
随着近年来人工智能大模型的兴起,关于具身智能(Embodied Intelligence)的讨论再度火爆起来。所谓具身智能,就是各类自主智能系统,包括无人机、无人车,也包括未来应用更为广泛的各类移动机器人。
具身智能并不是一个全新的概念,早在1950年,图灵在他的论文《Computing Machinery and Intelligence》中就提到了这种机器,即一种能够像人类一样与环境互动、感知、自主规划、决策并执行任务的机器人或仿真人,是AI的终极形态。根据今年CVPR Workshop的定义,具身智能的目标是构建一种智能体(如机器人),能够学习创造性地解决需要与环境交互的挑战性任务。


传统的机器人只能执行规划好的任务,比如扫地机器人,它只能在家里执行预定好的扫地任务;送餐机器人只能在餐厅按照规划好的路径,执行简单的送盘子、打开舱门任务。而具身智能机器人不仅能够在受限环境中执行预设任务,还能在开放环境中处理未定义的任务,并通过与环境的交互不断学习,提升自身的智能水平。
这标志着从特定任务机器人向通用机器人的转变,尽管距离真正的通用机器人还有很长的路要走,但具身智能无疑是实现这一目标的“最后一块拼图”。
在2024中国集成电路设计创新大会暨第四届IC应用展(ICDIA 2024)上,西安交通大学人工智能学院副院长孙宏滨带来了题为《迈向具身智能计算系统之路——算法与架构协同创新》的精彩报告。本次报告深入探讨了具身智能计算系统的发展趋势,特别是在算法与架构层面的创新路径。

西安交通大学人工智能学院副院长孙宏滨
三种大模型嵌入范式
为实现具身智能,孙宏滨教授提出了多种可能的技术途径,一个显著的趋势是机器人和大模型结合。大模型有着与人类似的常识和推理能力,在没有大模型的年代,及其人单纯靠数据驱动;有了大模型,我们不仅可以从环境中积累数据,还可以利用以往的知识把嵌入到机械模型中,使机器人具备推理能力,从而迈向具身智能。
其中在算法层面,有三种将大模型嵌入机器人的主要范式:单模块端到端、多模块端到端和混合AI系统。
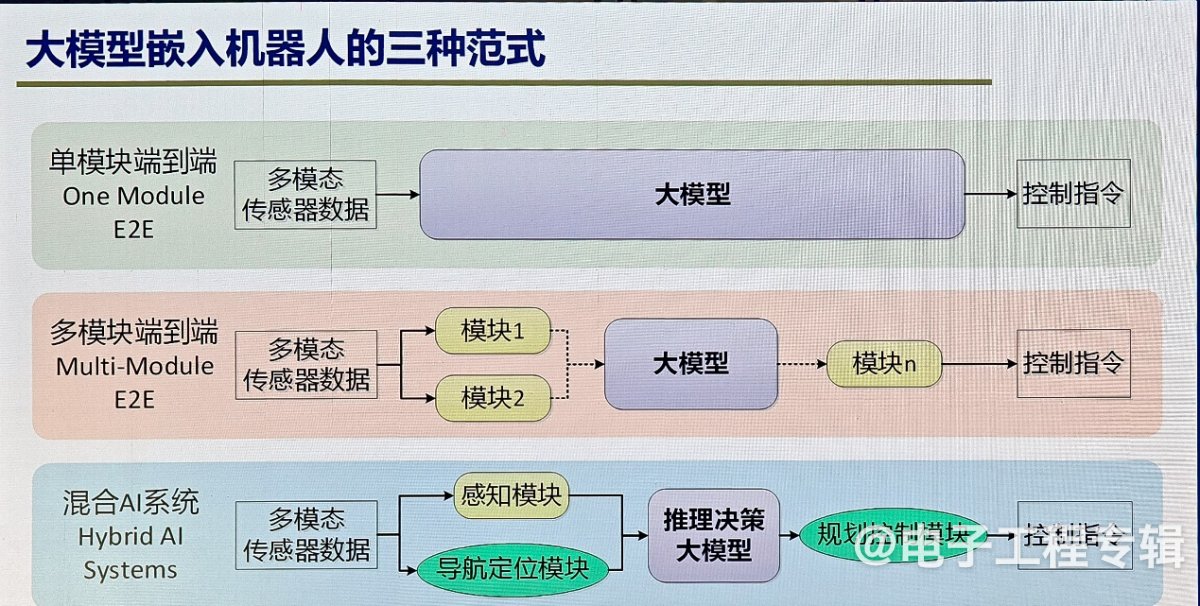
所谓单模块端到端,以自动驾驶为例,即用一个大模型,输入是摄像头、激光雷达等,输出是控制刹车和油门的指令,构建一个规模足够大、足够复杂的模型,它能拟合我们所有想要实现的智能任务,要实现这个想法极具挑战性。而多模块端到端,是将感知、决策、规划等任务分成多个模块,但每个模块都是由数据驱动的深度学习来实现的。
