
Cerebras公司发布了第三代晶圆级芯片,单个器件可提供125PFLOPS(FP16精度)的性能。在一天时间内,安装四个芯片的设备就能对Llama2-70B进行微调,而安装2,048个芯片的最大设备则能在同一时间内从头开始训练。
Cerebras公司首席执行官Andrew Feldman(图1)向笔者表示,该第三代晶圆级引擎(WSE3)在相同的15kW功率范围和相同的成本下,将WSE2的大型语言模型(LLM)训练速度提高了一倍。
Feldman表示,其战略合作伙伴G42基于WSE2的AI超级计算机系列Condor Galaxy的部署进展顺利。Condor Galaxy 2已按计划投入使用。该系列中的第三台超级计算机Condor Galaxy 3将使用全新的第三代WSE3硬件。G42还选择在Condor Galaxy 3中安装“大量”的高通Cloud AI 100推理专用硬件。为此,Cerebras与高通合作,调整了训练过程,以便针对高通Cloud AI 100芯片上的推理对所产生的模型进行优化。Feldman表示,与未优化的模型相比,这项工作使性能提高了10倍。


图1:Andrew Feldman。(来源:Cerebras)
WSE3
WSE3的物理尺寸与前几代产品相同,但在空间上增加了很多(图2)。新芯片已从台积电7nm工艺转移到台积电5nm工艺,内核数量从上一代的85万个增加到90万个。内核也更大。总体而言,与上一代的26万亿个晶体管相比,差异是4万亿个晶体管。
Feldman说:“我们根据过去五年部署系统的经验,对架构进行了一系列改进,并采用了稍大一些的内核。”

图2:Cerebras的第三代晶圆级引擎。(来源:Cerebras)
该WSE还具有42GB的SRAM,内存带宽为21PB/s。SRAM可以通过Cerebras提供的大型外部DRAM子系统进行扩展,以训练多达24万亿个参数的AI模型(大约是GPT-4和Gemini等当今模型规模的10倍)。即使是最大的模型,也可以存储在单个逻辑内存空间中,而无需分区或重构。
WSE3的系统名为CS3(图3)。最大集群规模已增加到2,048个CS3(FP16计算能力高达256ExaFLOPS)。
“有了2,048个CS3,你就可以利用Meta最大的GPU集群,在一天内完成需要在一个月时间才能完成的工作,”他说,“你可以为企业用户带来超大规模企业独享的计算规模。”
当被问及具有2,048个CS3的集群何时才能成为现实时,Feldman果断地说:“今年。”

图3:安装在加利福尼亚州圣克拉拉Colovore公司的CS3。(来源:Cerebras)
软件栈
Cerebras的软件栈支持Python 2.0,并支持所有模型类型,包括最大的多模态LLM、ViT、专家混合和扩散。它还支持非结构化稀疏性和动态稀疏性(针对训练过程中出现的零)。
使用数千个GPU训练一个175B版本的Megatron需要超过2万行的Python、C++、CUDA和HTML代码,他指出。Cerebras只需要565行Python代码,一名工程师一天就能完成,Feldman补充说。
Condor Galaxy 3
Condor Galaxy系列AI超级计算机的第三个集群将在德克萨斯州达拉斯市建立,它将拥有64个CS3系统,总计8ExaFLOPS的FP16计算能力。
CG3将加入到加利福尼亚州圣克拉拉的CG1和加利福尼亚州斯托克顿的CG2当中,后者都拥有64个上一代CS2。Condor Galaxy 1训练的模型包括最著名的阿拉伯语LLM Jais-30B和G42的临床LLM Med42(图4)。
在FP16时,CG 1、2和3提供的总AI计算能力将达到16ExaFLOPS,但Feldman表示,随着Condor Galaxies 4到9的投入使用,到2024年底,该超级计算机系列的总计算能力将达到55ExaFLOPS。

