
过去一年,以智能手机和AI PC为代表的终端设备在技术及外型设计上取得的长足进步令人赞叹。
Arm终端事业部智能手机市场高级总监Steve Raphael日前在Arm技术日上指出,随着AI工作负载成为了新的加速器,技术生态系统正在快速发展,计算需求要能够规模化地实现交付,上市时间和工程效率就至关重要。
由此可见,在面对越来越高的AI系统复杂性和呈指数级增长的计算需求时,系统级芯片(SoC)设计人员、OEM 厂商和软件开发者如果选错了路,将很难确保设备能够经受未来的考验。

Arm终端事业部智能手机市场高级总监Steve Raphael
“这就是Arm选择在这个时间节点发布终端计算子系统(CSS)的原因所在。”Raphael强调说,智能手机一直引领着开发者进行创新并突破平台限制,游戏和成像技术驱动着对更高效性能要求的同时还要满足新的消费者用例需求,AI正在突破计算的极限并创造出大量新的应用,Arm终端CSS希望凭借Armv9.2的能效优势、物理实现和持续的软件优化,彻底革新开发者和消费者的体验。
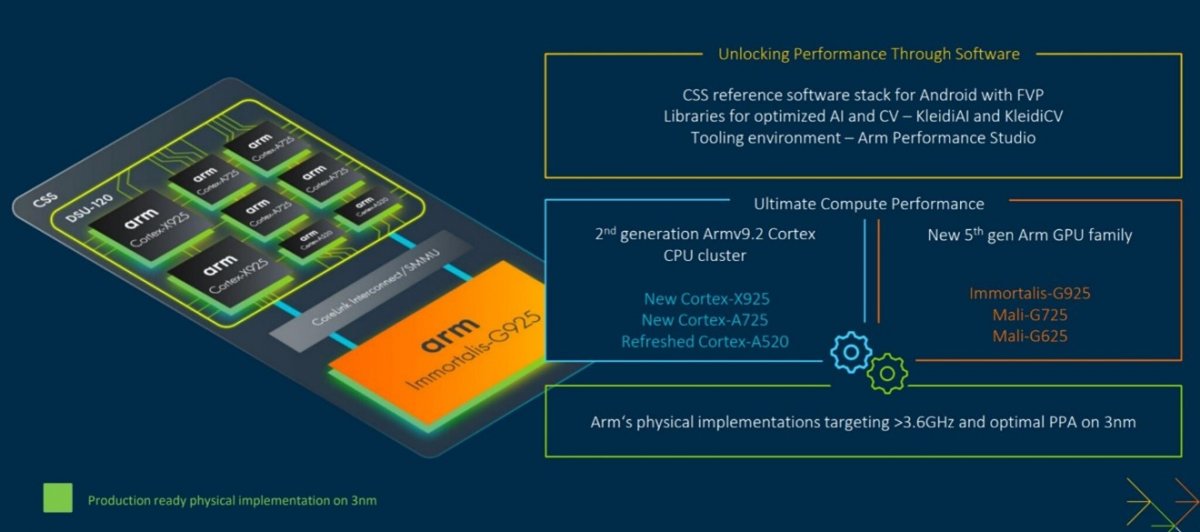
作为全面计算解决方案(Total Compute Solutions, TCS)的直接继任者,Arm终端CSS包括最新的Armv9.2 CPU、Arm Immortalis GPU、基于3纳米工艺生产就绪的CPU和GPU物理实现、CoreLink系统互连和系统内存管理单元(SMMU)。此外,Arm还同步推出了包含KleidiAI和KleidiCV的Arm Kleidi软件库,助力软件开发者无缝取得 Arm CPU 上的最佳性能。
深入了解Arm终端CSS
为了向各种移动终端设备提供无缝的计算体验,从2021年引入全新的Armv9 CPU集群、Mali GPU以及一整套系统IP产品,到2022年发布第二代Armv9 CPU集群和旗舰级Arm Immortalis GPU系列,再到2023年推出Armv9.2 CPU集群和基于第五代GPU架构的新GPU系列,Arm移动端产品在性能、效率和可扩展性方面带来的突破性变化有目共睹。
“Arm解决方案已连续三代实现两位数的性能和效率提升。在Specint和 Geekbench等基准测试中,计算性能每年提高超过15%;在各种GPU基准测试和实际游戏内容中,图形性能提升超过20%;更重要的是,我们持续实现了超过15%的同比效率提升。”Arm终端事业部产品管理总监Steve Hopper日前在Arm技术日上如是说。

Arm终端事业部产品管理总监Steve Hopper