前两种范式虽然在系统联合优化和避免级联误差方面具有优势,但完全依赖数据驱动的方法导致模型冗余、不可解释且难以维护。今天之所以大部分厂家在宣传采用这样的技术路线,原因是之前的神经网络经历了模型性能与泛化能力随着数据规模、模型规模和算力增长而不断增长阶段。以至于大家今天有这样的信心和期望,可以用更大规模模型来实现更好的智能,最终达到人的认知和决策能力。
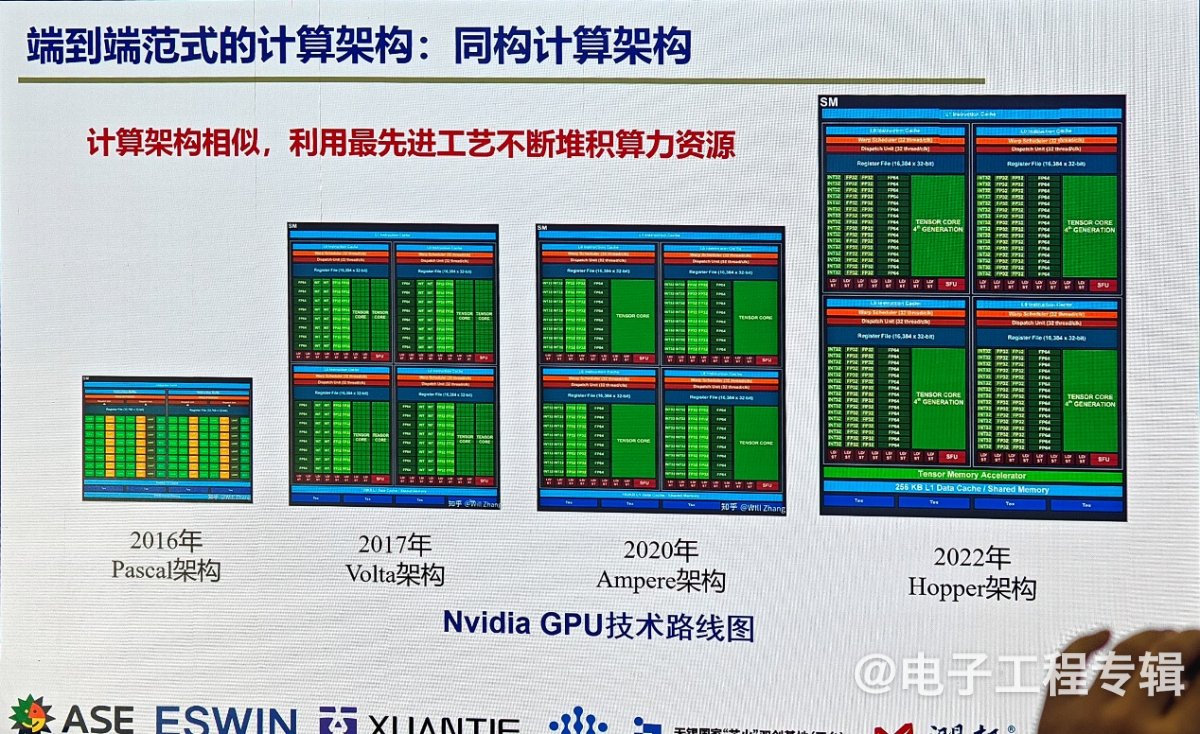
“这种路线的缺陷是模型不可解释,结果不可控,很难更新维护,而且模型训练和推理效率低,按照当前发展趋势看,算力耗费和代价极大。” 孙宏滨说到,如果未来算法级是端到端模式,那我们对架构的需求就是今天英伟达采用的同构计算架构,这种架构多年来的变化已经不大,只是用最先进的工艺把芯片面积做得更大,实现更高算力。
混合AI范式的崛起
相比之下,混合AI系统通过结合多种AI方法,包括深度学习和非深度学习方法,实现了更为可预测、可控、可解释和可信任的智能系统。
混合AI系统的优势在于其灵活性和高效性。通过将不同的智能组件组合在一起,混合AI系统可以在不同的任务中发挥各自的优势,从而更好地应对复杂多变的环境。
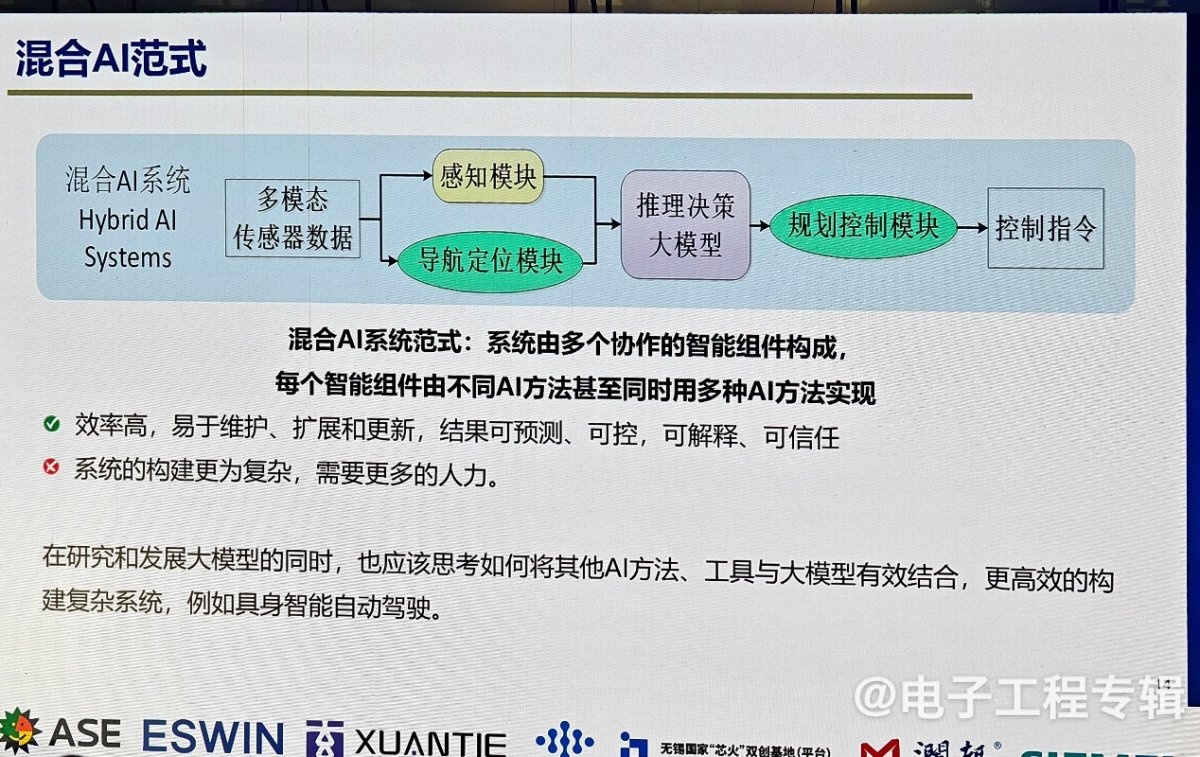
孙宏滨强调,未来的具身智能系统不应仅仅依赖单一的大模型,而是应积极探索混合AI范式,将大模型与其他方法相结合,构建更为高效的智能系统。
