
“超线程(hyper-threading)”实际上是Intel的专有技术,这一类通用技术名称叫SMT(同时多线程)——顾名思义,就是在一个CPU核心上可以同时并行多个线程,就操作系统看来,1个物理核心等同于多个逻辑核心。相对的,传统非SMT(或者叫Temporal/Interleaved Multi-threading)在同一时间内1个核心就只能跑1个线程。
在这个时间点谈SMT或超线程技术,主要是因为年底即将到来的,Intel面向PC的下一代酷睿Ultra处理器Lunar Lake,不再支持超线程/SMT技术。要知道,Intel的超线程技术是从2002年的奔腾4时代就开始的,那这会儿怎么又不再支持超线程了呢?


4核心8线程
当然,我们很难断言未来Intel是否还会重返超线程设计,而且至少到目前为止采用P-core的至强6处理器仍然是支持超线程的;我们也无力简单判断SMT在现代CPU设计中是好或不好。借着这个机会,本文尝试掰扯掰扯SMT的历史,并揣测一下Intel在Lunar Lake处理器上弃用超线程的原因。
超线程的历史,和技术实现
多线程CPU的提出最早可以追溯到上世纪50年代,而SMT同时多线程的设计,最初是IBM在1968年一个名为ACS-360的项目上提到的。所以这又是个很早就已经被拿来讨论的技术。
原本最早要商用的SMT处理器是当年DEC开发的Alpha 21464,但这颗处理器因为各种商业收购相关的因素并为真正问世。所以Intel的至强和奔腾4的确就是商用产品中,最早支持SMT/超线程的CPU芯片了。
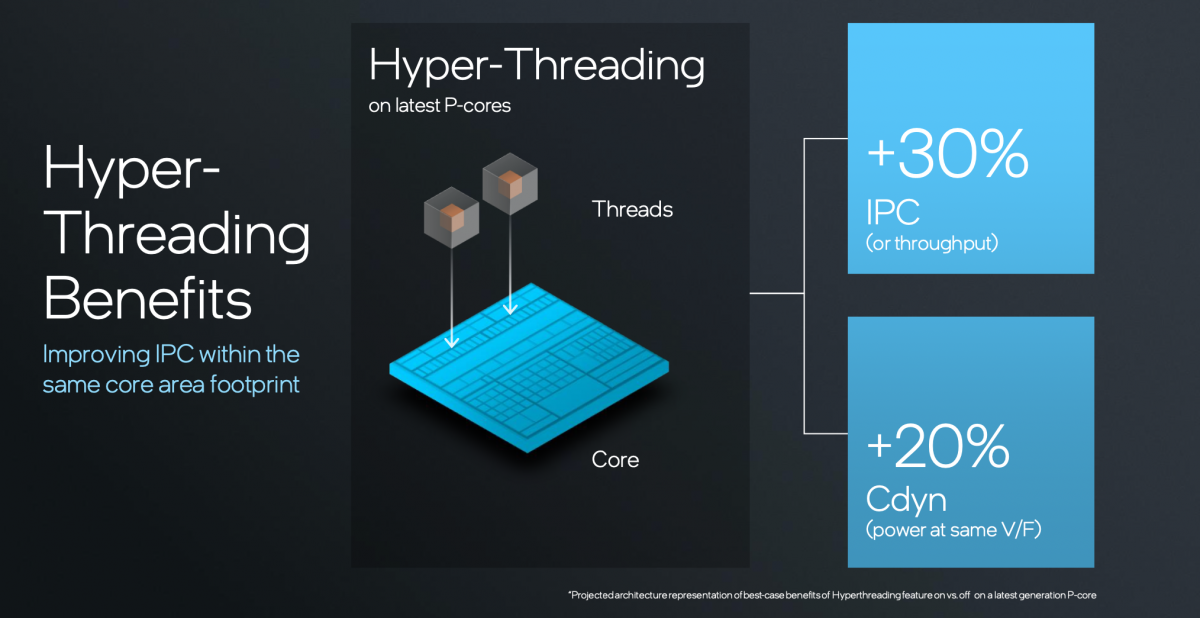
Intel的超线程技术具体支持到1个核心同时跑2条线程。大部分对Intel熟悉的读者应该知道,Intel一直在说超线程设计实现了30%的性能提升,且晶体管或面积代价远低于30%的投入。尔后就沿用至今了。

不过SMT技术并非只能做到1个核心同时跑2个线程。比如IBM当年挺多处理器设计都能做到1个核心同时跑4个线程的;Intel的Xeon Phi也是所谓的4-way SMT;IBM POWER8甚至做到了每个核心同时跑8个线程。Oracle当年的SPARC T系列也可以做到1个核心跑8个线程——不过似乎一部分是通过时域交错所谓的fine-grained threads实现的。
此前我们也关注到国内的合芯科技在做“SMT8”,12个物理核做到96个逻辑核的效果。
这里略微提两个在单核多线程技术领域相对特殊的方案。其一是早年AMD的Bulldozer推土机微架构,算是一种“部分SMT”设计。因为推土机架构的1个“核心”内(或2个核心),有2个整数模块和1个FPU模块,并共享L2 cache。
这样一个非常规的“核心”采用一种叫“Clustered Multi-threading”(CMT)多线程技术,即对FPU和L2 cache而言是SMT,但是对整数模块而言就属于非SMT设计了。当然当代的AMD Zen在SMT思路上就和Intel的超线程一样了。
