
可能大部分人对于AI PC于设计行业的印象,还停留在借助Stable Diffusion文生图的层面。而且几个月前,我们也的确看到,已经有数字艺术家借助RTX AI PC及各种AI工具来做严肃的商业设计,直接转化成生产力和钱的。
但在最近的GeForce RTX 40系列媒体品鉴会上,我们看到B站up主特效小哥008已经开始用生成式AI做3D建模了——一套丝滑工作流涵盖文生图(text-to-image)、图生3D模型(image-to-3D),而且真正用到了商业CG成品中。
结合前不久Computex上,NVIDIA发布RTX AI Toolkit,还有诸如面向RTX AI PC的ACE 、NIM等工具,NVIDIA眼中的AI PC能用来赚钱,或者说正儿八经用于生产力的属性显得愈发明朗。AI PC就不再是“有什么用”的问题,而应该是“能发挥多大作用”的问题。

从云走向端,用AI PC做3D设计
去年3月份的GTC开发者大会上,NVIDIA曾发布过一个名为“NVIDIA AI Foundations”的云服务。这个云服务有三个板块:Nemo、Picasso和BioNemo。
Nemo和BioNemo就不多谈了,这俩分别是定制LLM和用在药物发现方面的服务——跑在DGX Cloud上,企业客户借助这些服务,可以基于预训练模型,来做属于自己的定制模型。
而当时Picasso的演示是惊艳了不少人的——这是个文生图、文生视频、文生3D服务,也就是文字能转各种多媒体。首先当然还是借助服务做个定制模型。随后开发者可以在应用中调用Picasso,基于文字输入和元数据,就能生成图片、视频或者3D模型了。

NVIDIA演示的文生3D模型Demo,得到的3D几何体还相当细节化。生成的3D模型可以是基于USD格式的(NVIDIA现在在努力推动,应用在Omniverse生态内的一种开放3D格式)。也就是说通过Picasso服务,简单输入几行文字,得到3D模型——这个模型就能放进Omniverse中,不管是用于数字孪生(digital twin)还是3D协同设计。
往大了说,这叫为元宇宙填充内容。其时宣布的合作伙伴包括gettyimages, shutterstock, Adobe等。所以黄仁勋说生成式AI时代,人人都是艺术家。
