
今年华为开发者大会HDC的亮点,绝对不只是HarmonyOS Next操作系统。余承东(华为常务董事、终端BG董事长、智能汽车解决方案BU董事长)在主题演讲中给出了这样一张华为的能力栈框架图,这其中的每一个都可以说是亮点——这张图也有利于我们理解,华为不同能力所处的层级及个中关系。

这场发布会提及的不单是盘古大模型自身,也在于华为在AI HPC领域内的整体能力,包括昇腾服务器及华为云基础设施。虽然华为在发布会上没有提到英伟达,但很显然在我们看来,其AI HPC各方面能力看齐的都是英伟达。
比如说盘古大模型对于自动驾驶的助力,用于自动驾驶AI训练的合成数据(synthetic data)生成能力,这也是英伟达DRIVE Sim的能力;对于工业与建筑设计的辅助,甚至直接输出3D格式文件,略有点Omniverse用于设计的味道;用于机器人的具身智能大模型,英伟达Isaac;用于公里级别精度的气象预报,有点儿Earth-2的样子了;甚至药物发现、铁路检修等等...
所以我们说在AI这个方向上,华为大概的确是有成为英伟达替代方案的决心的;且相较于其他既有AI生态,华为也是国内走得最快的市场参与者之一。
盘古5.0概览:多模态强化是亮点
从盘古大模型的发展情况来看,这应该是个更偏重行业应用的基础大模型。华为云CEO张平安说,盘古大模型当前已经进入到中国30+行业,400+应用场景,包括后文会提到的汽车、医疗、交通、气候、重工业等。
这次新发布的盘古5.0主要强调3个方面的加强:全系列、多模态、“强思维”。

全系列指的是从大规模数据中心集群,到边缘的适配。所以盘古大模型5.0有E系列(Embedded)——面向手机、PC,参数量十亿级;P系列(Professional)——参数量百亿级别;U系列(Ultra)——千亿级参数量,是“企业大模型的通用底座,可以处理复杂任务”;S系列(Super)——万亿参数大模型,“处理跨领域的复杂任务”。
而多模态当然就是指,不同类型的数据理解能力,除了文本、图片和视频外,还包括了可见光、红外、雷达、点云等类型的传感数据。还有多模态生成能力,“盘古5.0能够生成符合物理规律的多模态内容”,例如后文将提到的自动驾驶合成数据生成。
第三,思维升级,也就是复杂推理能力。张平安说,“我们将思维链和策略搜索深度结合,极大提升了盘古的复杂任务规划能力”。