 另外值得一提的是,IBM的某些SMT设计更为复杂,“SMT引擎”可以动态开启或关闭。因为对于某些类型的应用负载而言,SMT反而会导致性能下降,则此时可以自动关闭SMT。2010年IBM基于POWER7发布的系统,每个核心可以同时跑4个“同时智能线程”,还可以在1线程、双线程、4线程间切换。
另外值得一提的是,IBM的某些SMT设计更为复杂,“SMT引擎”可以动态开启或关闭。因为对于某些类型的应用负载而言,SMT反而会导致性能下降,则此时可以自动关闭SMT。2010年IBM基于POWER7发布的系统,每个核心可以同时跑4个“同时智能线程”,还可以在1线程、双线程、4线程间切换。
这里简单聊聊SMT的实现。很多文献资料都提到,SMT的实现并不需要过多更动基础的微架构设计——不知道当代核心的微架构实现是否还如此,起码Arm认为SMT在大核心上的实现逻辑不划算。SMT在核心微架构层面,具备单周期内从多个线程获取指令的能力,当然还要有配套更大的寄存器堆来保存多线程的数据。
对SMT在核心微架构层面的具体实现感兴趣的读者,推荐去看一些SMT的核心公开设计。比如1997年一些研究人员基于MIPS R10000做了SMT的模拟设计;近代的也可以去看一看Arm Neoverse E1处理器,这款处理器所用的Helios核心就支持SMT——对于通用、矢量和系统寄存器及其对应架构做了资源扩展。

Arm Neoverse E1的多线程方案
总之SMT结合了宽发射超标量和多线程处理器特性。沿袭自超标量的,是每周期要发射多个指令;来自多线程设计的,则是需要包含针对多个线程的硬件状态。最终,处理器能够在每个周期,都从多个线程发射多条指令,实现针对某些负载更好的性能:对于相互独立的程序而言,实现了整体吞吐的提升。
另外,这种设计对于1个线程独占1个核心,也能实现所有资源的利用,相比非SMT的设计基本保持了相同的单线程性能。SMT的整体思路,是在确保单线程性能的基础上,结合指令级并行+线程级并行。来自不同线程的指令,也可以在相同的pipeline管线阶段同时执行。
于是SMT实现了处理器闲置计算资源的更充分利用,提升了吞吐;从更系统的层面来看,SMT也就是同时跑多任务或者某些复杂任务,也就提升了整体的性能。
Arm与超线程的那点渊源
没错!Arm其实也有SMT设计的IP,虽然当代基于Arm CPU IP的芯片的确罕有SMT设计的。苹果、高通、联发科的处理器基本上都是一个核心同一时间只能执行一个线程,一个萝卜一个坑。就连英伟达面向AI HPC的Grace CPU也是如此。基于Arm的例子,SMT提高吞吐应当也更容易理解。
Arm至少有两个处理器IP是支持SMT的:Cortex-A65和Neoverse E1。比较反直觉的是,这俩IP的定位都不是高性能、宽架构设计。从基础设施部署的负载类型角度来看,Arm似乎是有意要切分“compute”计算用例,和“throughput”吞吐负载的。后者主要是指大量数据的处理工作——也是Neoverse E1的目标应用场景。
Arm对此的解释是,在大量数据处理负载中,cache miss(缓存未命中)很常见,无论是车载Cortex-A65AE处理来自大量传感器的数据,还是Neoverse E1使用过程中来自网络基础设施的数据。CPU也就需要处理内存访问延迟比较久的情况,在CPU管线中带来stall。那么能够处理第2条线程,也就在带来了很好的吞吐收益,减少执行资源的闲置和浪费。