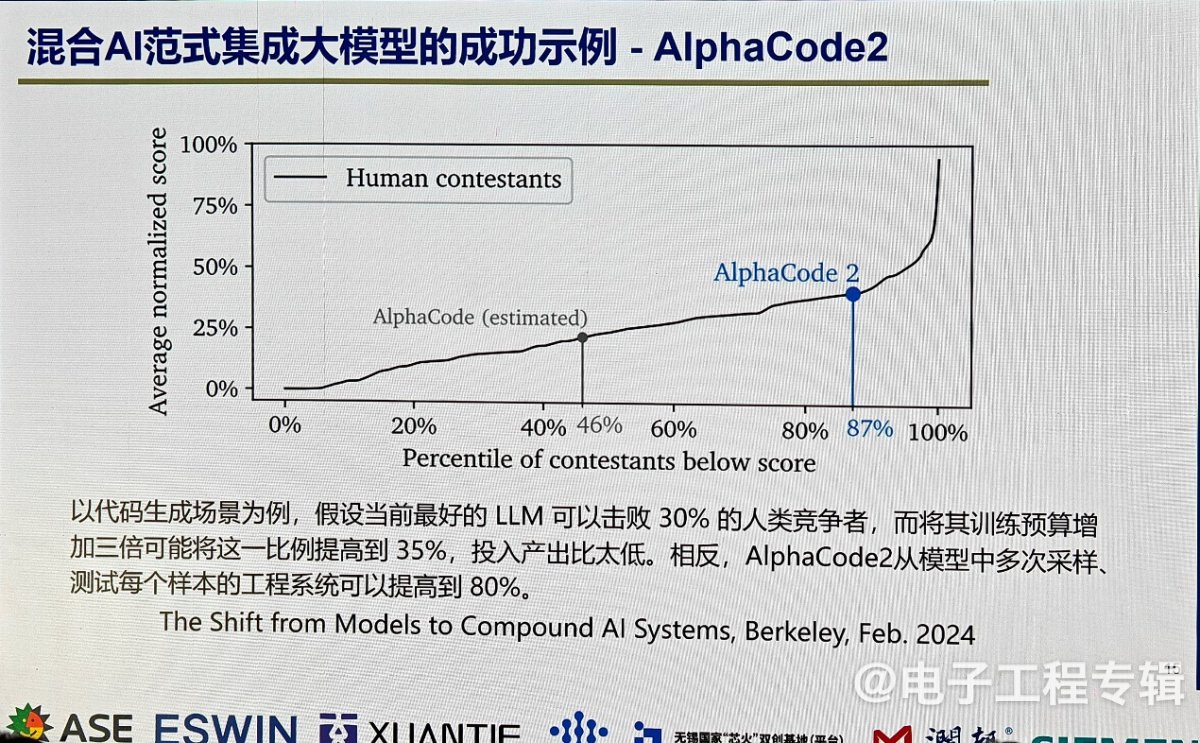
这种想法在今年年初已经初见端倪,在大家都热衷地追求大模型时,伯克利大学(UC Berkeley)以AlphaCode2为例发表了一篇文章。AlphaCode第一代是自动编程软件,能自动生成计算机软件代码,当时参加了计算机编程大赛,打败了30%的人类参赛选手。最早这款模型是希望用增加数据、增加模型规模的方式,使程序代码规模和质量继续提升,但是发现将其训练预算增加三倍后,只将代码规模和质量提高了35%。相反,AlphaCode2从模型中多次采样、测试每个样本的工程系统可以提高到80% 。因此很多学者认为,未来人类对于复杂智能系统构建,更可能是一种多手段、多元混合的,而不是单一的大模型。
“以今天的自动驾驶为例,虽然大模型表现出了非常好的智能能力,但有很多问题不是单一大模型能解决的。” 孙宏滨举例道,一类是对Worst Case敏感的问题,模型结果往往不可控,下限未知;另一类是能确定性建模描述的问题,再用黑盒子方式逼近,它的计算代价大,鲁棒性也会更差。“自动驾驶也好,无人机也好,更希望有混合AI这样的高效模式。我们认为未来的混合AI范式,非深度学习方法可能比当前的深度学习方法效率更高。”
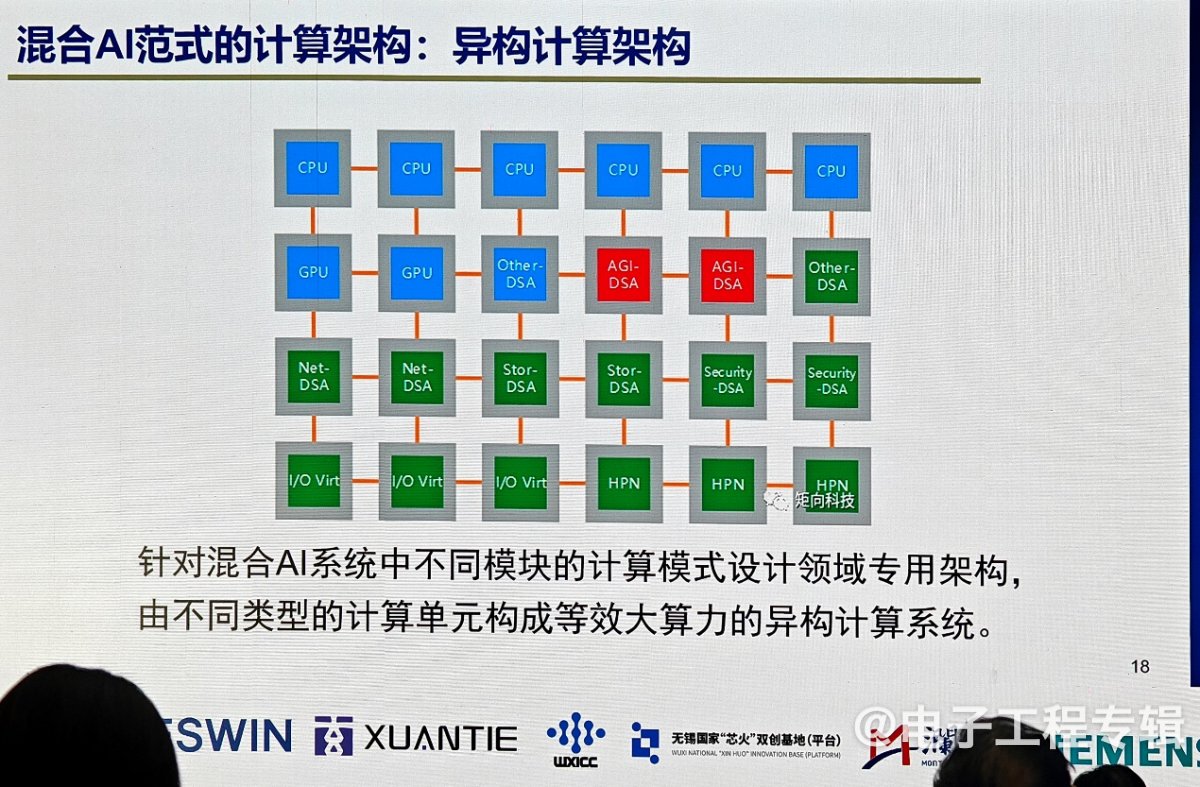
