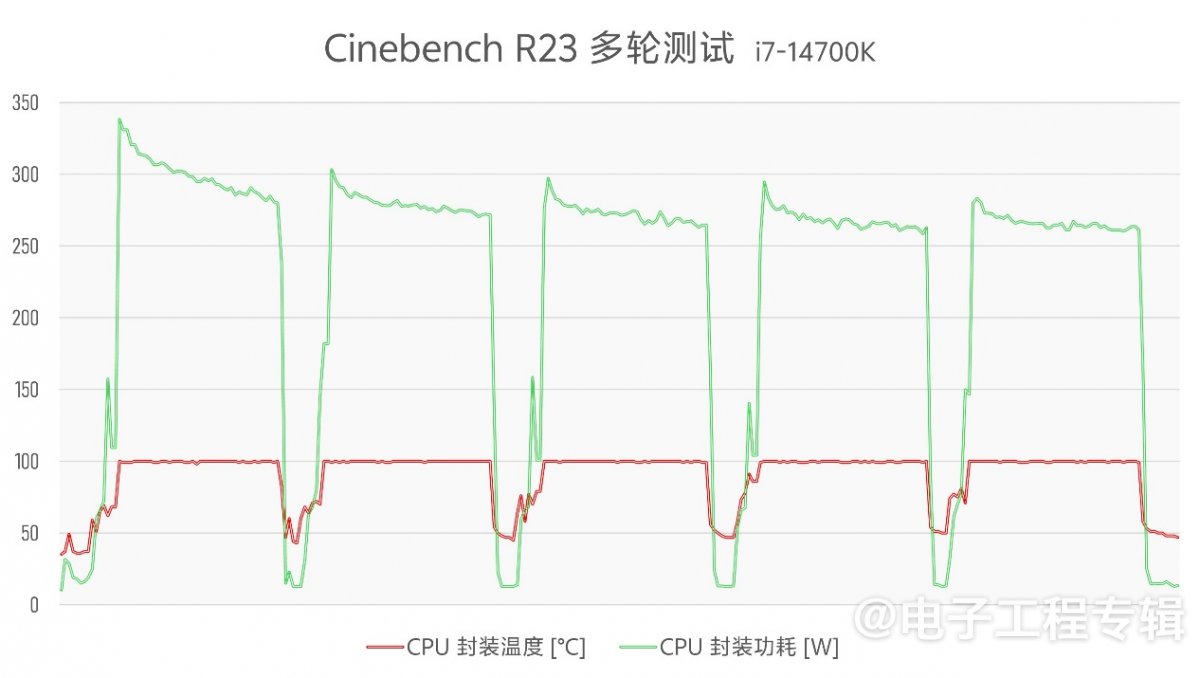
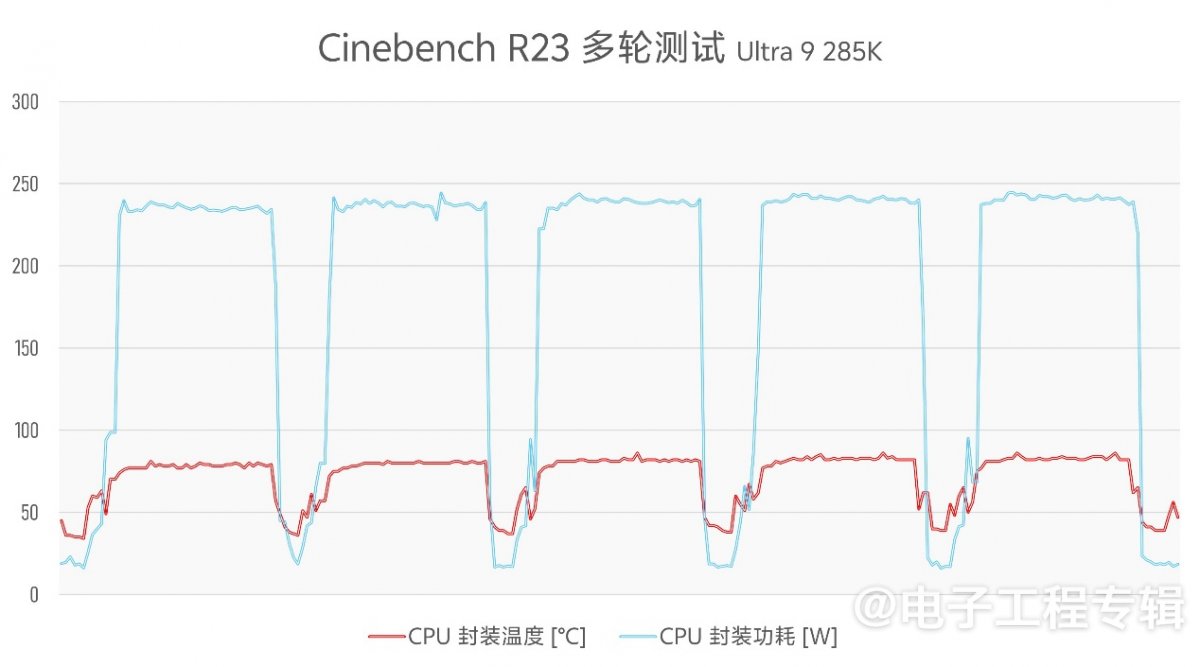
旧平台的酷睿i7-14700K在Cinebench R23首轮测试时同样有个明显的性能突发,甚至将CPU功耗推高到了将近340W;但在此之后就由于散热限制,再也没能达到该功率点——前4轮测试i7-14700K都曾尝试触摸300W功耗,最终会跌落至270W水平。
新平台(酷睿Ultra 9 285K)就比较奇怪:全程5轮测试CPU封装温度最高80℃,封装功耗不到240W。观察跑分时的各项数据,包括电流墙、CPU核心温度最高点等——没有任何指标达到上限,但功耗和温度也仅限于此了。
而且得到的性能成绩相较其他媒体已经公布的,也没什么异常。不知道是新平台何处瓶颈,亦或Cinebench R23多线程负载已无法跑满当代处理器?(逃...
从Cinebench R23持续跑10分钟的结果(总共跑了大约30轮Cinebench R23多线程测试)来看看这两个平台的实际性能稳定性情况(每个圆点表示一轮测试,纵轴表示性能得分):
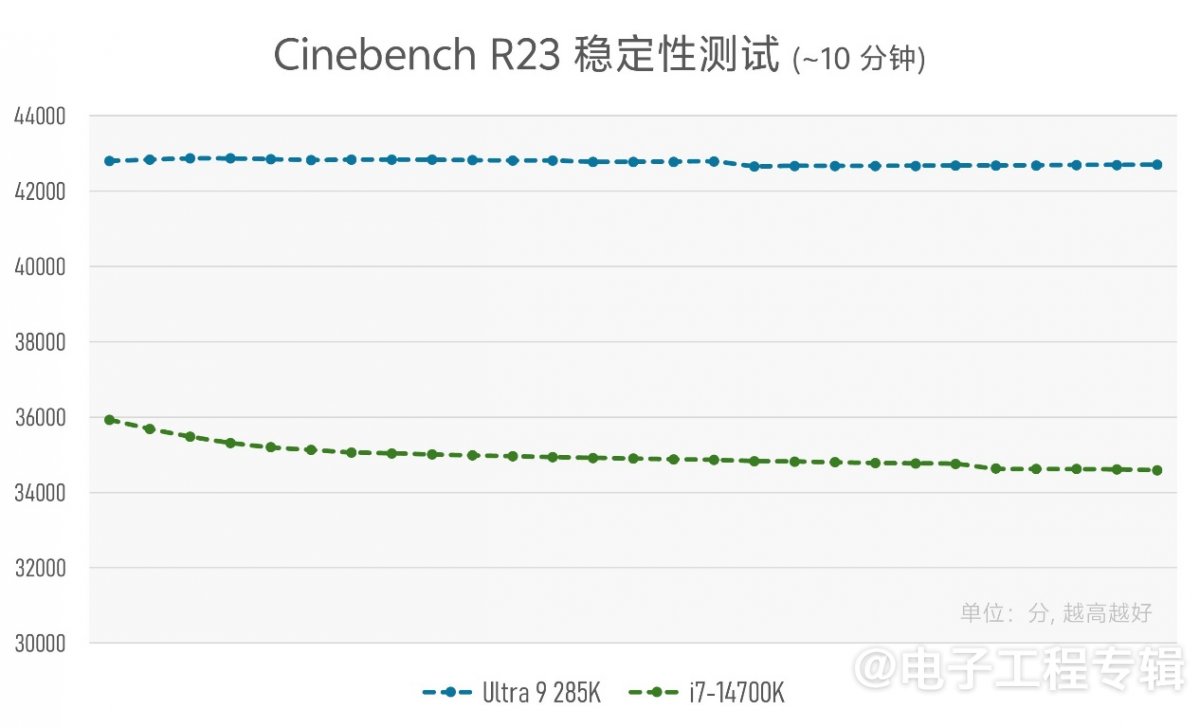
将近30轮的Cinebench R23测试,两个平台的性能稳定性基本符合预期。新平台的240水冷散热还是能够保证稳定的性能吞吐,10分钟内多线程分数基本没什么大变化。不过似乎主要是因为前面提到的,这项测试根本没有达到新平台的温度墙和功耗墙。
而旧平台的双风扇风冷的确存在散热瓶颈,10分钟稳定性测试的最后一轮,其性能得分相当于第一轮的96%——持续性能相比最高性能折损4%,也还算理想吧,毕竟没投入什么成本。
上面这几项测试,基本给出了新旧两个平台的性能发挥稳定性和上限印象。虽然整体比较粗线条,但基于Cinebench R23多线程性能成绩的领先,及CPU封装功耗、温度的变化情况,我们已经大致可以认为,新平台有着更高的效率了。

效率提升了,而且幅度不小
再强调一点:本文的体验和测试仅基于高抽象层级做性能和效率浅析,基本隐藏了核心/线程、异构、存储子系统的吞吐、延迟、指令执行能力等微观层面的信息——这部分内容后续会做针对性更新…