但其实Arm没少吐槽过SMT/超线程技术在某些场景内的应用。比如发布Neoverse N2/V1的时候,Arm就在发布会上提过,不用单核心的SMT而更多基于多核来提升吞吐,能够提高可预测性(predictability)。
前不久的至强6(E-core版)发布会上,联想作为OEM厂商代表也提到,1个核心1个线程有“确定性”,“因为每个线程就在独立的核上跑”,“确保业务负载有确定性的线性预期。”
说大白话就是,SMT有时面临线程间的资源争抢。对于操作系统而言,逻辑核心负载过半,它会认为仍有充足的核心资源可供利用,但此时物理核已经被占满。当负载持续提升,则性能表现就不再呈线性——因为后续是以SMT的方式跑更多线程。甚至在负载70%以后,系统就面临崩溃或出现性能颠簸。
当然了,这还是和具体跑什么样的负载类型有很大的关系。其实Arm早在2013年就发过一份技术文档,详述了对于追求能效、功耗敏感的移动应用而言,多线程技术是不适用的。当年Arm还没有像现在这样,把势力范围看向HPC领域。
或许在Arm于这个世代走向PC、数据中心等更高算力需求的新场景时,大部分情况下没有选择超线程, 与其发端自嵌入式和移动应用有关。当年Arm写的这份文档,即便是现在看来也还是颇有参考价值的。
这份文档当然首先还是明确了PC领域普及超线程技术的正确性的,“但是”——话锋一转,这份文档从第3页开始,后面就基本是在谈SMT技术于移动应用的不利之处了。其实以前大家对SMT的普遍看法也都是,该技术不适用于功耗敏感型应用。而现在或许有更进一步的商榷余地,毕竟某个不大能提、基于Arm的手机芯片SoC的CPU部分就已经开始用SMT了。

Intel与Arm的“英雄所见略同”
有关超线程的好处,20世纪末到21世纪初有太多的研究文章了,比如前文提到IEEE发表的Simutaneous MultiThreading: A Platform for Next-Generation Processors,详细将SMT与传统的超标量、时域多线程(非同时多线程)、多处理器方案做了比较,结论是SMT比后面几种方案明显更优。
以现在的眼光来看,这篇paper存在时代局限性。它发表于1997年,对比“多处理器方案”也给出SMT更优的结论,是基于当时的制造工艺和互联技术限制。多处理器方案既不能像现在这样堆料,也受制于处理器核心之间的互联一致性问题。而且这毕竟是个模拟测试,1997年连商用的SMT处理器都还没出现。
这篇paper只有两段话提到了SMT设计存在的问题。基于该研究的模拟结果,“SMT管线相比于单纯使用超标量设计的方案,多出2个周期。所以当仅1条线程在SMT处理器上执行时会引入额外的延迟。”“但是SMT的单线程性能也仅比普通超标量设计弱1%(并行负载)和1.5%(多程序设计负载)。精准的分支预测硬件,和重命名寄存器共享池,让额外的周期惩罚不会频繁发生。”
另一个关键问题是,“SMT的资源争用”。许多SMT的硬件结构,比如cache, TLB和分支预测表都在多个线程间共享。这种统一的组织结构,具弹性和更高利用率,因为执行中的线程可以按照需求去使用。”...但是,“线程间(interthread)使用,导致共享资源竞争,可能更多发生cache miss、TLB miss和分支的错误预测。”
