
Semidynamics推出了一款集RISC-V、向量、张量和自有Gazzillion技术于一体的一体化IP解决方案,该解决方案仅使用一个指令集和一套工具链即可实现AI工作负载。
据该公司介绍,目前AI芯片设计人员通常会在系统CPU旁边集成单独的IP模块,以满足AI日益增长的需求。这种方法导致了AI芯片的配置不够理想,因为通常需要依赖三家不同的IP供应商和三套工具链,这不仅使得功率、性能和面积(PPA)指标较差,也增加了适应新算法的难度(图1)。
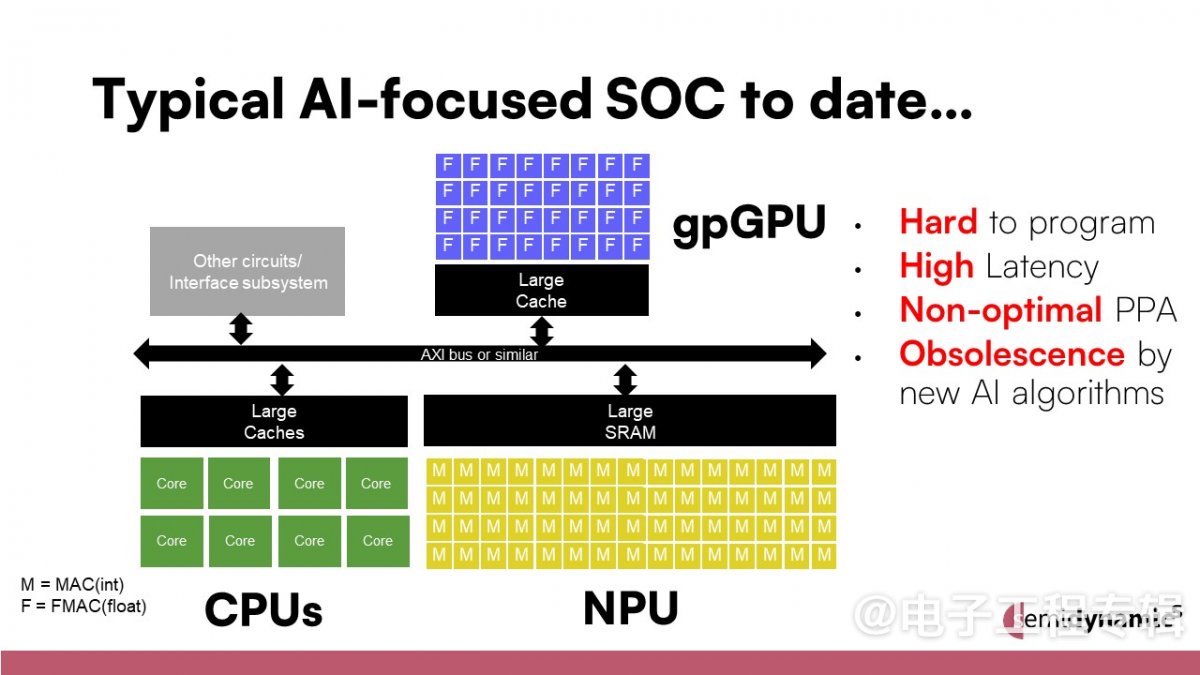

图1:目前AI芯片设计人员通常会在系统CPU旁边集成单独的IP模块,以满足AI日益增长的需求。这种方法导致了AI芯片配置不够理想,因为通常需要三家不同的IP供应商和三套工具链,这不仅使得PPA指标不佳,也增加了适应新算法的难度。(来源:Semidynamics)
Semidynamics首席执行官Roger Espasa(图2)解释说:“比如,现有的方案无法很好地处理Transformer这样的AI算法,但我们的一体化AI IP却非常适合。我们创造了一种全新的方法,只用RISC-V指令集和单一开发环境,使得编程变得简单。将各种模块集成到一个RISC-V AI处理单元中,意味着可以轻松部署新的AI算法,而不必担心如何分配工作负载。数据存储在矢量寄存器中,可以由矢量单元或张量单元使用,每个部分只需依次等待访问同一位置即可。因此,零通信延迟和最小化的缓存使得PPA得以优化,更重要的是,它能够轻松扩展以满足更大的数据处理要求。”

图2:Semidynamics公司CEO Roger Espasa。.
