
Intel在今年IFA媒体会上谈过一个很有趣的观点:AI PC虽然此前受到诸多质疑,但其实在iGPU——也就是集显/核显刚刚发布时,也被当时的人们嘲讽了很久,说它根本不可能用来玩像样的游戏。
Josh Newman(英特尔产品营销与管理总经理、计算机事业部副总裁)在主题演讲中甚至说,他当年还曾写过文章谈集显不堪大用,连GPU都算不上。“但现在我要承认当时的我错了。集显驱动了网页合成、UI渲染,是图形体验不可或缺的组成部分。”
而且现在的集显也的确能用来玩游戏,甚至在中低画质下畅玩3A游戏。“从这个角度来看,AI是一样的。”OEM厂商也普遍认为,如果说年初的CES展会上,大家还在问为什么要买AI PC,那么起码到了现在,AI PC的发展之路已日趋明朗。

即便最近的Lunar Lake处理器发布会上,酷睿Ultra第2代处理器的诸多亮点都给我们留下了深刻印象——尤其CPU, GPU能效大幅跃升、多场景功耗显著下降,Windows笔记本续航也终于能达到20小时,依稀让我们看到当年Pentium M的影子;但占据发布会最大篇幅的,依旧是AI PC这个近两年不得不谈的主题。
市场上正在推行AI PC概念的参与者不少——AMD、高通、英伟达、苹果,还有操作系统、OEM厂商都在发力。以现在的市场格局,Intel要在AI PC市场上胜出已经不那么容易了。
Intel在今年IFA上宣导了一个重要主题:出色的AI PC,首先是一台出色的PC。上篇文章已经详谈了Lunar Lake在达成“出色的PC”这件事情上具体做了什么;本篇将注意力放在所谓“出色的AI PC”上:Intel局内战况如何,以及接下来一段时间内AI PC会如何发展。
Lunar Lake的AI硬件与软件基础
先花少许笔墨回顾一下Lunar Lake处理器,也就是酷睿Ultra V200系列芯片,有关AI加速的硬件堆料——即便这在去年的架构解析文章里已经做了具体的探讨。
首先是CPU部分的VNNI, AVX扩展指令集支持。这一点尤其体现在Lunar Lake的E-core实现了2倍AI吞吐提升——架构层面主要表现为后端浮点和矢量运算资源大幅提升。CPU的AI算力为5 TOPS。
iGPU核显此前就作为酷睿Ultra处理器的中坚,这次的Xe2核显本身增加了XMX引擎——相当于隔壁的Tensor core;加上整体规模增大,核显的AI算力达到了67 TOPS——被Intel称为移动处理器中最快的AI加速器。
NPU作为更专用的AI加速单元,规模是上代的4倍,AI算力48 TOPS。最终Lunar Lake的xPU总AI算力为120 TOPS,较上代提升3-4倍。发布会上Intel还特别强调说虽然也有其他NPU有着相似的纸面数据(骁龙X Elite:???)但Intel的NPU有着更出色的实际性能。

不过AI算力基础并不是这次Intel宣传的重点。重点仍然是AI算力能用来做什么:包括开发者如何使用这些算力,用户有哪些真正用得上的AI应用,以及Intel的AI软件基础设施,包括各类框架、中间件、加速库、上层应用等。
这次发布会上,有关AI软件的关键发布至少包括:
(1)一款名为AI Play的应用——这是一款开源的生成式AI应用,在酷睿Ultra处理器及Arc显卡的硬件基础上,跑在Windows操作系统中。
Intel在发布会上介绍说,用户可以在AI Play中选择适用于本地硬件设备的AI模型。比如说可以用Stable Diffusion来做文生图、图生图;让AI来写代码;也可以基于现在相当流行的RAG(retrieval augmented generation)关联用户的特定内容,与SLM模型进行更有针对性的人机对话。

这应该是Intel为数不多亲自下场做的生成式AI应用。不知道在部署上是不是像隔壁英伟达ChatRTX那样,是一键完成环境搭建和应用安装的——现在的芯片企业还真是普遍一边做着芯片,一边操着最上层应用的心。
我们认为AI Playground作为一个开源项目,更像是基于Intel AI软硬件生态的应用参考,当然也是展示其生态构建水平更直观的方式。
(2)基于Lunar Lake的Copilot+PC体验,预计将于今年11月进行Windows Update推送。Copilot+PC是此前微软定义的AI PC,或者说其中涵盖了一些Windows操作系统层面的AI特性:如系统级的内容创作辅助,实时语言翻译,第三方app的AI体验加成等。
最初Copilot+PC概念是今年5月微软和高通(骁龙X Elite/Plus)一起推的。当时微软明确Copilot+PC需要至少45TOPS AI算力。于是后续Copilot+PC推向Lunar Lake平台也顺理成章。

