
近日,复旦大学自然语言处理(NLP)实验室LLMEVAL团队做了一个极具创意和挑战性的尝试,开创性地用高考数学题来评测大模型!
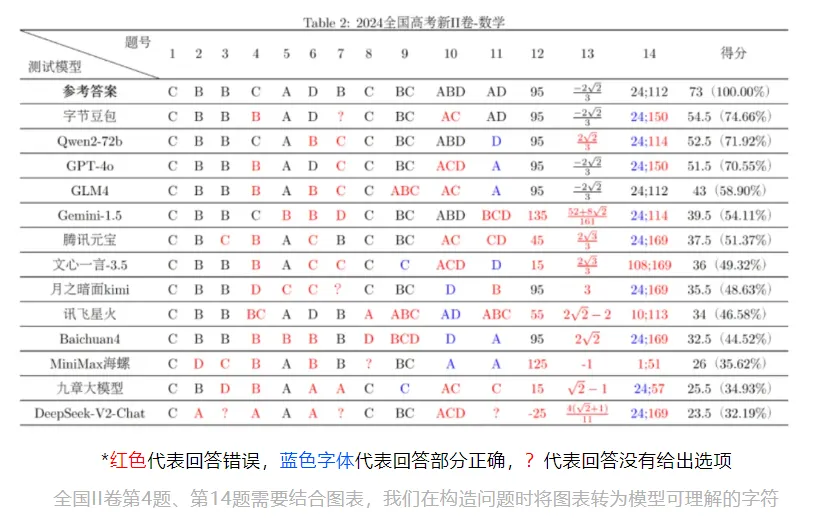
根据公开的2024 年高考数学大模型评测结果,阿里千问和讯飞星火分别获得了 2024 高考数学新 I 卷的第一名和第二名,以及高考数学新 II 卷的第二名和第一名,两份考卷的评测中,而GPT-4o 均列第三名。
据悉,LLMEval是由复旦大学NLP实验室推出的大模型评测基准,专注于评估专业领域的知识能力。评测团队表示,全新出炉的高考试题具备高度的独创性和保密性,是用来评测大模型的“绝好评测集合”。因此,团队在高考后第一时间对GPT-4o、文心一言、阿里千问、字节豆包等13家大模型进行了评测。

AI大模型成绩都不算太高
据悉,复旦大学NLP实验室的大模型评测LLMEVAL团队选取了2024年高考新I卷、新II卷数学试卷的14道客观题,用国内外的13个大模型“考生”测验。这些模型包括国内外知名的大型语言模型,如GPT-4o和Qwen2-72b。
在评测过程中,团队首先对数学试题进行筛选和分类,确保试题涵盖广泛的数学知识点和难度梯度。
具体评分标注如下:单选题共8题,每题5分,总计40分;多选题共3题,每题6分,总计18分,部分正确得部分分,有错误选项则得0分;填空题共3题,每题5分,总计15分;3项总分73分。
整体来看,AI大模型们的“高考成绩”都不算太高。其中,OpenAI 新一代旗舰大模型GPT-4o与阿里云研发的通义千问720亿参数大模型Qwen-72b在两次测试中排名都靠前,正确率稳定在60%以上。
部分大模型的表现存在起伏与波动,如百川智能、字节跳动新近发布的Baichuan4和豆包大模型分别在新I卷和新II卷客观题测试中得分排名第一,但在另一场测试中排名相对靠后。

图源:复旦大学NLP实验室
AI大模型仍有较大提升空间
通过两卷的评测,团队发现大部分模型在简单题(如选择题前三道)上有较高的准确率,而在中档题目上表现较为一般。Qwen2-72b(两次第二)与GPT-4o(两次第三)在两次测试中均名列前茅,显示出相对稳定的表现。
测试还表明,不同模型在两次评测中的表现存在较大波动,尤其在较难题目上,模型的准确率显著下降,有些题目甚至没有模型能完全答对。
总结而言,AI大模型对基础题目表现尚可,中档题目(涉及到数值计算和一定的逻辑推理)已经“力不从心”,复杂题目(涉及到严谨的推到和复杂的计算、以及图表理解等)无能为力。
此次测试证明,让AI大模型做数学题仍是一个难度较大的挑战,主要体现在以下几个方面:
一是文本输入格式的不同会对测试结果造成比较明显的干扰。目前测试主要采用上传图片识别文本的方式,这种方式更类似“人类”是对大模型能力的全面考验。而有的大模型还未做题,就先败在了AI识图这一步。
二是大模型的推理能力仍有很大进步空间。较难的题目对思维能力的考察要求更高,大模型的准确率也会更低。
三是在多选题方面,大多数模型表现不佳。可见,面临复杂选项的时候,大模型的准确率也会降低。
因此,AI大模型不管是逻辑推理能力还是按步骤解题的能力上,都还不及人类水平。
如何看待GPT4o被超越?
值得一提的是,数学能力是GPT-4o一直以来引以为傲的能力模块。OpenAI 在 5 月 14 日的发布会上推出大语言模型 GPT-4o 时,曾重点演示其数学能力。
然而,此次测试来看,Qwen-72b的表现要好于GPT4o。实际上,Qwen2绝对的智力程度是不如GPT4o的,造成这一差距重要原因可能是对于中文的理解以及处理。
有专业人士分析,从模型架构角度,GPT-4o基于OpenAI的GPT-4,采用了Transformer架构,是一种广泛应用于自然语言处理任务的深度学习模型。Transformer架构的核心思想是通过多头自注意力机制来捕捉输入数据中的长程依赖关系。GPT-4o通过预训练和微调两个阶段来进行训练。在预训练阶段,模型被暴露于大量的互联网文本,通过自监督学习来学习语言的统计规律和语义关系。
而Qwen2-72b具有720亿参数的语言模型,在参数数量上较GPT-4o有所不同,但也采用了Transformer架构。Qwen2-72b也通过预训练和微调两个阶段进行训练,但作为国内AI通用大模型,尤其强调在中文自然语言处理任务中的表现。
这两种模型的主要区别在于它们的规模和特定的优化目标,GPT-4o更侧重于广泛的语言理解和生成任务,而Qwen2-72b则在中文处理上有特别的优化。
因此,GPT-4o能够克服“水土不服”,拿到名列前茅的成绩,其能力可见一斑。
不过,从另外一个层面来看,最近半年来,国产大模型的发展突飞猛进,逐渐展现出超越国外模型的能力。例如,Qwen-72b就在之前的测试中力压此前的最先进开源模型Llama3。
最近,斯坦福大学抄袭面壁智能MiniCPM-Llama3-V的事件,也体现了国内AI技术的进步和竞争力。
另外,此次测试也显示,一个可以适应中文环境且拥有不俗智力程度的大模型,未来将具有很好的发展前景和潜力。
综上,尽管AI大模型可以解高考题,但离真正的“智能”还有不小距离。不过,通过不断地迭代和优化,以及训练过程中的各种磨合,AI技术的潜力无限。