不过这篇文章总体上还是认为,SMT设计是可以有效消除或隐藏大部分冲突的,额外的代价在SMT带来的吞吐价值面前不值一提。

Arm的文档也提到了SMT资源争抢的问题,认为SMT设计中每条线程的吞吐因此低于1条线程独占1个核心的设计;而且SMT核心还需要加入更复杂的调度和管理结构,整体上带来处理器效率的降低。“...处理器的管理和调度结构,对于复杂乱序处理器的能耗而言也是相当大的组成部分”。
所以Arm认为,如果只考虑吞吐问题,那么与其在大核心的这部分逻辑上下功夫,还不如用多个更小、更简单、更高效的处理器核心来解决问题。所以更为有效的替代方案应该是“使用两颗具备较低单线程性能的处理器或核心”。显然2013年的这份技术探讨文档,和1997年所处的半导体技术时代背景又极为不同了,即便这份文档的探讨场景是局限在移动应用的。
对于需要“大核心”性能的应用场景,Arm还做了个对比。比较其顺序核Cortex-A7和乱序核Cortex-A12:对Arm的处理器IP熟悉的读者应该知道这分别是Arm的小核和大核设计。
Cortex-A12作为大核,有更多的硬件资源,包括寄存器重命名、执行依赖追踪等逻辑,实现了远高于Cortex-A7的单线程性能。当然从单条指令执行的能耗水平来看,Cortex-A12也因此更高。结合功耗和性能,Arm给出了两种核心的相对功耗与性能柱状图:

一般我们说核心性能高50%(DMIPS,基于Dhrystone执行的Million Instructions Per Second),功耗提升必然超过50%。另外更重要的是,这张图中出现了2个Cortex-A7核心,以及Arm预计给Cortex-A12加上SMT设计以后,其功耗与性能变化。
“看一看给一个典型的乱序处理器核心增加多线程能力,在芯片面积、功耗方面的成本上,相对于性能吞吐红利的情况。”Arm预计给高性能核心增加多线程能力,比如此例中的Cortex-A12,的确能够带来两颗Cortex-A7核心相似的吞吐能力,但前者的功耗是后者的2倍,die面积则大10%。
我们认为,这可能还是和当年的核心微架构设计思路有关,另外也有Arm当年宣传big.LITTLE异构核心设计的因素在。但这番说辞,其实在前不久Intel Lunar Lake技术解析会上,我们也听到了。
Intel从酷睿12代(Alder Lake)也开始采用异构核心设计,E-core负责高能效,P-core复杂高性能。至少在后续2-3代产品上,其中的P-core都仍然是支持超线程的。但在接下来要推的Lunar Lake处理器上,P-core却不再支持超线程。
Intel的说法是,“E-core已经证明了它是比超线程更有效的一种多线程加速手段。”“如果追求多线程性能,与其赋能超线程,还不如去做E-core。”这个说法几乎与Arm当年的说法如出一辙,即便2024年这个时点和当年探讨移动处理器时期的时代背景又大不相同了。而且一个是说PC处理器,一个是说手机处理器;一个的能效核规模比另一个大得多...