各OEM厂商这次展示新机标称25+小时续航的本子,还真是不在少数;虽然这个数字和实际使用还是会有差异,但相较以往的9-12小时,大约是能够达成续航显著提升的
虽说Meteor Lake未能赶上Copilot+PC班车,但看起来微软多芯片架构并行推进的策略,以及“脚踩两只船”的传统还是在延续的。
不知道Intel在发布会上反复强调Lunar Lake在功耗和续航表现上实现对骁龙X Elite的超越,打破x86指令集做不了低功耗、高能效处理器的迷思,会不会对微软的未来决策产生些许影响。不过全民AI PC的时代,即将因为Windows和Intel的同时下场,很快到来了。
再谈Lunar Lake的AI性能
120TOPS只是理论峰值算力,Intel还在媒体会上给出了不少AI系统性能测试的对比数据。
比如说Lunar Lake总体AI性能是上代Meteor Lake的3倍;核显(酷睿Ultra 9 288V)部分的AI性能,是AMD HX 370的2倍多(基于UL Procyon AI图片生成测试);NPU的AI性能,则比骁龙X Elite高出约20%(基于Geekbench AI测试)。
微软在为Intel站台时也顺嘴提了句,Lunar Lake的NPU AI性能是苹果MacBook Air M3的2.5倍。

Intel工作人员在展示用Lunar Lake跑UL Procyon AI测试,并记录测试全程的功耗变化,与上代Meteor Lake的显著差异
媒体会上,Intel分享了更多第一方AI跑分与实际工作负载性能比较。总结一句话是,抛开独显之类的加速器不谈,Lunar Lake在AI性能方面强于市面上现存所有PC处理器。而且这次,Intel是自信到专门准备了个屋子,可现场进行各种AI跑分,与竞品直观比较。
对比关键数据有几则。首先是UL Procyon AI测试——这个测试目前分成两大类:计算机视觉与图像生成。跑分结果如下图:


