
前不久的Computex大会上,黄仁勋在主题演讲中谈自家面向生成式AI数据中心集群的Spectrum交换机,计划中未来的Spectrum-X1600会用于连接百万量级的显卡。换句话说AI数据中心的GPU数量过两年就会来到百万张——要知道现在搞AI的企业能做万卡计算就已经十分了得。
原因很简单,AI模型变得越来越大了,人们对于生成式AI的需求也越来越强烈。最近的芯原AI专题技术研讨会上,乌镇智库理事长张晓东也援引OpenAI的预测,2027、2028年最大的模型需要用1000万张卡来训练。“1000万张卡的功耗会达到GigaWatt级别,相当于美国一个中小型的州。”
生成式AI是否往这个方向走我们不知道,但生成式AI正在深刻变革人与计算机的交互方式,乃至人们的生活方式。芯原执行副总裁、IP事业部总经理戴伟进评价微软Copilot“不只是AI”,而是“深刻影响到与计算机交互方式的某种功能(function)”,“我们甚至无法分辨它是不是AI”。

随着AI Everywhere走向AI for Everyone的时代到来,包括英伟达、芯原在内的所有市场参与者普遍认同,AI要从数据中心,走向边缘、走向端侧,乃至走向嵌入式应用。今年4月份的IIC Shanghai期间,戴伟进在接受我们采访时就强调了AI全面走向边缘的趋势,而芯原现在正在思考的是如何在算力有限、功耗敏感的设备上,达成这一目标;与此同时芯片要兼顾可编程性与性能。
借着这次研讨会的机会,我们就来看看芯原具体是怎么做的,未来边缘AI又将发展成怎样。对芯片的AI相关IP做探讨,也有机会窥见英伟达之外的AI生态发展情况。
AI深入到端侧的时代
戴伟进说,我们现在所处的时代,已经是大模型进入嵌入式设备的时代。他举例谈到智能驾驶应用AI技术;智能手机现在能在本地跑文生图的Stable Diffusion 1.5,以及可进行本地对话的Llama 2-7B,能做以图搜图、实时翻译、智能拍照等;Copilot+PC的Recall特性,实时字幕、渲染交互等,AI PC也进入到了医疗和工业市场。“计算已经不限于CPU,NPU也加入进来;而且NPU最终的计算负载也将高于CPU。”
嵌入式领域内,前不久我们还在探讨MCU的AI化,微控制器都在强调指令级AI加速,以及融合专用的加速器。虽然要跑大模型暂时还不行,但电视、相机、PoS机及各类IoT设备都出现了芯原NPU/GPU/DSP/VPU IP的身影。
