
随着今年高考的落幕,一场鲜为人知的"智能较量"也在幕后悄然兴起,那便是国产人工智能大模型。
近日,搜狐科技、潇湘晨报、量子位、机器之心等十余家媒体对近10款国产人工智能大模型进行了高考作文、数学、物理三个科目的全面评测,并公布了成绩。
高考作文
考题以“随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?”为题,引领考生思考科技进步与问题之间复杂的关系。

搜狐科技组织了十款AI大模型的作文评测,包括ChatGPT-4O、腾讯元宝、百度文心一言等。三位资深语文教师作为权威专家为各大模型的作文打分。结果显示,ChatGPT-4O以52.7分的平均成绩夺得第一,腾讯元宝以51.7分位居第二,智谱清言、字节豆包与讯飞星火则并列第三。Kimi、阿里通义、百川、海螺排名相对靠后。即便排名最低的AI模型也获得了45.7分的平均分,考虑到作文满分为60分,这一成绩已相当于高中生的平均水平。
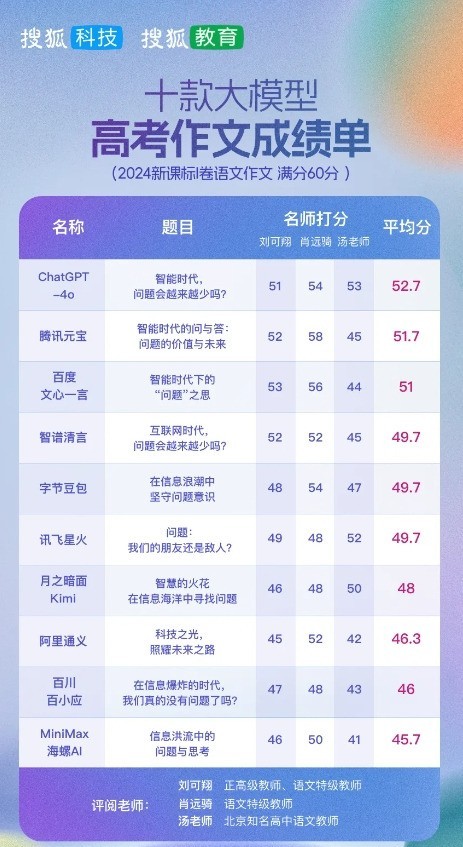
而在潇湘晨报的“AI写作”评测中,讯飞星火不仅平均分位居首位,且获得了全场最高分56分。潇湘晨报邀请湖南知名作家、编辑作为阅卷老师,对国内五大AI大模型产品——百度文心一言、讯飞星火、阿里通义千问、字节豆包、腾讯元宝的高考作文进行评分,经过四位阅卷老师的综合打分,讯飞星火以49分的平均分高居首位。
给讯飞星火打出“全场最高分”56分的阅卷老师表示:“本文观点清晰,论述集中且层层推进,很多句子都简洁有力,颇有思想性。如果是某个学生写的,无疑是难得的佳作。”
数学科目
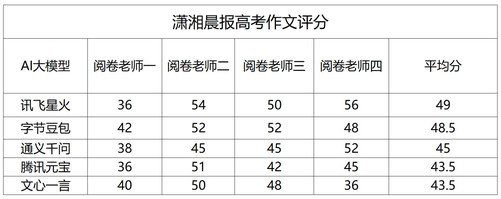
在搜狐科技的数学评测中,讯飞星火、文心一言、豆包均以63%的正确率位列第一梯队,智谱清言、阿里通义则以50%的正确率位居第二梯队,其他大模型相对落后。
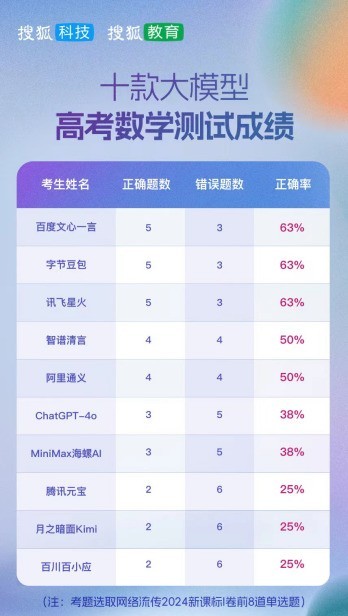