最新发布的Arm终端CSS自然是Hopper演讲的重点。作为2024年Arm战略的一个重要里程碑,集成了硬件、软件和工具的终端CSS这一综合平台旨在为合作伙伴提供全面的计算解决方案,持续优化性能和效率,为终端设备提供无缝的计算体验。
这种端到端的整体解决方案不但确保Arm的物理实现达到了3.6GHz以上的运行频率,可以在3nm节点上提供最佳的功率、性能和面积(PPA)指标。更重要的是,其强大的可扩展性让终端CSS能够适应不同的市场、任务和应用,无论是高端游戏、专业内容创作还是日常生产力任务,终端CSS 都可以根据各种用例的需求进行定制。
当然,这也符合当前智能移动终端的发展趋势和消费者的使用习惯。据data.ai数据显示,2024年人们每天使用智能手机的时间总和高达140亿小时,平均时长5H/每天且还在不断增长(同比增长6%);其次,随着机器学习(ML)/AI组件被越来越多的集成到各种用例之中,智能手机和PC市场正在由AI重新定义。所有这一切都引发了移动平台各个层次的变革:
1. 更智能的应用:AI应用将努力设法在模型大小和精度之间找到恰当的平衡,以确保在移动设备上实现理想性能。
2. 弹性的框架:部署弹性的软件框架以因应不断变化的运营商、网络和功能演进。
3. 突破触摸屏的用户界面:用户界面将不再局限于触摸屏,而是会包括语音和视觉输入在内的多模态交互方式。
4. 计算系统:计算系统需要显著提高处理吞吐量并大幅降低延迟,以处理复杂的生成式AI工作负载。
5. DRAM:内存变得愈发重要,高带宽、高密度且能耗更低的DRAM对于高效的移动端AI运行至关重要。
6. 内存系统:想要在功率有限的移动设备上运行具有数十亿参数的强大生成式AI模型,必须优化内存拓扑。
对高端移动平台而言,针对实际工作负载优化计算性能、针对生成式AI工作负载提高性能、持续专注于提高系统能效以充分延长电池的使用时间,成为了最主要的三大驱动因素。
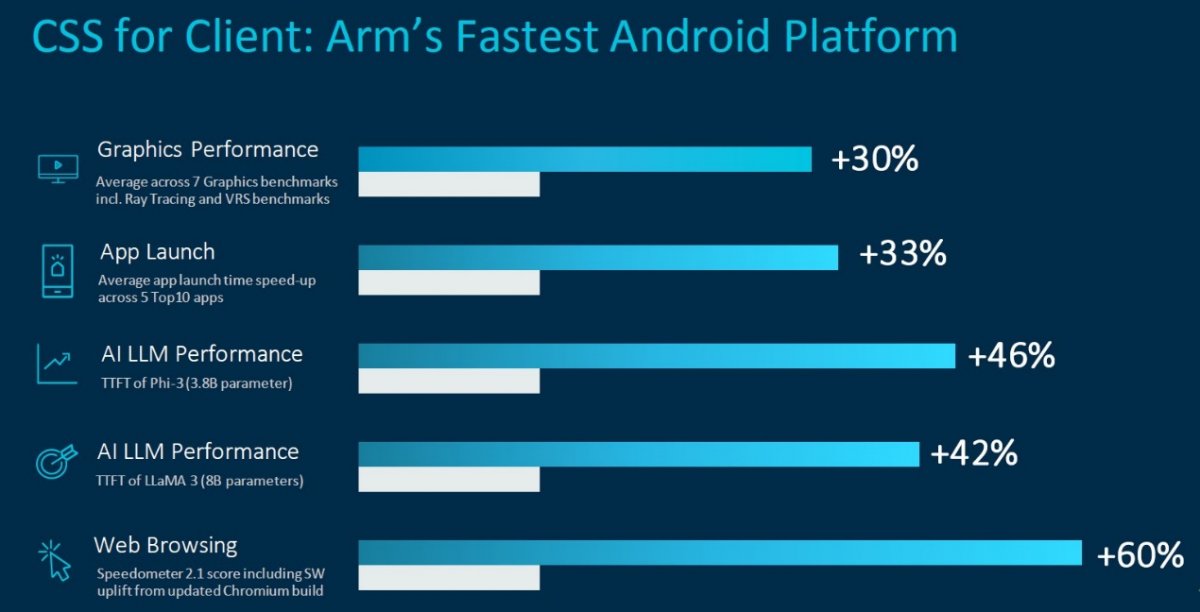
多项实测数据显示,此次推出的Arm终端CSS与 TCS23 相比:
- 在包括光线追踪和可变速率着色(VRS)在内的七个图形基准测试中,终端CSS将峰值图形性能平均提高了30%;
- 在前十大应用中,2+4+2 CPU集群将五款应用的平均启动时间加快了33%;
- 在AI大语言模型(LLM)的支持上,无论是具有38亿参数模型的Phi-3还是80亿参数的LLaMA 3,终端CSS可将词元(Token)首次响应时间(TTFT)分别缩短46%和42%;
- 根据Speedometer 2.1基准测试,网页浏览速度提高了60%;