Semidynamics的主张是将其四个IP组合在一起,形成一个完全集成的解决方案,即所谓的“一体化AI”IP处理单元(图3)。它具备完全可定制的RISC-V 64位内核、矢量单元(充当GPGPU)、张量单元(充当NPU)及其Gazzillion单元,以确保可以从内存中的所有位置处理大量数据,而不会出现缓存未命中的情况。由此,开发人员可以仅与一个IP供应商、一个RISC-V指令集和一个工具链合作,从而使实施变得更容易、更快,同时降低风险。此外,还可以将尽可能多的这种新型处理单元组合在一个芯片上,以打造下一代AI芯片。
Espasa表示:“我们已经建立了一种全新的方法来构建更强大的芯片,我们相信这将帮助AI克服现有最先进设计的局限性。借助我们的新配置工具,用户可以在处理单元中创建张量和矢量单元与RISC-V控制功能之间的适当平衡。”
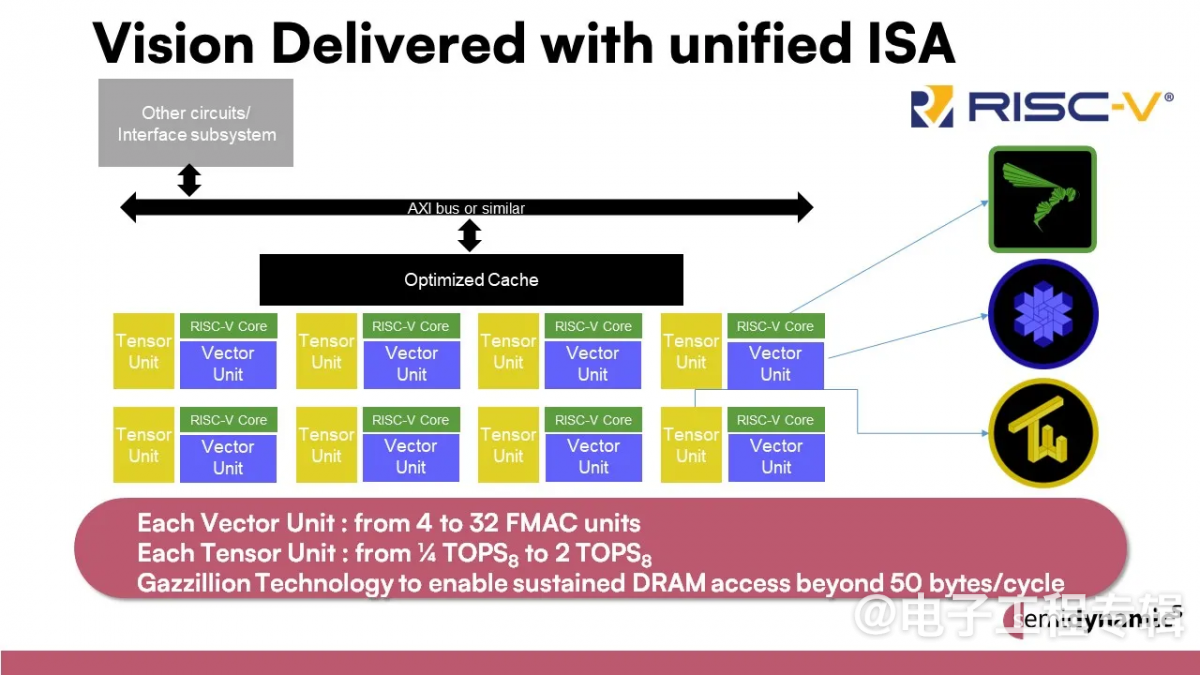
图3:Semidynamics的主张是将其四个IP组合在一起,形成一个完全集成的解决方案,即所谓的“一体化AI”IP处理单元。(图片:Semidynamics)
将重心从CPU移开
当被问及关键在于集成的原因以及为何以前没有这样做时,Espasa称这是一个范式问题。RISC-V的早期发展重心完全放在CPU上——无论是在RISC-V社区还是客户中。“我们比其他人更早地认识到了向量的优势,而AI最近对于如Transformer和大语言模型(LLM)提出了更高的灵活性要求。”他说,这也是为什么迄今为止没有实现如此高度的集成:“这并不是一件容易的事,这也是过去没有这样做的原因。特别是在2023年12月CPU+向量和Semidynamics的张量技术出现之前,在一个环境中还没有一致的指令集。”
他介绍了其全新一体化AI IP的几个关键创新点:
- 消除其他NPU解决方案中常见的“极难编程的直接内存访问(DMA)”,用RISC-V内核中的正常加载和存储功能代替,从而获得了更好的持续性能。据说这种特殊功能仅在Semidynamics的Gazzillion技术的RISC-V内核中可用。Espasa表示:“使用我们的解决方案,软件只需要执行常规RISC-V指令就能将数据(准确地说是矢量加载和存储)移动到张量单元中,而不需要去用那些令人头疼的DMA。”
- 将张量单元连接到现有的矢量单元,其中矢量寄存器用于保存张量数据。这减少了面积和数据重复,实现了更低的功耗,并且再次简化了方案的编程难度。Espasa评论道:“现在,启动张量单元变得非常简单:不再需要复杂的AXI命令序列,而只需一个普通的RISC-V指令(称为vmxmacc,是‘矩阵乘法累加’的缩写)。如果采用AXI命令,就意味着CPU必须读取NPU数据,然后要么缓慢地自行处理,要么通过AXI发送到GPGPU等器件以继续在那里进行计算。”