有关多模态数据的理解能力,让我们印象最深刻的例子,是将10k像素级分辨率的《清明上河图》输入盘古大模型,问“赵太丞家有多少人”。这里的赵太丞家,从图上看实际只占到清明上河图不到1/200的比例。盘古能够通过对于门匾的文字,及其中的人物数量,给出正确回答。
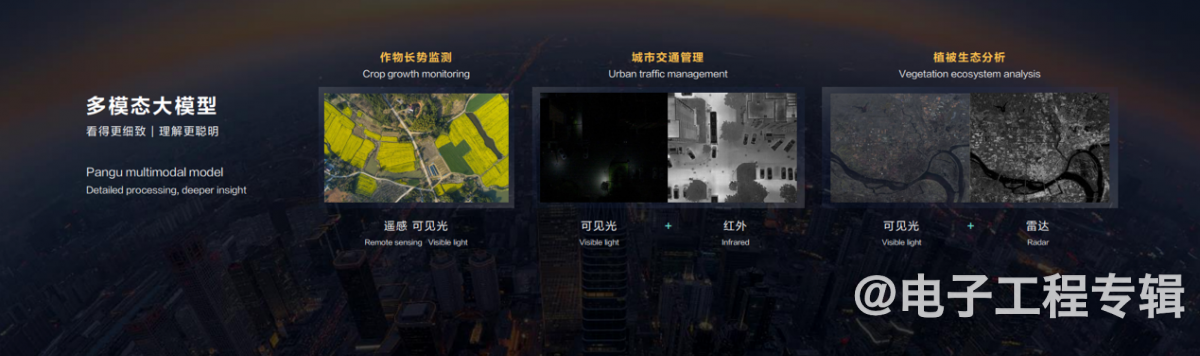
除了图像,如前所述盘古5.0支持可见光、红外、雷达、点云多模态输入。所以通过卫星遥感可见光拍摄的画面,可分析某个区域农作物的生长、收成情况。对红外影像的理解,用于城市交通管理,则可识别车辆和人行轨迹。理解雷达影像,搭配可见光,就能判断植被覆盖,利于生态监测。
具体到技术,诺亚方舟实验室主任姚骏提到,有关视觉的多模态,不同的视觉领域有各自独立的编码方案,“会有冗余、冲突”。“我们把这些编码器蒸馏到同一个视觉编码器中,提升模型表征能力和精度”;
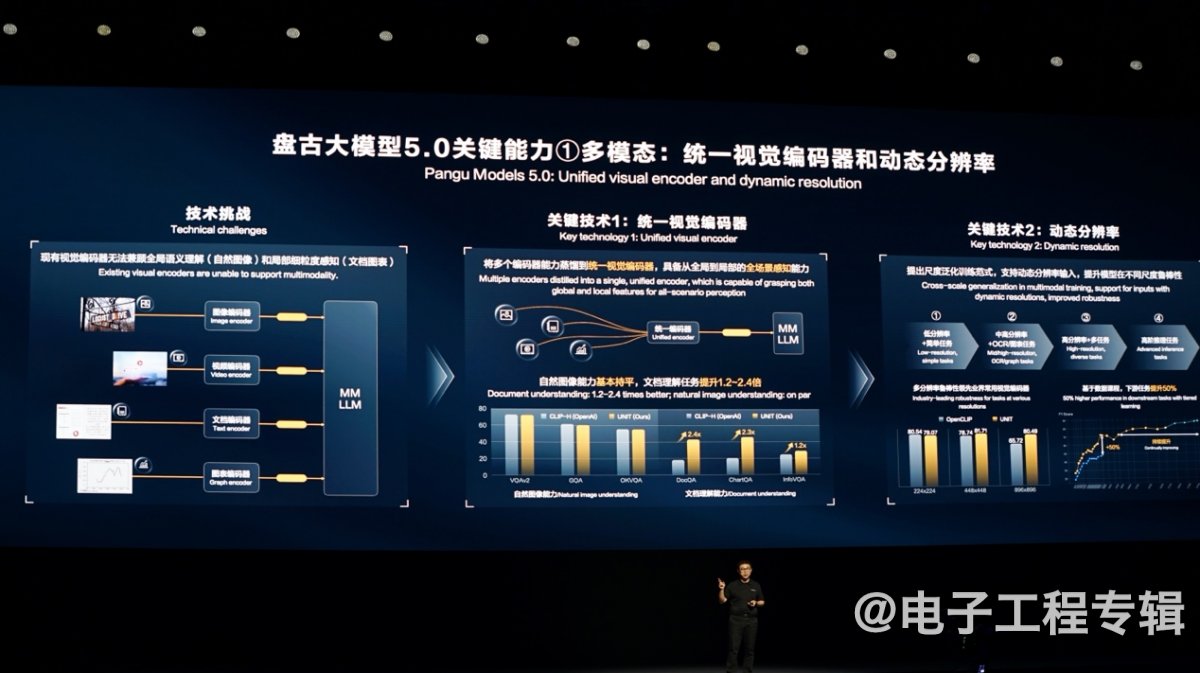
另外他还提到视觉输入的“动态分辨率”,“提出尺度泛化的训练范式”,用低分辨率图像及简单任务去训练基础感知能力;用中高分辨率图像与包括图像理解等在内的细粒度感知任务,得到细粒度的感知能力;
再扩展到更高分辨率和更多任务类型...最终“重点突破模型的高阶推理能力”,作为一种阶梯式数据课程学习方式,“由难到易学习多模态信息”。最终得到的结果是“超过业界同等模型的能力”,也就是更高的多模态数据处理能力。
而在“思维升级”方面,谈的主要是多步推理和复杂任务处理能力——尝试用大模型辅助写算法的开发者应该很清楚,大模型在复杂逻辑问题的处理能力上是比较差的。“模型也应该像人一样,把问题的快思考变成慢思考。”