这东西的初始形态之所以是云服务、跑在DGX Cloud上面,可能不单是基于前期扩大生成式AI应用的考量,还在于PC本地的AI算力或AI算法尚未全面准备就绪。
单看其中的文生3D模型部分,有没有感觉这次品鉴会上特效小哥008展示的图生3D模型,多少已经是相似应用,从云走向端呢?GeForce RTX 40系GPU的AI算力在200-1300 AI TOPS区间内,远高于PC领域任意集成在AP SoC内部的AI加速器。随这个系列GPU的逐渐普及,这种需求3D模型的生产力创作就成为可能。

特效小哥008在介绍他的工作流时说全流程依托于ComfyUI(Stable Diffusion的一个模块化GUI和后端)。去年7月的品鉴会上,他就已经向我们展示过借助生成式AI工具辅助完成的特效短片《Flower》。不过当时生成式AI主要是用于生成CG远处的背景图,和3D模型上的部分纹理。
这次除了AI生成场景氛围图,特效小哥008着重展示的就是图生3D模型。其流程大致上是这样的:比如要在3D图形场景中加入一把剑,则可以首先通过简笔画的方式,画个剑的形状——搭配文字部分的提示词描述,就能生成一张更为精细的剑的2D图片。
随后就是基于图片生成3D模型。“生成的结果不理想也没关系,我们可以接着‘抽卡’。”也就是多试几次,让AI给出更多结果,“效果满意之后就可以导入到场景里面了。”“场景中的远景,和一些并不是很重要、但又追求细节的东西,通过这种方式就能做出来。”

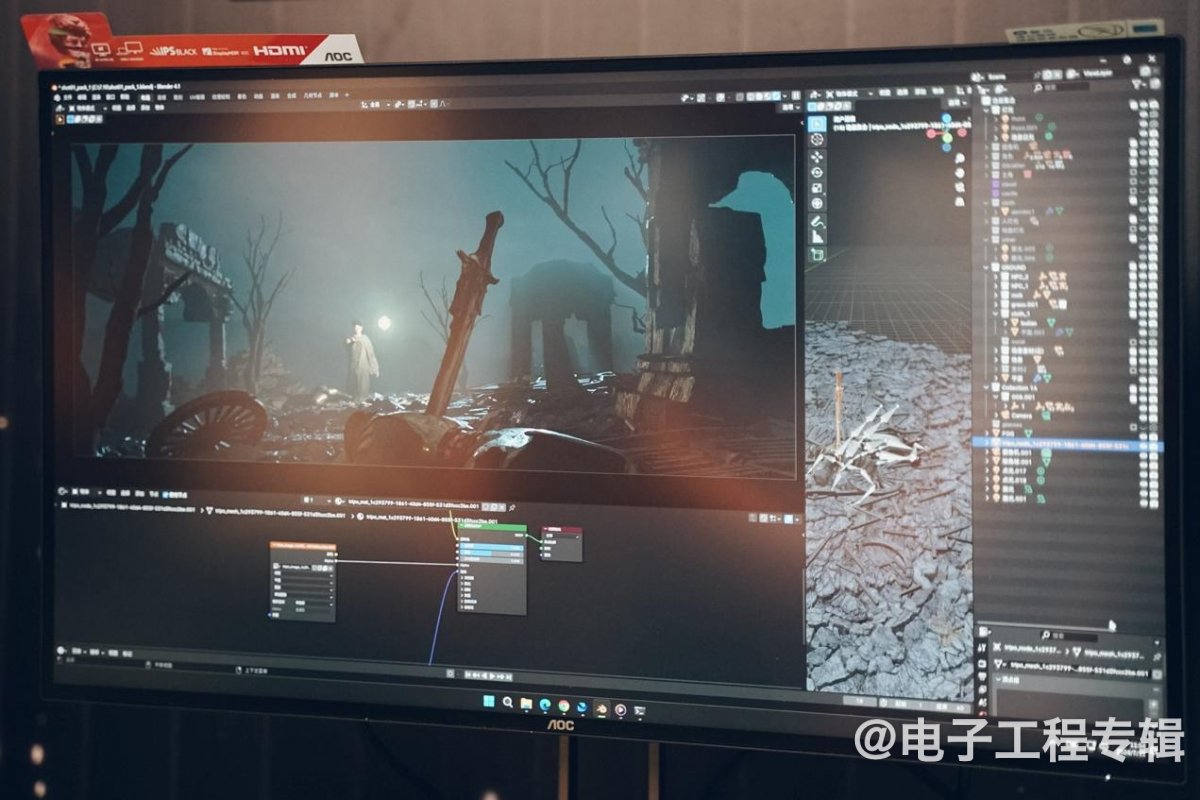
“想做近景也可以,但一般是作为参考,后续再由我们去做修改——这个过程还是比直接从零开始建模要快。”特效小哥008说,“以前要做概念图、三视图、建模,现在就方便多了。”如此一来,”整个画面,由AI生成参考图;根据参考图再用AI去做每个组成部分;最后我们做简单处理。”
“有些小伙伴有建模能力,但美术能力不怎么样。这种方式也就大幅提升了创作效率。”“而且现在‘抽卡’成本也不高,直接把需求丢进去看看结果是否符合预期,然后再去做调整。”这里的“抽卡”成本不高,实际上也是基于本地AI推理速度足够快(演示基于GeForce RTX 4090D)。

