
AI乃至生成式AI逐步走向边缘已经是这个时代无需言说的主旋律,在今年WAIC(世界人工智能大会)展会上逛一圈就能感受到这一趋势的浓墨重彩。不单是AIPC和AI手机,我们在爱芯元智展位上看到一款爱芯通元AX630C芯片,这是颗小芯片——Int8算力3.2TOPS,典型功耗<1.5W。
“这是我第一次看到(大模型在)这样一颗小芯片上跑起来,我相信不远的将来,大模型在边缘侧的落地一定会更进一步。”爱芯元智创始人、董事长仇肖莘在采访中说,“应用场景会非常多样,有无限可能。”
爱芯元智联合创始人、副总裁刘建伟在演讲中说这颗芯片能跑通义千问,“实现意图理解、进行简单对话”。从参数上来看这颗芯片可推理Qwen2 0.5b模型,速度达到10 tokens/s。“这也就意味着端侧智能可以装入到我们身边不同的电器里面。”


AX630C开发板,散热片下面的应该就是AX630C了
当然这个例子表达的是边缘生成式AI更进一步的潜在可能性。在《电子工程专辑》6月刊的封面故事采访中,刘建伟就提过位处边缘、主要用于推理的NPU既不应该是神经网络加速器,也不应该是基于通用计算的扩展指令集实现,前者的问题在于灵活性的缺失,后者则在大规模并行tensor计算上表现出性能和效率的不济。
爱芯元智的思路是要做“原生AI处理器”,实现AI计算的经济、高效和环保。WAIC活动上,与仇肖莘的对话,以及刘建伟的主题演讲,都给了我们有关边缘AI的更多启示。相比前两年AI芯片初创企业与雨后春笋般铺陈的蛮荒时期,如今的AI芯片有着怎样的不同?边缘和端侧要跑生成式AI,还欠缺什么?
前两年量产:现在还是跑Transformer“最佳”
爱芯元智早于2022年量产的爱芯通元AX650N芯片,“今天依然是市场上跑Transformer网络最佳的处理器,跑SwinT能耗比达到199FPS/W”。刘建伟此前在接收采访时的这番话,还是给我们留下了深刻印象的。
这里的SwinT是典型应用于CV领域的Transformer架构的模型。仇肖莘在演讲中给出了一组数据,用以表明AX650N的能效相较于“友商”12倍的优势。这里的友商毫无疑问就是英伟达了——从标称100TOPS算力,及前缀NX来看,可能是Jetson Orin NX,也就是Ampere架构的GPU。
这组数据都比较了MobileNet-v2、ResNet50、YOLO-v5s,以及SwinT。无论是能耗比(FPS/W)还是有效算力(FPS/TOPS),爱芯通元AX650N都有比较大的优势。AX650N在SwinT网络推理上相比于英伟达的Ampere,也的确有着显著优势。
其实MobileNet-v2之类的网络推理优势并不令人感觉到太意外,毕竟爱芯元智的NPU走的是DSA路线,表现出相较通用GPU的效率优势是合理的。
当我们考虑芯片设计需要12-18个月,以及面向客户和终端产品问世的周期,AX650N立项的时间理论上是CNN(卷积神经网络)风行时期。而以Transformer网络结构为基础的ChatGPT的爆发已经是2022年底的事情了,那么AX650N是如何做到在这个时代“依然是”“跑Transformer最佳的处理器”的?

爱芯通元AX650N
“研发还是要有前瞻性。”仇肖莘说,“2021年初这颗芯片立项,原生支持Transformer,很大程度要归功于爱芯通元NPU是AI处理器的设计思路,从一开始就考虑各种模型结构包括Transformer等模型的算子支持,爱芯通元AI处理器以算子为指令集,完备的算子指令能够对各种网络结构进行高效支持。”
以Transformer于AI领域横扫这个时代的势头,“这就是前瞻的重要性,这样芯片平台才能走在应用的前面。”实际上应当不止于算子的支持,“AI处理器架构层面也有一些小细节,例如计算访存比的考虑,不同异构计算单元的配比等方面。”
与此同时,“爱芯元智在Transformer网络端边侧落地方面已经走在行业前列。”刘建伟说,“一方面爱芯元智的Github上已经有大量基于Transformer网络的应用demo;另一方面爱芯元智的客户也已经在AX650N这颗芯片上实现了基于Transformer网络的应用落地。例如通过以文搜图、开集检测等。”
比GPU高效“12倍”:怎么做到的?
“并不是英伟达做得不好。”“在边缘侧、端侧,我们认为GPGPU不是最好的架构。”仇肖莘再度谈到DSA架构路线与GPGPU路线,在可编程性与效率方面的权衡。“在过去10+年的发展过程里,CNN网络的基础结构已经趋于稳定。”“CNN主流的模型结构无外乎那几个,算子也基本固定了。”
“固定的好处,在于我们可以将基础算子在芯片中硬化,那么芯片的成本、功耗、运算效率都会很高。”“之所以说现在DSA是很合适的架构,就是因为算子走向收敛,DSA架构就能将这些通用的算子都覆盖到。”

