
今年Computex的主题演讲中,黄仁勋(英伟达CEO)打了个挺有趣的比方:如果用2016年Pascal架构的显卡来跑生成式AI(GPT-4),那么每生成一个token,需要消耗17000J的能量。17000J是什么概念呢?2个灯泡亮两天差不多是这么多能耗——虽然没具体说灯泡功耗...
换句话说,这样的2个灯泡连续亮两天的能耗,只能生成GPT-4的1个token。要知道平均3个token才构成1个单词——可以想象以Pascal架构来跑ChatGPT的话,ChatGPT说出一句话就得耗费多少能量...也就是说当年的硬件条件也的确孕育不出现在相当流行的生成式AI。

到现如今Blackwell正式开始量产,每个token的生成能耗是0.4J。有这样的量级差异感知,才能理解英伟达所说AI算力8年内增长1000倍,以及GPT4-1.8T训练能耗现在仅为8年前的1/350(从Pascal的1000+ Gwh,降低到Blackwell的3 GWh)。
至于GPU和对应的系统,究竟是怎么在这些年实现如此性能提升的,我们过去曾数度撰文做过探讨:无论是架构变革、chiplet、先进封装技术的采用,还是系统层面的效率提升——包括芯片间与节点间互联相关的一揽子技术。
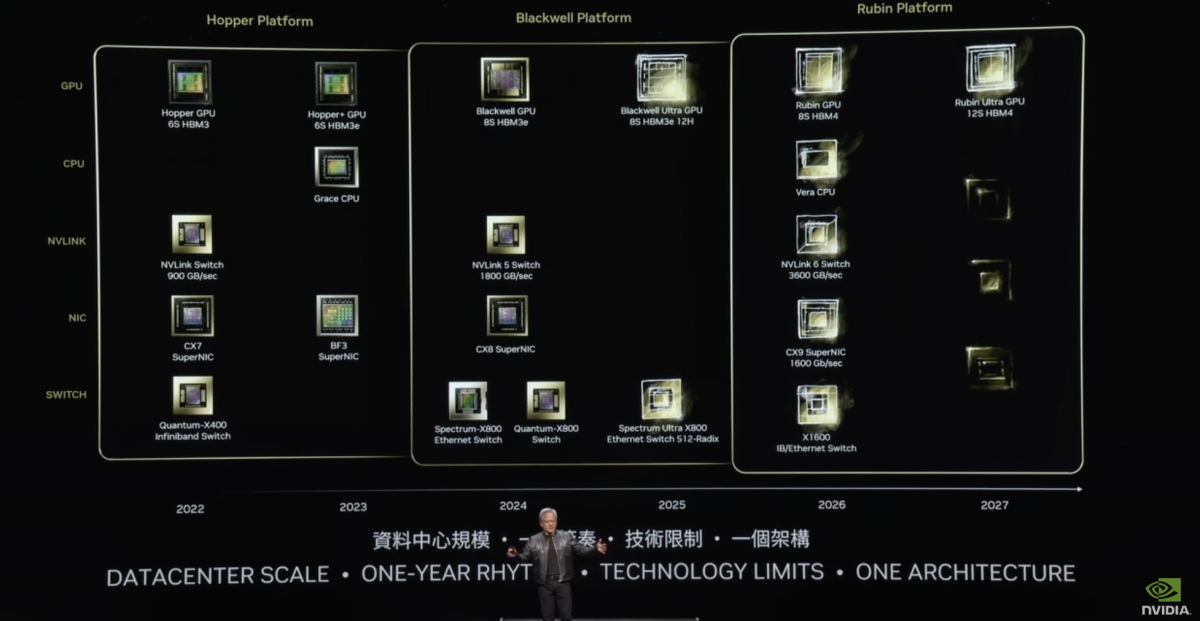
这次英伟达还预告了明年的Blackwell Ultra、2026年之后的Rubin平台;NVLink 6交换技术,以及对应下一代Spectrum交换机。黄仁勋在谈Spectrum-X800及未来Spectrum Ultra X800,和X1600的规划时,表示容纳百万GPU的数据中心时代就要来了,因为有更大的模型要训练,更多的人需要更频繁地与生成式AI做交互。
我们倒是非常好奇,以当代半导体与电子技术的进步速度,即便在系统层面再做优化和精进,这种一年一更新的节奏在未来数年内还能达成多大幅度的性能与效率提升...