- 添加了专门针对AI卷积中使用的“平铺”数据类型进行了优化的矢量加载指令,并且可以利用Semidynamics底层的Gazzillion技术。
总结来说,Espasa表示:“只有那些恰好拥有高带宽RISC-V内核、优秀的矢量单元和张量单元的IP提供商才能实现这一结果,并且可以提出新的指令将这三种解决方案结合在一起。”
统一计算单元
Espasa表示,最终的目标是“统一计算单元”,它需要:
- 可以通过简单的复制来扩展,以达到客户的TOPS目标——就像现在构建的多核系统一样。他指出:“似乎没有人担心拥有一个多核系统,其中每个核心都是一个浮点运算单元(FPU),但是一旦有多个FPU,即一个矢量单元,就没人再理解它了。”
- 在扩展过程中,在控制(内核)、激活性能(矢量单元)和卷积性能(张量单元)之间保持良好的平衡。
- 面向未来。Espasa表示:“通过在解决方案中拥有一个完全可编程的矢量单元,客户可以获得面向未来的IP。无论未来发明哪种类型的AI,内核+矢量+张量的组合都能保证运行它。”
简化编程
随着AI数据量和处理需求的不断增加,当前的解决方案本质上是集成更多独立的功能块。CPU将部分专用工作负载分配给GPGPU和NPU,并管理这些单元之间的通信。但这种方式有一个主要问题,即在各模块之间移动数据会产生高延迟。使用三种不同类型的IP模块进行编程也非常困难,每种模块都有自己的指令集和工具链。
Semidynamics表示,由于不断有新的AI算法问世,现有的不可编程固定功能NPU模块甚至在进入硅片之前就可能过时。今天设计的AI芯片到2027年进入硅片时很可能就已经过时了,因为软件的发展速度总是比硬件快。
“我们的一体式AI IP中的RISC-V内核提供了‘智能’,可以适配当前最复杂的AI算法,甚至是还未发明的算法。张量单元为卷积提供了纯粹的矩阵乘法能力,而向量单元则具有完全通用的可编程性,可以处理当今所有的激活层以及未来人工智能软件社区可能想到的各种东西。拥有一个简单且可重复的一体化处理单元解决了可扩展性问题,因此我们的客户可以通过在芯片上使用尽可能多的处理单元,将速度从1/4TOPS扩展到数百TOPS。此外,我们的IP仍然完全可定制,使得公司能够创建独特的解决方案,而不是使用标准的现成芯片。”Espasa总结说。
(原文刊登于EE Times姊妹网站Embedded,参考链接:Semidynamics launches AI IP based on single ISA and one toolchain,由Franklin Zhao编译。)
本文为《电子工程专辑》2024年10月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
