
酷睿Ultra 1代处理器——也就是Meteor Lake的发布,是去年12月份的事。感觉Intel和各大OEM厂商推广酷睿Ultra笔记本还没多久;Computex展同期的Intel Tech Tour活动上,新一代的Lunar Lake处理器技术解析就来了。
从Intel的计划表来看,Lunar Lake处理器Q3全面跑量产晶圆是箭在弦上的。最近隔壁AMD、高通也正卯足劲推广自家的PC处理器,可见PC处理器的技术迭代和市场宣发现在真是相当卷,连苹果的压力都前所未见地大。


Intel总结现在的酷睿Ultra处理器相比以往大致上有5个技术亮点:(1)混合架构,也就是CPU核心异构;(2)近几代处理器的iGPU核显性能大幅跃升;(3)新增NPU,并配合CPU和GPU做AI计算加速;(4)先进封装,Meteor Lake就已经在民用领域普及2.5D/3D先进封装和chiplet了;(5)开放生态建设。
如果你能理解这些,那么大概率就知道从微观角度来看,酷睿Ultra基本用上了商用领域时下最先进的技术——虽然最终“疗效”还远未及最优,大量亟待完善之处。所以我们对于Meteor Lake的看法是,它大概会成为未来PC处理器十多年的技术基础,但能改的地方还有很多。
这不还没到一年,Lunar Lake就来了。和同在计划表上的Arrow Lake不同,Lunar Lake应当是专门面向轻薄笔记本的能效型处理器。我们大致总结Lunar Lake的亮点如下:
(1)P-core取消了超线程设计,但IPC提升14%,能效提升18%;
(2)E-core大幅加强,IPC略超酷睿13/14代的P-core;
(3)低功耗强化设计有望大幅提升笔记本的续航能力;
(4)iGPU核显图形性能提升1.5倍,AI算力提升至67 TOPS;
(5)NPU算力较上代提升4倍,达到48 TOPS(Lunar Lake总体AI算力120 TOPS);
(6)“扩展可伸缩”架构设计理念的推行…
最近实在太忙了,无法一次将Intel技术分享中有价值的部分全部抽取出来。有关Lunar Lake的技术剖析,我打算切分成三篇:本篇是Lunar Lake处理器的概览,着重于处理器整体;下一篇会重点谈处理器的AI加速部分,包括NPU单元;最后一篇则会尝试详细谈谈Lunar Lake的CPU核心微架构。
其实这次更新的Xe2架构iGPU核显也挺值得单独写一篇的——不过因为它和后续要发布的第二代Arc独显共享一种架构,我们可以等到Intel新显卡发布时再论。后两篇的更新时间可能稍晚,毕竟Computex期间的大厂活动真的多;而且很快Intel至强处理器又有新品发布...这年头真是干啥都得卷...