也就是说,我们将酷睿Ultra 9 285K、Ultra 5 245K、酷睿i7-14700K当做整体进行体验与跑分,完全隐藏其核心、频率、线程数情况,测试也以实际负载为主;仅从性能得分、处理器功耗与温度变化来尝试推断某些微观层面的信息。
上述持续性能与压力测试已经能够给出Arrow Lake相较Raptor Lake效率提升的印象。要将这一点具象化,可以固定不同功率点,让两个平台分别再跑Cinebench R23测试,基于结果可以拟合出以下曲线(横轴表示功耗,纵轴表示性能得分):
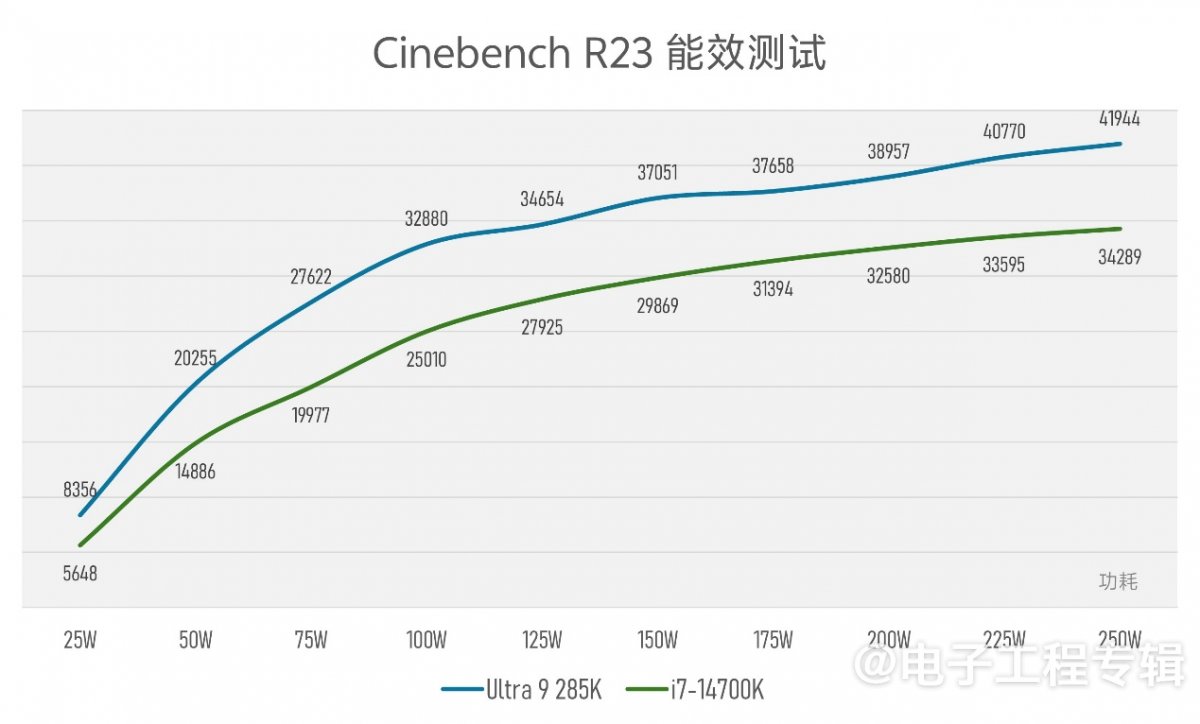
用XTU限定CPU封装功耗,以25W为步进,测试两颗处理器在25W-250W这一区间内的性能变化。全功率区间内,酷睿Ultra 9 285K都保持着领先,也基本表明了效率的提升。
Intel在此前的发布会上说,这一代Arrow Lake在达到与上代Raptor Lake-Refresh相同性能时,功耗低了一半。当时比的主要是酷睿Ultra 9 285K和酷睿i9-14900K。
虽然我们手头没有酷睿i9-14900K,且更多核心的i9-14900K跑到i7-14700K相同功耗时,表现出的性能和电特性不一样;但这项测试也能验证个大概。酷睿i7-14700K在250W达成的性能水平,酷睿Ultra 9 285K的确只需要不到125W功耗就能达成。
还是要提醒一点:从前面的测试可知,酷睿Ultra 9 285K并不需要250W功耗,就基本能在Cinebench R23测试中发挥出全力(或现有工况无法令其达成全力输出);而酷睿i7-14700K是不行的。所以这个测试,前者在250W功率点可能不能表现出其极限性能。
当然了,光是发挥多线程性能的渲染测试并不能全面覆盖所谓的“能效”提升诸场景。所以我们也做了Office办公、Premiere Pro视频创作,与《黑神话:悟空》游戏这三个场景的能效测试。
因为这些测试很难简单限定两个平台达到相同性能,且双方存在散热等各方面的变量,所以我们的测试方法是限定双方的CPU封装功耗为150W,记录测试全程的CPU封装功耗变化,绘制成曲线(横轴表示时间,纵轴表示功耗):