- 在CPU上运行焦外成像工作负载算法的性能提高了24%;
- 在《使命召唤》、《暗黑破坏神:不朽》等五款游戏测试中,终端CSS在相同功率的条件下,其FPS性能平均提升37%;而在相同的120fps性能条件下,功耗显著降低30%。
Immortalis-G925在17个主流AI网络(fp16数据类型)上的AI推理速度平均提高了36%;与上一代Cortex-X4相比,Cortex-X925 CPU推理速度提升了59%;通过利用一颗额外的Cortex-X925 CPU,在17个主流AI网络中(int8和fp16数据类型)的AI推理时间大幅提升了170%。
Hopper表示,尽管摩尔定律可能正在减速,但高端移动平台的创新压力却并未减轻——“新一代用户体验需要越来越复杂的硬件和软件,导致集成、验证和实现过程被拉长。同时,基于先进工艺节点和新封装打造的高端移动芯片组往往需要更长的生产周期,这些都让合作伙伴面临着开发时间急剧压缩的困境。“而终端CSS将能够凭借出色的能效,帮助用户实现更久、更丰富的移动体验和AI性能。
全面转向3纳米工艺技术
这是Arm终端CSS的另一突出亮点,代表着半导体制造的重大飞跃,在性能、功耗和芯片密度方面均有显著改善。毕竟3nm工艺的主要优势之一是它能够在更小的面积内封装更多晶体管,提高时钟速度,从而提高性能并降低功耗,这对于移动和便携式设备至关重要,因为响应更快的计算体验、电池寿命、热管理都是关键考虑因素。
但Hopper也指出,对软IP来说,越来越复杂的微架构增加了在3纳米工艺上优化PPA的难度,在3纳米工艺上管理电压调节和di/dt环节也变得具有挑战性。此外,为了真正针对3纳米进行优化,软IP还必须考虑目标工艺节点以优化PPA。
“在工艺复杂性方面,从4纳米到3纳米带来的PPA益处其实不如之前那么显著。处理器需要满足两方面的需求:为要求严苛的任务实现峰值性能,以及通过高效低功耗操作充分延长使用天数,加之每平方毫米封装更多晶体管加剧了散热问题,因此管理功率密度是芯片设计过程中的重要任务。“他说。
为了应对这些挑战,Arm全面审视RTL和物理实现的共同开发,确保了其计算IP能够满足性能预期,同时克服先进工艺技术的挑战,包括:单元库和快速缓存实例针对特定处理器和工艺节点进行了优化;处理器优化包(POP)可增强Arm CPU和GPU PPA,等等。
合作伙伴则可以充分利用这些生产就绪的核心物理IP,将其作为构建模块,专注于 CPU 和GPU集群级别的差异化。从而大幅缩短他们在3纳米工艺上优化PPA的时间,确保芯片一次流片的成功率。
