
片上系统(SoC)的创建者通常希望从他们的系统中榨取最大的性能,这是很自然的事情。为了达到这一目的,使用高性能的知识产权(IP)内核,包括中央处理器(CPU)内核,是一个常见的策略。但是,使用最新的高端CPU内核会带来较高的成本,这可能比中档内核高出5到10倍。
SoC架构师在设计时需要根据目标市场和应用做出多种权衡考虑。虽然有些设计不惜一切代价追求性能,但更多的嵌入式系统项目则更倾向于在尽可能低的成本下实现最佳性能。
对于那些使用低成本、低性能处理器内核的设计团队来说,提高效率变得尤为重要。通常,他们可能不知道有一种相对简单的方案能够为其SoC的CPU性能提升多达32%。
性能、性能、性能
SoC中常用的大多数CPU内核基本上都是基于精简指令集计算机(RISC)架构的,比如RISC-V联盟成员开发的RISC-V处理器内核,以及Arm公司的Cortex-A(应用处理器)、Cortex-R(实时处理器)和Cortex-M(微控制器处理器)等内核。
经典的标量RISC处理器旨在每个时钟周期获取并执行一条指令。实现这一目标的第一步是采用经典的RISC处理器流水线,其中包括五种状态:指令获取(IF)、指令解码(ID)、执行(EX)、内存访问(MA)和写回(WB)。如图1所示。
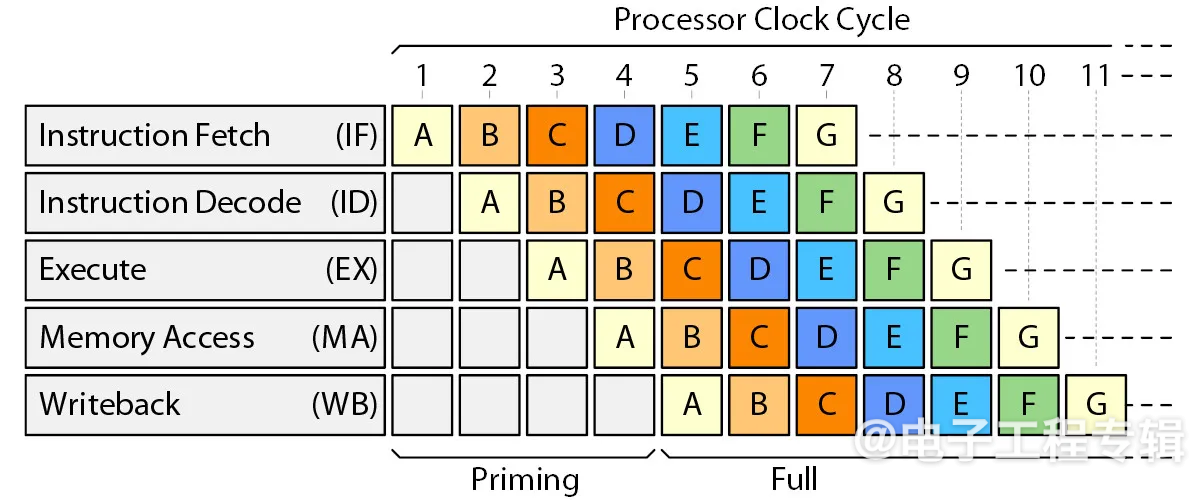
图1:经典RISC流水线。(来源:Arteris)
当应用程序开始运行时,需要几个周期来加载流水线。一旦流水线装满,处理器就可以实现其最大性能目标,即每个时钟周期执行一条指令,尽管在实践中这种情况并不多见。
中档处理器的两种常见场景
CPU性能取决于两个因素:计算能力和数据的可用性。如果处理器在需要指令和数据时无法获取它们,就会导致流水线中的气泡。
