
PC处理器行业这两年的硝烟始终没有停过,尤其今年高通也以骁龙X处理器的面貌强势袭来,AMD Zen 5也对其前代架构实现了全面超越。加上还有AI PC新热点存在,PC处理器的厮杀进入到一个全新的阶段。
今年中的Computex展上,Intel提前解析了Lunar Lake新架构带来的提升——也就是酷睿Ultra主要面向轻薄本的下一代处理器。我们此前总结Lunar Lake作为新一代酷睿Ultra处理器,其更新亮点包括:
- P-core取消超线程设计,IPC和能效两位数提升;E-core大幅加强,IPC甚至略超前代P-core;
- Xe核显图形性能再提1.5倍;
- AI算力大幅提升,GPU的AI算力67TOPS,NPU算力48TOPS,xPU总AI算力120TOPS;
- 低功耗设计,大幅提升笔记本的续航能力。


最近的IFA(柏林消费电子展)上,Intel公开了Lunar Lake的产品信息。搭载这代酷睿Ultra 200V处理器的笔记本已经开启预购——首发的机型有80+款;这些笔记本的正式上市时间预计从9月24日开始。而基于vPro平台的商用版Lunar Lake笔记本则要等到明年初。
感觉上代Meteor Lake推出还没多长时间,Lunar Lake就来了,可见市场竞争节奏之快。我们将分成上下两篇文章来谈谈Intel在德国柏林发布的新款Lunar Lake处理器产品,本篇着重谈谈新品处理器的产品规格,及其性能与功耗表现;下篇则将着重于Lunar Lake的AI属性。
全系4+4核,最高睿频功耗也才37W
面向轻薄本的Lunar Lake具体到产品型号上,是Intel酷睿Ultra 200V系列——隶属酷睿Ultra第二代。Intel在媒体会的答记者问阶段说,这里的“V”并无特别含义,仅用以明确此为Lunar Lake家族处理器产品。猜测可能后续随Arrow Lake的更新,还会有字母后缀非“V”的处理器产品问世。
此次发布的处理器新品从酷睿Ultra 5至酷睿Ultra 9皆有,具体的型号信息如下表:
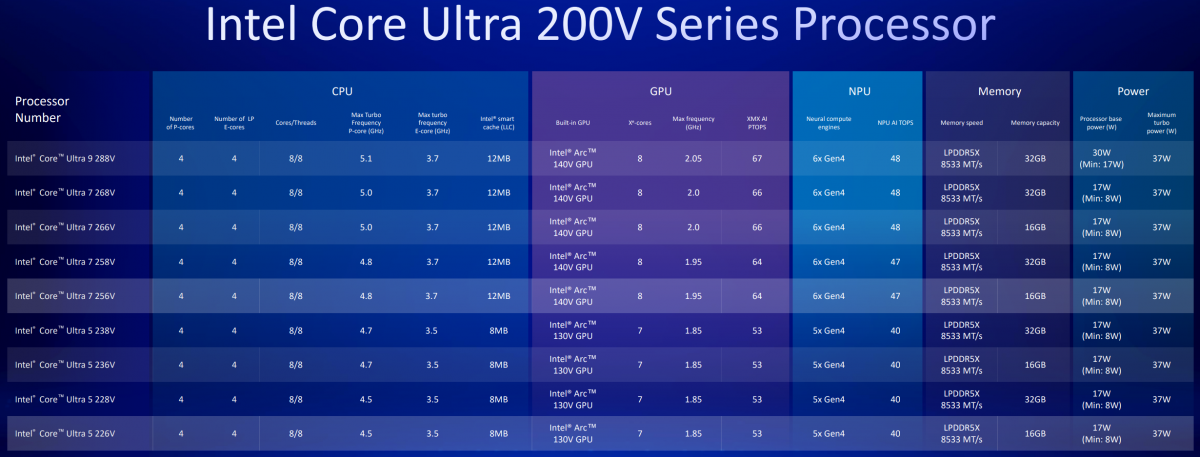
全系CPU部分皆为4 P-core + 4 E-core的8核8线程方案,其中P-core不再支持超线程——此前我们特别撰文探讨过相关Intel于本代酷睿处理器CPU核心不再支持超线程的逻辑。
从核心频率角度来看,根据不同型号定位,P-core的最高睿频有差异。最高配的酷睿Ultra 9 288V处理器P-core睿频5.1GHz。另外,根据型号不同,CPU的E-core睿频,及LLC容量也有差异。
从iGPU角度来看,酷睿Ultra 9和Ultra 7,皆为8个Xe核心——Intel称其为Arc 140V;而酷睿Ultra 5的核显定名为Arc 130V,相比前者少1个Xe核心(也就是少8个XVE矢量引擎和8个XMX矩阵扩展引擎,配对的图形固定功能单元应当也会减少)。不同型号的GPU频率也有差异。
NPU——也就是专用的AI加速单元方面,酷睿Ultra 5也会比另外两者少一个NPU 4核心。似乎对于Lunar Lake而言,拉开酷睿Ultra 5/7/9市场定位差距的主体,已经明显偏向了GPU和NPU算力资源。果然这是个加速器愈发重要的时代。

值得一提的是,Lunar Lake将最高LPDDR5/x-8533规格的DRAM die封装进了芯片内,所以内存容量限定在了16GB和32GB两种。这张表中未列出的是16GB的DRAM die stack为1R方案,而32GB为2R方案。有关Wi-Fi 7, 蓝牙5.4, 4x PCIe 5等IO方面的支持就不赘述了。
从功耗来看,Intel官方为这些处理器设定的基础功耗低至8W,最大睿频功耗普遍标定37W。要知道去年末Meteor Lake发布之际,CPU的基本功耗被定在15W/28W,而最大睿频功耗则达到了57W/64W/115W。
所以我们基本可以认为,Lunar Lake更多地被定位在轻薄本市场——其锚定市场相较Meteor Lake实际上是更窄的。今明两年游戏本、全能本、设计本之类的市场,应当会更多地由后续很快也要发布的Arrow Lake肩负起来。

MSI在展区展示的一台采用Lunar Lake的掌机原型设备
一直说“低功耗”,低到什么程度?