戴伟进表示芯原早在2016年就开始做NPU,到现在采用芯原NPU IP的芯片出货量已经突破1亿颗——覆盖72家客户128款AI芯片;GPU全球也累计出货了近20亿颗。从初期的AI视觉,到语音、图形到现如今的自然语言,覆盖AR/VR、自动驾驶、PC、智能手机、可穿戴设备、机器人等不同设备。
“再后来我们也走向了Transformer。”戴伟进在主题演讲中谈到,“所以这8年多的时间,我们和行业、客户共同成长。其实我们很多技术是头部客户驱动的——所以我们能够进入那么多行业。”
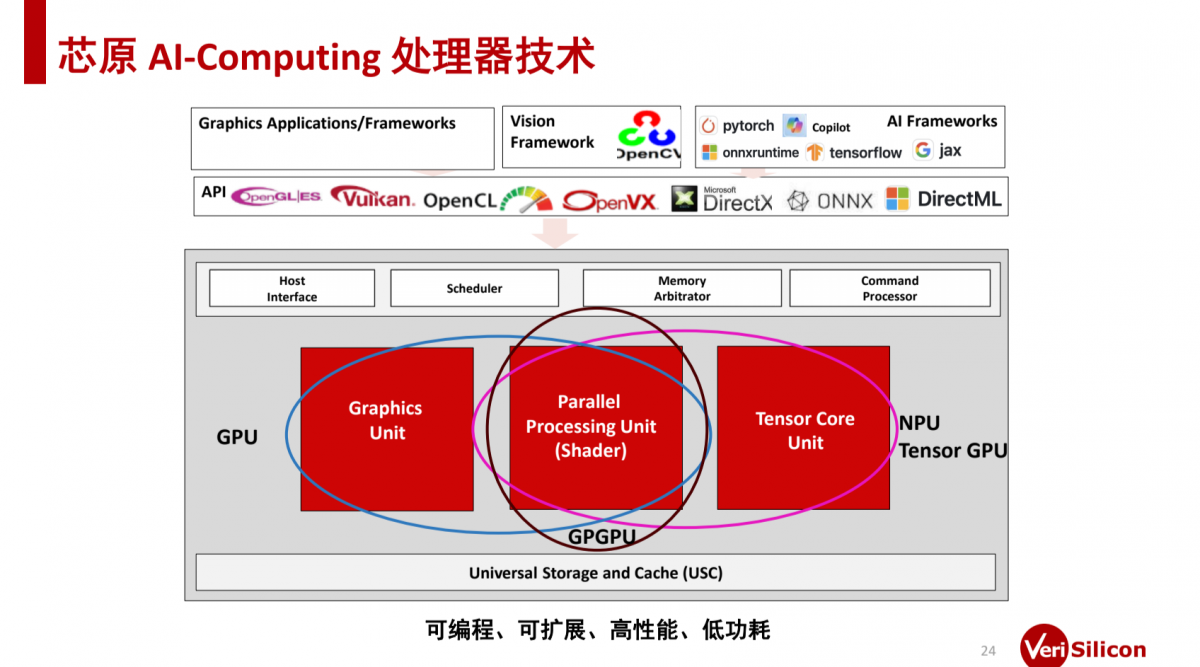
上面这张图展示的是芯原的AI软硬件堆栈。除了上层软件和中间件之外,硬件IP部分涵盖具图形单元的GPU,强调shader通用单元的GPGPU,以及着力在MAC加速的NPU。所以戴伟进说芯原“的技术具备相当好的伸缩性”。
IP本身,及其间相互搭配可满足不同的应用场景,加上各模块本身的可伸缩,在通用性和AI加速上实现平衡,“各种新技术都可以在这个组合中得以实现”。当这些IP覆盖不同算力需求的应用场景时,则如下图所示:

边缘和嵌入式设备AI推理与fine-tuning领域,主要采用芯原的VIP9X00系列NPU IP——可以是与其他IP紧耦合类似AI-ISP这样的的DSA加速,也可以是AIoT设备中的专用AI加速——规模上主要是2b-13b参数量的语言模型,以及其他感知和生成模型;
当追求一定的通用性时,考虑GPGPU IP;对于也需要图形渲染加速,兼顾通用与效率的AI PC这类场景,可以选择NPU + GPU IP;另外芯原也有面向数据中心的CCTC-MP方案,大语言模型为70b及更大参数量,这里的Tensor Core GPU IP也是考虑训练场景相对更为多样化,及对通用性的要求。
有关数据中心的解决方案这里多提一句。芯原高级副总裁、定制芯片平台事业部总经理汪志伟大略谈到了某颗数据中心AIGC芯片的少量信息:提及计算核是多核高性能CPU,加速器采用芯原GPGPU-AI IP,存储部分为HBM3;而且整体是基于chiplet方案构建的。
“我们还为客户设计了,和硬件结合、充分挖掘硬件性能的、完整的从底层到中间层的软件协议栈,满足推理、训练要求;包括解决芯片之间、板卡之间互联的通信协议软件。”汪志伟说。

值得一提的是,此前谷歌开启了一个名为Project Open Se Cura的开源项目在“从云到边缘”AI实现上是颇具代表性的,芯原是其中的关键参与者。这是个开源框架,旨在加速安全、可扩展、透明和高效的AI系统开发。