不过对于生成式AI的发展而言,算力一味提升只是一方面:现在更关键的问题恐怕在于生成式AI如何全面落地?无论是对于企业还是个人。之前我们也多次探讨过现如今即便对于企业市场而言,生成式AI都处于萌芽阶段——真正在业务开展过程或产品中融入生成式AI的企业还不多。
一方面说明生成式AI的发展潜力巨大,另一方面是很多企业都期望借助AI技术来提升生产力、创造价值。但开发者其实并不清楚要怎么做,或者欠缺导入生成式AI全流程的能力。所以今年3月份的GTC上,英伟达推出了NIM(NVIDIA Inference Microservice,英伟达推理微服务)。

再谈NIM,生成式AI赚钱的关键
NIM无疑是英伟达的生成式AI要在企业市场乃至可能的AI PC做进一步推广的关键,是英伟达普及、巩固AI生态的重要产品,也是未来要将生成式AI进一步变现的技术。说句大白话,就是要让更多的客户用上生成式AI。
简单回顾一下什么是NIM。阻碍企业部署AI技术的一大关键在于,跑AI的计算堆栈相当复杂。比如ChatGPT这么个面向用户看起来还挺简单的服务,底下有一大堆的软件层级。
另外千亿、万亿参数量级的大模型也不是只跑在一台计算机上,而是一堆计算机:负载在大量显卡之间做分布,进行各种各样的并行计算。而且一旦数字化、AI深入到业务流程,像这样一个AI数据中心运转起来的效率,是直接关乎企业成本和营收的。
所以英伟达总结企业客户的需求在此有两点。第一是AI必须易于部署——以前要几周才能部署好的,现在最好几分钟、十几分钟就能搞定;第二是性能要好,生成尽可能多的token,且更智能。
对于第一点,简单来讲就是开发者需要一个完全打包好的方案,最好开箱即用。黄仁勋形容NIM就是“AI in a box”。这个盒子里面囊括了一大堆的软件、工具。比如说CuDNN,Kubernetes容器环境、云原生堆栈,推理需要用到的TensorRT-LLM, Triton Inference Server,还有AI模型、统一的API,以及优化引擎等等...据说其中整合的库有409个之多...