在Lunar Lake的架构解析文章中,我们特别谈到了其低功耗设计。包括片内DRAM降低通信开销、P-core取消超线程设计可带来面积与功耗效益、E-core的强化可让负载少唤醒P-core、新架构IPC与每瓦性能提升、全局新增Memory Side Cache等...
另外为不同模块配独立的电源控制域、加强ITD线程调度辅助等设计,最终都促成了更低的能耗与更高的能效。即便此前Intel宣称Lunar Lake比竞争对手更省电,以及给出Teams会议功耗明显下降之类的数据,我们对于Lunar Lake究竟有多省电,仍然是没有量级概念的。
这次Intel在媒体会上格外强调“Lunar Lake的一切都是有关能效”的,给出有关能效提升与功耗降低的更多直观数据。首先轻薄本作为生产力设备时,最重要的应用场景可能就是Office办公了。
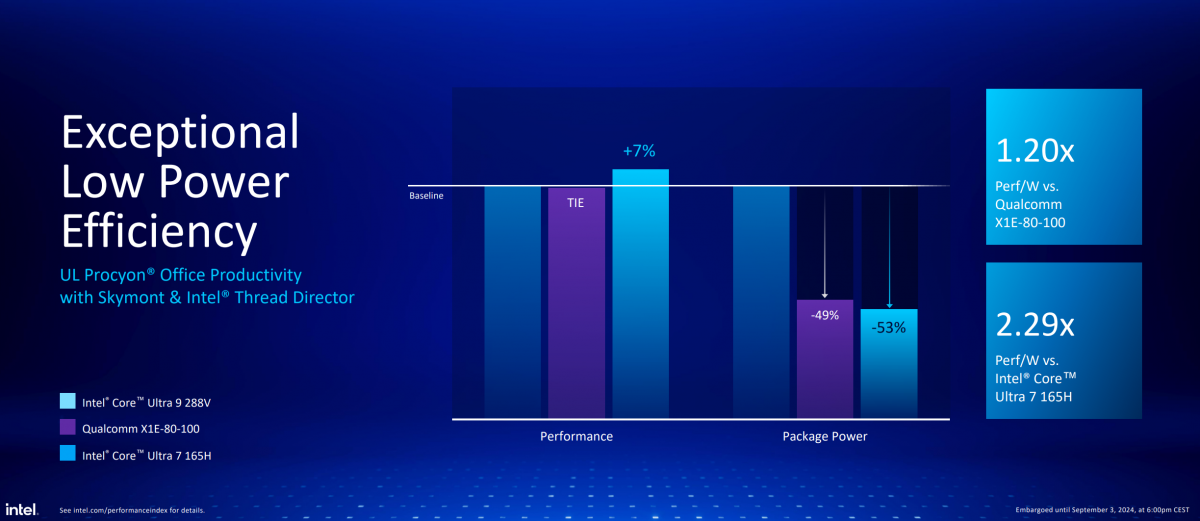
基于UL Procyon办公生产力测试(Word, Excel, PowerPoint, Outlook测试),从测试数据来看,最新的酷睿Ultra 9 288V(Lunar Lake)相比高通骁龙X1E-80-100(骁龙X Elite)和上代酷睿Ultra 7 165H(Meteor Lake),性能还高了约7%,但这代的封装功耗却比上一代低了多达50%+,也低于骁龙X Elite。
所以从每瓦性能的角度来看,Lunar Lake比上代Meteor Lake提升超过2倍,相比隔壁骁龙X Elite也高出约20%。换句话说,笔记本若着眼于离电办公,Lunar Lake会比另外两者明显更省电。
除了办公之外,考虑更为重载的场景:用轻薄本的iGPU玩3D游戏,Intel列举了《刺客信条:英灵殿》《赛博朋克2077》《模拟农场22》三款游戏场景下,Lunar Lake在确保图形性能比前代提升32%-68%的同时,GPU功耗还下降了35%-11%。
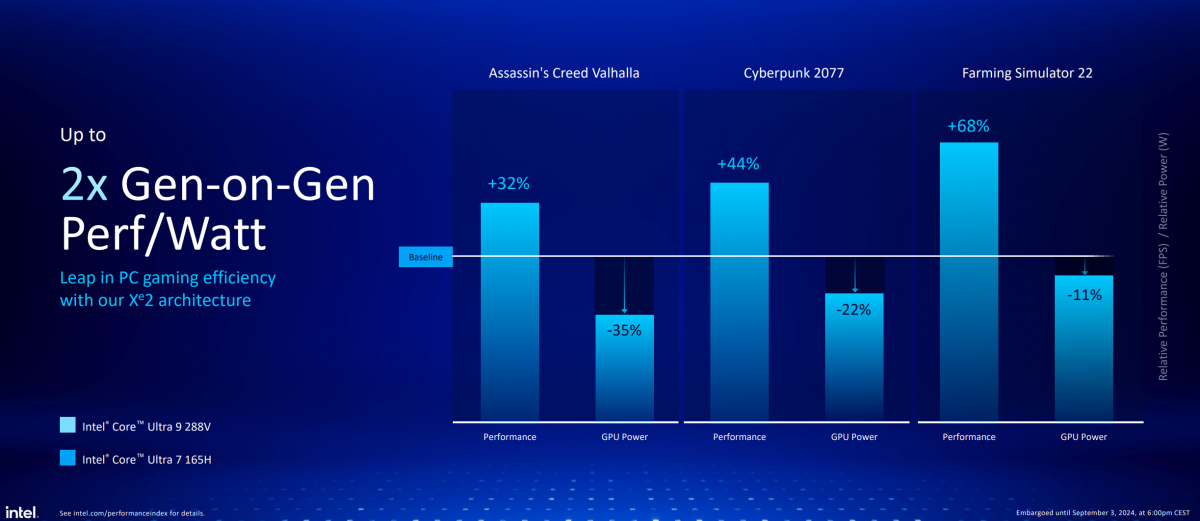
于是游戏场景下的每瓦性能基本也至多提升了2倍。这代核显的Xe2新架构在其中也扮演了相当重要的省电角色。