也就是一步步分解、推导。“我们提出基于多步生成和策略搜索的MindStar方法”,“先把复杂推理任务分解成多个子问题,子问题会生成多个候选方案;通过搜索和过程反馈奖励模型,选择多步最优回答路径。”
姚骏说用MindStar技术的百亿模型,就能达到业界千亿模型的推理能力。“相当于使用慢思考带来10倍以上的参数量加成。”“将MindStar这一强思维方式应用到更大尺度的模型上,就能逐步在复杂推理上,更接近人、超越人。”
列举几个行业场景:高铁、汽车、机器人
如文首所述,这次华为列举盘古5.0的几个行业应用,主要是客运、汽车、工业与建筑设计、机器人、重工业等相关的。这里列举几个给我们留下了深刻印象的例子。
首先是和北京铁道所合作,“盘古眼”(包含大量传感器的机器人)配合盘古大模型用于高铁巡检。一辆动车有超过32000个故障检测点,需要数百个工作人员才能完成日常巡检工作。新版的盘古大模型新增了更多维度的数据理解能力,它能解决很多传统机器视觉解决不了的问题,如结合三维信息发现螺帽是否松动、借助光谱分析识别漏油还是漏水。
北铁所介绍说,盘古高铁大模型对海量的高铁行业数据进行训练和精调(fune-tune);结合二维图片+三维点云+激光光谱等多模态数据的融合诊断技术;以及对高铁场景罕见故障样本生成,通过数据反哺,“边用边学,故障识别准确率进一步达到99%+”。
据说将来这样的智能化技术,准备从火车、高铁,延伸到城铁、地铁等更多轨道交通业务场景。

还有个例子是自动驾驶相关的,体现的主要是盘古5.0的多模态生成能力。我们知道在AI应用于自动驾驶以后,汽车可以在虚拟数字世界中进行学习和测试——给汽车的自动驾驶系统看各种复杂场景,以便在实际操作中能够应对各种状况。通常自动驾驶要做好,需要数十万、百万公里的高质量视频驾驶数据。
但高质量自然数据往往不够,这就需要生成所谓的“合成数据”。张平安着重展示了盘古5.0这方面的能力,“通过可控时空生成技术,理解物理规律,大规模生成和实际场景一致的驾驶视频数据。”比如车身不同位置的6个摄像头,对应生成同一场景内不同视角、合乎空间和时间对应关系的合成数据。
生成过程可以改变各种控制条件,比如增加不同方向的来车;以及让模型生成不同天气与时间的行车视频。华为展示的雨天行车视频中,车尾行车灯也是开启的。“说明模型通过海量视频数据,学习到雨天开车是应该要开车灯的。”这些都是自动驾驶+AI技术的必备技能。

此外,将盘古大模型用于工业设计,不仅能够生成适配不同环境光影的3D汽车模型,还能输出3D文件;和华南理工大学合作用于建筑设计,基于设计草图就生成建筑环视视频等;
以及AI原生译制能力,可将电影原片译制为不同语言的版本——且语音保留原角色的音色、情感和语气;乃至在视频会议中,结合数字人与AI译制,直接让视频参与者的数字化身说不同的语言等等...
相信关注AI技术的读者,对于这些案例都不会陌生,此处不再一一例举。