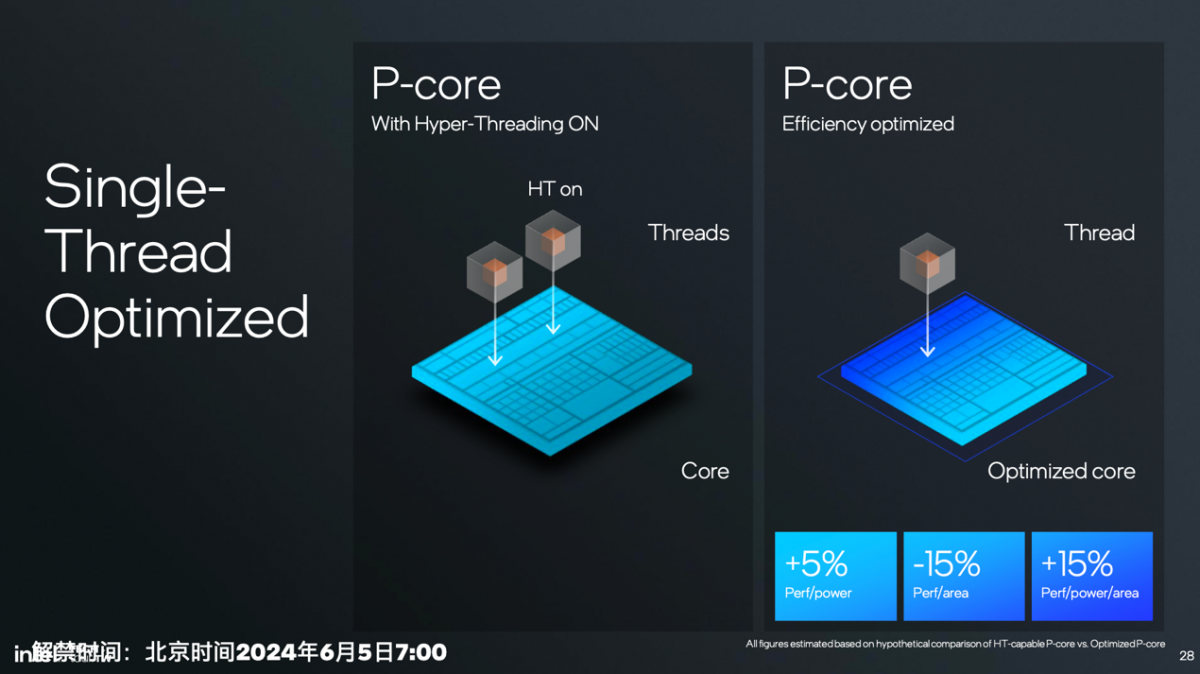
Intel说在这一代P-core去掉超线程以后,虽然每瓦性能只提了5%,还带来单位面积的性能降低15%,但综合考量单位面积单位功耗的性能(perf/power/area)则提升了15%。所以这是个挺划得来的生意。而且Intel没说的是,去掉超线程也简化了操作系统的线程调度,以及在不同核心之间迁移的难度和复杂性。
SMT还会继续走下去吗?
Arm还在文档中谈到了更多SMT技术所需付出的代价。比如说前文提到的性能的“不可预测性”,或者要么增加硬件资源、芯片面积为代价;带来节电设计的复杂化——这可能也是当年Arm在功耗敏感型应用上考察的重点;安全方面的风险、边际递减效应等…
比较有趣的是,其实在当年的这份文档里,Arm就提到了小核心反倒适合做多线程技术。原因是,对于很多存储敏感(memory-bound)型负载而言,核心经常要等待内存中的数据,诸如networking之类的负载明显更适合小核心来跑。
“这样的负载”…“能够受惠于可以跑第二条线程,尤其是在其他线程处于stall状态时。Stall是一种能耗浪费”…“这样的系统不同于大核心的多线程”…“处理器核心中的大部分能耗是用在了关键任务的计算上,而不是用于管理开销”。“相应的,在第一条线程stall时,让第二条线程跑起来就提高了效率”…
这不就是Neoverse E1的思路吗?只不过是在10年以后才实践了这一思路的。
有关SMT/超线程未来是否还会持续在PC、数据中心及网络基础设施中发挥作用,技术层面大概还有争论的余地。也不能因为Lunar Lake不再支持超线程就说超线程没有了未来。况且现在市面上采用SMT设计的处理器也还有不少,即便是非x86或Arm的。
不过我们认为,一方面是以应用为导向的芯片设计思路越来越明确:比如Intel这边根据应用场景差异,将至强6切分成不同核心版本,就是这种思路的体现。则SMT的未来在于更有针对性的应用场景。
就芯片企业的动作可以再做更进一步的观察。比如说可以看一看Intel下一代至强处理器是否还会沿用P-core超线程设计,以及下一代面向台式机的酷睿Ultra会不会重返超线程设计。
说到底,SMT的走向都在于它对芯片PPA权衡的价值;只不过这个命题的真伪在半导体技术的不同发展阶段可能也是不一样的。
- 写的太好了,非常感谢