综合在包括办公、网页浏览、视频会议、流媒体4K视频播放等应用场景下,酷睿Ultra 9 288V相较于酷睿Ultra 7 165H,有着至多50%的整体功耗降低。Intel强调说,“这是在困难模式下做到的功耗降低,因为不要忘记Lunar Lake整体封装内还包含内存。”这部分也算在了“整体功耗”内。
有关低功耗相关的,最有价值的数据就是笔记本续航了。这次Intel还真是相当自信地与高通做了同OEM品牌、同模具笔记本(据说仅有主板和CPU差异)的续航对比——毕竟这是高通此前发布骁龙X Elite强调的绝对长板。

OEM展示区内华硕灵耀笔记本的展示
包括使用UL Procyon办公生产力测试,及Teams会议。结果显示,Lunar Lake相较骁龙X Elite,办公能多坚持2小时(20.1小时 vs 18.4小时),Teams会议则少2小时续航(10.7小时 vs 12.7小时);是个互有胜负的成绩。
官方宣传中提到Lunar Lake笔记本可达成20小时的续航能力,出处应该就是这一测试了。
如果拉上AMD一齐比,则在无法确保模具、配置达成极尽相似,对齐1080p分辨率150nit亮度显示、75Whr左右的电池容量下(据说Intel还稍微吃了点亏,选择对比的机型电池容量为70Whr,而AMD Ryzen机型则配有78Whr的电池),办公套件及会议续航对比如下图:

值得一提的是,基于笔记本日常使用的复杂性,一般续航测试还是需要更复杂的模型来反映实际情况的。但这两个项目在我们看来,的确还是比较有代表性、可做横向对比的测试。
如果实际使用过程中,Lunar Lake笔记本也能达成续航相较骁龙X Elite的反超,则再度证明了低功耗、高能效设计与指令集的关系并不大,而与微架构实施方案真正挂钩。
8核8线程,性能还顶得上吗?
此前的分析文章里,我们就提过,今明两年又是Intel在CPU性能上压力山大的两年。
虽然我们说这代P-core和E-core的确在架构设计上亮点颇多,尤其E-core甚至在IPC上实现了相比前代P-core的赶超,P-core则在设计方法技术上有了巨大改进;而且我们对于Lunar Lake去掉超线程设计的做法也颇为看好;
但单线程性能方面,刚刚发布的AMD Zen 5大幅赶上;而从多线程性能角度,Lunar Lake全系8核8线程,相比上一代Meteor Lake顶配的22线程,少了那么多的线程数...