似乎Intel不仅着眼于强调自家NPU比高通强,GPU比AMD强;也顺便在谈Lunar Lake处理器的适用性更广,包括NPU能跑FP16数据精度的推理,而AMD和高通都不行;以及高通骁龙X Elite的核显尚无法进行特定AI负载的加速。
冯大为(英特尔客户端计算事业部副总裁兼客户端细分市场部总经理)在会后接收采访时说,Intel工程师尝试用高通GPU去跑AI应用,发现大部分情况下都不可行;而AMD的NPU应用则几乎还看不到。想必这与AI生态培养,还是有莫大关联的。
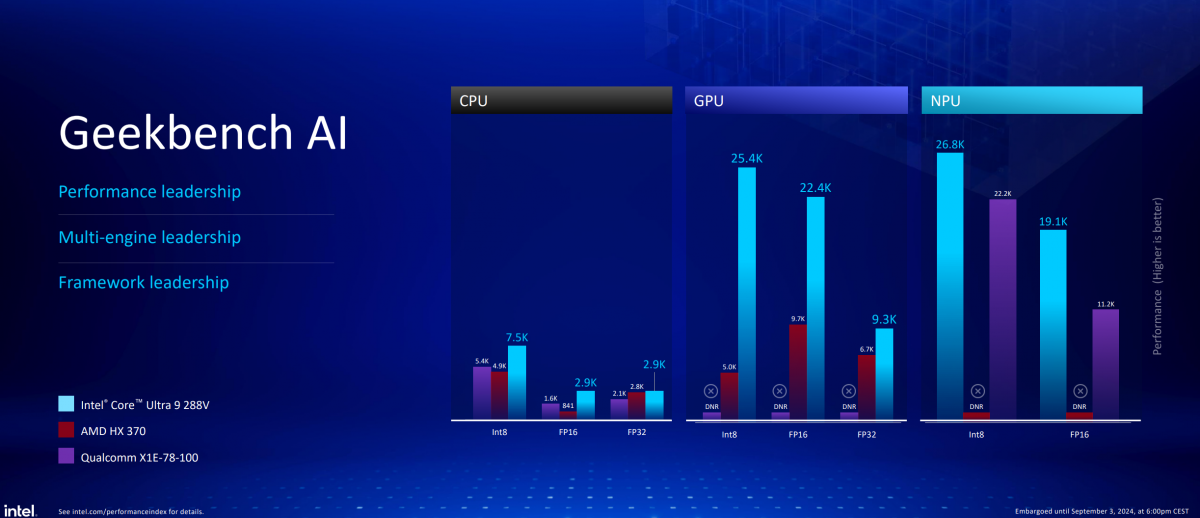
Geekbench AI测试的情况也类似,无论CPU, GPU还是NPU的AI推理性能测试,都优于另外两家——也算是在Meteor Lake先发,AMD和高通连续出招以后,Intel在AI性能上的扬眉吐气了。
另外,Blender、Lightroom、Premiere Pro等既有生产力软件逐步开始加入更多的AI特性,比如照片的AI降噪、超分、场景编辑检测、语义分割、内容生成、自动加字幕等。Intel也给出了主流存量生产力应用的部分AI特性,Lunar Lake与骁龙X Elite的执行速度比较。
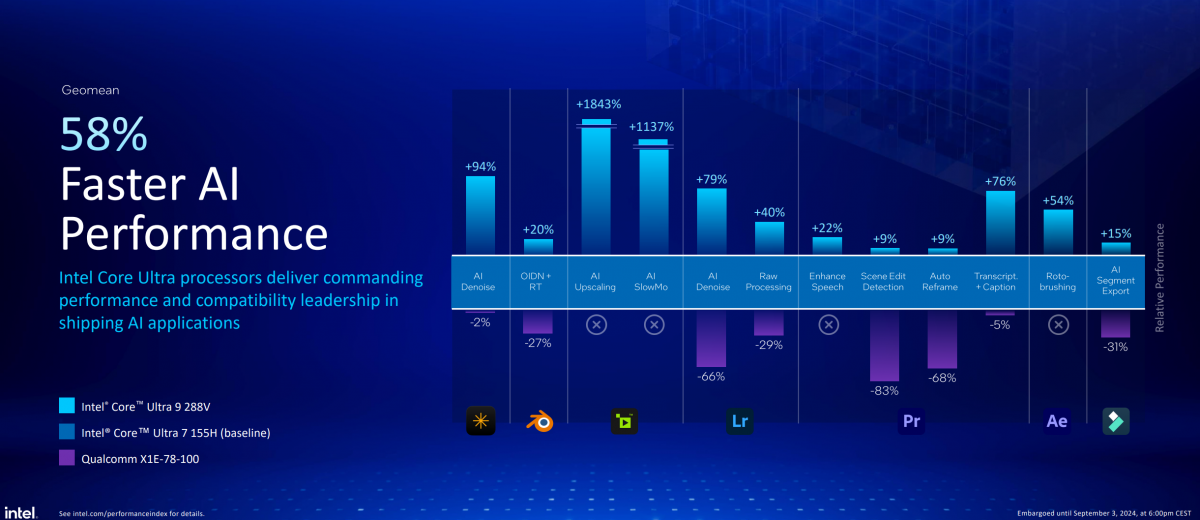
比如说,用Premiere Pro自动给视频加字幕和标题。酷睿Ultra 9 288V相比骁龙X1E-78-100快了86%,相较酷睿Ultra 7 155H快76%。;还有Lightroom的AI降噪特性,Lunar Lake比骁龙X Elite快145%,比Meteor Lake快79%;After Effect的ROTO笔刷特性实现上,Lunar Lake比Meteor Lake快54%,骁龙X Elite则尚不适配该特性的加速...
兼容性可能仍是Intel的王牌
值得一提的是,上述这三项AI特性,主要是借助Lunar Lake的GPU核显加速达成的,而且从Intel发言人的演讲来看,通过和Adobe的合作,这些特性还充分利用了核显新增的XMX矩阵扩展单元。而当这些AI功能跑在骁龙X Elite平台时,依赖的就只有NPU。
这一例大概至少能体现三件事:
首先是xPU加速AI的灵活性——这也是自Meteor Lake起,Intel就在反复强调的,AI加速应当是不同处理器针对不同场景,灵活发挥作用的体现。
Lunar Lake的CPU扩展指令集实现的AI加速,主要针对轻度AI负载,和实时响应要求更高的AI应用。GPU面向游戏和创作AI,也是相比CPU和GPU性能更强的AI加速器。NPU则面向追求高能效和长时间运行的AI负载。