特效小哥008还提到,他平常出差还是更常用笔记本借助AI生图工具去提作品修改的直观建议
其一是GeForce RTX 40系GPU作为RTX AI PC的硬件基础;其二在于面向ComfyUI Stable Diffusion的TensorRT节点加速,应该也是从大半年前就开始的。虽然这次没有从具体数值上展示加速效果,不过现场演示的从简笔画到最终出3D模型速度,还是相当快的。
从演示来看,这套工作流的关键定制节点可能至少包括了PainterNode、TripoSR(似乎还有BRIA RMBG?)。尤其这里的TripoSR是个基于图像做3D重构的开源生成式AI模型——此前Stability AI发布TripoSR时还强调过这个模型性能远超同类模型,官方数据是A100在大约0.5秒内可生成草稿质量的3D输出。
现在Youtube和Reddit等社区有关利用ComfyUI构建图生3D模型工作流的教程还挺多。这个行业看起来的确是最先被AI技术推着走了。而显卡算力提升、中间件加速,和模型优化,都是端侧这番演示能够呈现在我们面前不可或缺的组成部分。
RTX AI PC好像也的确是现阶段,唯一能达成上述效果的解决方案——这端侧AI生产力还真妥妥地继续被NVIDIA拿捏了。
从ACE PC NIM谈起,RTX AI PC的开发生态
GeForce RTX 40系列媒体品鉴会展示了近一年的演示重点少不了NVIDIA ACE(Avator Cloud Engine)。这项技术反映在游戏中,就是游戏NPC能像ChatGPT那样,和玩家进行各种对话——一边体现交互的灵活性,一边还和游戏剧情密切相关。
这次活动上,NVIDIA又对ACE的游戏Demo做了强化:场景中出现了一个新的NPC人物。这个人物和Demo主线剧情关系并不算太大;但他能宣传NVIDIA和各家OEM、板卡厂商的产品和技术。

NVIDIA ACE演示新增的游戏NPC
当时据说NVIDIA和InWorld为包括七彩虹、华硕、技嘉等各厂商,在他们的展位上定制了不同版本的Demo。与图中展示的这个NPC人物对话,该NPC就能专门针对特定厂商的产品做宣传。比如让他介绍NVIDIA的DLSS 3技术,追问各种技术细节都不在话下。这名新NPC的加入,无疑是为了更明确地展示对开发者而言,角色NPC的可定制性。