Intel自己对于Lunar Lake所在TDP 9W-33W区间内CPU性能竞争倒是颇为乐观的。首先从单核角度来看,此前Intel就预告过,这代P-core是绝对优于AMD、高通竞品的。反映到Cinebench 2024、Geekbench 6和SPEC2017的单线程性能测试结果如下:
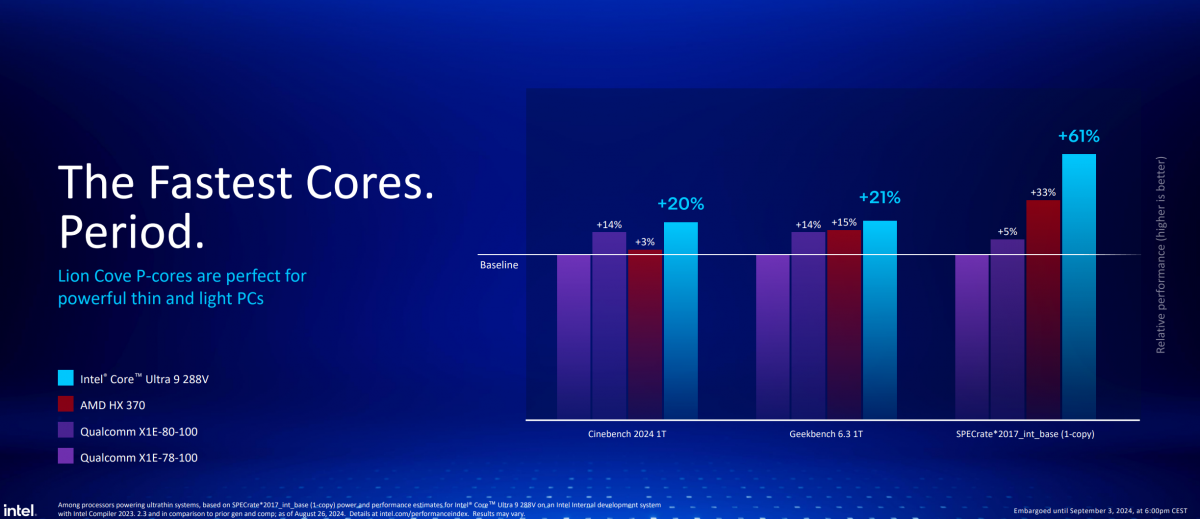
以骁龙X1E-78-100为性能基准,酷睿Ultra 9 288V的单线程性能领先约20%-60%。这在我们看来是意料之中的。
而更多人关心的多线程性能,Intel这次也给出了一些数据——只不过重点还是在效率方面。
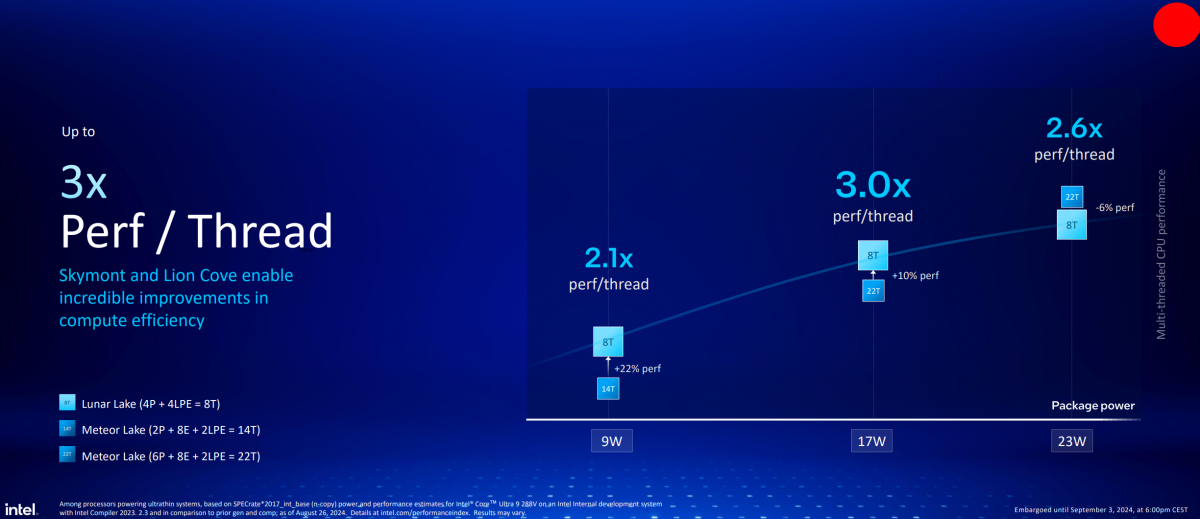
首先Intel非常自信地认为,在特定功耗区间内——也就是上图中的横轴,Lunar Lake的8线程是可以在性能方面胜过Meteor Lake的22线程的。比如当限定9W封装功耗时,Lunar Lake比14线程的Meteor Lake性能高出22%;而在17W功耗时,Lunar Lake的8T性能就比Metoer Lake的22T性能高出10%。
在23W功耗点之上,Lunar Lake的多线程性能会落败于Meteor Lake约6%。毕竟当功耗给足时,越多核心与线程数表现出的性能优势还是能够凸显的。所以Intel提到,就Lunar Lake的8T,与Meteor Lake的22T,20W功耗是两者多线程性能曲线的交叉点。
这里Intel强调的Perf/thread,也就是多线程性能测试结果,除以线程数,得到平均每线程性能。这个值其实更像是另一个维度的平均单线程性能,表达的是Lunar Lake单位线程的性能收益相比Meteor Lake高出2-3倍。