值得一提的是,这次仅是Lunar Lake的技术分享,有关新一代酷睿Ultra的产品信息,比如说核心频率多少,有哪些SKU还是未知的。想了解这部分信息可能依然要等到年末。
内存装进了片内,chiplet设计依旧
从封装层面来看Lunar Lake,和上代产品一样也是基于先进封装的多die设计(Intel称其为tile、模块)。只不过这次的die数量减少了。
除了下方的base tile作为interposer/RDL之外,上层有三片die,分别是Compute tile(计算模块)、Platform Controller tile(平台控制器模块),还有一片Filler tile(填充模块?),应该就是我们常说的structural silicon——属于芯片设计中的结构承载件,没有逻辑功能。

尤为值得一提的是,Lunar Lake把原本位于片外的主内存也封装进了片内,就像苹果M系列那样。封装技术叫“Memory on Package”,这应该是一种更单纯地从substrate走线的2D封装方案。去年Intel也演示过Meteor Lake搭配片内LPDDR5X内存的样片;早在LakeField时期,Intel也曾借助PoP封装把内存装进芯片。所以Lunar Lake也不算是头一回了。
这么做好处很明确,一方面内存离CPU更近,配合MOP封装可降低功耗(至多40%);节约了主板面积(至多节省250mm²),降低主板设计复杂度。
内存具体规格为支持16b x4通道,最多2 rank的32GB LPDDR5X。不过这么做也增加了成本——尤其表现在对下游OEM/ODM而言,产品SKU更不具灵活性。

Lunar Lake本体的2片die,其中CPU, GPU, NPU等主要计算部件都位于Compute tile之上;而Platform Controller tile分布的是I/O连接、安全相关的部分。Intel这次特别将连接与安全作为单独的章节做了技术分享,我们不准备对这两部分内容做详述。(I/O数据连接部分的亮点主要是Wi-Fi 7、蓝牙5.4、雷电4的支持)