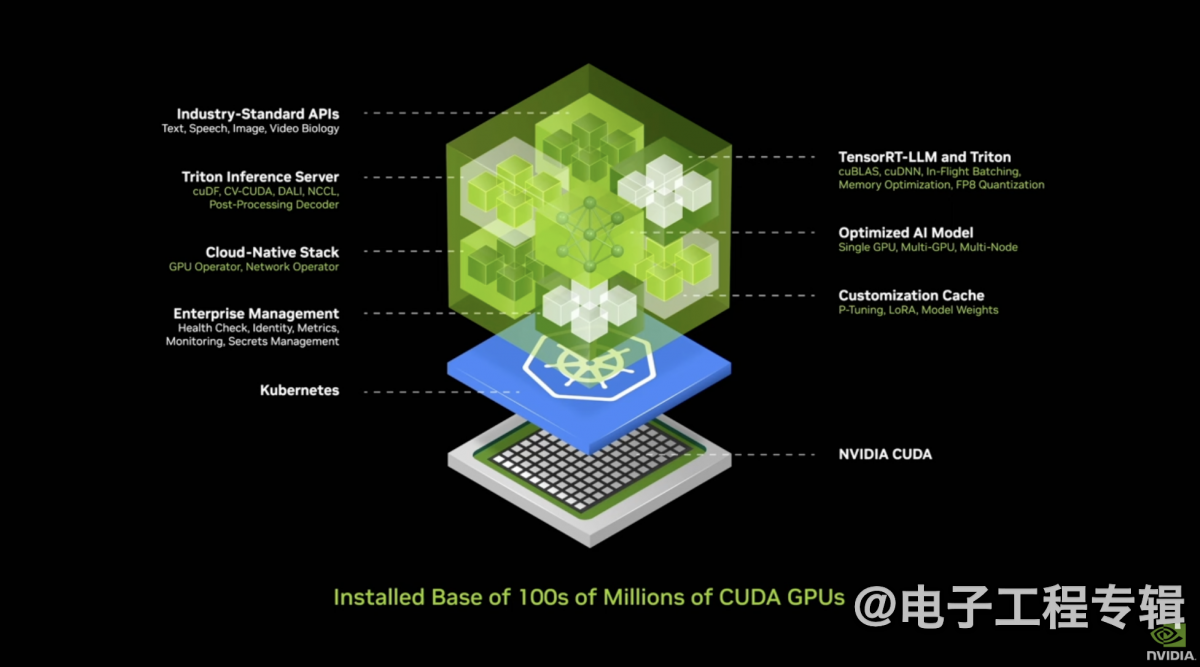
Computex 2024上,NVIDIA特别发布了NVIDIA ACE PC NIM微服务。有关什么是NIM(NVIDIA Inference Microservice),此前我们也不止一次撰文探讨过。这是个面向企业客户或开发者的“AI in a box”——盒子里面包含各种模型、软件、工具、环境。
企业或者开发者用里面的工具,基于自家数据就能fine-tune这些模型,然后将这一堆东西部署到想部署的地方,包括AI PC。我们此前评价NIM,是大幅降低企业和开发者使用生成式AI难度的打包服务;对英伟达而言则是接下来要快速扩张生成式AI的产品。
换句话说AI开发者不再需要把太多注意力放在怎么搞AI、怎么搭环境之类的复杂问题上,而可以将注意力放在业务逻辑上。Computex上发布的NIM,其实不只有ACE或游戏。具体到ACE和游戏领域,自然就是便于游戏开发者去用生成式AI技术,能够把更多资源真正放在游戏内容、而不是AI技术开发上。
NVIDIA ACE本质上为开发者准备的是一种数字人技术——游戏NPC就是一种典型的数字人。这次新加的这名NPC角色,显然已经有行业零售应用那味儿了(推销嘛)。无论对行业客户,还是对游戏开发者,ACE都可以通过NIM融合到其现有应用的框架、引擎中。
另有一点值得一提。对ACE比较熟悉的读者应该很清楚,这是个端云结合的生成式AI应用:云上主要做LLM推理,PC端侧负责语音转文字、唇形同步等推理步骤。
有关端云协同问题,这次比较有趣的一则探讨是,我们此前普遍认为,LLM/SLM放在本地推理问题也不大——什么7b、13b规模的模型,借助GeForce RTX显卡跑起来,效果都不错;延迟也远低于数据去云上转一圈。
NVIDIA现场的工作人员说,游戏场景内显卡本身的大量算力需要用于图形渲染,还要考虑光追等算力密集型应用,DLSS则需要占用Tensor Core资源;如果同时还要做本地LLM推理,从带宽、功耗等角度可能都有商榷余地。所以端云协同是个很优的解决方案。