Intel也给出了Lunar Lake CPU的能效曲线,其上有苹果、AMD、高通几个不同的参考点。Intel认为,Lunar Lake在预设的低功耗、轻薄本应用场景内,是具备绝对竞争力的,“即便到33W功耗,我们在持续的多线程性能方面仍保持强势”。
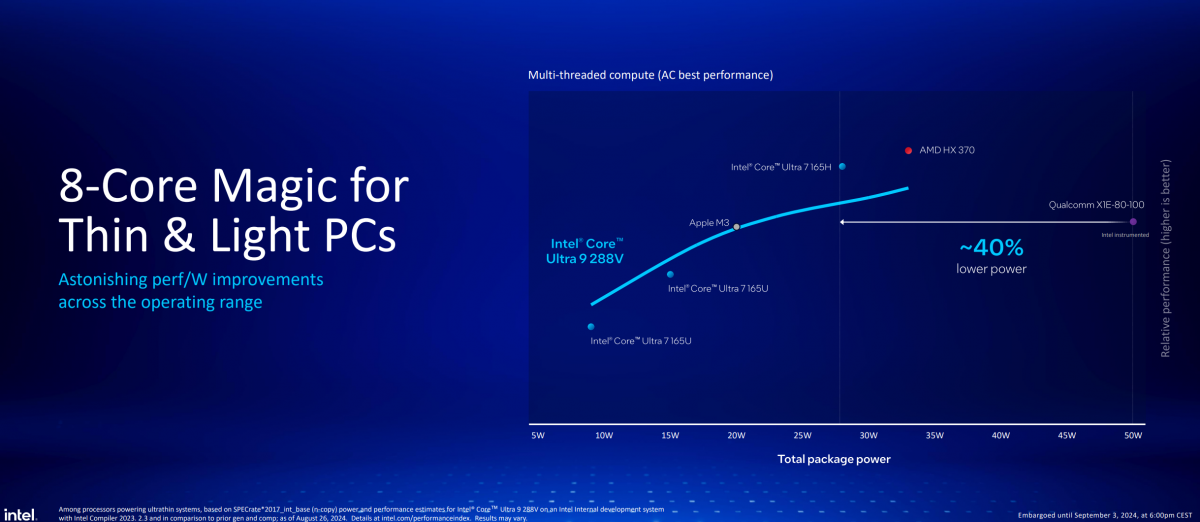
比较有趣的是,Lunar Lake相较骁龙X Elite还少了4个核心,但前者达到后者50W功耗所能达到的性能时,所需功耗低了40%。Intel特别强调这是在多个实验室进行了反复验证的结果,“但每次测试都给出了相同的结果。”
最后是高层级的系统性能测试,更偏向于实际负载——对最终用户体验也更有参考价值。Intel再次选择了Office办公、Photoshop作图、多媒体转码、网页浏览,及生产力综合测试场景,具体结果如下图:
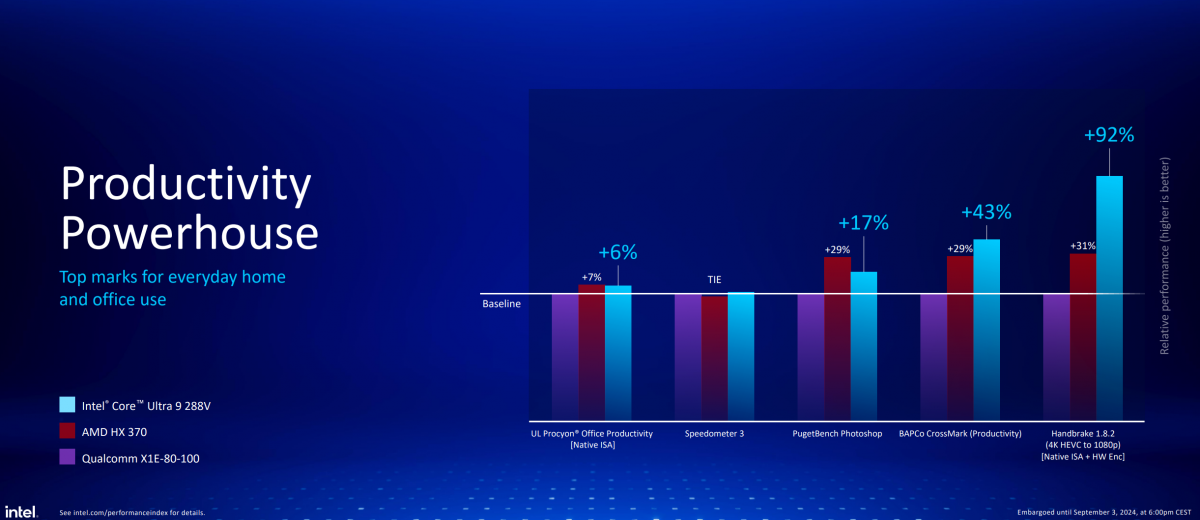
媒体转码的性能优势,可能与Lunar Lake的硬件或指令加速有关。不过在核心与线程数明显少的情况下,于系统层面表现出这样的性能,还是超出了我们的预期的——尤其还要考虑到这里对比的AMD HX 370是个TDP更高的竞品。
我们认为,在渲染测试这类追求绝对多线程性能的场景下,Lunar Lake相较更高功耗段定位的其他选手有所不及是理所应当。但Lunar Lake的设计,颇给人当年Pentium M问世时的即视感——效率大幅提升,不再盲目追逐高频与多核。
这是IPC、频率、核间通信延迟,乃至全系统PPA权衡的结果,成效还是相当瞩目的。有关核心之间的延迟,此处多提一句:Intel在媒体会上特意用一页PPT展示了“低延迟结构”,提及E-core间通信约23ns延迟,P-core间为26ns左右;