制造工艺未知,外媒此前有传言说Lunar Lake可能采用台积电N3B工艺。如果的确如此,那么采用N3B工艺的应该是Compute tile;Platform Controller tile传言用的是N6工艺;Intel Foundry自己基于22FFL工艺造了Base tile。另外,先进封装明确为Foveros,也是Intel自己完成的。
超线程没了,E-core性能超过曾经的P-core
位于Compute tile之上的CPU,仍然是P-core + E-core的异构设计。P-core名为Lion Cove,E-core名为Skymont。不过Intel只堆了4+4个核心。而且后文会提到Intel去掉了P-core的超线程设计,所以Lunar Lake的配置应该就是8核8线程。
这对多线程性能而言,实在不是个好消息——要知道隔壁苹果M4是4+6总共10核心设计;而上一代Meteor Lake则是6+8+2的设计(还要考虑Redwood Cove是支持超线程的)。猜测Intel可能会考虑用Arrow Lake的更多产品线来填补多线程性能缺位。
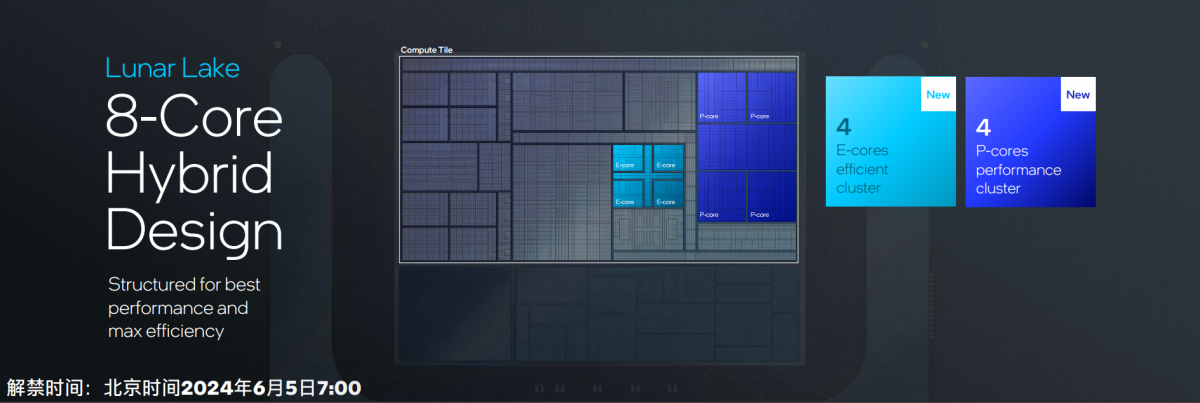
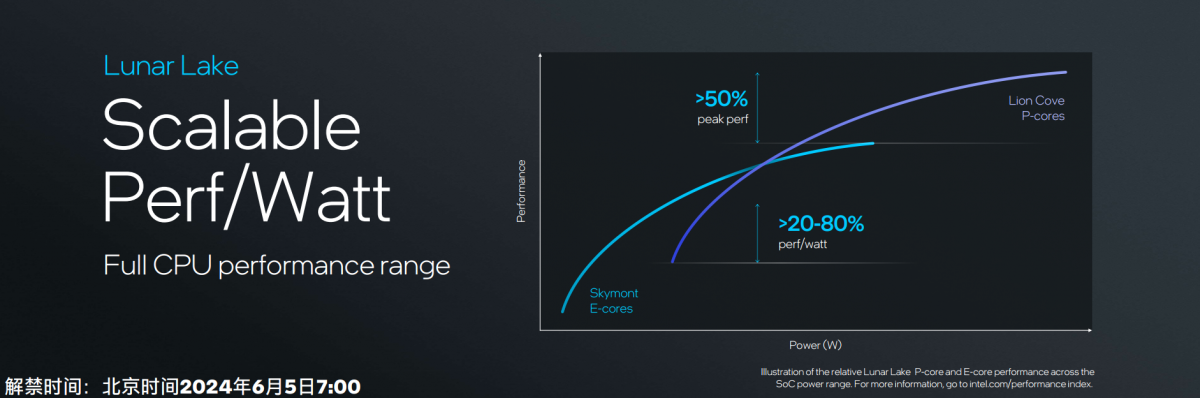
不过这次P-core和E-core在核心层面都有较大幅度的改动。Lion Cove相比于上一代Redwood Cove,IPC提升14%,能效比至多提升18%。因为不清楚最终的频率,没有系统层面真正的性能提升数字。不过IPC 14%提升也算有诚意了。
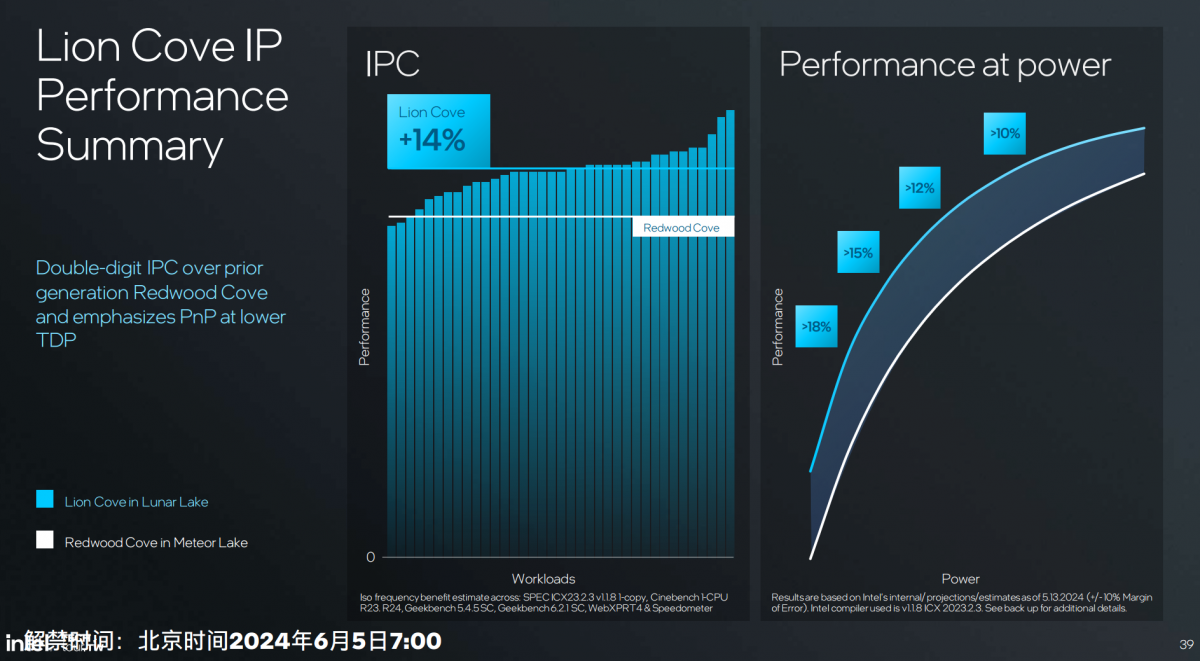
结合上个月Intel给出的信息:核心相比Ryzen 7 8840U和骁龙X Elite更快,说的应该就是Lion Cove核心了。
核心微架构并非本文要探讨的重点,整体来说就是架构显著加宽:包括前端明显更大的预测模块,取指模块、解码带宽提升,μop cache容量和读取带宽,以及μop队列条目也都加了;