考虑两种常见的中档处理器配置:单处理器内核(图2a)和处理器集群(图2b)。假设单个处理器只有一个一级(L1)缓存,而集群中的每个内核(通常是2、4或8个内核)都有自己专用的L1缓存,这些内核共享一个公共的二级(L2)缓存。
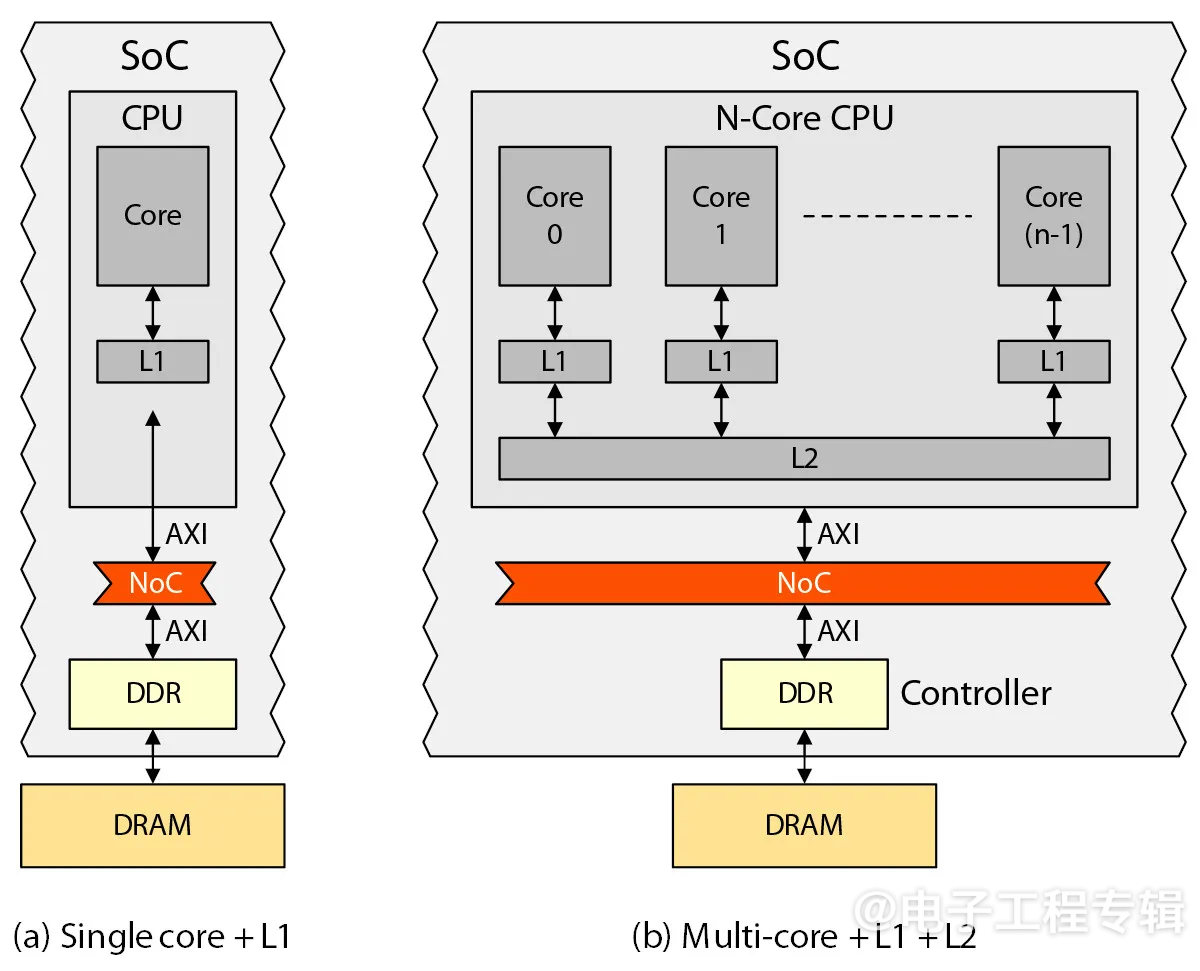
图2:两种常见的中档处理器配置。(来源:Arteris)
在这些场景中,所有的IP(包括处理器和加速器)都通过片上网络(NoC)连接。此外,DDR控制器IP用于与外部DRAM内存通信。访问外部DRAM可能需要100到200个处理器时钟周期,我们假设在这个讨论中为150个时钟周期。
现在,假设运行1,000,000条指令,我们来看看图2a中所示的单核场景。我们来简单做个思维实验,看看如果没有L1缓存会发生什么。在这种情况下,CPU每次需要访问主内存来获取每条指令和数据。因为每次内存访问需要150个处理器时钟周期,所以顺序执行的CPU效率非常低,仅为1,000,000条指令/(1,000,000×150)个时钟周期=1/150或0.67%。
这也就是CPU配备缓存的原因。我们再来做第二个思维实验,假设L1缓存与CPU同频运行,并且访问L1缓存只需一个时钟周期。如果L1缓存无限大,能够将DRAM中的所有内容复制进去,那么1,000,000条指令就能在1,000,000个时钟周期内完成执行,从而使CPU效率达到100%。因此,CPU的理想效率就从没有缓存时的0.67%扩展到了缓存无限大时的100%。
实际缓存计算和CPU效率