除了性能和效率的提升,这一新的计算平台还带来了增强的安全性和AI功能。Armv9.2架构的内存标记扩展(MTE)、指针验证(PAC)、分支目标识别(BTI)和机密计算架构(CCA)可针对各种安全威胁提供强大的保护,确保数据和应用程序的安全。
新CPU集群加速AI在移动设备领域的发展
随着AI工作负载的计算强度及复杂度持续增长,Arm最新的Armv9.2 CPU集群带来更强性能、更高效率,以及更多功能,为新一代AI奠定扎实基础。这些优势可扩展到包括旗舰智能手机、AI PC,以及主流移动设备、XR和可穿戴设备等在内的各类消费电子设备。
- Arm Cortex-X925:有史以来最大幅度的IPC同比提升
新的Arm Cortex-X925实现了Cortex-X系列推出以来最高的每时钟周期指令数(IPC)同比提升。Arm终端事业部高级产品经理Manish Pandey称,自2020年推出Cortex-X系列以来,提高单线程性能就是其核心目标。今年,Arm采取了更大胆的方式,通过综合考虑IPC、频率、编译器、操作系统(OS)、封装等多个要素,对Cortex-X CPU的设计进行了根本性的改变。

Arm终端事业部高级产品经理Manish Pandey
该CPU利用了领先的3纳米工艺节点,在3.8GHz的时钟速率和最大缓存大小的条件下,与2023年旗舰智能手机的4纳米SoC相比,其单线程性能大幅提高36%。而在AI性能方面,Cortex-X925取得了46%的性能提升,可显著提高如大语言模型(LLM)等设备端生成式AI的响应能力。

为了确保内核可以快速获取和解码指令,从而最大限度地减少延迟并最大限度地提高性能,Cortex-X925在微架构方面也做出了较大改变,例如10宽度的解码和调度宽度、L1指令缓存带宽增加了2倍、以及高度先进的分支预测单元等,都大大增加了每个周期处理的指令数量,使内核能够同时执行更多指令,从而提高执行单元的利用率和整体吞吐量。
Cortex-X925还具有高度先进的分支预测单元,可减少错误预测的分支数量。通过采用折叠式无条件直接分支等技术,Arm消除了多个架构障碍,从而实现了更精简、更高效的执行路径。这可以减少管道刷新次数并提高持续IPC水平。
“我们构建Cortex-X核心的目的不仅是为了取得卓越的基准测试结果,更是为了满足AI 等实际用例的需求,包括AI和应用的响应速度、网页浏览、图像和视频,以及更出色的高帧率游戏体验。”Manish举例说,在Geekbench 6、应用启动速度及 Speedometer 2浏览器基准测试中,Cortex-X925提升了约15%;在热门的大语言模型上词元首次响应时间缩短了约 40%;在热门的AI网络中,推理速度提升高达35%。