最后再谈谈机器人应用,即“盘古具身智能大模型”。此前我们多次撰文提到过,机器人是AI走向高级阶段,从数字世界走向真实世界的关键。盘古具身智能大模型“能够让机器人完成10步以上的复杂任务规划,并在任务规划中实现多场景的泛化和多任务处理”;与此同时,和隔壁的Isaac Sim一样,让机器人在虚拟世界进行训练,“生成机器人所需的多模态数据,让机器人提前训练和学习各种复杂场景”。
发布会现场演示名为“夸父”的机器人,能够通过多模态的世界感知,进行逻辑推理和任务规划。比如说从桌上拿对应的东西、理解桌上的东西是什么、该怎么拿,与人进行语言和肢体交互等。“除了人形机器人,盘古具身智能大模型,还可赋能多形态的工业机器人和服务机器人。”
在AI走向物理真实世界以后,AI赋能包括零售、物流、医疗、家庭服务、工业与生产等在内的千行百业,也就成为驱动万亿市场价值的生意了。
光有模型还不行:算力基础设施配合强化
从华为的介绍来看,盘古大模型的行业应用进展很不错。除了前述诸如与北铁所的合作,还有像是已经在宝钢的一条热轧生产线上线——用于进行工程调优、增加年收益,目前还在探讨用于高炉场景的降本增效;
与深圳市气象局合作,打造基于盘古大模型的AI区域报模型“智霁1.0”,提供公里级的气象预报;以及与天士力合作,让盘古药物分子大模型学习350万天然产物分子,以期发现中药有效成分、优化方剂等等...
不过光做模型,要搞好生态还是远远不够的。在模型之下的基础设施部分,华为强调的是昇腾算力底座、昇腾AI云服务。这是“加速模型开发,使能千模百态”的基础。

当前华为在贵安、乌兰察布和芜湖构建了三个大型数据中心,“构建满足全国AI算力的云服务”。用户“可以获得百卡、千卡,甚至更多的AI资源”,“在训练大模型的长期稳定性和故障恢复方面有极大优势”。“当前适配了行业主流的100+大模型。”张平安说,合作企业已经有了600+。
此外华为云CTO张宇昕表示,华为云也在华北、华东、华南等热点区域部署了AI算力资源池;“还通过华为云CloudLake,和CloudPond边缘云平台,将AI算力推到客户身边。”“由此打造了云-网-边-端协同的AI native算力平台。”所谓的AI native,要求云的架构能够真正为AI服务,让AI更高效。

为了实现云的AI native,华为云打造了CloudMatrix:通过高速互联的网络协议,将CPU、NPU、内存等资源全部互联和池化,实现所谓的“矩阵算力”,是“分布式全对等架构”,而非传统的CPU为中心的主从架构。张宇昕强调说,华为云是目前唯一采用“对等架构超节点技术”的云厂商。
在解决方案上并没有说得很具体,不过张宇昕表示“华为云超节点相比业界单节点算力提升50倍;大模型的E2E恢复时长低于10分钟;万卡集群线性度>95%”;最终实现了相比传统集群架构,相同算力条件下“模型训练效率提升68%”。这些数据看起来都相当惊人。
达成这这些指标的其中一个关键技术,是EMS(Elastic Memory Service)弹性内存存储,用于缓解存储墙问题。