乱序引擎的乱序度显著提升;后端执行单元也有对应的ALU增加以进一步提升吞吐;存储子系统DTLB(Data Translation Lookaside Buffer)扩容,AGU单元数增。Intel总结说微架构是彻底改造(overhaul),这些会在未来的文章中详述。

Lion Cove选配的L2 cache为每核2.5MB/3MB(Lunar Lake是2.5MB,Arrow Lake为3MB),Lunar Lake 4个Lion Cove核心总共就是10MB L2 cache。Lion Cove的cache相比上代多了一个层级,L0-D 48KB,L1-D 192KB。L1 cache应该算是新增的中间层级——从读取带宽数字来看也是如此。
L3 cache 12MB——注意这个L3不与E-core共享。换句话说这次的E-core替代的其实更像是上代的LP E-core(超低功耗E-core),可能事实也的确如此:基于前代“低功耗岛”的设计理念,Lunar Lake追求对于E-core更积极的调用,中低负载尽可能少唤醒高能耗部件——当然这其中肯定还涉及电源管理的优化。
不过上一代Meteor Lake的LP E-core受人诟病之处,也在于没有L3 cache及容量才2MB的共享L2 cache,导致相比于普通E-core明显更低的IPC;二是频率也低。所以系统对LP E-core的调用很不积极,因为其性能实在不理想,低负载应用跑在LP E-core的体验就不够好,反倒违背了LP E-core省电的设计初衷。
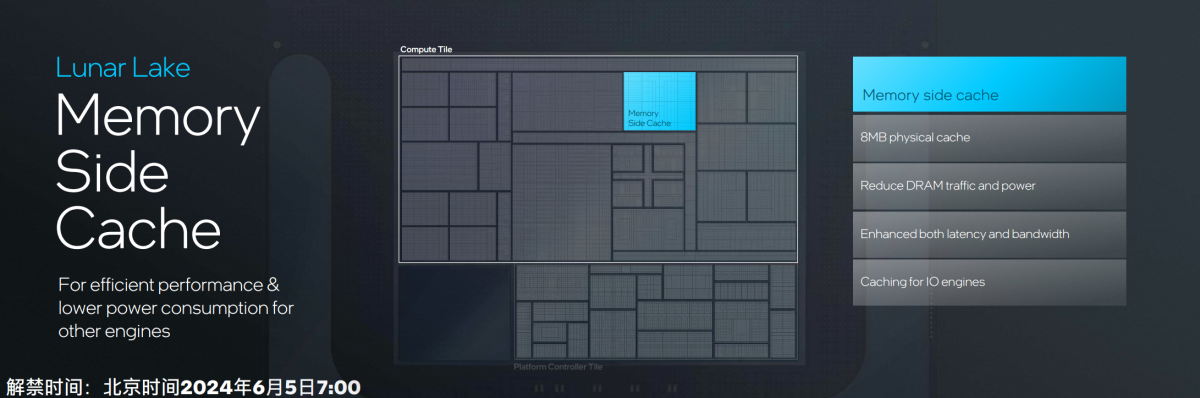
Lunar Lake在设计上,一方面是把Skymont的L2 cache增加至4MB,另一方面在Compute tile上新增了一个所谓的Memory Side Cache,大小8MB——这是个面向多个IP的全局cache,E-core、NPU、IPU、媒体引擎之类的都可以访问,角色上有些类似于Arm这边芯片设计中常见的System Level Cache。Intel也提到它有助于提升E-core的IPC。