更重要的是E-core到P-core不同集群间通信延迟也控制在了55ns,赤果果的对AMD和高通的讽刺...毕竟后两者的这一值高了3-4倍。加上片内集成DRAM,带来了更低的访存延迟(较片外方案低了30-40%),这应该也是系统性能及某些多线程性能测试时,Lunar Lake能够凭借更少的线程数有一战之力的关键。

展区内,赛车游戏的性能对比——这次Intel拉AMD和高通对比,真是完全没在客气
图形与AI性能一览,主打嘲讽对手的生态
说完CPU,就该看看GPU和NPU了。在架构解析文章里,我们也对这代iGPU所用的Xe2架构进行了详述。新架构的特点在于整体规模进一步扩大,且加入了XMX这种更偏AI加速的矩阵单元。所以Lunar Lake核显的图形性能提升1.5倍,AI性能是前代的3.5倍。
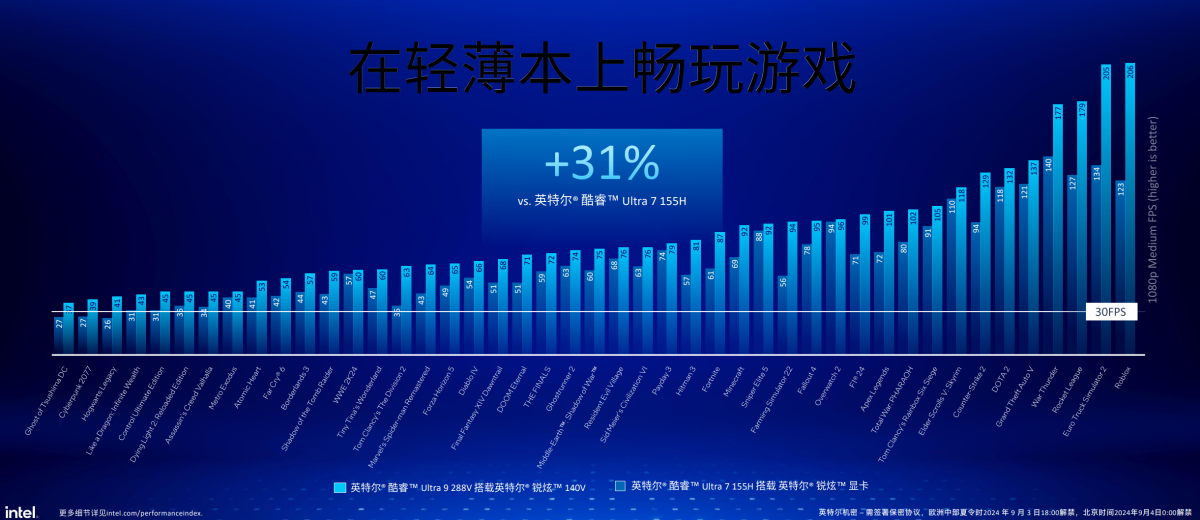
满血版Arc 140V核显配置的Lunar Lake,实际游戏性能相比前代(酷睿Ultra 7 155H)提升约30%。某些游戏的帧数提升梗显著,比如《F1 24》帧率提升了40%,《霍格沃茨之遗》提升60%,《全境封锁2》提升80%。在开启XeSS的情况下,因为有XMX的加速,游戏性能提升幅度则可达到60%。

Intel在展示区直接展示用Lunar Lake笔记本跑《古墓丽影》和《赛博朋克2077》的benchmark,1080p中画质下,开启XeSS超分的情况下,竟然也有60-70fps的平均帧了
除了在竞品对比中,在这45款游戏测试里,Lunar Lake相比AMD Strix Point 核显游戏性能高出约16%;主打的还是嘲讽骁龙X Elite跑不了这其中超过一半的游戏,即便能跑Lunar Lake也在游戏性能上领先68%。