尽管性能出色,Cortex-X925 的设计也注重节能。3 nm工艺技术至关重要,可实现比前几代产品更好的节能效果。内核的设计包括动态电压和频率调节(DVFS)等功能,可根据工作负载调整功率和性能水平,这可确保高效利用能源,延长电池寿命并减少热量输出。
Cortex-X925 还集成了先进的电源管理功能,例如每核 DVFS 和改进的电压调节。这些功能有助于更有效地管理功耗,确保内核在不影响能效的情况下提供高性能。这种平衡对于需要持续性能和长电池寿命的移动设备尤其有益。
- Arm Cortex-A725:持续提升大核效率
Arm Cortex-A725旨在平衡性能和能效,定位为大核,特别针对需要稳定性能但又不需要顶级内核高功耗的设备,例如智能手机、平板电脑和笔记本电脑。
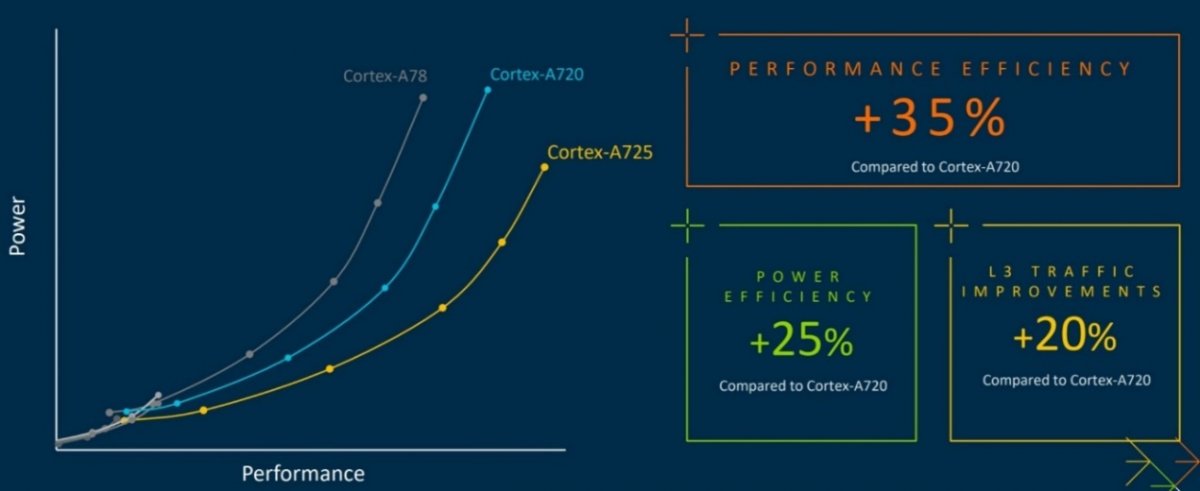
与Cortex-A720相比,新的Arm Cortex-A725 CPU将针对AI和手游用例的性能效率提高了35%,能效提升了25%。这一改进也得益于更新后的Arm Cortex-A520 CPU和更新后的DSU-120,使得采用最新Armv9.2 CPU集群的消费电子设备可提升能效和可扩展性。
增加指令发布队列和扩展了重新排序缓冲区,使得内核能够同时处理更多指令并乱序执行这些指令以提高效率,是Cortex-A725的一项重大改进——乱序执行窗口大小的增加使Cortex-A725能够更好地利用其执行单元,从而更顺畅、更快地处理复杂的工作负载。
新的1MB L2 缓存配置也让该内核受益良多。这种更大的缓存可以更快地访问常用数据和指令,减少延迟并提高性能,这对于需要快速数据检索的应用程序来说十分重要。此外,Cortex-A725的寄存器文件结构也得到了增强,进一步简化了数据处理并减少了瓶颈。
能效方面,得益于3nm工艺和动态电压、频率调节(DVFS)功能,与Cortex-A720相比,Cortex-A725的能效提高了25%(L3流量减少了20%),使其成为需要长电池寿命的移动设备的理想选择。
- Arm Cortex-A520:针对3nm工艺优化
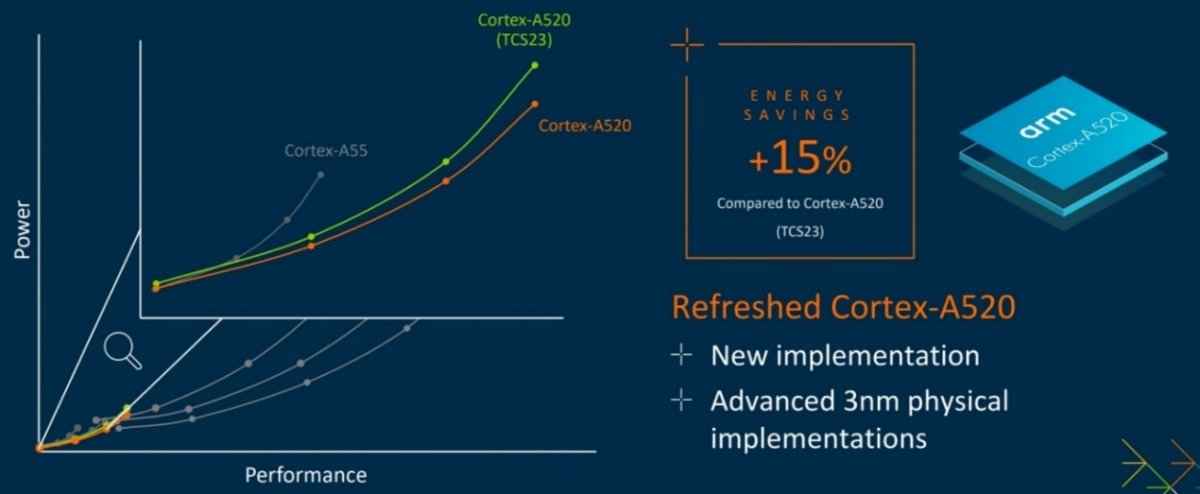
Arm Cortex-A520在架构上与去年推出的TCS23相比没有变化,主要是针对最新的3nm工艺技术进行了优化,提高了效率和性能,可为移动和嵌入式设备中的日常任务提供一些额外的计算能力,同时保持峰值能效并降低Arm最小内核的预期功耗。数据显示,与TCS23中的Cortex-A520相比,Cortex-A520的节能效果提升了15%。