这对酷睿Ultra处理器而言的确是个非常重要的设计,无论是提升效率,还是降低功耗。Intel说这块cache“高度可配置”,“允许在引擎之间动态分配”,“适用于各种不同的应用”。
而作为Skymont的E-core本身,应该可以称得上本次更新的最大亮点了。和Lion Cove一样,本文也不打算详谈Skymont的微架构改进。从大方向来看,Skymont也大幅加宽了微架构设计,比如解码宽50%,还借助新增的nanocode方案提升了microcode处理并行度;OoO乱序度显著加强;
比较关键的一大加强,后端的浮点和矢量运算资源大幅提升,为VNNI支持做了矢量与AI吞吐的翻番。
在整型与浮点测试中,Skymont的IPC是上代LP E-core(Crestmont)的1.38倍和1.68倍——这很大程度得益于增大的L2 cache,和新增的Memory Side Cache——当然也在于Skymont核心规模显著扩大。Intel给出的数据是,Skymont单核性能是上代LP E-core的2倍,基于核心数还多两个,多核性能就是4倍。
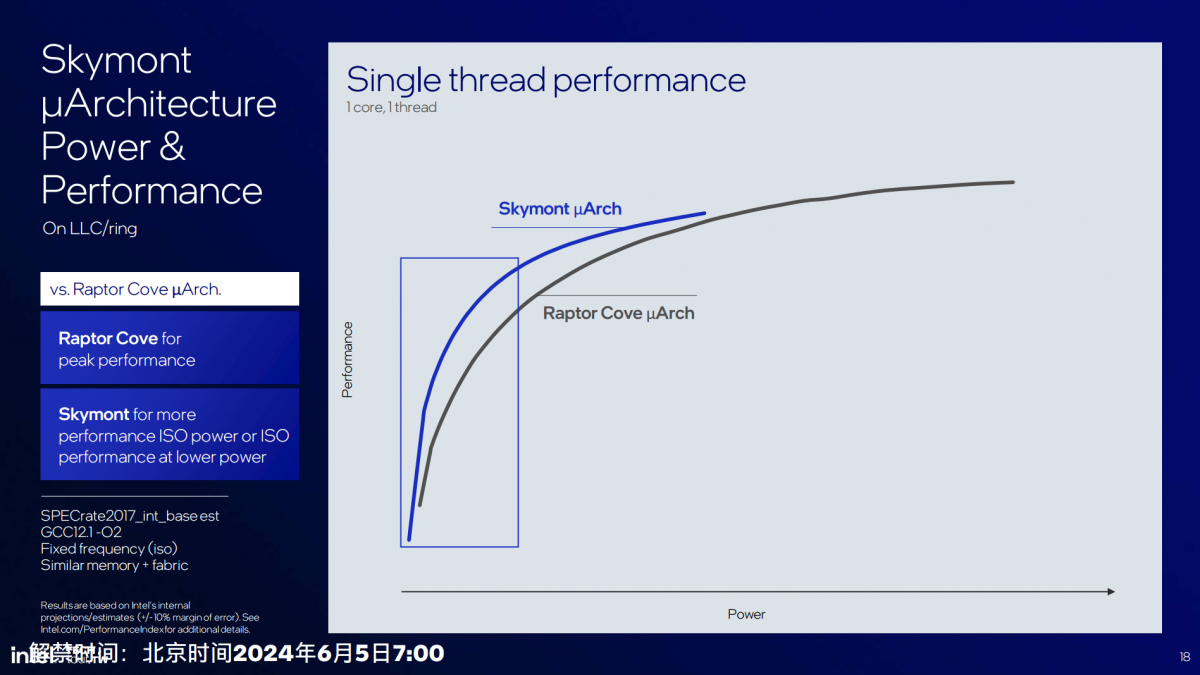
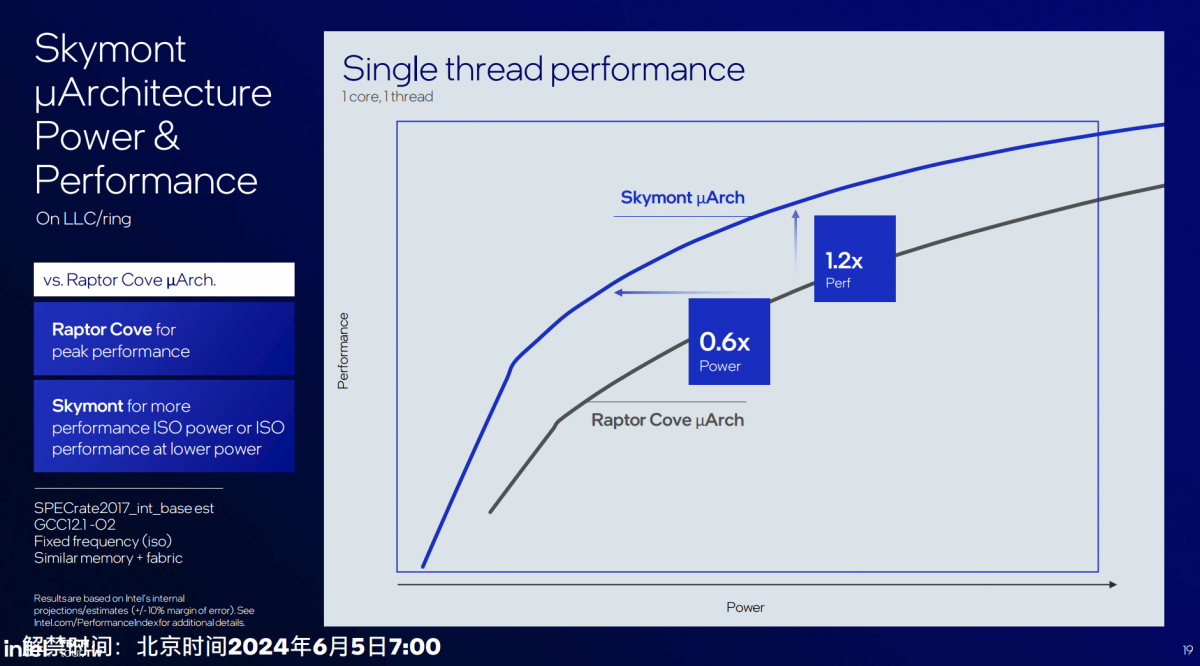
这代E-core vs 前代P-core
而且相比酷睿13代(Raptor Lake)的P-core(Raptor Cove),Skymont IPC领先2%,单线程角度看,“达到相同性能只需要Raptor Cove 60%的功耗;同功耗下,Skymont的性能是Raptor Cove的1.2倍。”从Intel的图来看,Raptor Cove大概还是因为能够达成更高的频率,在绝对性能上胜过Skymont,毕竟是P-core。
但Intel期望将更多日常工作负载放在E-core来跑的决策还是一目了然的。
CPU核心部分还有不少内容没有展开谈,比如说Lion Cove基于AI的self-tuning controller作为加强的电源管理技术,能够达成更高的持续性能;核心频率现在可以16.67MHz为步进做更细粒度的频率调节,挤出更多性能等等……