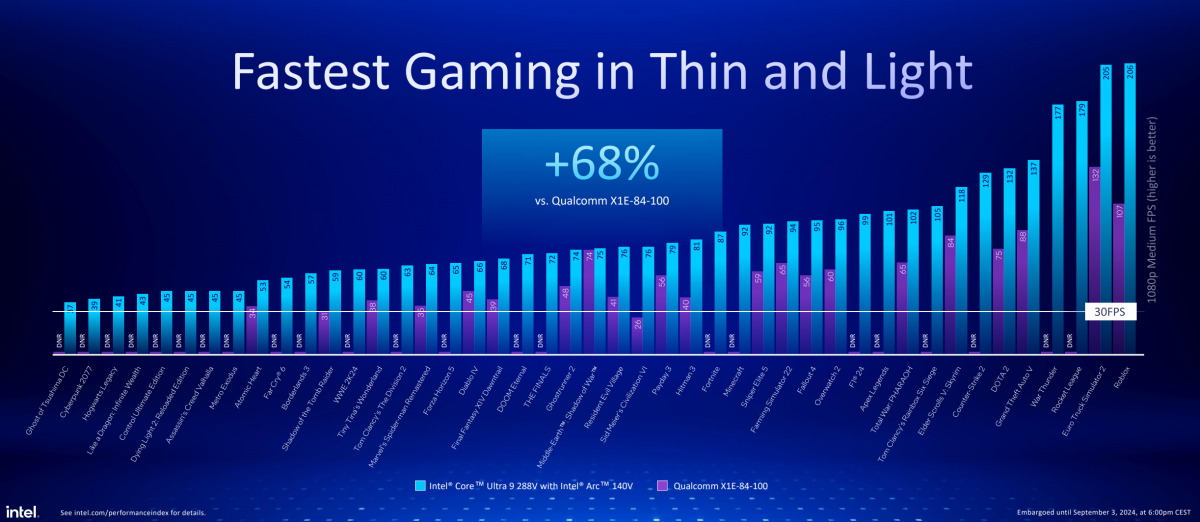
更多有关核显媒体引擎、光线追踪等子项测试数据,受限于篇幅不做展开。
不过基于Windows on Arm生态的不健全,及高通在Windows平台上于图形和AI标准支持的不完善,媒体会现场有关骁龙X Elite某某测试跑不了的梗也算是此起彼伏了。不单是图形和游戏测试、要在GPU上跑Stable Diffusion 1.5、以及某些AI benchmark的FP16精度都跑不了也是常态…
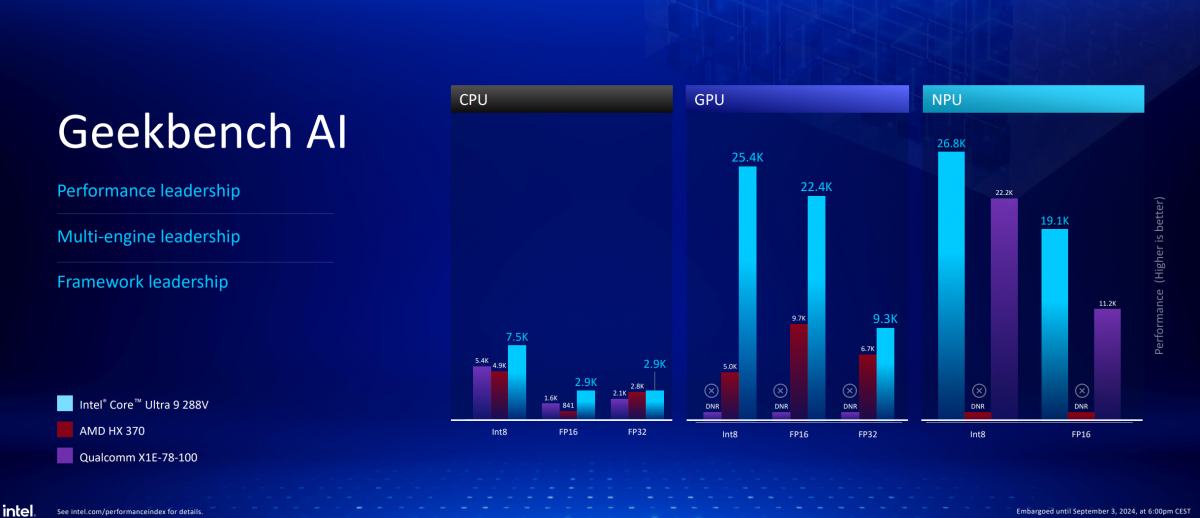
所以对于AI处理器的属性而言,Intel自然一方面是要强调120TOPS总算力:除了Copilot+PC概念达成之际,微软不忘给Intel站个台,Lunar Lake在UL Procyon AI的计算机视觉和图片生成测试里,也都领先于竞品。
但另一方面,Intel要强调的似乎仍是结合CPU+GPU+NPU的XPU策略,体现AI绝对算力的同时,也追求灵活性。所以很多对比要么是谈竞争对手的核显无法进行AI加速,要么是说竞争对手无法以FP16精度进行AI推理。
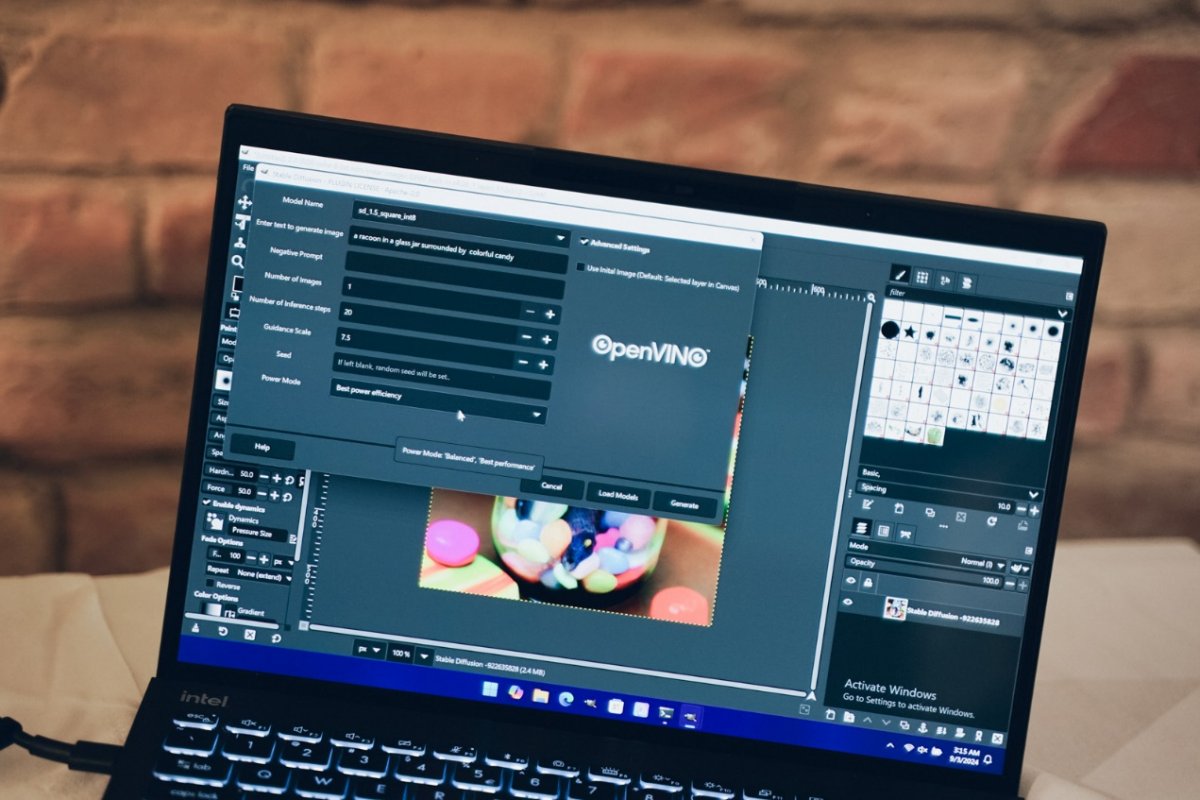
性能展示区内的Stable Diffusion测试,多出了性能模式、高效模式的选项,前者让SD诸环节都跑在GPU上,而后者则令负载都跑在NPU上,主打的也是灵活性——颇有一种,速度我最快、效率我也能最高的即视感
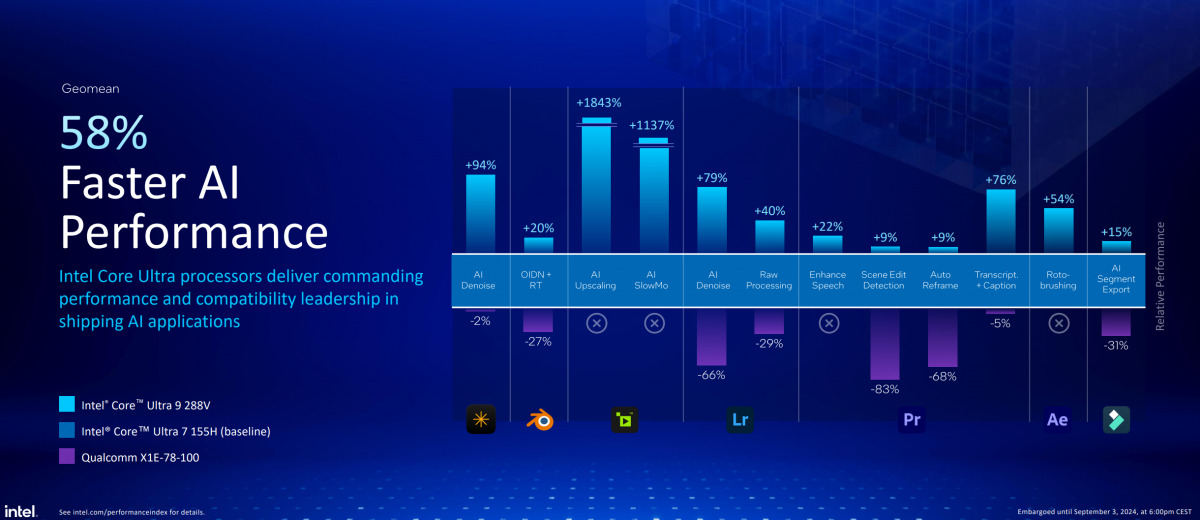