或许NVIDIA在最初构思ACE的技术框架时,就尝试过这套方案完全跑在本地的可行性。不过工作人员还说:“对于游戏来说,如果游戏开发者对NPC交互的要求并没有那么高,仅专注于游戏内容本身,其实数据量要求并不太大。比如我们可以通过SLM(小语言模型)来实现,那就有本地跑生成式AI的潜力。所以最终要看游戏开发商如何去平衡这个问题。”
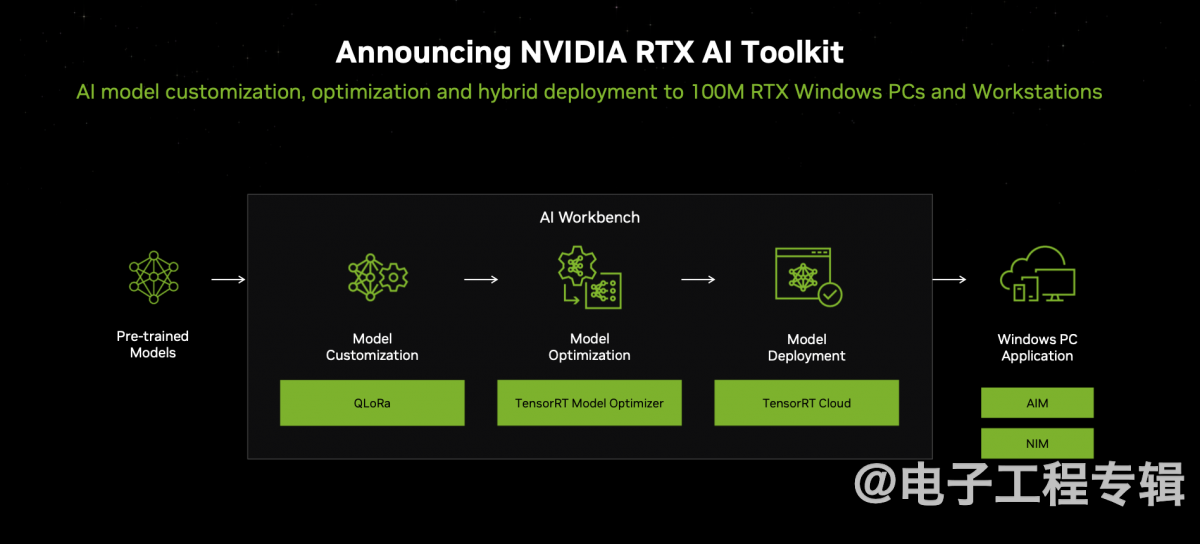
最后,虽然本次品鉴会上并没有对应的展示,但Computex 2024上英伟达还面向AI PC做了两个比较重要的发布。其一是NVIDIA RTX AI Toolkit工具,帮助Windows应用和游戏开发者,去定制、优化和部署AI能力,并且能够在PC端侧和云之间去做推理的AI编排工作。
全流程这样的:基于预训练模型可以采用QLoRa工具来做模型定制;然后用TensorRT模型优化器做优化;再借助TensorRT Cloud做模型部署;在应用侧,开发者借助AIM(AI Inference Manager),外加前文提到的NIM,最终让模型推理在云或RTX AI PC之间进行。
据说走这套流程,可以实现模型的大幅优化:比如如果用Llama 3适配游戏角色NPC对话,则首先这套流程能做游戏角色的模型定制;其次是原本GeForce RTX 4090D才能跑得起来,经过RTX AI Toolkit,用RTX 4050 Laptop就能跑。
当时NVIDIA给的数据是,优化前LLM需要17GB VRAM,推理性能48 tokens/s;用这套工具对模型做优化之后,显存需求降低到5GB,推理性能187 tokens/s。
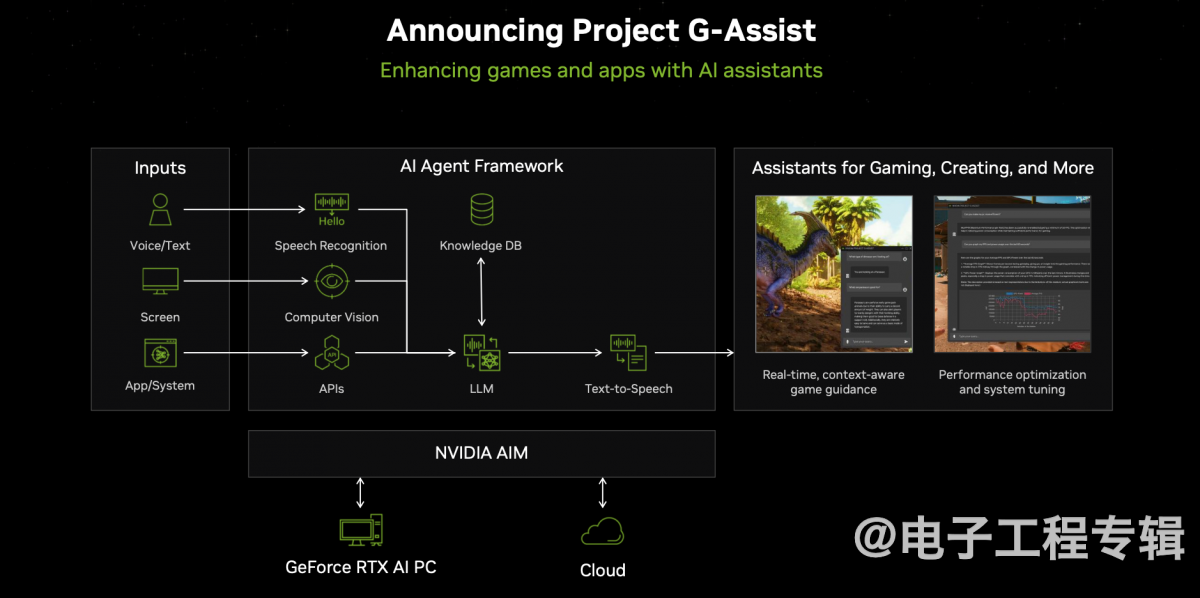
还有G-Assist项目,此处也简略谈一谈:游戏接入这项特性,就能给玩家提供AI助手。玩家可以和该AI助手进行语音或文字交互。这个技术主要考虑的是当游戏玩法或系统较复杂、多样时,玩家可以快速获得相关游戏内容、游戏过程中的系统性能,乃至基于自己的PC配置怎么进行游戏设置才能达到最佳体验等信息...
这些都算得上是RTX AI PC生态构建的组成部分,尤其将注意力放在了NVIDIA现如今最擅长的生产力和游戏方面。
人人都是艺术家、人人都是程序员