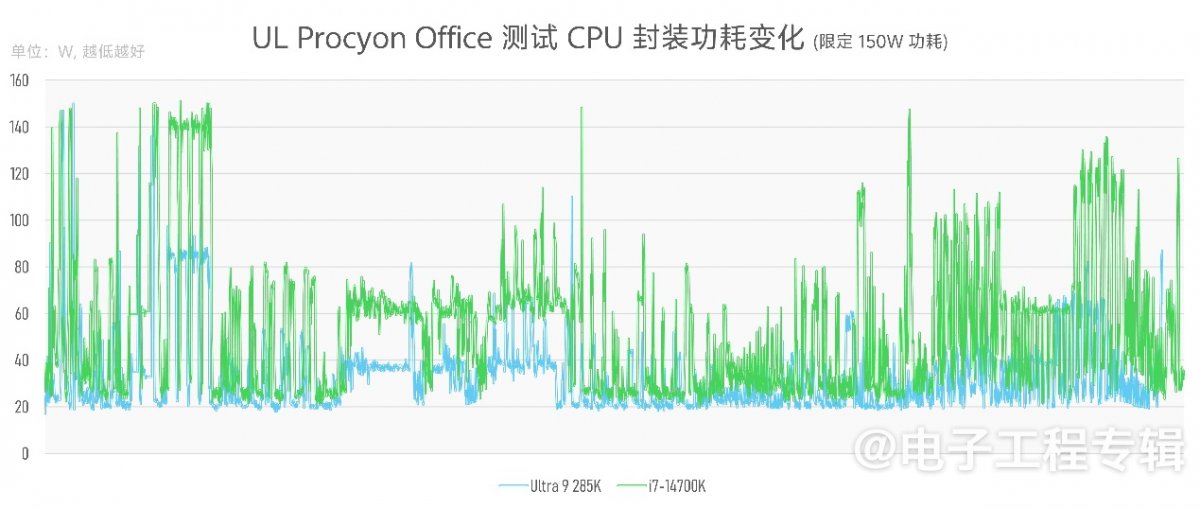
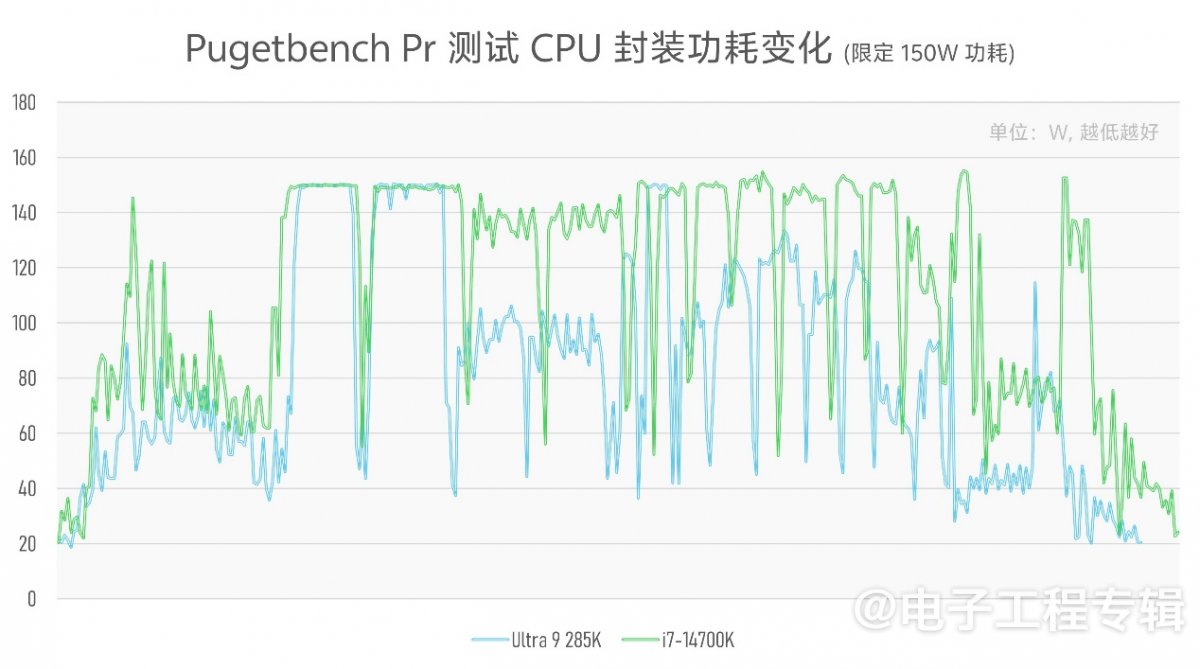
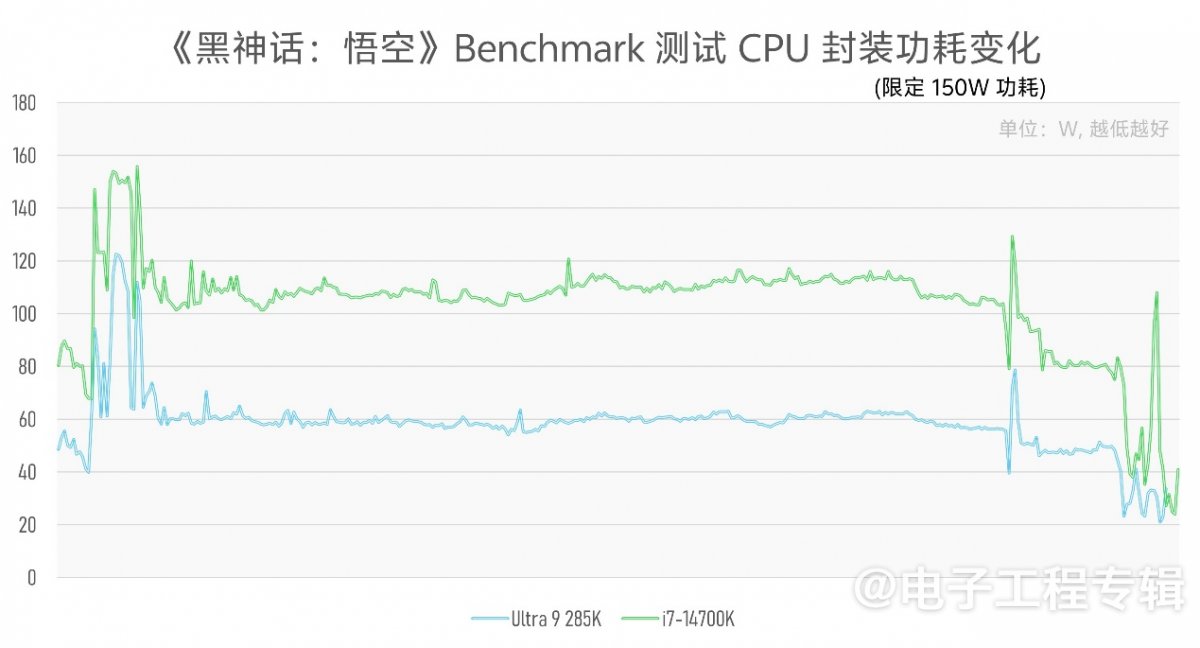
不用管那么多弯弯绕绕都是在跑些啥——无非也就是像Office中的Excel表格、PR中不同视频格式的编解码…其中蓝线代表酷睿Ultra 9 285K的CPU封装功耗变化,在几乎所有场景下都表现出了相较上代显著的功耗下降:某些特定负载下刚好也是低一半的功耗。
这些测试实际上还有个关键变量没有反映到图中,即性能。因为我们很难在基准测试前就限定两个平台达到相同性能,所以只能选择限定功耗上限。不过在限定功耗上限以后,这三项测试中,双方的性能成绩的确相差不大(UL Procyon Office测试成绩7837 vs 7622;Pugetbench Premiere Pro测试成绩13526 vs 13258)。
尤其《黑神话:悟空》,1080p高画质下,双方跑到的平均帧率都是96fps。且需要注意,酷睿Ultra 9 285K测试全程没有在任何时间点碰到过150W这一人为设定的功耗上限(这也决定了限定或不限定功耗,基本对该游戏测试结果没有影响)。最终可给出不那么严谨的、这三项测试全程的平均功耗对比:
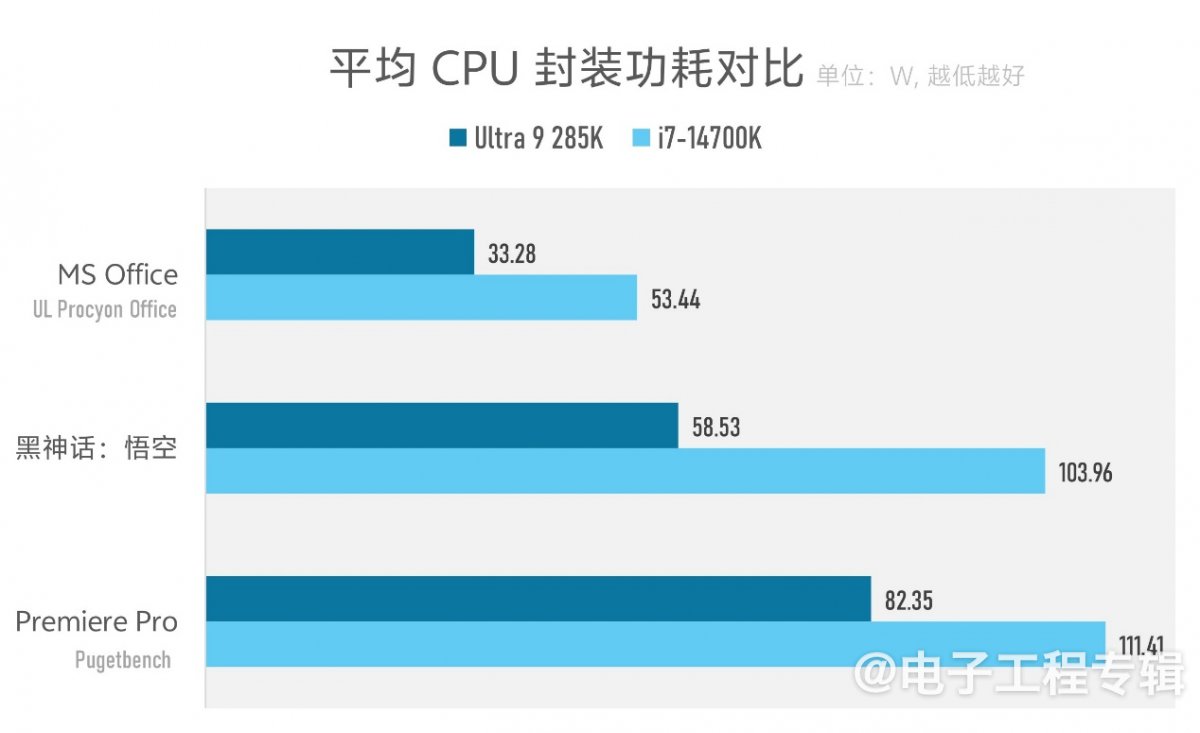
* 注意该对比不严谨,仅供参考
此外,Intel在宣传中提过Arrow Lake在不同负载下的处理器发热更低。这一点我们无法给出明确结果,因为新旧两个平台的散热方案是不一样的。
不过从系统角度还是可以看看,两个平台在三项测试下的CPU封装温度差异,全当图一乐,供各位参考——毕竟这些数据糅合了新处理器更好的发热表现,及水冷与风冷的散热差异:

* 注意该对比不严谨,仅供参考
这么看来,Arrow Lake-S更环保、更节能(或者说我们的新平台比旧平台更环保、更节能)是板上钉钉的:也就是更低的温度和功耗。
除了将对应系统级芯片架构搬到Arrow Lake-H笔记本平台上会很有价值之外,很多人评价说台式机处理器并不需要追求低功耗和高能效,毕竟谁用台式机玩个游戏还会在意那点电费呢?