自主芯片挑战,如何摆脱英伟达依赖?
当前,自主智能系统(如无人机、无人车和移动机器人)已成为推动芯片技术发展的新动力。从系统整机产业看,我国在市场上的优势非常明显,无论是新能源汽车的智驾功能,还是消费级、工业级和军用无人机,以及机器人市场规模,都在急剧增长。
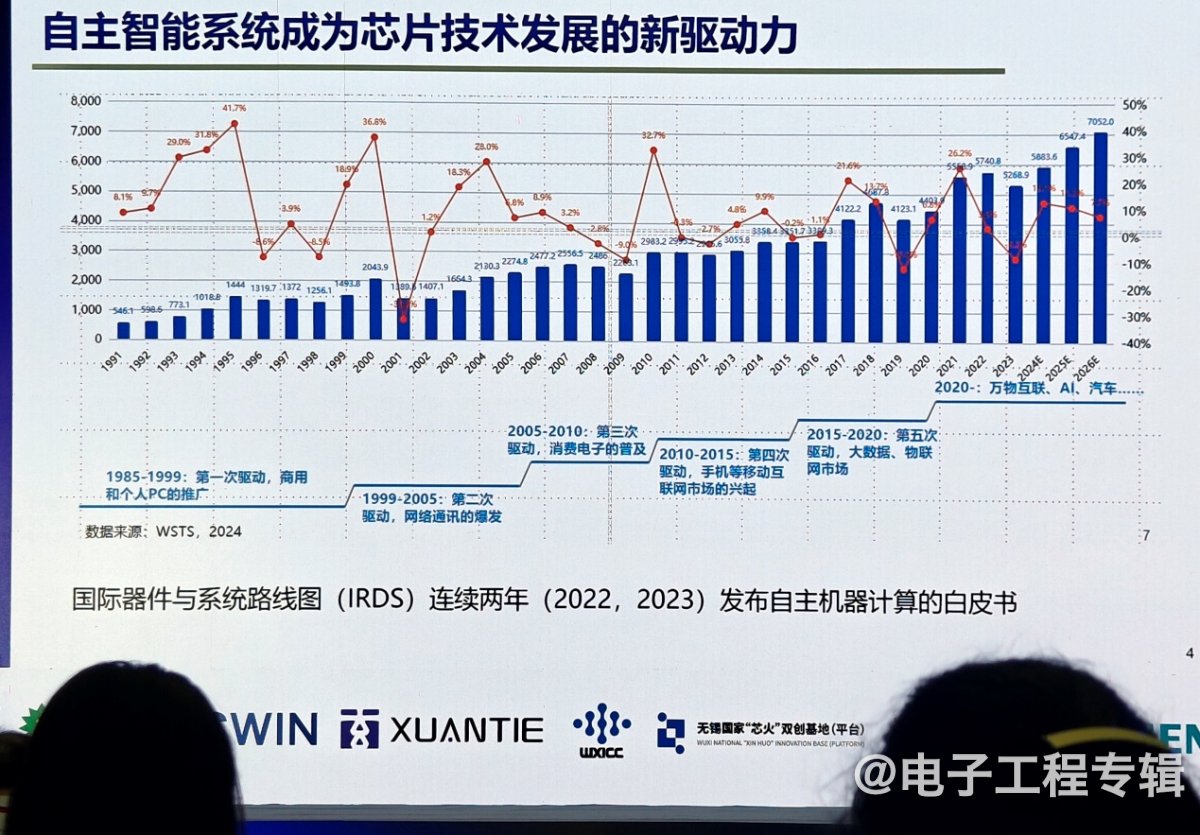
但如果看这些自主智能系统中的芯片,它们可能还像以前家电、手机、PC中的芯片一样,已经成为未来具身智能产业发展的短板。
如果未来的范式不是单一大模型,而是混合AI,那用在端侧的芯片就不是现有架构的简单芯片,也不可能仅靠最先进工艺堆砌算力就能实现,更需要异构计算架构。虽然今天的SoC已经是异构计算,包含了CPU、GPU、NPU,但我们还应该思考未来的具身智能机器人中还会出现哪些新的计算核,这样才能让整个系统变得更高效灵活。
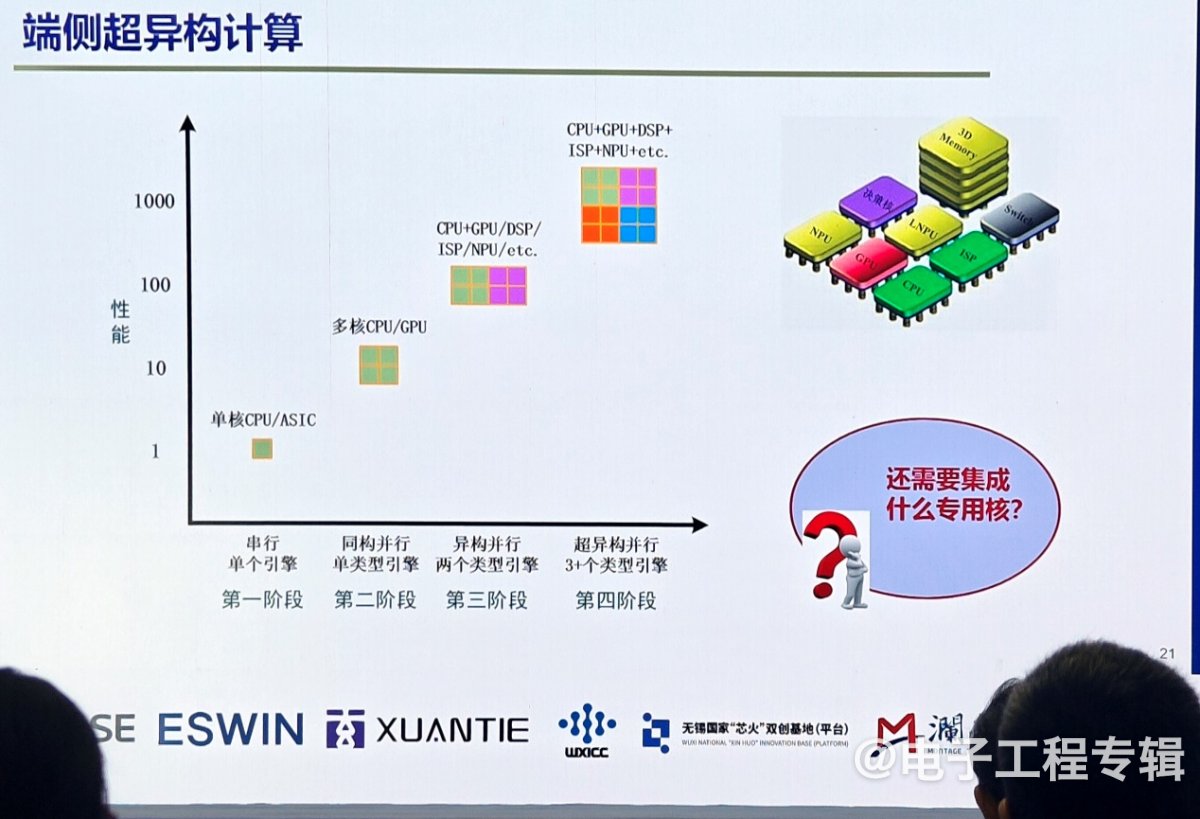
在谈到具身智能计算架构对芯片的需求时,孙宏滨教授指出,未来的芯片需要支持多模态感知、自学习、推理决策、人机自然交互、导航定位、规划控制等功能。特别是在自学习方面,他介绍了两种学习方式:有监督学习和强化学习,并强调了片上自学习架构的重要性。