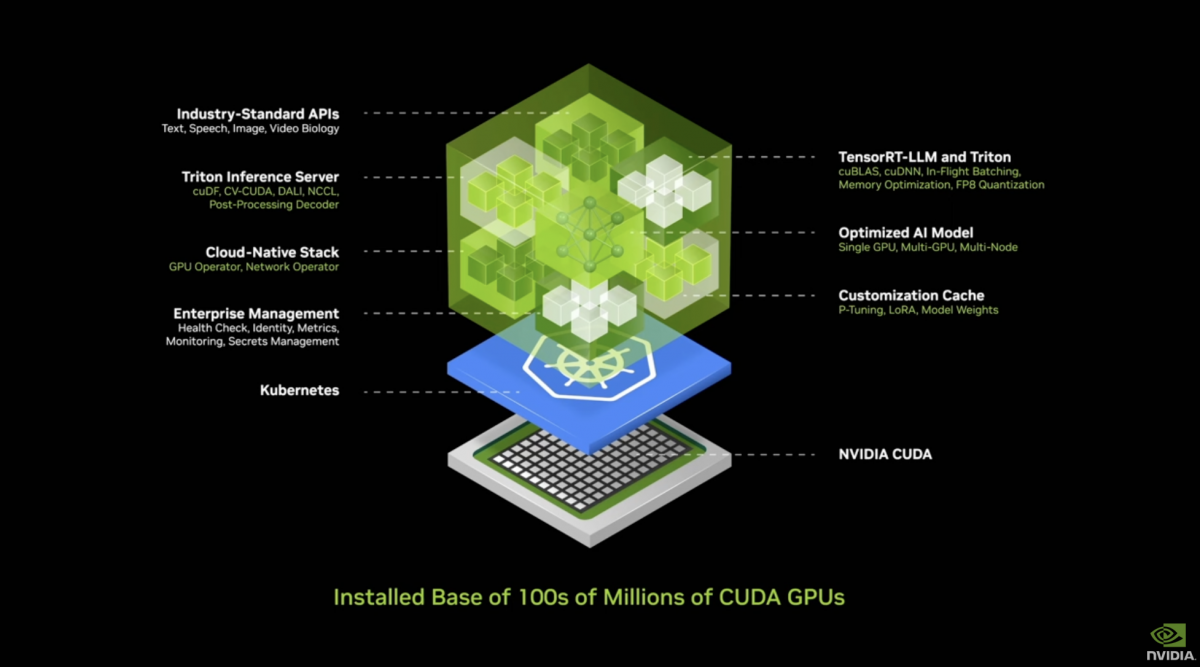
简单来说,NIM提供了可用于部署各种AI模型、部署到任意能够容纳container环境的runtime。企业可以直接用NIM里面的模型;也可以借助英伟达的工具,基于自家数据来fine-tune这些模型;最后将这一堆东西部署到想部署的地方——NIM可以下载安装到任意位置,公有云、数据中心、工作站皆可。
一个NIM就是个类似ChatGPT的对话AI,其种类基于模型差异当然可以是多种多样的——不管是客户服务对话AI,还是供应链助手、医疗数字人助理等等。最终可将这些微服务接入到大型应用中。
但光是易于部署还不行,所以第二点,英伟达提到性能。这里的性能并不是指GPU性能,而是软件层面的效率和性能。英伟达表示针对NIM做了不同领域的覆盖,接入不同领域和来自不同供应商的各种模型。而借助以往各领域应用的优化经验,让模型在相同的硬件上跑得更高效,是NIM期望达成的。

据说针对Llama3-8b模型,相比于“NIM Off”,模型跑在NIM里面吞吐就领先了3倍(tokens/sec)——虽然具体也没说究竟是什么样的硬件、什么样的环境。但此处强调的仍然是开箱即有的、优化过的推理性能。
在我们看来,NIM的一大价值就在于让AI开发者更多地专注到业务逻辑上,而不需要把时间都浪费在模型部署的复杂性、可靠性和性能优化上。
各种各样、一大堆NIM
这次英伟达正式宣布了NIM作为产品发布——不过这还不够。
针对NIM,英伟达也拉来了一些合作伙伴,比如Hugging Face:比如像现在Hugging Face社区里的Llama 3模型卡页面,会直接有选项可选择部署到NIM。对已经在做AI开发,有对应工具(如LangChain, LlamaIndex等)的开发者来说,都可以“将NIM融合到他们常用的工具中”,“无论开发者选择如何做开发,都能找到NIM”。
本次公布融合、分发NIM的合作伙伴有150多个,即将NIM融入到他们的平台中,并分发给用户和开发者。从公布的合作伙伴列表来看,主流的生态链参与者几乎都涵盖进去了。可见生态前期开展工作还是做得相当迅捷...