或许从更高维度来看,如文首所述,这一代台式机处理器的设计受到了笔记本低功耗平台,以及数据中心低功耗高能效强烈需求的影响,而表现出了Arrow Lake在台式机平台上如今的偏向性。毕竟Intel面向的客户群体和需求比较多样。
PC个人用户可能的确不会在意那点功耗下降和能效提升,但对Intel整体布局或许有价值;或者也可能对未来架构给出性能提升空间有帮助。后文的游戏测试环节,会就此话题做更进一步的探讨。

综合性能提升了,但有个槽点
以往各代Intel处理器体验的主菜一般都是更高的频率、更高的性能,这次也居于能效提升之后了。不过从微观层面来看,Arrow Lake也是以更低的线程数、核心频率、显著提升的E-core效率与性能,来尝试在系统性能上超越前代。在绝大部分测试中,这一点还是确实的:
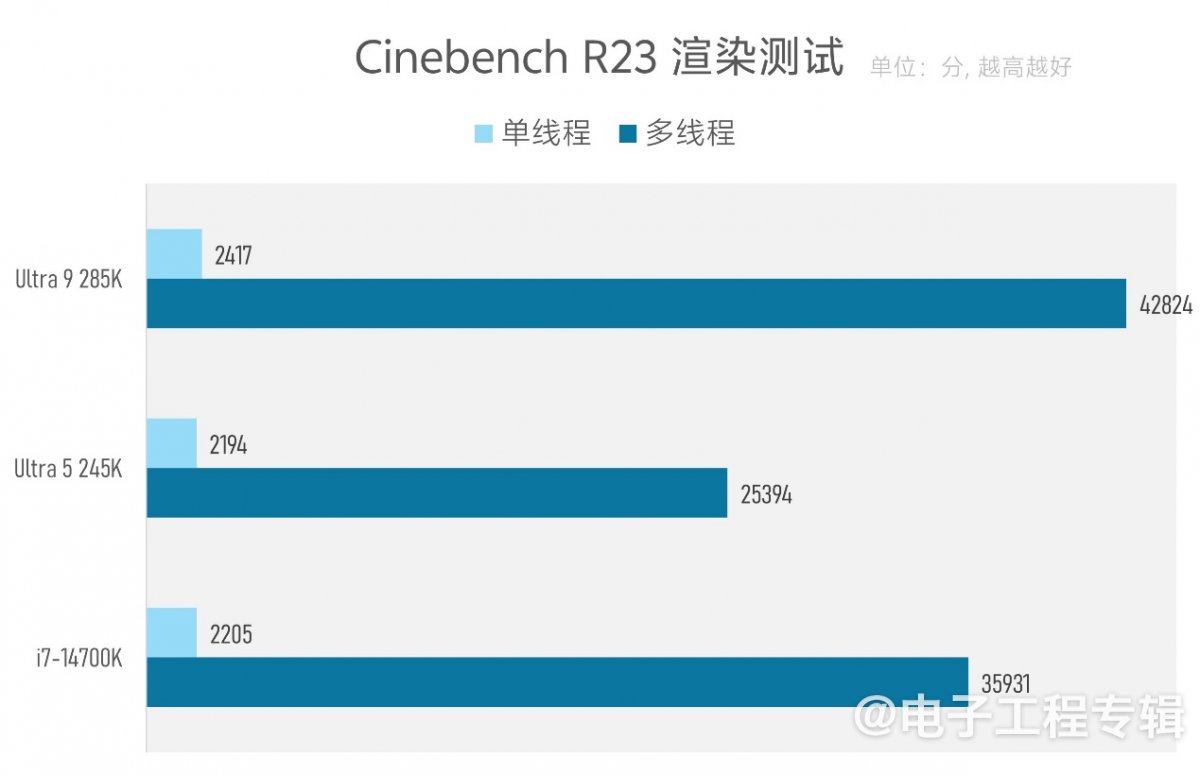
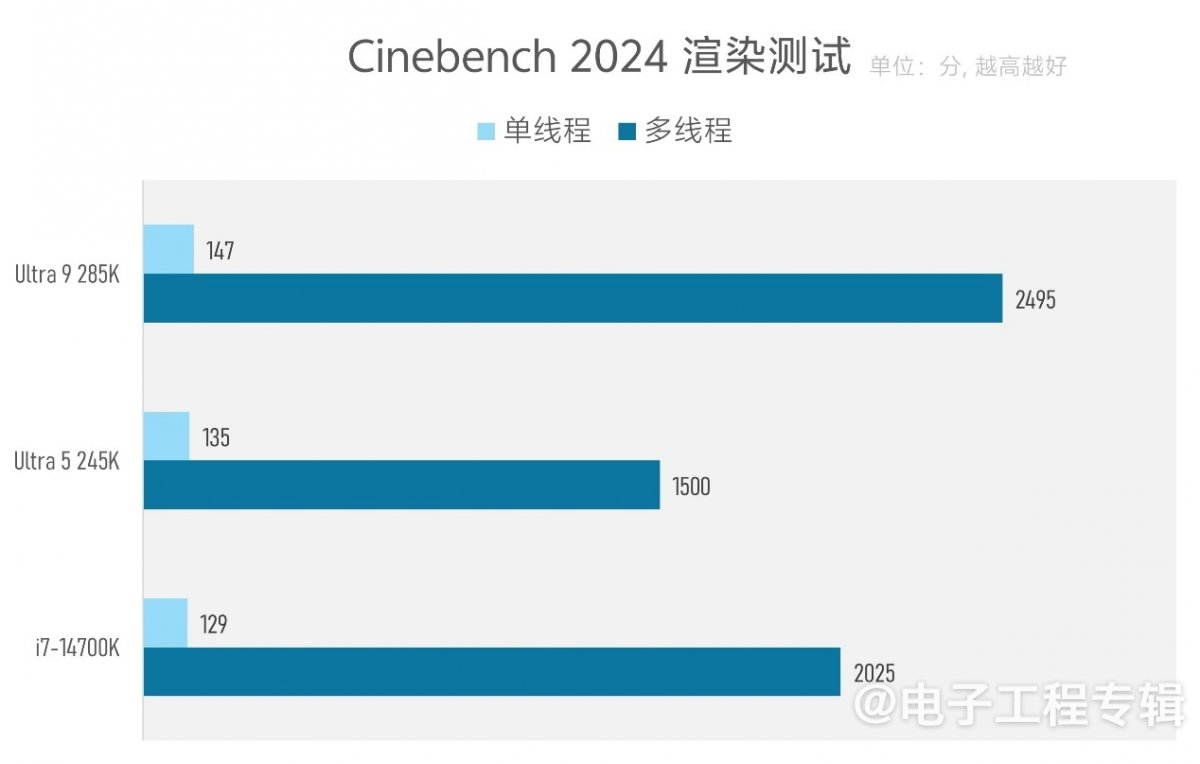
从Cinebench渲染测试结果来看,除了对比的两代处理器相近频率下,Arrow Lake获得更高的单线程性能(提升9%-14%);Arrow Lake在更少线程(24线程 vs 28线程)的情况下,也能获得多线程性能大约20%的领先(注意这里比的是Ultra 9和i7),可见用小核替代超线程还是正确的。
相比Cinebench,常被同时拿来对比测试的是Geekbench。实际上,Geekbench和Cinebench的测试覆盖类型差别是比较大的。后者的测试时间虽然也不长,且给出了单线程和多线程两个性能成绩,但它测的子项代表了不同类型的真实负载,如网页浏览、文件压缩、代码编译等。
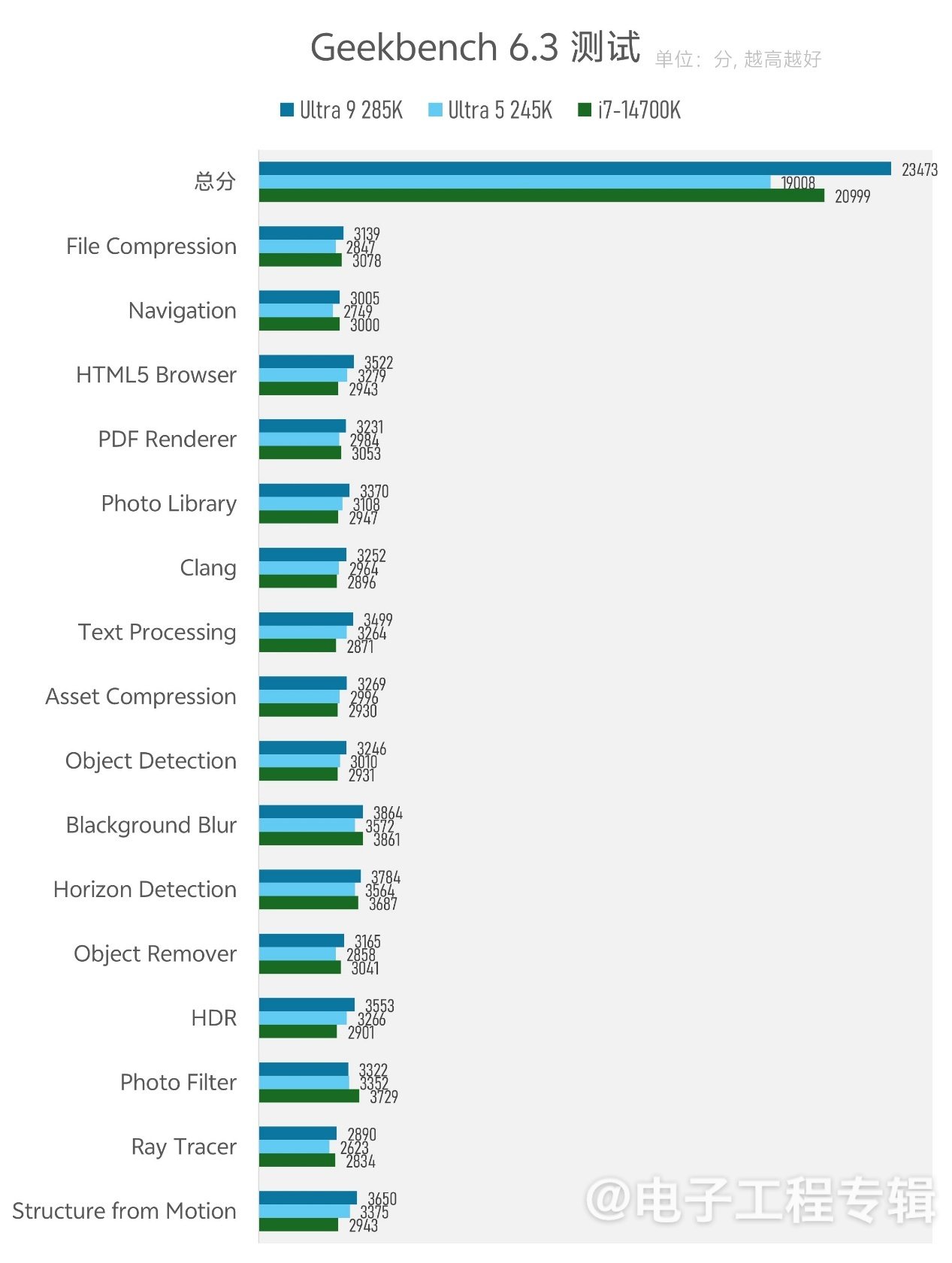
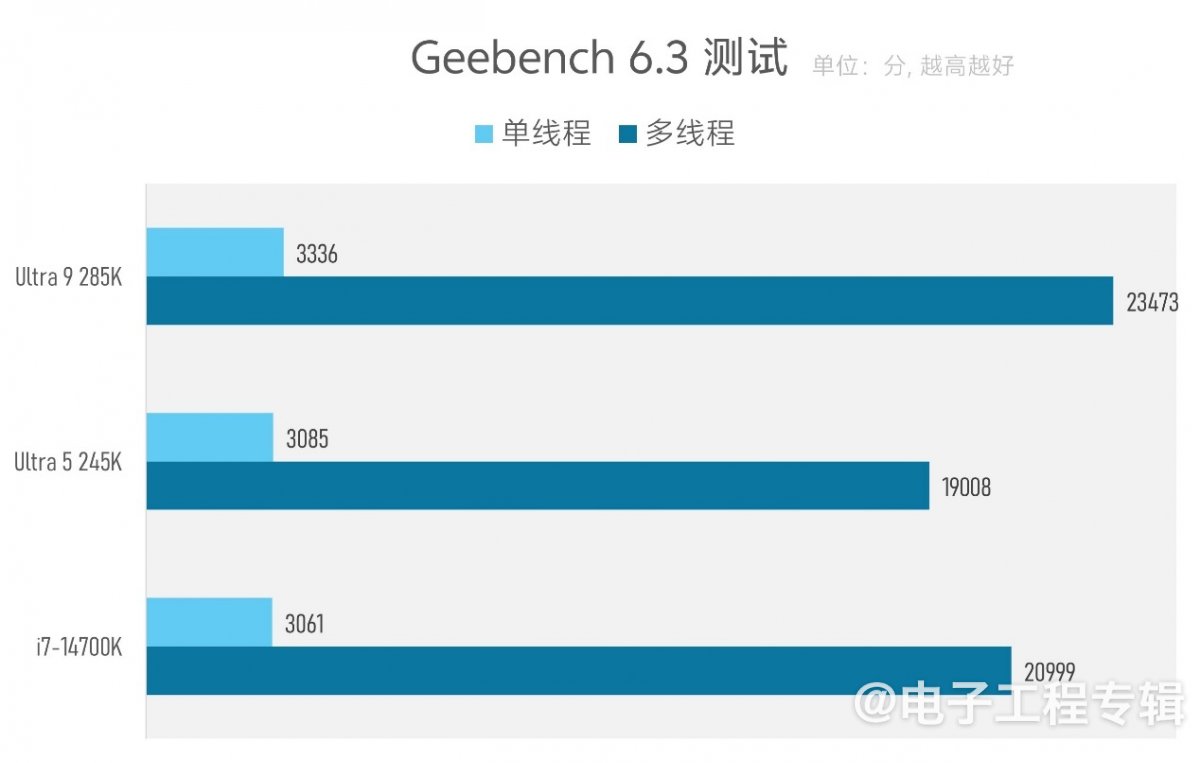
所以其参考价值就普通PC用户会更大。不过因为Geekbench测试时间短,任何子项若只追求突发性能,对旧平台也会更有利;而且理论上它应当更加不受制于内存性能。在这项系统性能测试下,双方单线程性能差距约9%;系统性能差距在12%上下。
接下来按照常规,基于PC三大主要使用场景:办公、媒体创作、游戏进行真实负载的分项测试。这些测试考验的就完全是系统整体了,包括对独显加速的调用。系统层面的性能差异,也就不会像Cinebench这样的渲染测试表现出来的进步那么大:
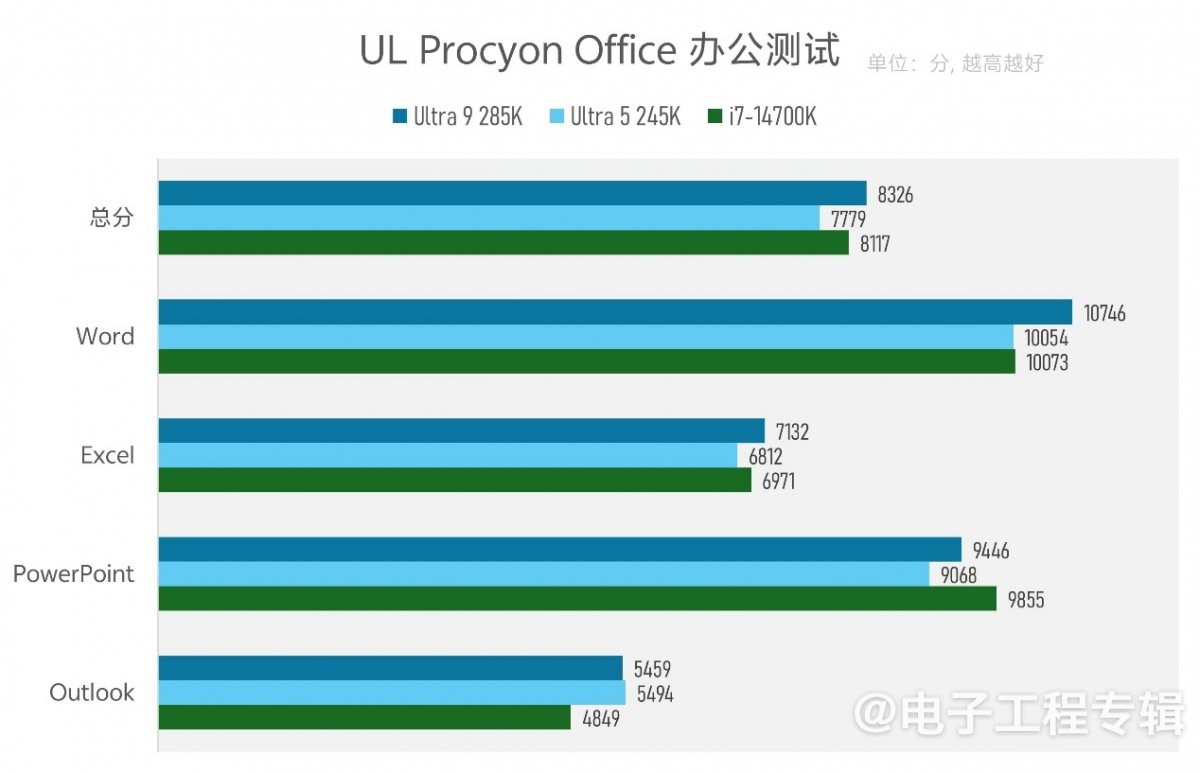
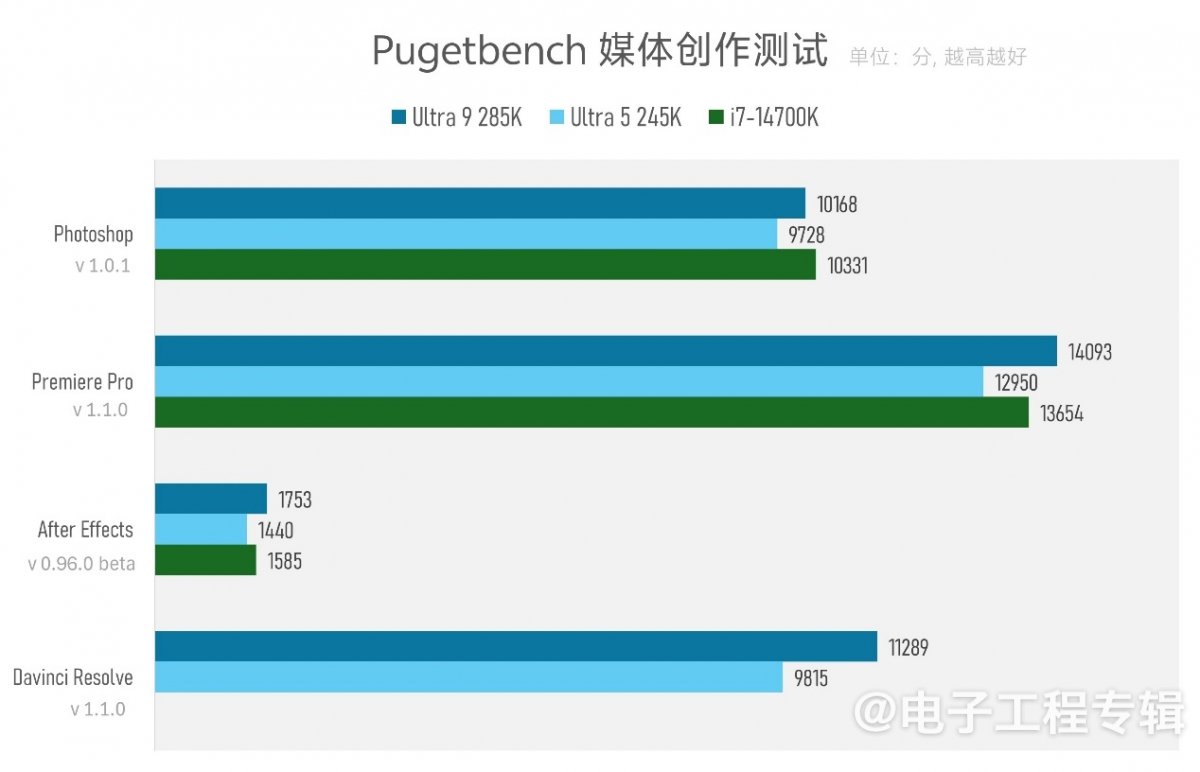
值得一提的是,Pugetbench的Davinci测试,对新版Davinci似乎存在兼容性问题,我们的旧平台没能顺利跑通测试流程,故该项缺失。
而且因为我们用免费版Davinci Resolve软件做测试,测试的HEVC编解码加速项无法获得GPU加速,OpenFX和AI特性也受限,所以该得分不能与其他来源的测试结果直接比较。
这里的Premiere Pro测试对视频编辑的各方各面都有参考价值。Pugetbench的Pr测试主要涵盖重负荷的媒体软硬件编码、不同格式与分辨率的媒体解码输出,以及GPU加速的视频特效。理论上这是个考验系统硬件加速媒体引擎、CPU软解软编,以及GPU通用加速能力的测试。
酷睿Ultra 9 285K在AE(After Effects)测试中的优势也主要在CPU多核得分上——多核得分子项的领先达到了17%。
有些令人意外的是,比较注重单核性能的Photoshop测试里,旧平台略胜新平台。可能与新平台因为软件尚未完全就绪,当前仍不能全力发挥性能有关;也可能是这项测试一定程度倚重内存性能,虽然此处没有给出微观性能成绩,但Arrow Lake的确存在内存延迟高于Raptor Lake的问题。
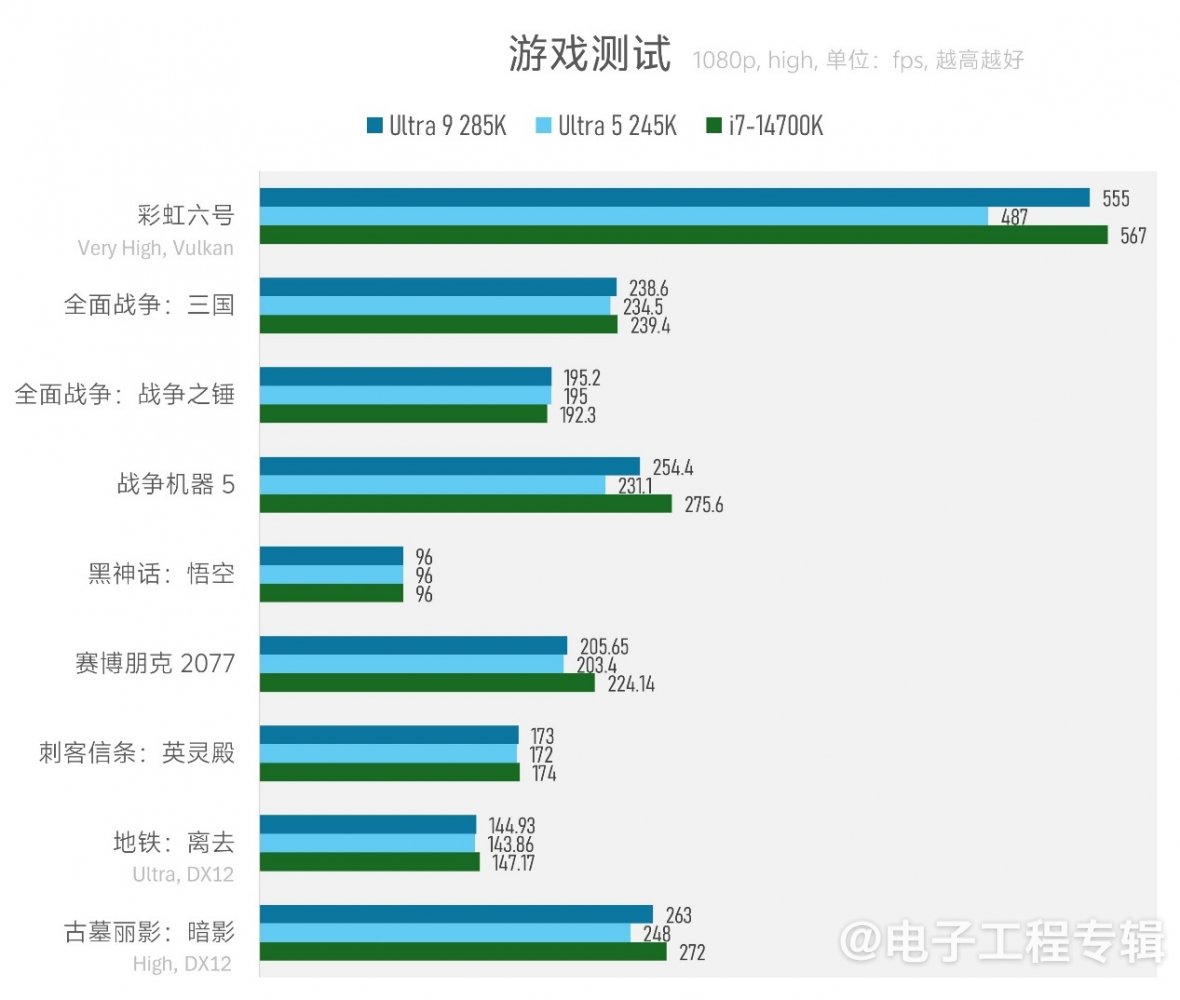
最后是游戏测试,全部测试皆不开启AI超分和帧生成。且为尽可能避免GPU瓶颈,测试选择了1080p高画质(非画质设定最高档,通常高画质是3A游戏设定中的第三档)。多插一句:抛开VRAM容量和带宽给料不谈,老黄这一代RTX 4070 Super在很多场景下是可以比肩上一代3090的。
游戏测试的结果不及其他测试理想。除了《黑神话:悟空》这样即便选择“高画质”也依旧明显存在GPU瓶颈的游戏,在我们测试的绝大部分游戏里,新平台似乎都不及旧平台的帧数高——差距可以拉大到20fps(差距最多9%左右)。但还是需要注意,用户在真的玩游戏时,会拉高画质和分辨率,则这样的差距会被显著弥合——这种测试通常不代表实际体验。
我们的游戏测试样本量一向不大,所以并不能代表综合游戏性能变化(比如看到有媒体测试《地平线:西之绝境》《星空(Starfield)》《地狱之刃2:塞娜的传说(Hellblade2: Senua' Saga)》等游戏,Arrow Lake性能就优于Raptor Lake)。