然而,当前的端侧训练芯片算力无法满足要求,需要在算法和芯片架构上进行新的创新。以英伟达为例,其最新的Thor芯片算力高达2000Tops,而国产芯片在算力上仍存在较大差距。
孙宏滨指出,国产芯片受制于先进工艺的限制,与国际领先水平的差距在短期内难以迅速缩小。“比如用英伟达的Orin和华为升腾310B对比,我们算力相差几乎达到了10倍的规模。因此,如何在现有技术基础上实现创新,成为了亟待解决的问题。”

当前做大模型的公司真正盈利的很少,唯一盈利的公司是支撑大模型训练的英伟达,然而英伟达并不关心大模型能进化到多好或能挣多少钱,作为“卖铲人”他们更希望看到模型规模越来越大,大家买更多的GPU。从大模型开发者的角度来说,如果有一种更好的范式,也就在另外的路径上摆脱了对英伟达的依赖。
片上自学习架构的突破
具身智能的一个重要特征是机器人能够在环境、交互中自主学习。为了实现这一目标,芯片需要支持自学习功能。今天无论是移动机器人还是无人车、无人机,都有自学习基本范式,其几大标准模块包括感知、建图、定位、规划、决策和控制。
未来的自学习大概会有两种范式,分别是感知类任务范式和决策类任务范式。感知类任务范式用于机器学学习,采用有监督学习法,通过采集环境中大量的数据并进行标注,用有标注的数据来训练模型,这个模型就具备了我们希望它具备的识别跟踪能力;决策类任务范式更倾向机器学习三大分类中的强化学习范式,在环境中定义一个奖励函数,通过在环境中的试错最终达到一个优化的模型。