以上两个Demo,是我们认为极具代表性的、现如今AI PC可以达成设计和开发的高水平应用——即便可能ACE和RTX AI Toolkit的使用和开发,本身未必是基于AI PC;但它们最终的产品形态都是要落地到AI PC(或其他边缘设备)的。
除此之外,本次GeForce RTX 40系品鉴会还有一些我们早就见过的Demo。比如说ChatRTX——可以一键安装的本地检索增强生成工具,现在也支持中文大语言模型ChatGLM 3-6B,配合RAG指向本地文件夹,可基于用户的本地资料进行对话;也支持CLIP,也就能够通过文字描述,精准找到图库中对应的图片...

用CLIP模型,基于输入的文字描述直接找到对应的图片
再比如已经进入beta测试阶段的NVIDIA App,用于替代以前的GeForce Experience和NVIDIA Control Panel。NVIDIA App本身加入了一些AI特性,比如两个基于AI的游戏滤镜RTX动态亮丽和RTX HDR。
还有RTX Video,在浏览器中看流播视频,就能进行本地的AI超分、SDR→HDR;乃至“万兴喵影”基于该SDK,已经支持将SDR视频转为HDR色彩空间的视频并导出...
其实这场品鉴会的重头戏还在于《三角洲行动》,《鸣潮》,《解限机》和《漫威争锋》这些即将支持DLSS 3的游戏Demo展示。游戏体验部分虽然不是我们关注的重点,不过看到《解限机》这类游戏呈现的机甲画面,我们也在慨叹现在的游戏建模、纹理和光影的精细程度,即便是即时演算呈现出来的效果,也远超早年的CG过场动画了。

《解限机》游戏Demo画面
要知道当年那些仅几分钟的CG动画,可是专业卡渲染几天才能最终出片的;而现在却能够在消费级显卡上以实时光线追踪+DLSS的方式,进行上百帧的游戏交互。一方面是体现出图形技术的发展,另一方面则是DLSS这样的AI技术着实为高画质+高帧率呈现立功不小——这些还真的不是光靠传统半导体技术和摩尔定律推动可发展至此的。
不知道现在有没有游戏工作室,大范围应用文生3D或图生3D模型的工作流,毕竟游戏交互和单纯的CG或广告片制作还是不同。不过像RTX Remix这样的Mod制作工具,借助AI来重塑高清和增强纹理大概已经提供了这种可能性。
而在RTX AI PC的加持下,生成式AI时代大概真的就是“人人都是艺术家”“人人都是程序员”的时代。