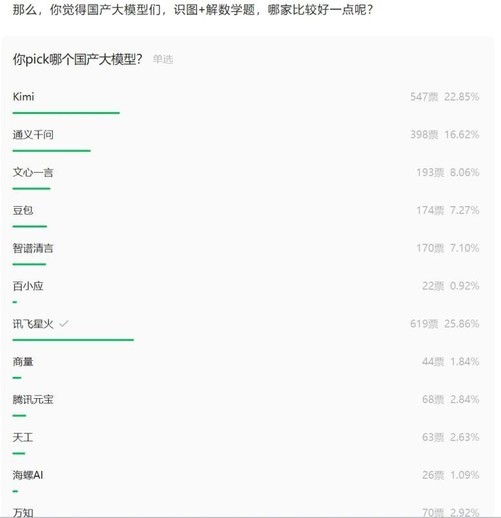
在量子位的高考数学评测中,虽然没有给出详细成绩单,但展示了各家大模型详细的解题思路,交由网友打分,通过网友的投票打分可以看出,讯飞星火的“识图+解数学题”能力收到了最高认可,位居其后的分别是Kimi、通义千问、文心一言、豆包等。
机器之心选取了六家国内头部大模型公司的产品与考生们一同参与一场客观且公平的高考数学考试(新课标 Ⅰ 卷),其中包括 GPT-4o、GLM-4、文心一言 4.0、豆包、百小应(百川 4)以及通义千问 2.5。
而在机器之心的评测中,大模型(产品)的表现并未达到预期,甚至出现了几乎全部不及格的情况,只有智谱最新发布的 GLM-4-0520 模型超过了及格线。
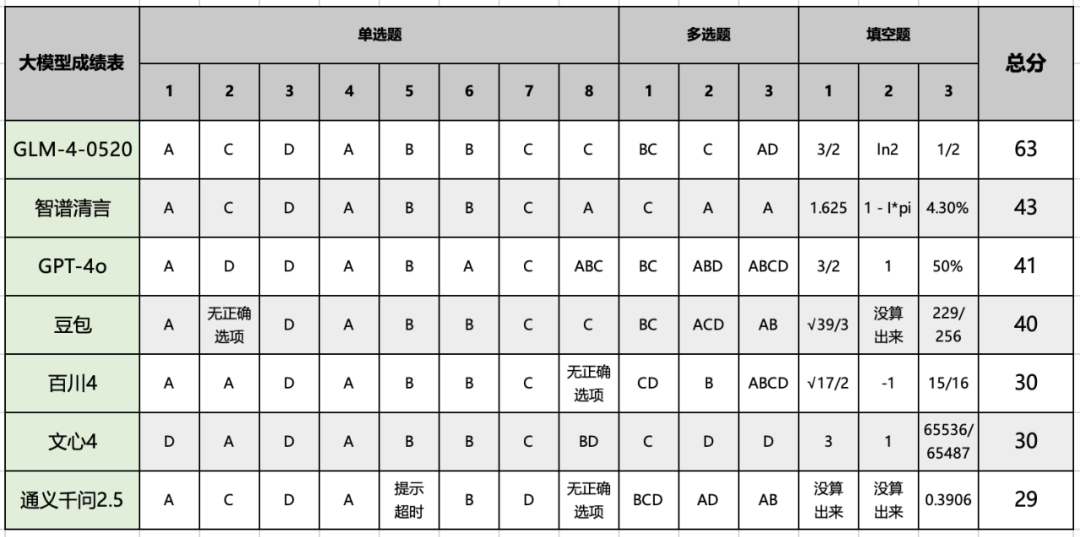
机器之心将评测的重点放在了高考数学的前 14 个客观题上,这些题目覆盖了基础的数学知识和计算能力,满分为 73 分。在测试时,我们将题目直接输入产品,不做 System Prompt 引导,直接输出结果;同时也没有触发搜索,没有来自外界的干扰。
分数计算方法依照高考真实判分原则:
- 单选题 8 道,每道 5 分,选项正确计分,错误不得分;
- 多选题 3 道,每道 6 分,全对计 6 分,漏选按正确答案数量计分,如答案为 ABCD,漏选其一扣 1.5 分,错选不得分;
- 填空题,3 道,每道 5 分,填空正确计分,错误不得分。
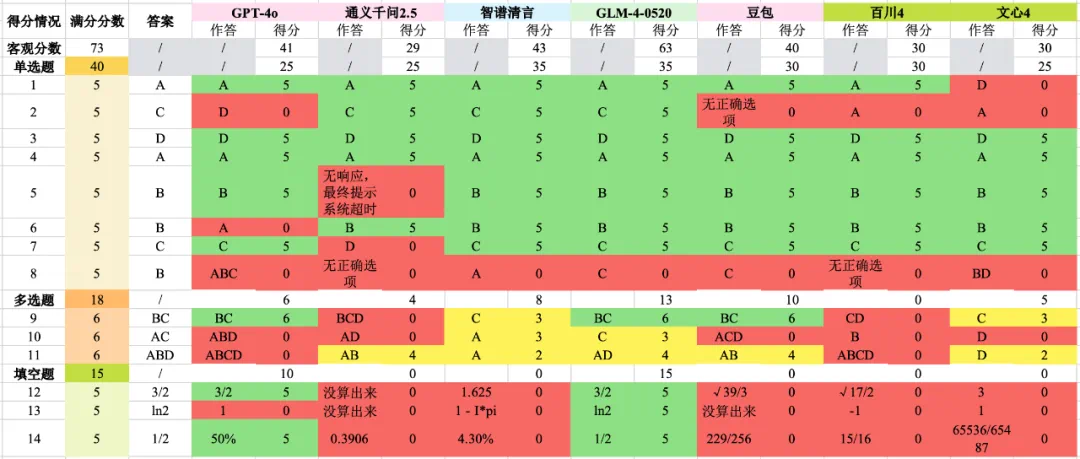
图|8 个模型对 14 道数学题的回答结果,绿色为正确、红色为错误、黄色为部分正确具体而言,在满分 73 分、及格线为 43.8 分(60%)的情况下,六家大模型产品的分数结果分别为:GLM-4-0520 (63 分) > 智谱清言 (43 分) > GPT-4o (41 分) > 豆包 (40 分) > 文心 4 (30 分) = 百川 4 (30 分) > 通义千问 2.5 (29 分)。