另外有关NIM,本次主题演讲还有个重要发布。上次GTC就已经宣布了NIM作为NVIDIA AI Enterprise的一部分,面向NVIDIA AI企业用户可用。也就是NVIDIA AI Enterprise中现在“包含了所有的NIM”。而这一次是通过NVIDIA Developer Program开发者计划,所有开发者可以免费访问NIM,用于应用开发、研究、测试,以及最终实现产品化。
这些动作应当都算得上是卯足劲要推NIM了吧:发动现有企业、开发者,和合作伙伴资源,让NIM持续渗透到AI应用开发中。所以说NIM是未来一段时间生成式AI落地的关键。
要更具象地理解NIM也不难。我们不止一次地撰文谈到过NVIDIA ACE(Avatar Cloud Engine)技术,尤其是游戏开发对于ACE的应用。游戏中的NPC借助于这项技术,就能直接和玩家进行语音对话:玩家说什么,NPC都能给出基于其人物设定的回应。
将一整套方案和环境打包,NVIDIA ACE自身就形成了一个NIM微服务。开发者可以将ACE NIM融入到其现有产品的框架中,达成数字人的呈现。我们之前在CES、GTC上看到的NVIDIA ACE演示,其本质就是英伟达作为开发者去接入ACE NIM的过程。
ACE作为一个打包好的容器,是NIM的具象化这件事,是黄仁勋在主题演讲中说的。于此,更多NVIDIA AI应用层布局的技术,包括RIVA, Audio2Face什么的,也就都有了NIM的第一方实现(可从ACE NIM中剥离?)。
谈点儿更有现实意义的:主题演讲中列举的需要用到生成式AI的典型场景是客户服务,不管是零售行业、金融保险,还是医疗领域,都需要有AI加强的客户服务。“所有这些盒子基本上都是NIM。”黄仁勋说,“其中一些NIM是逻辑代理(reasoning agent)——给它一个任务,去理解任务并将其切分成不同的工作计划。”
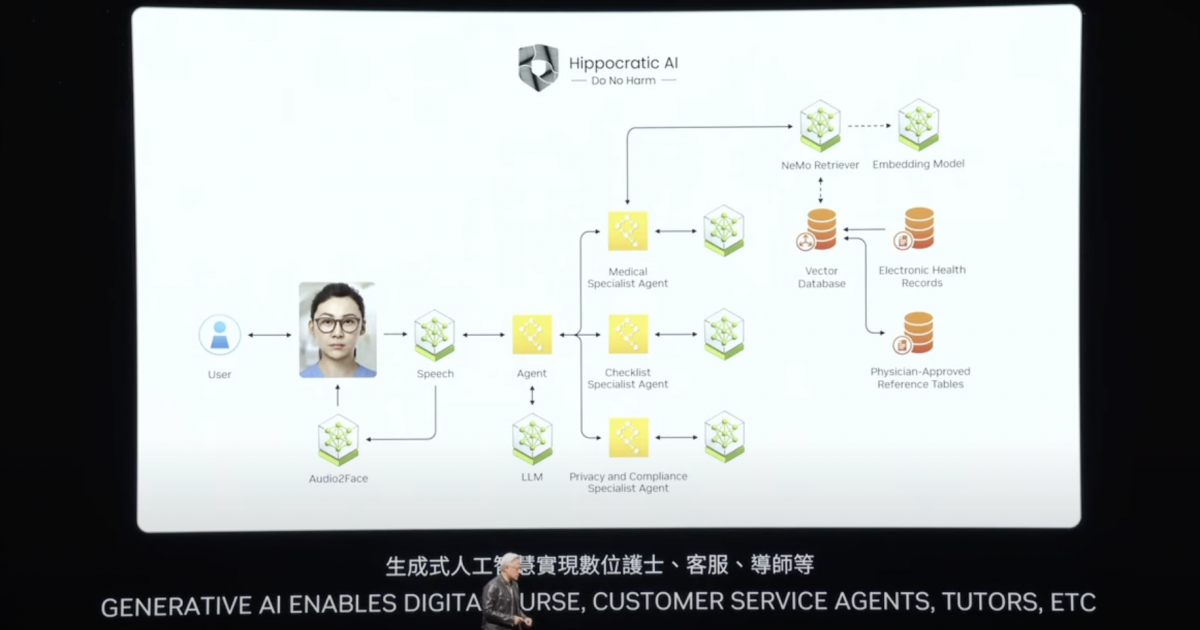
“有些NIM负责提取信息;有些NIM可能执行搜索;有些NIM可能会用到工具——比如CuOPT或者能跑在SAP上的工具;还有一些则进行SQL查询……所有这些NIM组成一个团队。”“团队成员执行他们的任务,然后把结果交给‘队长’,‘队长’思考以后将信息呈现给你。”
相比于企业和开发者以前开发应用的传统方式,这个过程的确是个十分巨大的变化。所以英伟达认为,每家企业将来都会有一大堆不同的NIM。“这会是未来应用的构成方式。”