实际上,缓存的大小是有限的。在我们的中档处理器示例中,典型的缓存值为16KB到64KB L1缓存,或32kB L1缓存和512KB L2缓存。在这两种情况下,只有一小部分应用程序及其数据可以从DRAM复制到缓存中。
即便如此,即使很小的缓存也非常有效,有两个原因。首先,当程序访问某个位置的指令或数据时,它通常也需要访问附近的位置。其次,程序通常包含多个嵌套循环,在程序执行下一个任务之前,会对同一数据执行多次操作。
因此,当CPU请求数据时,通常可以在缓存中找到。这时称为“缓存命中”,指令只需要一个处理器时钟周期。如果数据不在缓存中,则称为“缓存未命中”。此时,访问DRAM需要150个处理器时钟周期。
在我们的单处理器场景中(图2a),假设典型的缓存命中率为95%,那么1,000,000条指令中的950,000条指令只需要一个处理器时钟周期。剩余的50,000条指令每条需要150个时钟周期。这样,L1专用的CPU效率可以计算为1,000,000/((950,000×1)+(50,000×150))≈12%。
假设我们增加一个L2缓存。L2缓存通常以处理器时钟频率的一半运行,每次访问需要20个处理器时钟周期。假设L2缓存同样有95%的命中率,那么它就能以此速率解决50,000次L1缓存未命中的47,500次。剩下的2,500次未命中则需要访问主内存。这样,基于L1+L2的CPU效率可以计算为1,000,000/((950,000×1)+(47,500×20)+(2,500×150))≈44%。
为了便于讨论,我们再假设增加一个缓存层级。这时,新的缓存通常以与L2相同的时钟频率运行,每次访问需要40个时钟周期。假设这个新层级也有95%的命中率,则CPU效率将为1,000,000/((950,000×1)+(47,500×20)+(2,375×40)+(125×150))≈50%。