刘建伟所说的NPU既不应该是单纯的AI加速器,也不应该是通用处理器扩展指令集的加速,而是“原生AI处理器”,从思路上来看是“算子指令集”+“数据流DSA微架构”。仇肖莘将爱芯通元NPU称为“AI的通用计算处理器”。
首先“作为一个处理器,需要有对应的指令集”,“AI处理的指令集就是算子。”如前所述,当算子开始逐渐收敛,“只要做到算子的完备,就能支持不同AI的程序算法。”“算子指令是比较宏观的指令:我们采用宏观指令,而非基于微架构来设计,硬件本身就有了很强的架构探索空间,那么我们就可以采用数据流的微架构。”
“这是个可编程的数据流微架构。这里的灵活性不在于支持各种训练;而定位于,对训练完的模型,提供高效的运行(推理)支持。”“整个pipeline都可以在我们的处理器上跑,不需要CPU频繁参与。”相关细节如下图所示:
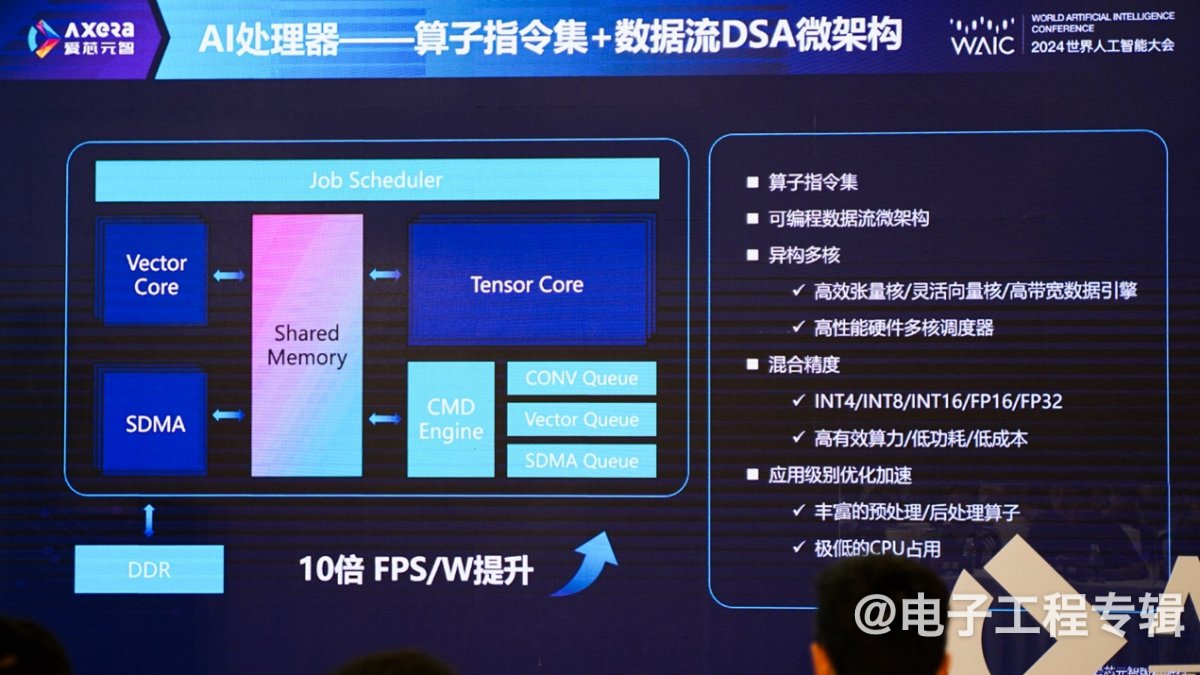
采用算子指令集+数据流的微架构,是10+倍能效优势的关键所在。开发生态相关的部分,即开发工具链,“目前也已经非常完善”,“支持我们自己和客户的量化算法”,“客户基本上可以在1小时以内,让算法在我们的处理器上跑起来。”
另外,刘建伟还提到软硬件的联合设计,基于“算子在逐渐收敛,但并未完全收敛”,以及在摩尔定律遇到瓶颈的大背景下,考虑AI处理器的经济、高效、环保的诉求,需要这样的联合设计。“这就要求我们进行对应的团队建设,要和架构做匹配。”“所以当我们有新需求时,硬件上尽量做减法,而不是被迫做加法。”
大模型走向边缘的现在和将来:联合优化
爱芯元智眼中的AI是要“走向万物智能”的,生成式AI也是其中一部分。“大模型不可能只存在于数据中心,一定会下沉到边缘侧、端侧”。有关隐私安全、模型guardrail、定制化、实时性要求等作为边缘与端侧AI要素考量,已经被提过太多次了。
而现在关键在于要让AI走向万物智能,更高效的DSA架构,及“原生AI处理器”的思路选择就成为必然。“也许再下个阶段、也许不久的将来、甚至也许是在明年这个时候,我们就会跟大家报告说,AI大模型现在可以跑在你的家里了。”仇肖莘表示。文首提到那颗3.2TOPS的AX630C显然是提供这种可能性的依据之一。
在规格特性上,爱芯通元NPU也专为跑在边缘的效率和功耗做了优化,比如说混合精度支持。“大模型的数据量很大,存储、IO成为限制算力发挥的瓶颈,混合精度就是节省带宽、存储和功耗的一个方法。”“我们从2020年第一款芯片开始就认为,混合精度是边缘侧、端侧,AI落地的关键。”“毕竟边缘侧、端侧的算力存在更大限制。”
“我们本身也在和国内很多的合作伙伴,做算法的调优、系统的优化。”“AI不光是算力越来越大,芯片跑参数量越来越多的过程,还需要芯片+算法联合调优,算法也需要做更多的优化。”实际上,包括英伟达、Intel在内的国际巨头现如今普遍在做大模型走向边缘与端侧的轻量化研究,这也是如今软件技术的主旋律。“算法从云下沉到边缘和端侧,一定是优化迭代的过程。”