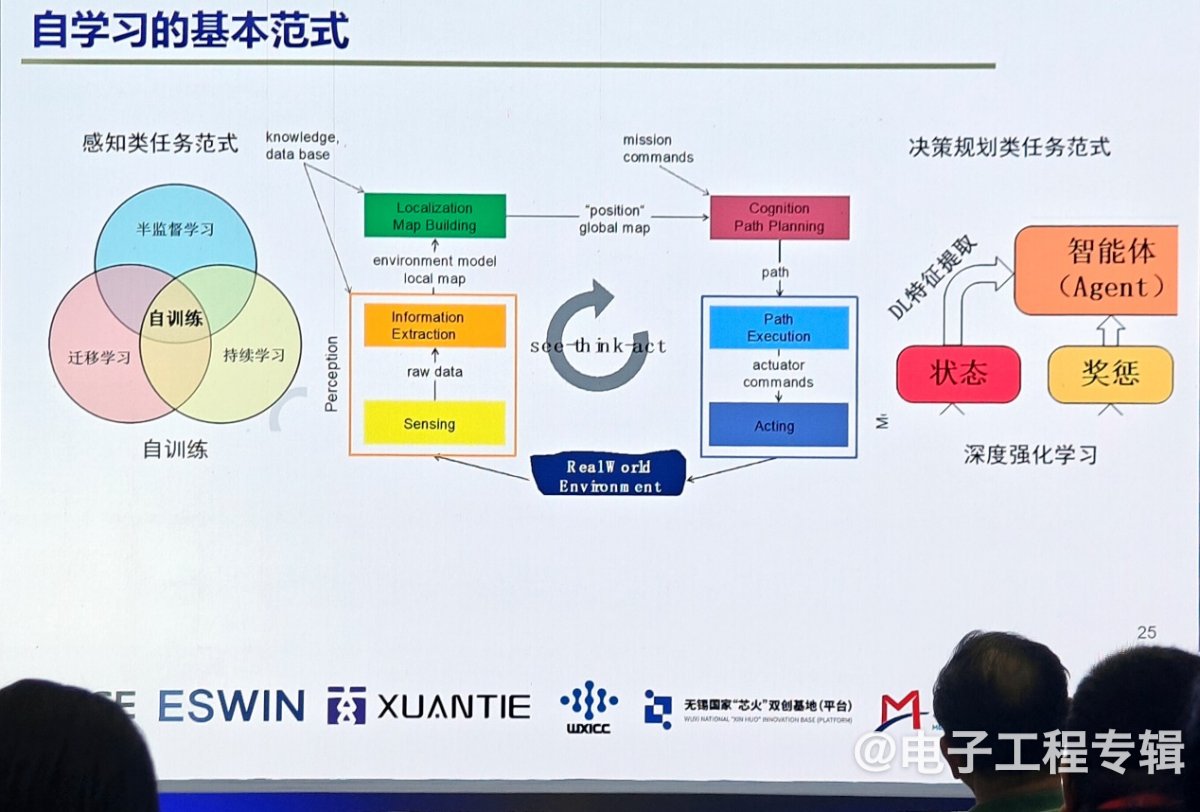
孙宏滨表示,今天的深度学习表现出非常好的数据,但是实际场景数据与离线训练数据间难以满足独立同分布假设,导致深度学习算法在实际部署中的性能下降。“智能算法如何在环境部署中自己搜集数据?在整个使用过程中持续约束?就好比我们从小到大都是经历由家长监督学习,到持续自主学习,如果智能机器人能实现自监督的持续学习,就更像人了。”
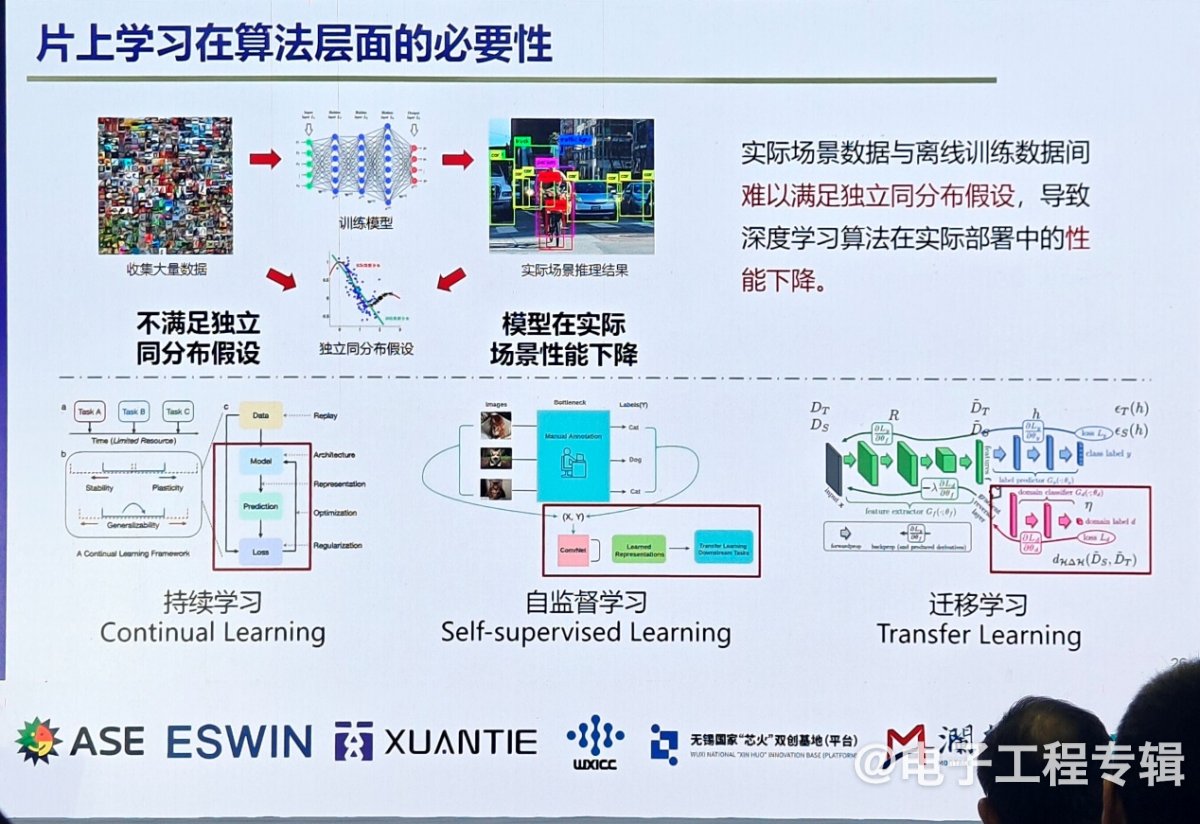
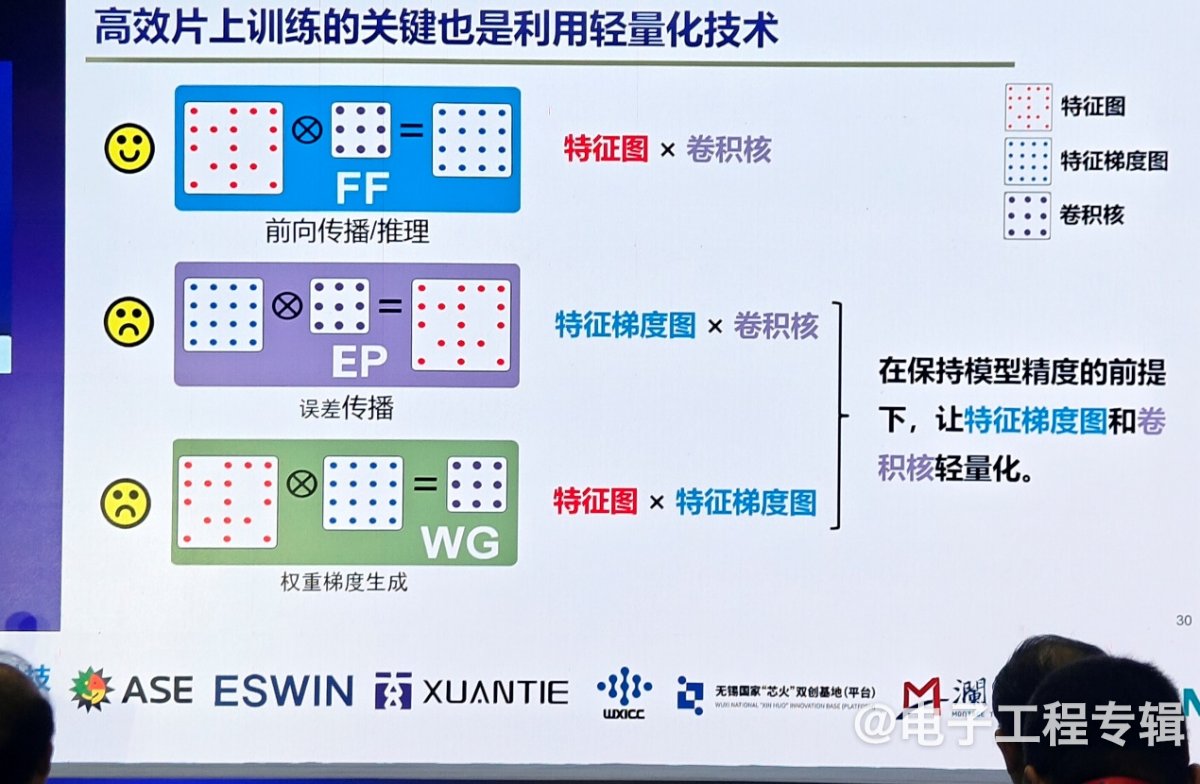
不过不管哪类学习模式,都需要在端侧训练,不仅需要算法支持,也需要芯片架构有新的改变。如今大部分芯片不支持端侧训练,“推理只需要前项推理,训练需要反向误差传播和梯度生产。” 孙宏滨指出,推理已经发展了很多年,也用了很多轻量化推理技术,我们也尝试把在端侧推理已经非常成功的技术用在训练上,但稀疏化、权重分解和数据量化技术都不能用于直接训练,这是因为训练过程中参数在不断变化,过程减掉后无法恢复,这对训练精度影响很大。