这部分的最后来唠唠Intel取消超线程设计的问题。记得Arm此前曾多番吐槽过超线程技术收益不高(毕竟Arm那边也鲜有超线程设计);前两年有关Intel要取消超线程设计的传言不少——当时有人就提过E-core的存在可用于替代P-core的超线程。
我们知道超线程是充分利用闲置单元来实现在1个核心内跑2个或更多线程的线程空间并行方案,追求的是以相对低的成本(面积与功耗)来换取更高的吞吐(性能)。一般我们说Intel的超线程技术能带来30%的性能提升——当然这也需要付出对应的晶体管和功耗。

这次Intel就提到E-core是比超线程更高效的多线程加速手段,“与其赋能超线程,不如去做E-core。”而且Intel自己的测试数据是,虽然去掉超线程以后,单位面积性能降低了15%,但能效比提升5%,perf/power/area(单位面积单位功耗性能)综合提升15%。
加上超线程对于异构核心设计的CPU而言还大幅增加了调度的难度,“从我们的数据来看,在P-core和E-core的混合系统中,非超线程是取胜的。”所以Lunar Lake就取消了超线程。不过Intel也提到数据中心追求线程密度的情况下,超线程是很好的选择。所以大概率Intel的服务器CPU还是会沿用超线程方案。(虽然Arm就是在数据中心处理器上表达对于超线程的鄙视…)
功耗下降40%,据说续航有“突破”
上个月Intel曾向媒体就Lunar Lake做过一个简短的说明会,会上提到Lunar Lake会带来非常出色的续航表现,用词是”breakthrough(突破性的)”。不过提供的对比数据不够有代表性,比的是用Teams进行线上会议,Lunar Lake比Ryzen 7 7840U功耗低30%,比骁龙8cx Gen 3功耗低20%。
我们一直都很期待Intel专门做个有关低功耗设计的主题演讲:可惜Intel没有这么干。低功耗相关的特性散落在了不同组件的技术点中。
从前述CPU核心的很多改进,比如P-core取消超线程设计,带来更好的面积和功耗效益;E-core的全面强化,对E-core更积极的利用,中低功耗负载减少唤醒P-core集群时间(Intel说这是延续了上一代低功耗岛的设计思路);新架构的IPC与每瓦性能提升;以及新增Memory Side Cache和新的NoC等技术点;乃至片内DRAM,多少应该都能带来能效红利。