作为新的Arm终端CSS的一部分,DSU-120已针对新一代用例和消费电子设备体验进行了强化。其中包括新的性能和效率功能、新的低功耗模式和面向主流消费电子设备的强化,并保留了为高性能用例扩展到14个核心的选项。
得益于此,典型工作负载的功耗显著降低50%,并且整个CPU集群的缓存未命中功耗降低60%,从而减少漏电并延长设备的电池寿命。新的低功耗模式,例如半切片断电模式 (half slice power down) 和Quick Nap,以及增强功能支持大量低强度和高强度的AI工作负载,包括生物特征识别、语音转文本、AI智能摄像头、内容创建和基于机器学习的AAA游戏。
总而言之,Arm将其所有最新CPU设计都转向3nm工艺技术,并推出全新的Cortex-X925和 Cortex-A725内核,同时对既有的Cortex-A520进行改进,包括增加每个内核的缓存大小、转向更宽的管道,以及为2024年增强 DSU-120内核集群,这无疑带来了显著的性能和能效提升。
GPU,为新一代AI和游戏体验而打造
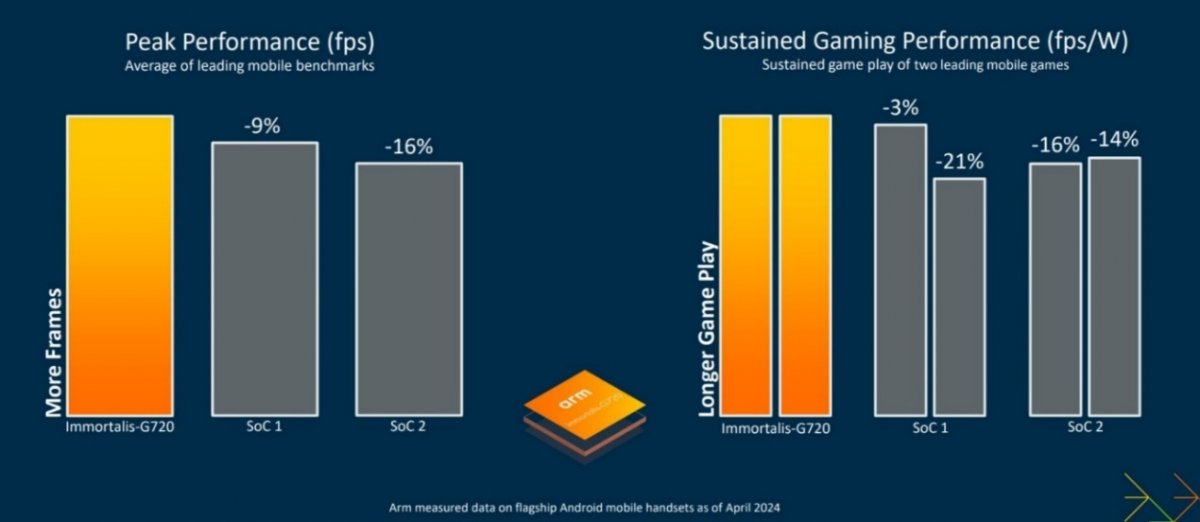
新的Arm Immortalis-G925 GPU是Arm性能最强、效率最高的GPU,在各款领先的手游应用中实现了37%的性能提升,并在多个AI和ML网络上提升了34%的性能,其光线追踪技术在面对复杂物体时的性能表现提升高达52%。
同时,Immortalis-G925所支持的着色器核心数量增加了50%,达到24个核心的最大配置,而上一代最多只有16个。为了实现这一性能目标,并确保能够支持所有着色器核心,Tiler和命令流前端(Command Stream Front-end, CSF)等顶级单元都经过了调整和优化,以充分发挥GPU的性能。
目标市场方面,Immortalis-G925面向旗舰智能手机市场,而包括 Arm Mali-G725和Mali-G625 GPU在内的全新高可扩展性GPU系列,则面向从高端手机到智能手表和XR可穿戴设备等广泛的消费电子设备市场。
安谋科技市场总监王刚在讨论技术升级重要性这个话题时,援引data.ai 预测称,2024 年,移动应用商店中至少10%的应用将由AI以某种形式驱动,手游营收将增长4%,金额超过1110亿美元。为此,持续投入创新以确保为用户带来崭新体验,成为了必选项。

安谋科技市场总监王刚