如果仔细看前向推理、误差传播和权重梯度生成这三种计算,其本质是两类数据的计算,训练和推理之所以不一样,是因为训练误差传播是特征梯度×卷积核,权重梯度生成是特征图×特征梯度图。在训练端能够轻量化的关键,是怎么在保证训练精度的前提下,让特征梯度图和卷积核能够轻量化。
针对这些问题,孙宏滨详细介绍了两种关键的自学习技术:基于近似统计量的边层计算方法和张量权重分解方法。
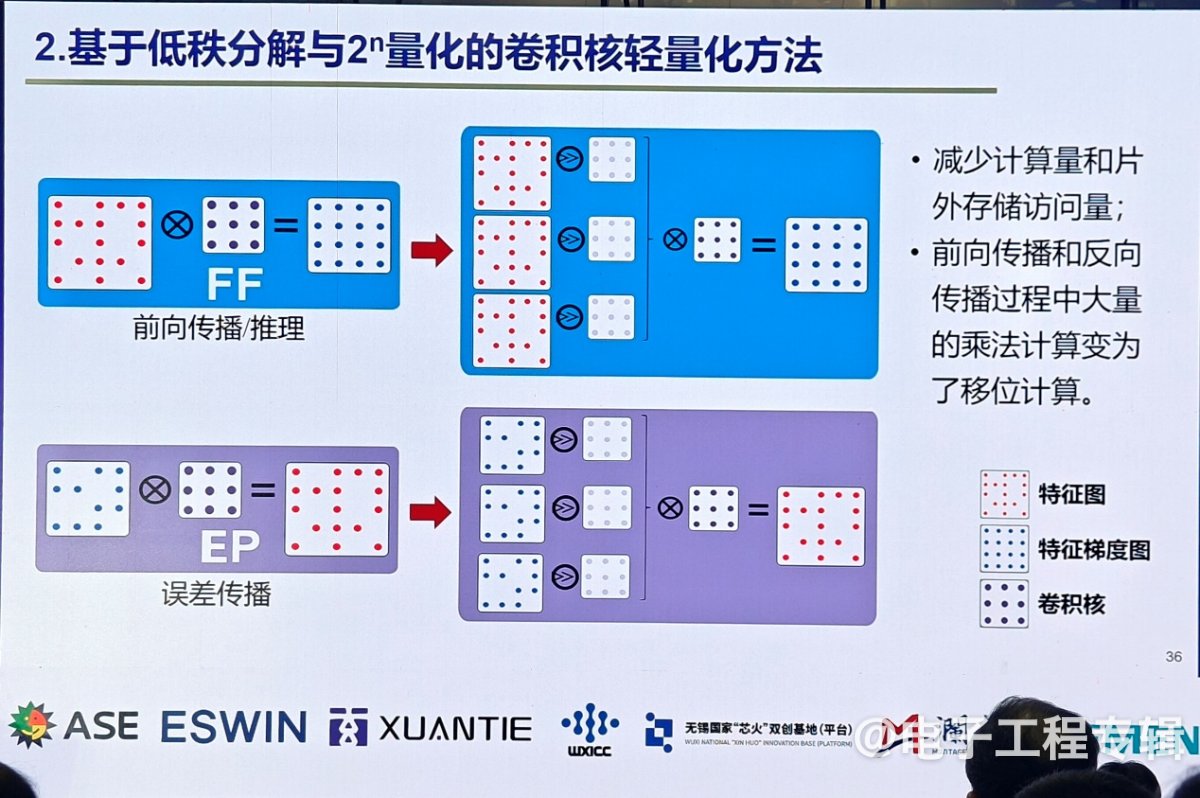
- 基于近似统计量的边层计算方法:这种方法通过逼近拟合的计算方式,将原本稀疏的数据变得不稀疏,从而大大减少了计算量和片上访存量。实验结果显示,该方法在特征梯度中增加了60%的稀疏性,整体资源量减少了27%,片上访存量减少了28%。

- 张量权重分解方法:该方法通过在端侧进行预训练后的微调,减少了卷积核的计算量。具体而言,这种方法将大量的乘法计算转换为一位计算,进一步降低了计算量和片上访存量。
这两种方法虽然在算法层面实现了突破,但还需要芯片架构的支持。硬件主要解决两方面问题,一是如何高效计算不规则的稀疏数据,二是对稀疏数据进行高效的片上在线压缩,降低访存量。
对此,孙宏滨团队在电路设计方面进行了大量研究,提出了高效的计算和压缩方法,确保了自学习功能的顺利实现。“终的效果是,这一套方法能够在芯片面积效率、能耗效率上有非常大的提升。”