但自Arrow Lake-S发布以来,网上有关这代处理器游戏性能“不行”的讨论就相当热烈。有说游戏打补丁能提升帧率的,有说操作系统版本对游戏性能存在影响的,也有说Windows的CPU线程调度策略尚不完善(所以仅用某些核心簇据说会大幅提升游戏帧率)…
基于现有变量能够对游戏性能产生影响的事实,我们基本可以认为,现在与Arrow Lake搭配的硬软件平台或环境的确还不够成熟。未来几个月内,我们猜测Arrow Lake-S还有进一步的性能优化空间,尤其是Intel在软件方面的调试推进。这代产品还是上得匆忙了点儿。
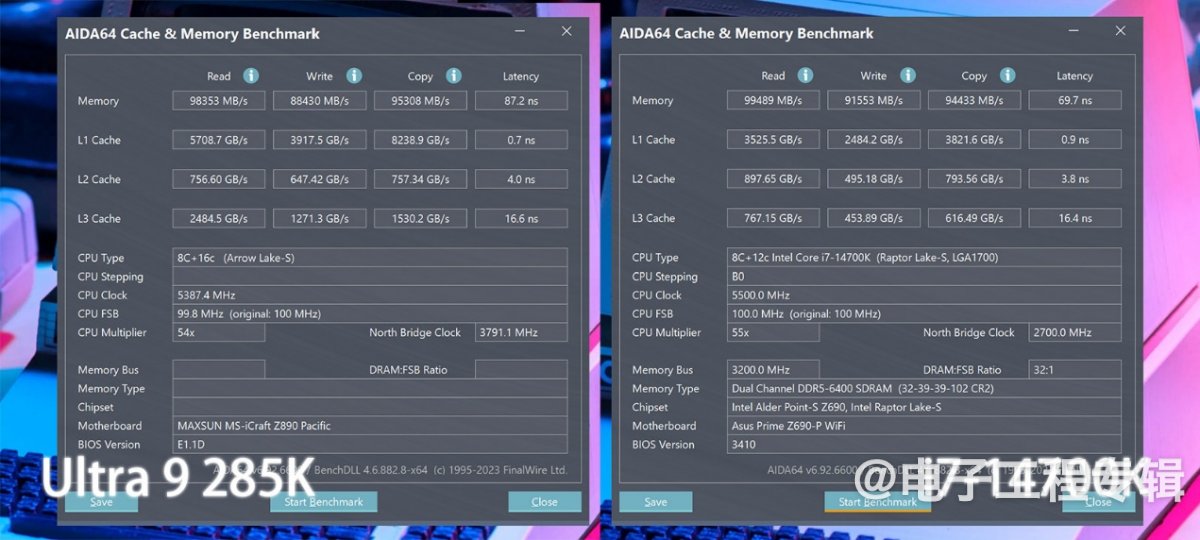
从硬件层面看,我们认为游戏性能不及预期,相对靠谱的解释是内存延迟的增加,及其背后原因:内存控制器与CPU核心不在一片die上,die间互联的延迟造成影响。所以此处也简单插播AIDA64的一条micro-benchmark,可见两者在同样用6400 MT/s内存情况下的访存延迟差异。
Intel在Arrow Lake的超频特性中给出了tile-2-tile & fabric overclock选项——配合更高规格的内存,的确算得上是改善内存延迟的思路;即便从极客湾的测试来看,这些方案也并不能令Arrow Lake的这一弱势达成彻底逆转。
有关游戏性能,谈一点我们的看法。Arrow Lake的游戏性能一方面并没有网上传言得那么不堪——还要考虑针对CPU游戏测试在大部分情况下不能反映实际体验这一点;另一方面,前文我们也给出了《黑神话:悟空》游戏测试全程的功耗曲线,Arrow Lake是在大幅降低CPU功耗的情况下,拿下了相似的性能;更何况还是应当看到除游戏外,其他大部分应用场景的性能提升。
不过迭代产品的游戏性能不及预期的确是个槽点。从产品角度来看,Intel从酷睿14代转向酷睿Ultra 200S,是其初次为台式机CPU——尤其面向发烧友,用上基于chiplet的2.5D/3D先进封装方案,探索期的坑多少还是要踩的。
从Meteor Lake时期,我们就提过,PC处理器走向2.5D/3D先进封装的成效会在后续产品中逐渐显现——尤其是Intel这种非对称的chiplet方案;即便可能初期的几代产品要遭遇一些波折,这也是必由之路。