与其说是一大堆NIM,倒不如说是不同用途的一大堆模型。只不过为了部署方便,开发者可以选择NIM。看起来英伟达对于NIM的确是抱持着十分宏大的愿景。所以我们说NIM的重要性,于英伟达绝对是不容小觑的。
一个例子:NIM与游戏
今年的GTC分析师采访环节,有人提问英伟达在AI PC趋势面前扮演何种角色。“我们之前做的一件事情是让Windows能跑CUDA。”黄仁勋特别提到CUDA对于WSL 2的支持。基于NVIDIA与微软的合作,Windows平台“有了WSL 2以后,PC用户就能用NIM了,下载以后马上就能跑。你就能跟你的PC对话。”
当然这里的PC至少也是工作站级别了。对大众而言这个说法可能还有些未来向,也还有进一步深究的余地。不过它大概可表明NIM对于AI PC还是具备潜在价值的。这次Computex上英伟达也发布了几款新的RTX AI笔记本——到目前为止,RTX AI笔记本型号数量超过了200款。前不久我们也撰文谈过英伟达在AI PC时代的特殊地位。
从RTX AI PC的角度来看,Windows平台的AI应用开发者面临的局面,和前述企业客户在业务中想要融入生成式AI技术,其实是类似的。一方面是大模型要跑在端侧相对受限的硬件资源上;另一方面,虽然市面上已经有高质量的开源预训练模型,但这些模型仍然是比较通用的。
AI开发者理论上需要对模型首先进行定制,来符合其业务特点——比如游戏NPC讲话,对话内容必须围绕游戏剧情,也要符合人物性格、记忆之类的基础设定。然后还要对模型做优化,并且最终部署到PC或者云上。
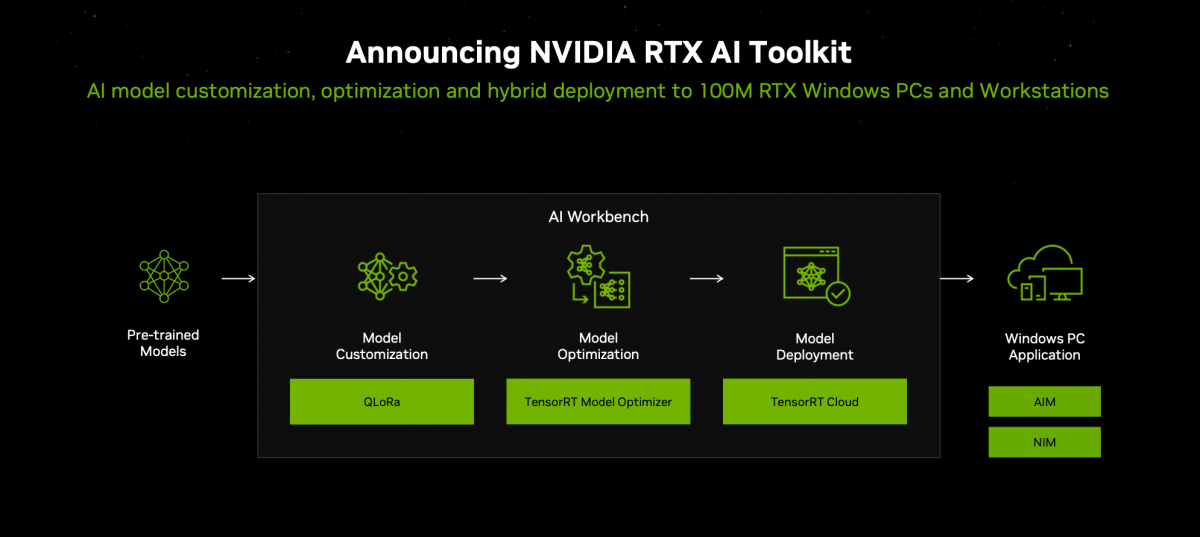
对此英伟达在Computex上发布了RTX AI Toolkit开发工具。这其中就包括了在Windows应用和游戏中定制(QLoRa)、优化(TensorRT Model Optimizer)、部署(TensorRT Cloud)AI模型的工具,能够在PC和云之间做推理的编排。在最终的应用侧,可以用新发布的NVIDIA AI Inference Manager(AIM)加上NIM在本地或云上跑AI。
这里的AIM是个面向所有后端(NIM, DirectML, TensorRT)和硬件的统一推理API,能够跨本地PC和云做AI推理的编排和管理,并且进行模型和PC运行环境的下载与配置。
英伟达针对这套流程,演示了通用Llama 3模型在不做任何定制与优化的情况下,不仅需要GeForce RTX 4090级别的桌面GPU才跑得动——吞吐48 tokens/s;而且生成的回答也不具任何应用针对性。