具体是在NPU显存(本文的“显存”均指AI加速卡的存储资源)和持久化内存之间,增加EMS弹性内存存储。“基于memory pooling(内存池化)专利技术,通过显存扩展、算力卸载、以存代算,来打破内存墙”。
有关“内存扩展”,是指将模型参数是分层存储在显存和EMS中,“使用不到一半的NPU卡,就存下万亿参数的大模型,算力节省超过50%”;
“算力卸载”,则是将KV计算(应该是指key-value数据结构计算与caching)offload到EMS和CPU上,模型计算仍然在显存与NPU上进行,提升单卡并发度,“AI推理性能提升100%”;“以存代算”是指将历史KV计算结果保存在EMS中,供后续推理直接调用—— “首token的时延降到0.2秒以内。
盘古5.0的3个技术点
盘古大模型5.0就是基于这样的华为云AI平台开发的,盘古5.0也因此具备了几个关键的“黑科技”。除了前文已经介绍的能力升级实现更多模态、更强思维以外,姚骏主要从数据、参数、算力方面,介绍了盘古5.0的3个技术点。
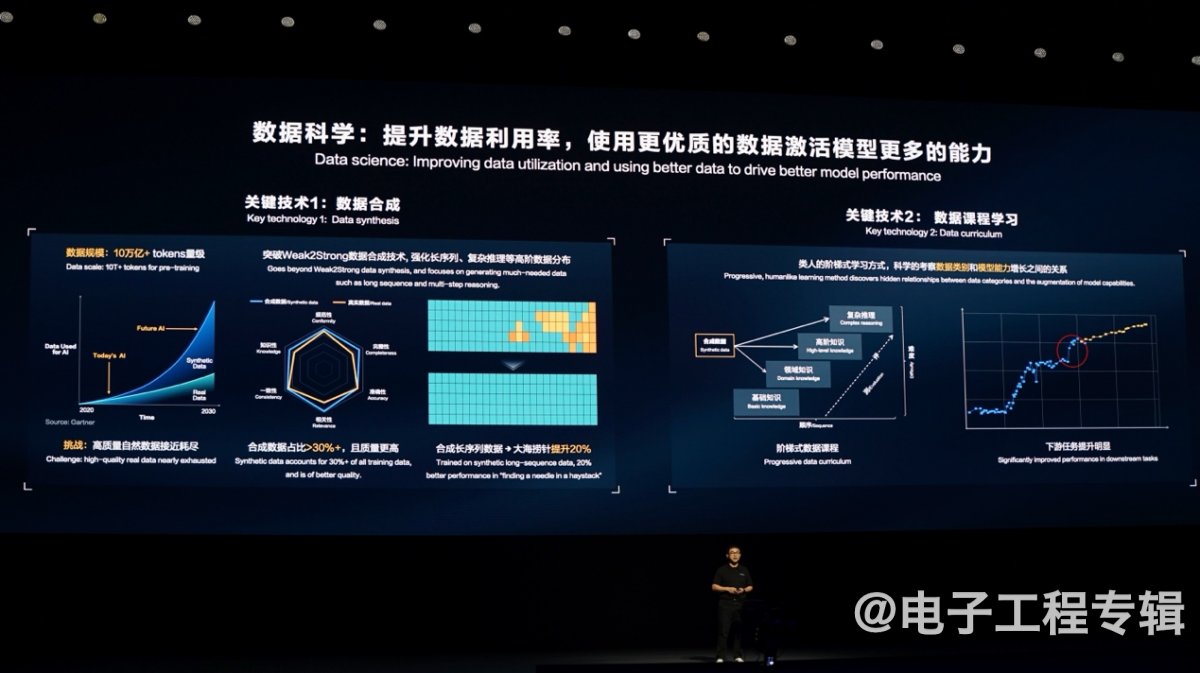
首先, “向科学使用数据的方向演进”。 “合成数据(synthetic data)会在更大规模的模型训练中占有一席之地,弥补高质量自然数据增长不足的空缺”,从盘古3.0的3T token数据量,到盘古5.0的10T token数据量,“其中合成数据占比超过30%”。
“我们探索面向高阶能力的数据合成方法。”具体是“以弱模型辅助强模型的weak2strong方法,迭代式地合成高质量数据。”结果合成数据质量“各个维度都略强于真实数据”。且weak2strong技术能够加强一些特定数据,“例如自然数据中偏少的长序列、复杂知识推理等数据”,以此加强模型特定的能力。
此外,在“数据课程学习”的过程中,采用“阶梯式数据课程”,先让大模型学习基础课程,再逐渐加大复杂数据配比,“从易到难学习知识”,“实现更可控、可预期的能力提升”。