而且从相对高能耗的酷睿14代,重启思路与设计,走向高能效与更低的功耗,同样是Intel的必由之路,这一步迟早都是要走的。如此,产品和技术未来才有持续进步的空间。并不像很多人说的那样,台式机不需要在意功耗,那只会让产品走向死胡同。
不过在此还是想重复一个猜想:基于大部分半导体企业现如今一个架构设计覆盖多场景的基本思路,从Intel的整体产品策略来看,或许这代Arrow Lake-S的权重并不怎么高;至少它可能远不及数据中心和笔记本产品线。这可能是Arrow Lake-S所有外在表现的底层逻辑。

普及AI PC,从加入NPU开始
最后,有关AI PC的性能变化也是不得不谈的,毕竟Intel赋予Arrow Lake的使命是加速AI PC普及,将AI PC这一概念带到台式机及更多价位段的笔记本产品中。
Arrow Lake-S的标称AI总算力36TOPS(CPU 15TOPS, GPU 8 TOPS, NPU 13TOPS),这是个显著高于Raptor Lake-S的值:不仅因为新增的NPU,也在于iGPU核显规模的成倍扩增。
我们简单跑了几个AI测试。注意这些测试仅针对Arrow Lake-S处理器,包括其上的CPU, iGPU和NPU,而完全没有选择独显加速(有关台式机AI PC为何需要NPU的逻辑,此前的文章已经做过解释)。推理引擎全部选择了OpenVINO,因为它相较WinML/ONNX在性能上有着显著优势。

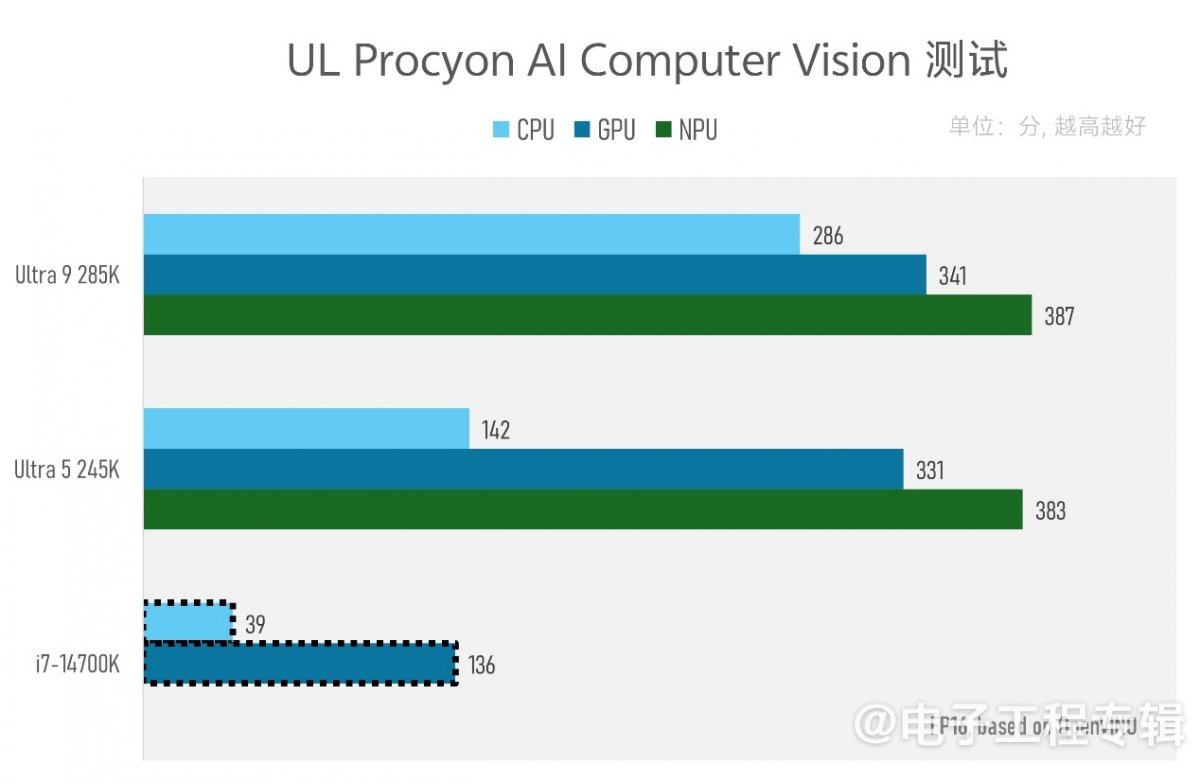
Geekbench AI的测试项目还是比较多,只不过主要集中在CV方面。其测试子项包括图像分类、语义分割、姿势估测、对象检测、面部检测、图像超分等。基于不同精度,按照不同的处理器类型,给出最终成绩如上图。
这里我们不打算细究得分详情,Arrow Lake相较Raptor Lake的AI性能显著提升还是一目了然的。只是跑分结果不像Intel给的INT8标称值,这和软件及芯片系统架构应该有很大关系。
前几个月,Chips and Cheese对Intel的NPU 3做过micro-benchmark,其理论算力受制于和CPU的交互、不同matrix size、内存带宽等因素;CPU本身有响应延迟优势,GPU则有功耗预算、更快的cache等资源——而且这两者也有着更好的编程灵活性;所以结果呈现出差异性是很好理解的…