图4:Condor Galaxy 1内部。(来源:Cerebras)
推理硬件
G42还首次为Condor Galaxy 3增加了仅用于推理的硬件,其规模旨在为CG3将要训练的大型模型提供推理。G42已选择高通Cloud AI 100器件来处理推理工作负载。
“如今,Cerebras并不专注于推理,除了国家安全和国防领域的一些非常困难的推理问题。”Feldman说道,“我们没有推理产品,我们只进行训练。”
Cerebras一直在与高通合作,以实现从Cerebras CS3上的训练到高通Cloud AI 100上的推理的一键转换(图5)。两家公司还共同致力于推理感知训练,从而与在相同高通芯片上运行的未优化版本的LLM相比,速度提高了10倍。
“直到最近,几乎所有的计算都是在训练中进行的,但随着我们从AI业余爱好的环境转向AI生产,训练并没有减少,但推理却在增加。”Feldman说,“对于超大规模企业来说,这不仅仅是一个抽象的问题,对于一些规模最大、最具前瞻性的公司来说,这也是他们在考虑投入生产时所面临的问题。”
这项工作使用了四种主要技术来定制Cerebras训练的模型,以便在高通Cloud AI 100器件上进行推理:
稀疏性是Cerebras的秘密武器之一,因为该公司能够在训练期间利用动态、非结构化的稀疏性。高通的Cloud AI 100硬件支持非结构化稀疏性,可以跳过所有会浪费能源的乘以零的操作。这种稀疏性协同作用可以使性能提高2.5倍。
推测解码是一种前景广阔但迄今为止难以有效实施的行业技术,也被用来加快速度。该技术使用大型LLM和小型LLM的组合来完成一个大型LLM的工作。小型模型的准确性较低,但效率更高。大型模型用于检查小型LLM创建的句子的合理性。总体而言,这种组合效率更高,因为大型LLM在这里只是检查词元(token)组合的概率,而不是生成词元。由于总体计算量更少,这种技术的速度可提高1.8倍。
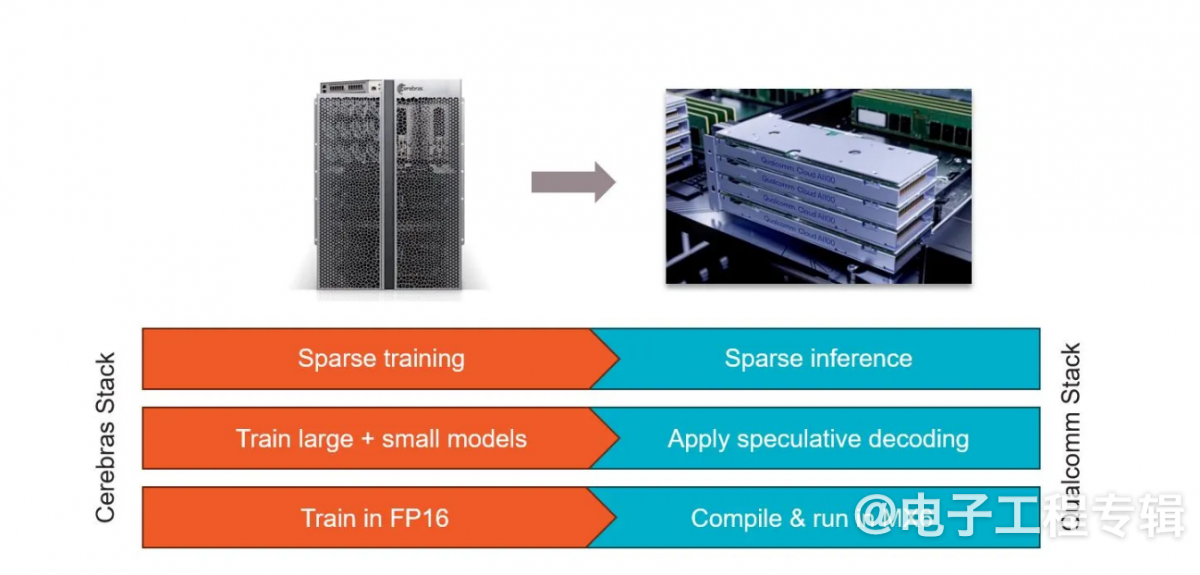
图5:Cerebras和高通一直在合作优化高通硬件上的推理模型。(来源:Cerebras)
将权重压缩为MxFP6,这是一种业界通用的6位微指数格式,与FP16相比可节省39%的DRAM空间。高通的编译器可将权重从FP32或FP16压缩为MxFP6,而Cloud AI 100的矢量引擎可在软件中即时解压缩为FP16。据高通称,解压缩确实会产生开销,但它通常是与其他任务并行执行的,因此大多是隐性的。这项技术可将推理速度提高2.2倍。
神经架构搜索(NAS)是一种著名的推理优化技术,也已被采用。该技术在训练过程中会考虑目标硬件(在本例中为高通Cloud AI 100)的优缺点,以支持在该硬件上高效运行的层类型、操作和激活函数。Cerebras和高通在NAS方面的工作将推理速度提高了一倍。
这些组合带来的总速度提升高达10倍。
“这些创新能够真正推动市场的发展。”Feldman认为,并补充说,与高通的合作“提供了改变整个市场的范围、容量和工程能力。”
Cerebras表示,该公司有“大量”的CS3订单积压,涵盖企业、政府和国际云。
(原文刊登于EE Times美国版,参考链接:Cerebras' Third-Gen Wafer-Scale Chip Doubles Performance,由Franklin Zhao编译。)
本文为《电子工程专辑》2024年9月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