其中提供一系列的开源设计工具和IP库,通过联合设计和开发的方式,加速机器学习负载的全栈系统开发。芯原自然是在IP、芯片设计、BSP开发和商业化的过程中提供自家的专业技能。
戴伟进介绍说这个项目追求边缘与云的协同计算,比如在智能眼镜这样的设备上以低功耗always-on的方式感知环境,而AI模型跑在移动设备和云上。具体到芯片层面,其中的低功耗安全智能传感芯片用于端侧大模型数据采集,其中内置了芯原的多种处理器IP。
本地跑AI模型的价值在于低延时的响应,具隐私和安全性,以及更具个性化(如此例中的情境感知)。“我们每个人都有手机。而当有更高的计算需求时,也可以发往云。”“不仅为数据中心提供了价值,更重要的是AI也进入到了嵌入式设备,而且还是协同计算。”
“我想这其中的价值,是AI真的可以以离我们很近的方式为我们赋能,而且十分自然(less intrusive,少打扰)。”
从端到云的生态概况
谈得再具体一点,芯原NPU IP研发副总裁查凯南展示了NPU IP架构大致的框图:
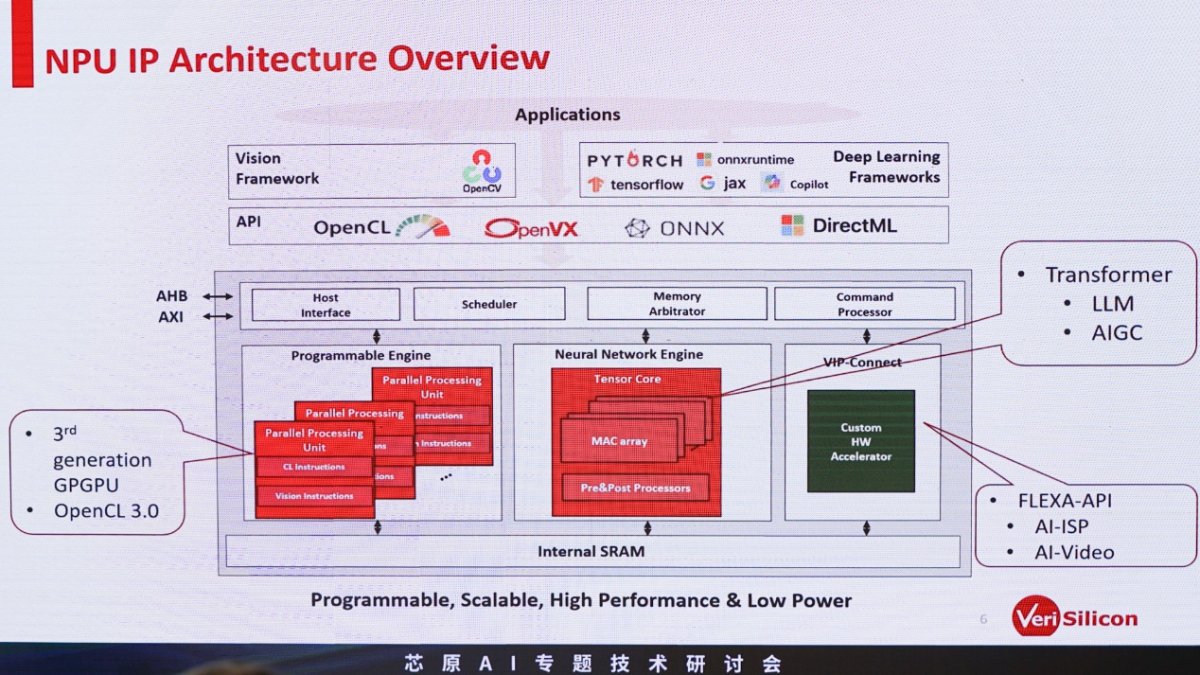
芯原的NPU核心部分,大框架有个可编程引擎——可类比于GPU里面的shader核心,可做“通用运算,不管是科学运算还是训练网络的优化、损失函数等”;中间是我们日常所说真正用于AI加速的tensor core,进行矩阵乘的密集型运算;另外还有前文提到DSA相关的诸如AI-ISP、AI-Video加速的部分。
值得一提的是,在Transformer成为绝对的主流以后——包括视觉、音频、LLM等方面的全面开花,很多AI芯片也逐渐开始加入所谓的Transformer引擎——即便这并非一个单独的物理模块。查凯南在演讲中提到了芯原的NPU IP在Transformer加速上的考量。
包括数据格式的混合精度支持,INT4/INT8/FP8/FP16都是常规,还有AF16W4, AF16W8——查凯南解释说是16×4, 16×8“一些比较特殊的数据格式,把权重做4bit和8bit的量化压缩,大幅降低带宽消耗”;矩阵运算GEMM/GEMV(General Matrix Multiplication/General Matrix-Vector Multipilication)加速支持,矩阵转置引擎,流处理器等...