CodaCache作为性能增强方案
如图3所示,添加额外的缓存层级来服务CPU或CPU集群是Arteris的CodaCache IP的一种可能部署方式。在上述示例中,这种部署称为专用缓存(DC),因为它专门服务于一个IP——CPU或CPU集群。
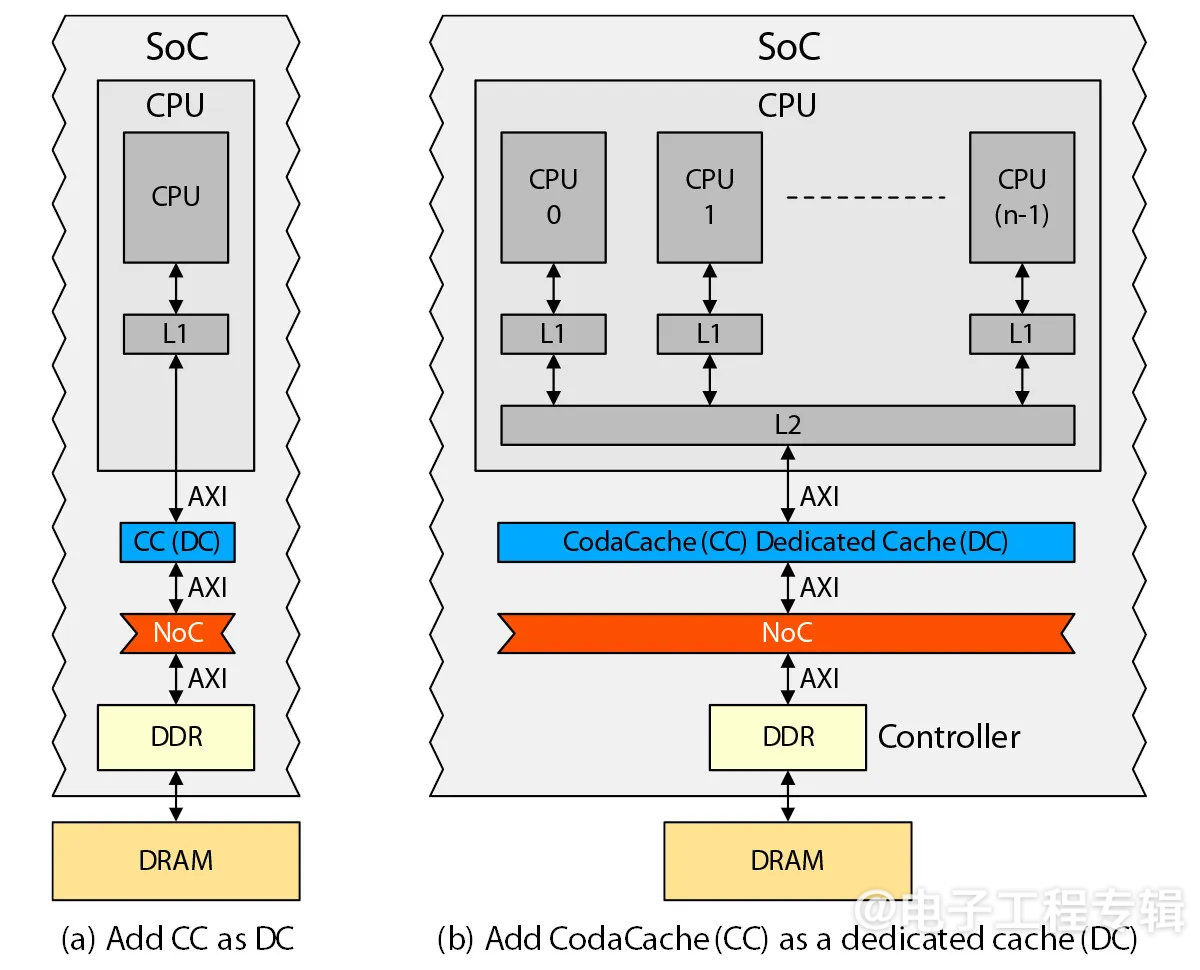
图3:使用CodaCache为CPU提供额外的缓存层级。(来源:Arteris)
每个CodaCache实例的大小可以是64KB到8MB。例如,当与只有L1缓存的CPU结合使用时(图3a),CodaCache可以将性能从12%提高到44%,效率提升了32%,性能提升了267%。
值得注意的是,这只是CodaCache的一种可能部署方式。其他CodaCache IP也可以分配为其他IP的专用缓存,以加速它们的性能。此外,CodaCache还可以部署在NoC和DDR控制器之间,作为最后一级缓存(LLC),以加速整个SoC。
总结
CodaCache是一种可配置的独立非相干缓存IP,通过其先进的架构提供了独特的商业价值,提高了系统性能、数据局部性、可扩展性、能效、应用程序响应能力、成本优化和市场竞争力。
就像一氧化二氮可用于提升一级方程式赛车的性能一样,CodaCache可用于显著提升SoC和SoC CPU的性能。
(原文刊登于EE Times美国版,参考链接:How to Turbo Charge Your SoC's CPU(s) ,由Franklin Zhao编译。)
本文为《电子工程专辑》2024年10月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