Intel提到现有ISV合作伙伴中,1/3选择了用GPU做AI加速。据说在面向合作伙伴的的调查中,Intel发现合作伙伴采用CPU, GPU和NPU作为AI引擎的比例差不多。这可能也让Intel更加坚定了XPU做AI加速的策略,而非很多人理解的AI单纯就依赖于NPU加速。
冯大为也提到ISV(独立软件供应商)选择GPU用作AI加速的比例不小。这大概与面向GPU开发更友好有关。“我们不希望用我们的主观想象去指导ISV写软件。”“要给他们提供选择,这是大前提;也是和另外两个竞争对手不一样的地方。”

其次反映的,是Intel长期以来积累的合作伙伴与生态资源。此例表现的是Adobe作为开发者,与Intel的合作。
Intel给出的数据是,基于Intel芯片及开放生态,其AI软件生态系统,已经有100+ ISV,支持超过500种AI模型,可用的AI特性超过300个。
第三,AI软件兼容性。在媒体会上,Intel不止一次地嘲讽过,但凡涉及GPU, NPU相关测试,高通就有很多应用和测试是完全跑不了的:比如测50款游戏,就有近一半无法运行在骁龙平台上,还有前述Adobe全家桶的某些AI特性骁龙X Elite/Plus处理器也跑不了。
Intel在发布会开场就援引了第三方测试数据,在110款AI应用中,x86支持其中的99%,而Arm阵营整体为84%。“这种兼容性差距不因为指令集,而是多年对生态的投入和积累带来的。”冯大为在采访中说。

虽说现在嘲讽高通和Arm的PC生态兼容性略有些欺负后生,但这不得不说就是Intel的优势之一。从生态的角度来看,Intel大概的确是现阶段PC市场上,除了英伟达之外,从AI开发、优化到部署,全栈生态最为完整和健全的竞争者。
所以Intel才在发布会期间反复说自己是AI PC市场上唯一能够做到跨操作系统,达成这么多ISV、AI特性、AI模型覆盖的企业。
走向PC的新10年
近两年的Intel发布会普遍有个特点,不仅限于客户端计算业务,还包括其数据中心、网络与边缘业务,在发布会上谈“软件”的篇幅显著提升。这其实和Intel开始推行XPU策略,将更多注意力放在加速器上是有关的。
因为加速芯片、加速器需要对不同应用场景、行业做针对性加速。基于这些应用场景的差异,针对性的加速技术大量体现在软件加速库、框架、中间件上。软件就是开发者是否会采用对应芯片的关键。英伟达现在的开发者大会就几乎都是在谈软件。
现在酷睿Ultra的发布会和媒体会也开始将诸多篇幅给到了软件。Intel回顾过去45年做软件生态系统的历史,头二三十年专注在操作系统相关的优化、工具、库、框架构建;

而过去10年,OpenVINO, oneAPI等相关加速计算和AI基础设施的软件,以及诸多AI框架、开发者云等工具就成为了工作重点。前文提到Lunar Lake的AI性优势,软件就在其中发挥着举足轻重的作用。
Intel这次还找了几家不同领域的AI软件企业上台做开发分享:无论是基于AI做在线演示和内容分享的技术,用AI辅助做视频编辑,还是将AI应用到信息安全领域——借助NPU来做本地安全扫描、异常检测…
可见Intel在AI软件生态方面的投入是巨大且长期的。这大约都是在为后续AI应用的全面爆发做准备。单说AI模型,前不久Intel中国国内技术人员和我们聊起,在模型支持合作广度与深度上,Intel还鲜有竞争对手。
冯大为在采访中也说,“我们现在无法预测未来哪些AI应用会立刻成为主流。”“我自己的观点是,大大小小的AI模型跑起来,让所有应用都有选择——让他们知道需要多大程度的AI化。”让开发者不需要将过多精力放在模型和硬件上。

过去一年多我们也能看到,AI应用场景正逐渐变得多样化,且深入到了行业应用。不管是视频工作者借助AI工具做语义分割,划分画面深度;还有音乐人会将一首曲子用AI工具切分不同的音轨;
办公资料整理、视频会议记录、不同语言翻译,乃至将生成式AI应用到工业制造领域的机械臂上、教育领域的教师备课和智慧课堂上…AI PC已经在其中发挥作用。这些都是生态长期投入的成果。
今年的IFA展会上,微星、华硕、联想等OEM企业都相继发布了自家AI PC工具——如此一来,AI PC已经真正成为芯片、操作系统、OEM、ISV等诸多产业链市场角色的狂欢。就像惠普发言人在Lunar Lake发布会上说的,AI正对工作和生活产生变革,让“PC走向崭新的10年。”