“在VIP9000架构里面,我们针对Transformer网络的性能提升达到了10倍。”

再来是软件栈的情况——这也是AI芯片竞争的关键。应用层的PyTorch, TensorFlow, ONNX Runtime支持都算是常规。推理部分的工具,芯原自研了Acuity Toolkit,“可通过工具链直接导入所有流行的框架”,“内部嵌入了模型转换、量化,及优化的相关功能”,“可直接生成易于部署的network binary”;
LLM推理引擎选择的则是支持vLLM(Vectorized Large Language Model)——一个开源的LLM推理库,查凯南说这是芯原最新做出的适配;硬件支持主流数据格式INT4/INT8/INT16/FP16/BFP16/FP8。
训练部分的框架,则主要是PyTorch 2.0的Torch Dynamo以及TensorFlow XLA后端接入;“芯原提供完整的计算库,包括可编程tensor core的引擎”;还有“我们自己写的”AI Compiler部分,以及再往上层分布式训练所需对接的Megatron和DeepSpeed支持。
有关训练比较值得一提的是支持Triton——Triton本身是OpenAI开发用于GPU编程的开放语言,一般我们说它是打破CUDA霸权的关键技术,也是诸多AI技术企业打算对接的新标准。“PyTorch 2.0之后的inductor会包含Triton的编译器。硬件厂商就可以直接通过编译的方式去接入Triton。我们的后端编译器也可以通过Triton接进来。”查凯南表示芯原计划于今年10月“完整接入Triton”。
从整个结构来看,芯原的AI生态走的也是开放路线。这也是在英伟达AI制霸时代下的常规思路。
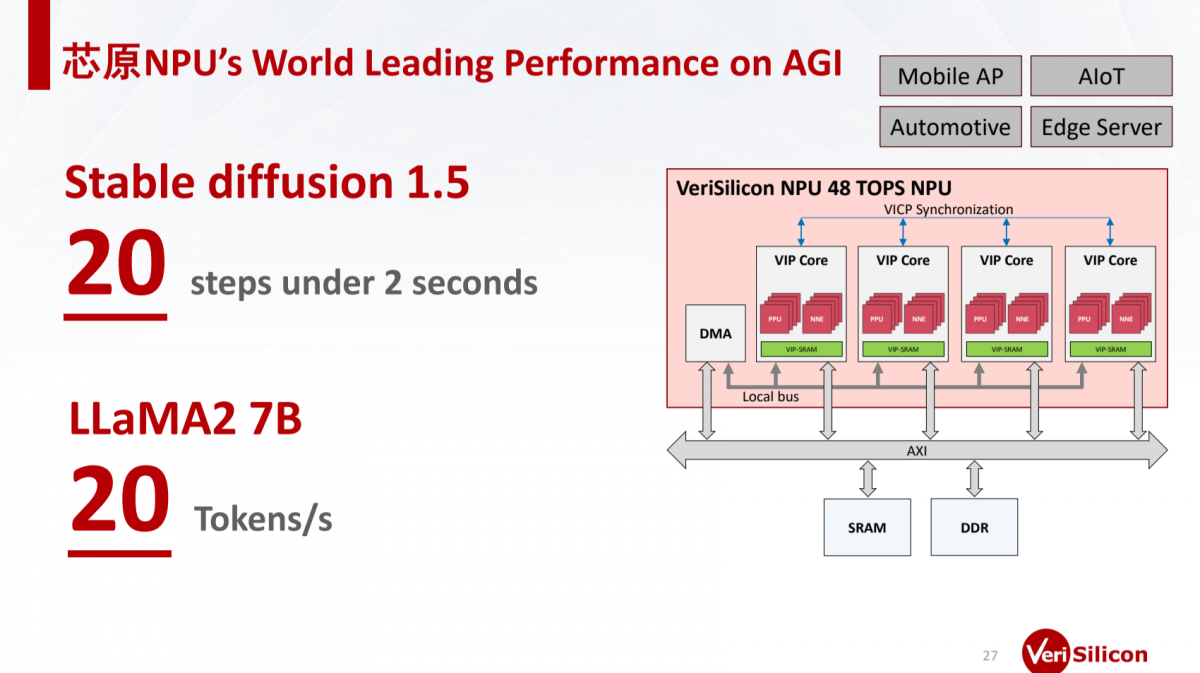
最后有关芯原NPU IP性能有个粗线条数据:VIP核心构成48TOPS算力的NPU,设定20 steps迭代跑Stable Diffusion 1.5生图<2秒;Llama2-7B模型推理则达成20 tokens/s的性能。虽然这个数据还是模糊了点,但总体都是相当出色的指标。