UL Procyon的AI推理测试现在分成了CV计算机视觉与Stable Diffusion文生图两大类。CV部分,跑了几个模型:MobileNet V3, ResNet50, YOLO V3等;我们仅选择基于FP16数据类型来跑测试。
需要注意的是,此处酷睿i7-14700K的得分是明显偏低的(可能偏离至少1倍);但跑了很多次,仍是这个结果,可能是软件bug,故该结果仅供参考。只不过即便令其得分+100%,相较新平台也仍有差距。除了iGPU规模不同,CPU的AI性能差距可能是来自指令集方面的差异(虽然好像Raptor Lake也有VNNI之类的指令扩展)。
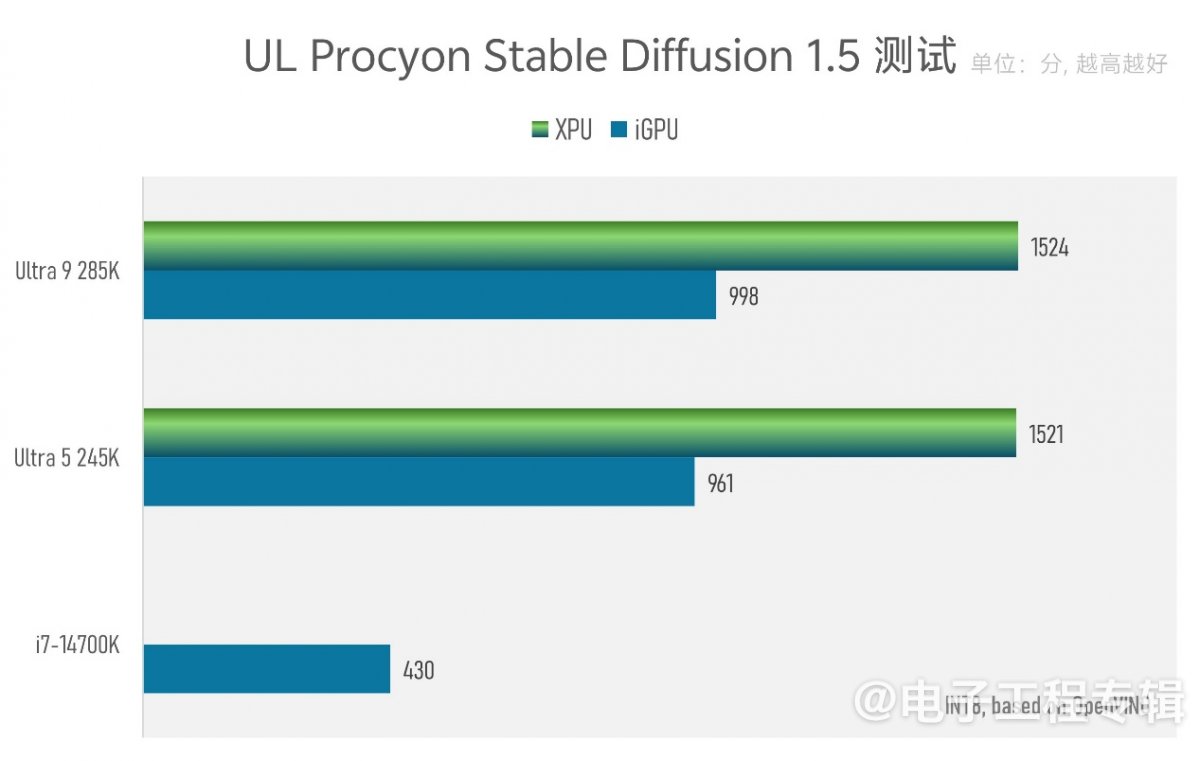
最后是Stable Diffusion 1.5生图测试。在新平台上,这项测试可以选择仅用iGPU来跑,或者选择“Intel AI Boost”选项——OpenVINO会在NPU上跑UNET迭代,而VAE和text encoder是放在iGPU上跑的,也算是个XPU方案了。
酷睿Ultra 9 285K如果用XPU来跑,综合生图速度为20.5秒/张,平均UNET迭代速度2.551 it/s;Ultra 5因为有着相同的iGPU和NPU,只不过频率稍低,所以结果也差不多;酷睿i7-14700K差得就比较远了,它没有NPU加速,所以只有规模仅一半的iGPU支撑。其生图速度为72.6秒/张,UNET速度0.712 it/s。
从这个测试也不难看出,AI PC时代的生态话语权可能未必在操作系统厂商手上——现在能和芯片直接对话,而非通过通用抽象层,是效率和体验提升的关键。

重启台式机处理器的新开端
我们对Arrow Lake-S处理器的评价是积极和正面的:Arrow Lake-S虽然在游戏性能上未能达到预期,但其他绝大部分负载的综合性能仍然是有提升的;AI性能更是显著增长;更重要的是,它大幅降低了几乎所有日常工作负载的功耗,这对酷睿Ultra未来的产品与技术升级意义很大。
就像前文提到的,降低功耗、提升能效是酷睿/酷睿Ultra系列处理器的必由之路——并不像很多人所说台式机处理器能效不重要;chiplet和2.5D/3D先进封装技术也是PC处理器的必经之路。
当下做好技术布局,都会持续产生越来越积极的效果,并在未来持续发挥作用,即便在此过程中面临着各种挑战。而且或许这一思路最初诞生,并不是专为台式机处理器准备的;毕竟数据中心、笔记本也需要用到相同的技术成果。