场景几何、顶点数量的增长,片段着色技术日趋复杂,是手游领域呈现出来的共同趋势。以《原神》和《堡垒之夜》这两款热门游戏为例,2021-2023年间,其所处理的顶点数量同比增长了9%至11%,GPU在片段着色上投入的处理时间同比增长高达27%至 43%,而这一切都是为了创造出更加逼真的物体和角色纹理效果,提高游戏对象的清晰度,实现诸如光晕、模糊和高质量的基于物理着色等效果,为游戏角色增添真实感。
在游戏性能方面,与TCS23相比,主流手游运行在采用Immortalis-G925的 Arm终端CSS参考平台时,性能平均提升了46%。以米哈游的《原神》为例,Arm终端CSS使其性能提高了 49%;由腾讯光子工作室群和KRAFTON公司联合开发的《绝地求生手游》运行速度提升了36%;《Roblox》更是大幅提升了 46%。这种代际的性能飞跃令人惊叹,对开发者和玩家来说都意义重大。

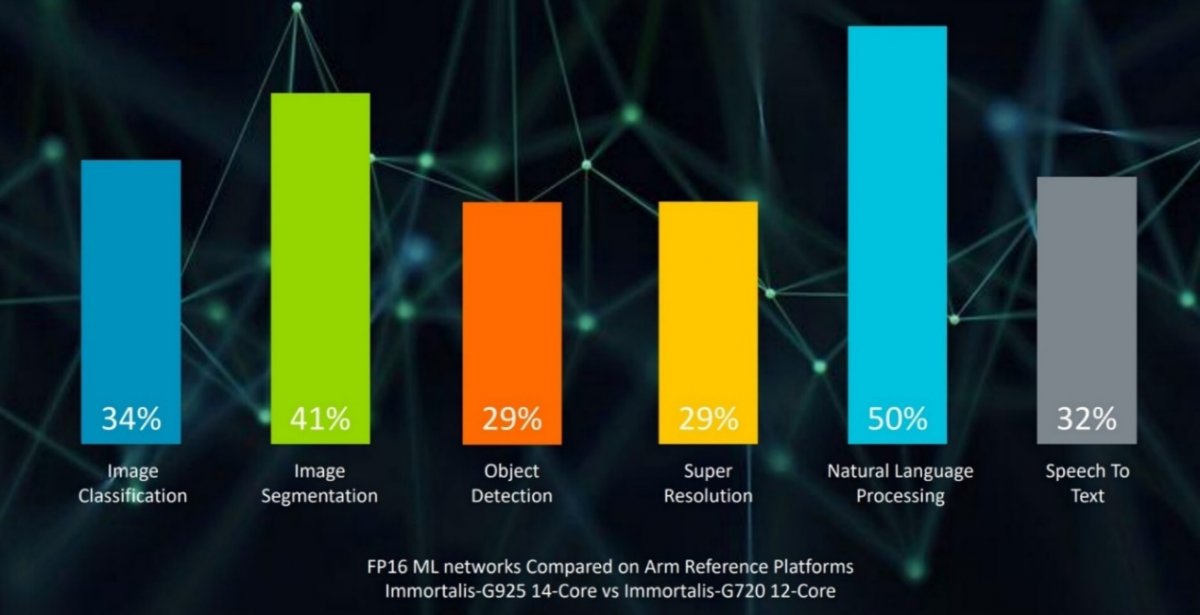
AI方面,尽管由于CPU的可编程性和灵活性非常高,许多的AI运行于CPU之上。但对于图像分割或物体检测这样的工作负载来说,更适合在GPU上运行。对比数据显示,在图像处理(如分割或分类)方面,与TCS23相比,Immortalis-G925将性能显著提升了41%;在超级采样任务中使用神经网络放大图像时,性能提升了将近30%;在自然语言处理和语音转文本方面,更是取得了50%的性能提升。
在 Immortatis-G925 中,Arm还改进了光线追踪技术。王刚介绍称,使用传统透明度处理技术进行渲染时,树叶和草地等复杂物体会给光线追踪带来挑战。如果光线无法透过此类物体,而继续寻找可穿过的透明对象,会导致成本高昂并影响性能。通过改进,在保持视觉准确性的同时Immortatis-G925将性能提高了27%,开发者也可选择稍微降低场景处理中的透明度准确性,并由此带来52%的性能提升和57%的内存访问降低。
其他性能改进则包括:
- 除了支持4KB内存页外,GPU还支持2MB内存页,减少了内存管理单元的操作次数,从而提高了性能。
- 优化了着色器核心的执行单元。执行单元数据路径由三种类型功能单元组成,即融合乘加运算、移位转换或CVT单元和特殊功能单元。通过将CVT单元的吞吐量提高一倍,显著改进了复杂着色器性能并优化了INT8 ML工作负载。
- 为了改进前几代产品中均支持的可变速率着色(Variable Rate Shading, VRS)技术,Immortalis-G925还改善了着色器核心深度模板单元,使其能够追踪更大补丁,有助于减少片段的工作负载。
如何支持数百万开发者创新?