AI的征程刚刚开始
AI专题技术研讨会也可以算作是芯原AI生态布局的一环。所以研讨会上,我们也看到了不少采用芯原AI技术相关IP的芯片企业参与,比如AI-ISP,比如所谓具身智能机器人所需的3D空间计算芯片——“机器人加上大模型,能够与人进行更自然的交互。”戴伟进说,“计算机未来能够移动,一直在你身旁,跟着你,甚至能对你笑。”
神顶科技(南京)有限公司董事长、CEO袁帝文说PC、手机和嵌入式领域的AI发展,会为机器人大模型的发展提供助力;但与此同时,机器人本身还需要感知世界、导航避障、与物理空间交互。而且机器人也同时作为一个典型的端侧、边缘设备,AI算力需求又将远高于PC这样的端侧,因为其感知和交互是多维的,还涉及空间计算。
近两年英伟达开发者大会都将机器人技术视作AI从数字世界走向物理世界的关键,这其中涉及到方方面面的技术,“3D空间计算芯片+NPU,是掀起物理AI浪潮的必备组合。”而机器人在我们看来也会是AI、生成式AI下一个要全面应用和大力发展的市场,并由此影响到工业制造、医疗健康、零售、智慧城市千行百业。半导体这个万亿规模的产业,也会因此撬动全球经济。

芯原创始人、董事长兼总裁戴伟民在圆桌环节说,“前三次工业革命我们起步晚,不过我们有机会追得上;但这次我们不加快步伐的话,恐怕就永远追不上了。”“因为这是相关各行各业的技术,不是汽车、手机、PC或者任意的某一个领域。”“所以这一次,我们没有选择,无论如何非追上不可。”这大概也是芯原在生成式AI时代下努力加强技术研发,加强合作的动力之一。
张晓东说,“以前物理学家费曼说微积分是上帝的语言;但现在上帝的语言已经变成了图灵机。”而“图灵机是最广义的计算装置”;与此同时“所有的学习问题等价于图灵机求逆”,“所有的学习问题等价于next token prediction”......似乎生成式AI现如今的发展是计算机科学走向的必然。
从历史尺度来看,自然语言处理从过去几十年才进入新范式,到10年一迭代,以及后续以年为更新单位,“到今天大模型的迭代速度已经以周为单位了,几周就会有新的东西出现。”这似乎让我们看到了AI快速行进的开端,以及未来的无限可能。生成式AI的征程才刚刚开始。