AI性能数据对比呈现上,我们认为颇有价值的是在现有内容创作工作流内,融入的AI特性,不同处理器表现出的性能差异。包括Adobe全家桶、Blender等工具内逐渐融入更多的AI特性,寻求GPU/NPU的AI推理加速。
高通仍然是吃了生态系统的亏,某些app本身实则都还没有原生版本,更不必说需要开发者适配NPU加速的AI特性实现——何况NPU相较GPU,面向开发者时也更不友好。在整个AI PC生态内,抛开英伟达不谈,Intel大概的确是在AI应用、AI模型支持,及整体AI开发生态上做得相对完善的PC处理器企业了。
实际上,展区内Lunar Lake的应用展示及性能对比,绝大部分都是围绕AI PC进行的:发布会上找来的操作系统、OEM及ISV合作伙伴普遍也是在AI PC上做文章。只不过本文的下篇将把注意力更多放在AI上,此处也就不再做相关AI PC的更多阐述了。
这次发布会上Intel有个理念宣导还是比较靠谱的:出色的AI PC首先必须是一台出色的PC。即在谈AI特性以前,PC原本追求的性能和效率不能丢:AI是在此之上的技术延展。这可能对应到Intel在媒体会上所做上述性能对比的前言:
这些对比数据并非来自Intel自己的参考平台,而基于已有OEM产品的真实数据。甚至“在用户上手产品之时,还有机会看到比以上对比数据更出色的结果。”“我们这次给出的数据是比较保守的。”无论是操作系统设置,还是对比三方对象的选择,“在某些数据的呈现上,我们甚至把自己放在了不那么有利的位置。”
虽说嘲讽骁龙还是我们头一次在Intel的发布会和演示中看到,但Lunar Lake的确更像是Intel于追求高频多核心以及堆料之后,做深刻思考的力挽狂澜之作。而且它并不单纯建立在AI PC的热点之上,而是从多方位给到了PPA、用户体验的优解。