而在借助RTX AI Toolkit开发工具的情况下,开发者定制模型的回复明显更像是个游戏NPC,而且RTX 4050就能跑得动,吞吐也提升至187 tokens/s。

不出意外的,英伟达这次也宣布了面向RTX AI PC推出ACE NIM——顺带里面还放了英伟达自己的Nemotron SLM(Small Language Model),4.5b参数量。NVIDIA ACE作为一种数字人技术,面向的也不单是游戏,包括了前文提到的客户服务、医疗助手等应用。
不知道如果单纯基于Nemotron做文本生成的话,ACE的推理流程是否还需要云的介入——因为此前英伟达是将ACE定位为结合了本地与云推理的混合AI的。
其实ACE对于英伟达而言,倒是一种更能体现英伟达这家公司现如今图形、模拟与AI交汇的特质的。数字人的外貌、动作本身就需要3D图形技术支持,甚至动用实时的路径追踪实现反射、次表面散射之类的效果,比如像下面这样。

这种过去看来比较纯粹的图形实现,现在也开始大范围采用AI和生成式AI技术,让实时的路径追踪成为可能。
图形技术主要应用之一的游戏,在DLSS, ACE,以及本次我们不打算作为重点去谈的Project G-Assist(解决现在游戏的复杂性问题,面向玩家可直接文字或语音对话的AI助手)这些AI工具融入以后,外加RTX Remix这种融入生成式AI的MOD制作工具,AI正从各环节影响游戏。
扯得有点远了,拉回到NIM——我们认为,以NIM微服务形式影响游戏开发,在未来其程度应该还将变得更深。而游戏公司、游戏开发者作为一类NIM目标客户群,其实和其他行业的企业客户是类似的,这原本也是英伟达的主场。
从另一个角度来看,这是否也会成为英伟达在端侧持续吃进AI PC市场的关键呢?或者它只是NIM影响AI PC的冰山一角。

随NIM的推进和落地,未来我们与计算机的互动,以及不同计算机的token生成大概会变成常态——虽然这个目标听起来还稍微有点距离。但英伟达对于生成式AI的价值预期是,未来AI工厂 – 生成token,类比于发电厂- 发电。将来人们对于AI生成token的依赖,将如同用电需求。而且基于万物皆可生成的原则,token生成将在各行各业变得普遍。
因为生成式AI生成的不仅是我们现在直观看到的文本、图像和视频,还会有基因、脑波、天气、物理学、路上行驶汽车的转向控制、工厂里机械臂的关节动作等等。则IT这个3万亿美元价值的行业将撬动百万亿级别的各行各业,像英伟达这样的芯片企业自然是能够分得一杯羹的——即便类似NIM这样的东西,将来可能还会发生结构和形态上的变化。