其次在于“昇腾亲和”的Transformer:π架构。这部分优化应该是与昇腾芯片密切相关的。姚骏表示原始的Transformer模型存在“一定的特征坍塌问题”,“通过理论分析发现,Transformer中的自注意力模块会激化数据中的特征消失”,业界一般的方法是增加一条残差连接,以缓解特征坍塌问题。
π架构“引入了非线性增广残差连接”,“进一步加大不同token的特征,使数据特征的多样性在深度的Transformer中得以维持。”
与此同时,提高Transformer的FFN(Feedforward Network)模块处理效率。“在π架构中,我们改造了FFN中的激活函数,用一种级数激活函数的方式来代替,增加了模型的非线性度。虽然增加了FFN的计算量,但也在维持精度的前提下,减小了自注意力模块的大小,实现昇腾的亲和。在昇腾芯片上,推理速度因此提升20-25%”。
有关π架构的相关研究成果和内容,已经发表在了NeurIPS 2023顶会,有兴趣的读者可以去看一看。

第三点是在系统层面,针对超大规模集群训练的优化。姚骏谈到,千卡集群训练的bubble(等待时间)一般在10%左右,更大规模集群训练的bubble可能到30%。多卡通信过程还可能存在“大量路由冲突”,“导致集群整体线性利用率只有80%左右”。
华为云的解决方案是“将大块的计算和通信,切分成小块的副本;系统会自动编排多个副本间计算与通信的执行顺序”,小块的通信更容易被隐藏在计算中。另外,“还有NP hard问题的自动寻优优化,正反向流水交织等等关键技术。”
“还优化了大集群的调度和通信。通过rank table的编排算法,将大流量放到节点内或者同一机柜级的路由下,减少跨路由器的通信”;也“对原端口进行了动态编排,实现集群通信的路径完全零冲突”。
这些技术大概率是华为此前在通信方面的技术积累具体体现,表现的也是当代HPC与AI计算,优化性能与效率必须从系统层面下手的基本思路。据说藉由这些方法能够“有效隐藏70%以上的通信,bubble从30%降到10%”;MFU(Model FLOPs Utilization)也有比较理想的表现。
盘古模型也在解决华为自己的问题
在张宇昕谈的AI native华为云话题中,还有一部分是借助AI技术实现云平台的效率提升的,包括对于CodeArts、DataArts、MetaStudio,乃至GaussDB的帮助。
比如说CodeArts作为软件开发生产线,让AI来读代码、写代码、调代码、测代码——在盘古5.0的加持下,CodeArts的能力“从函数级升级到项目级”。
还有针对GaussDB高斯数据库,“我们将高斯数据库的产品文档、专家知识、运维经验等专业数据和大模型结合,构建盘古数据库大模型,实现GaussDB开发、测试、迁移、运维的全生命周期智能化”。
开发人员可以直接用自然语言生成SQL脚本,支持多表关联查询、存储过程等复杂的SQL生成;也支持将其他数据库SQL语句转化为GaussDB语法……这部分不是本文要探讨的重点,就不做过多赘述了。
不过这些实际上是AI for Cloud,乃至AI for华为全栈技术的体现,很大程度上算得上是华为自己作为盘古5.0用户的亲身实践了;也是盘古5.0在计算机科学领域的应用实例。

在国内的AI基础设施提供者中,华为大概是为数不多真正在生态层面有机会与国际巨头一战的市场参与者,尤其表现在两个关键点:盘古大模型深入到各行各业并不断加强能力,以及昇腾服务器、华为云作为推动华为AI生态发展的基础设施,从系统层面提供AI训练与推理的性能和效率优化。据说当前华为的AI框架份额超过了20%,迁移并孵化主流大模型50+,孵化的AI场景化方案有200+。
作为我们现在常说第四次工业革命的转折点,AI赛道上的盘古大模型及周边相关层级技术与基础设施的前行,在我们看来其重要性是绝对不亚于鸿蒙操作系统的生态发展的。在下一篇文章里,我们将谈谈本届HDC的另一个主角HarmonyOS Next,尤其是融入其中的AI技术:Harmony Intelligence。