“我觉得大模型落地,现在还只是开始。如今的AI大概还在brute force大力出奇迹的阶段。”仇肖莘在谈大模型于边缘与端侧AI落地的现状时说,很多潜力技术的发展曲线普遍是先有个高速追捧(hype)的过程,当达到顶点(peak)以后,“大家探索到了技术边界,后续会寻求优化。”
“我们现在连这个顶点都还没有到”,边界也还没有被触及,“任何事物的发展都不会永远是线性的,到达某个时间点增速不再呈线性,是不是就会有技术上的突破、优化方式是不是就变了?”这是在仇肖莘看来,未来的边缘和数据中心AI都要面临的议题。“我们不能指望全球的电力都拿来支持AI计算,否则国际民生就要停顿了。”
所以经济、高效、环保,才会成为仇肖莘在演讲和采访中反复提到的3个关键词,这是边缘侧和端侧AI的必选项。
深入各行各业:探讨潜在可能性
爱芯元智芯片产品已经在智慧城市、智能汽车、边缘计算等领域落地,而且现下还正把目光聚焦于具身智能。
在率先落地的智慧城市场景内,涵盖智能摄像头在内的各类视觉AI——这部分应当已经是爱芯元智手到擒来的市场了。

M76H行泊一体域控开发套件

M55H开发套件
而智能汽车,不单是智驾,“车上任何与视觉、图像相关的,我们都做”,如DMS, OMS, CMS。除了高阶智驾这种“巨头生意”,越来越多的市场走向强制的主动安全标准,就是相当大的市场机会。据说汽车应用方向上,爱芯元智这半年的芯片出货量就已经相当不错。

基于AX650N的PCIe加速卡

基于AX650N的M.2算力卡

基于AX650N的智能服务器板子
“我们的第三大市场,现在已经开始落地、出货也在往上走的是边缘计算。把边缘的CPU服务器变成AI服务器:比如我们的PCIe加速卡,以及AI盒子等等。”
属于爱芯元智市场增长的“第四曲线是具身智能”,仇肖莘谈到,“具身智能是我们现有产品形态的一个延伸。现在我们已经在跟一些客户做探讨,积累行业know-how。只不过具身智能目前所处的阶段还比较前期。”

当然这些AI应用未必都与生成式AI、大模型有关。但汽车市场,BEV Transformer的融合;更多CV应用场景中借助多模态模型实现对环境的感知和理解;乃至未来可能以NAS方式存在的家用AI服务器实现智能家居交互的颠覆等等,都是正在推进或存在巨大潜力的市场。
“在现在这个AI时代,如果我们想找一个抓手,这个抓手一定是AI芯片和多模态大模型的结合。如何让芯片能够更高效地运行多模态大模型,让大模型做到真正的调优,能够轻量化、多模态化、以更低的成本跑在端侧和边缘侧?”
仇肖莘在论坛开场时就提了这个问题。这是行业在持续探讨,也是爱芯元智在尝试解决的问题。无论是AX630C这样一颗小芯片跑通义千问的,还是AX650N立项之初就决定做Transformer原生支持……至少就现在来看,爱芯元智还是在这个问题探讨过程中走得比较正确和积极的一分子。