机器之心还指出,每年的第 8 道单选题往往是高考数学卷中最难的一道题,被测试的大模型都 “全军覆灭” 了。
机器之心表示,对大模型产品来说,高考语文作文可以直接测试它们的创造性写作技巧,包括构思、组织和表达观点的能力。
而在数学考试测试中,除了基本的计算能力、对数学知识的掌握,更能体现大模型在逻辑推理、抽象思维和问题解决方面的高级能力。大模型必须理解并运用数学概念、公式和定理,这要求它具备深厚的数学知识基础。同时,逻辑推理能力是解答数学题目的关键,大模型需要通过严密的逻辑推导来解决问题。
物理科目
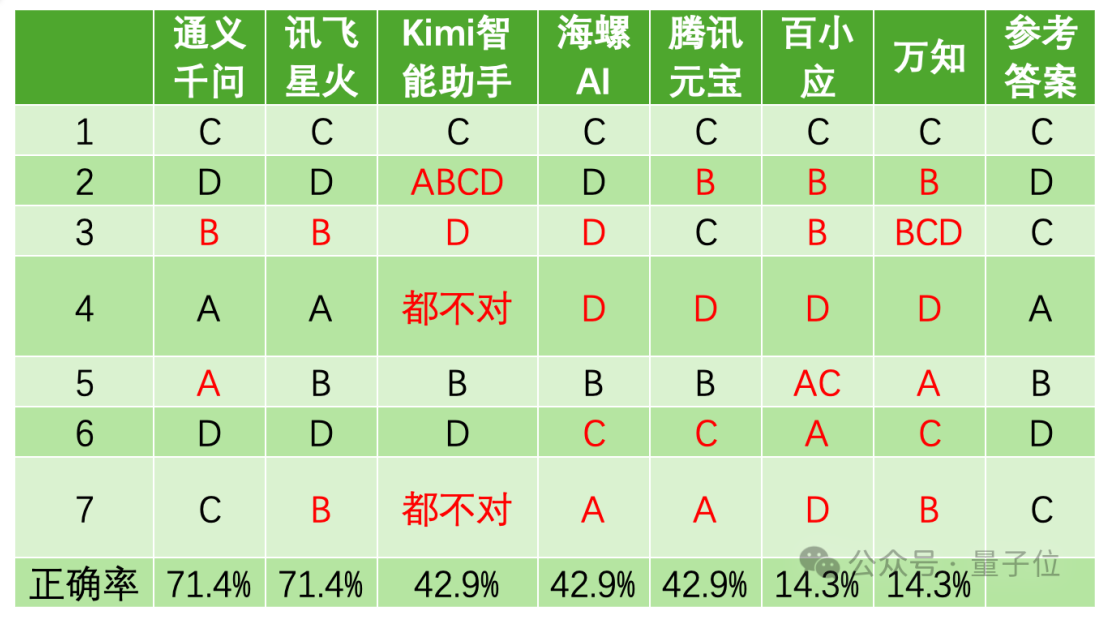
在量子位的评测中,阿里通义千问与讯飞星火以71.4%的准确率高居第一梯队,而Kimi、海螺和腾讯元宝则以42.9%的准确率位于第二梯队。百川百小应和万知答对一题位于第三梯队。
文心一言、豆包、天工、智谱清言、商量因为出现了不同程度读图失败的问题,在成功识别的题目中,商量和文心一言的正确率为2/4,即正确率为28.6%;豆包、天工、智谱清言正确率为1/2,即正确率为14.3%。
综合以上媒体在作文、数学、物理三门科目的成绩,来自科大讯飞的讯飞星火以总分52.49分高居综合排名第一。紧随其后的是通义千问和文心一言,分别位列第二、第三名。而Kimi、字节豆包、海螺AI等其他大模型也有不错的表现。
此次评测展示了人工智能大模型在应对高考这类复杂考试中的能力进展,体现了国内AI技术的快速发展。此外,高考作文单项成绩方面,有AI大模型取得了52.7的高分,显示出在语言理解和生成任务上的显著提升。
综合成绩:
第一名:52.49 讯飞星火
第二名:46.08 通义千问
第三名:37.67 文心一言
第四名:34.68 Kimi
第五名:33.57 字节豆包
第六名:31.92 海螺AI
第七名:30.61 腾讯元宝
第八名:30.28 智谱清言
第九名:21.56 百川百小应