为了使开发者能够以最高性能快速实现这些创新,尤其是确保高效的AI处理,Arm还推出了Arm Kleidi,其中包括面向AI工作负载的KleidiAI和面向计算机视觉应用的KleidiCV。Kleidi一词来源于希腊语,意为“钥匙”,意为开发者释放更多性能的钥匙。

安谋科技开发者生态高级经理李陈鲁
根据安谋科技开发者生态高级经理李陈鲁的介绍,KleidiAI是一套面向AI框架开发者的计算内核,使他们能够在各种设备上轻松获得 Arm CPU上的最佳性能,并支持Neon、SVE2和SME2等关键Arm架构功能。KleidiAI与PyTorch、Tensorflow、MediaPipe等热门AI框架集成,旨在加速Meta Llama 3、Phi-3等关键模型的性能,并且还可前后兼容,以确保Arm在引入更多技术时依然能适用未来市场的需求。
数据显示,当把KleidiAI整合进MediaPipe CPU执行路径所依赖的XNNPACK库以后,20亿参数的Gemma模型运行速度提升了25%;而Unity中基于量化网络的内核运行速度达到了原先FP32实现的近5倍。
在与生态系统合作伙伴Unity展开的合作中,Unity推出了原生支持FP32的ML框架Sentis,这是一个端侧AI推理引擎,可让游戏开发者在所有支持Unity游戏引擎的设备上打造创新的AI游戏体验。在集成KleidAI后,Unity Sentis成功启用了int4量化功能,将模型内存占用率降低了72.5%,同时在运行Phi-2 LLM时性能提升了660%。
KleidiCV 则针对计算机视觉工作负载,该库为图像处理、对象检测和场景识别等任务提供了优化的功能。将KleidiCV与Arm架构集成可确保应用程序能够快速高效地处理视觉数据,使其成为增强现实、自动驾驶汽车和智能监控系统的理想选择。通过利用这些优化的软件库,开发人员可以构建在基于Arm架构的硬件上流畅运行的复杂应用程序,充分利用3nm工艺技术带来的性能和能效改进。
除了Kleidi 库之外,Arm还提供了一套强大的开发工具和平台。终端CSS平台包括参考软件堆栈和性能优化工具,如Arm Performance Studio,以及新增的两个新工具(RenderDoc for Arm GPUs/Arm Frame Advisor),它提供有关应用程序性能的详细见解,并帮助开发人员微调其软件以实现最高效率。这个全面的支持系统确保开发人员能够快速有效地将创新应用程序推向市场,充分利用Arm最新的架构进步。
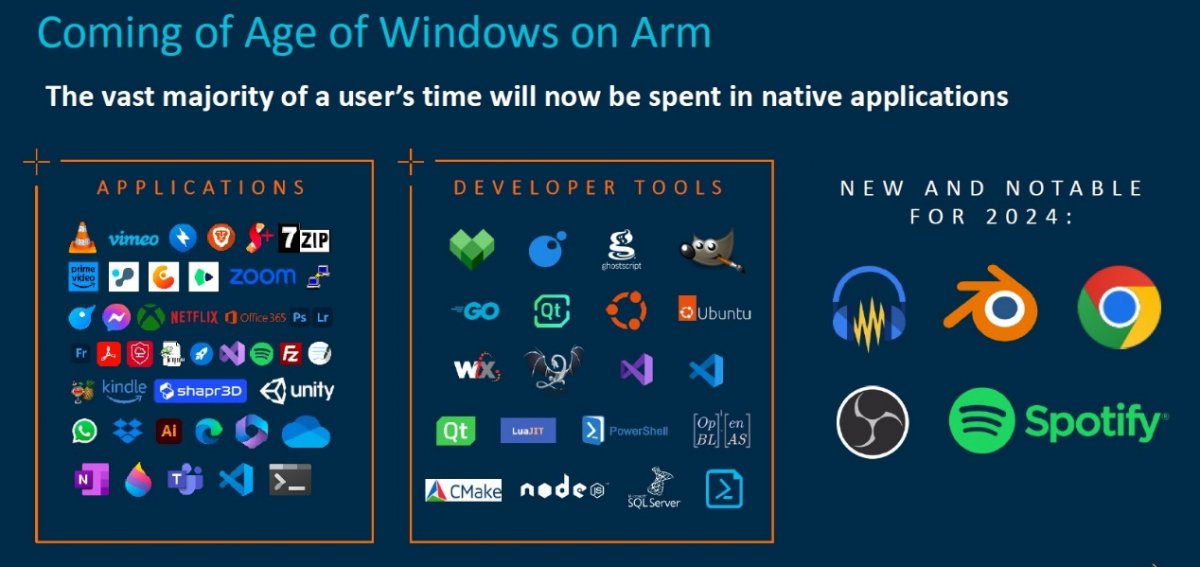
李陈鲁特别强调了Windows on Arm(WoA)生态系统近期取得的一系列进展。首先是通过与微软合作,使得Arm面向Windows的Performance Libraries(Arm性能库)得以发布,它们面向Windows系统优化运算例程,进而使开发者能提升WoA应用的性能
其次,除了我们日常熟知的Microsoft Office、Dropbox、Zoom、Adobe套件外,百度、哔哩哔哩、Chrome浏览器、爱奇艺、搜狗、腾讯QQ音乐等都已成为Arm原生应用。尤其是许多针对创作者的开源工具,例如最近新增的Audacity、Blender和OBS Studio(用于流媒体),都整合了大量的开源库和开发者工具,让应用更易于落地为Arm原生应用。
结语
随着Arm不断突破半导体技术的界限,专注于增强Armv9.2架构、推出终端CSS平台以及过渡到3nm工艺技术,新一代移动设备的性能、能效和安全性都得到了大幅提升,能够更加轻松处理最苛刻的应用程序。同时,该解决方案还可以扩展到不同的设备外形和用例,无论是智能手机、平板电脑,还是笔记本电脑和二合一设备,都将能够受益于此。