后文有关GPU的部分也会谈到一些节电特性。这里还可以从SoC架构与线程调度层面再做一些相关低功耗、高能效设计的解读。

配套实现所谓“低功耗岛”设计思路的一大关键,在于Lunar Lake的供电与电源管理新方案。供电部分,共4个PMIC电源管理控制器,“尽可能为不同的组件实现丰富的电源轨(power rail)”,让P-core集群、E-core集群、图形和内存控制相关组成部分,能够“独立运行”;在实现“细粒度电压轨道拓扑结构”的同时,“实现增强的遥测,更好地分辨电的使用状态,进行好的控制。”
电源管理“引入重大变化”。包括新一代用于线程调度辅助的ITD(Intel Thread Director)在调度工作时更关注效率;优化过的power balancer针对不同负载类型“巧妙地利用每一瓦”功耗;加强“sleep”状态功耗与延迟;基于机器学习进行负载分配和频率控制,动态调整处理器速度……总体来说就是要把能耗用在刀刃上。

在多电源控制域、加强的ITD,以及memory side cache, E-core强化设计等因素的加持下,Intel宣称SoC功耗整体降低至多40%。Intel处理器以往在功耗方面表现较弱的部分就在于中低负载下仍表现出不低的功耗水平,不知道这次的强化能否弥补这部分的短板。
ITD作为低功耗实现的重点,这里也简单谈一谈。从Alder Lake(酷睿12代)引入CPU的异构核心之后,Intel每次都会花大篇幅去聊自家的线程调度器Intel Thread Director——说起来Intel做异构核心的历史,是远短于Arm、高通这类移动市场玩家的,也必然要在调度优化的问题上摸索成长。
感觉在去掉LP E-core以及P-core的超线程特性以后,Lunar Lake的任务核心间调度理应更得心应手才对。下面这张图给出了Raptor Lake(酷睿13代)、Meteor Lake与Lunar Lake三代产品,ITD逻辑上的变化:
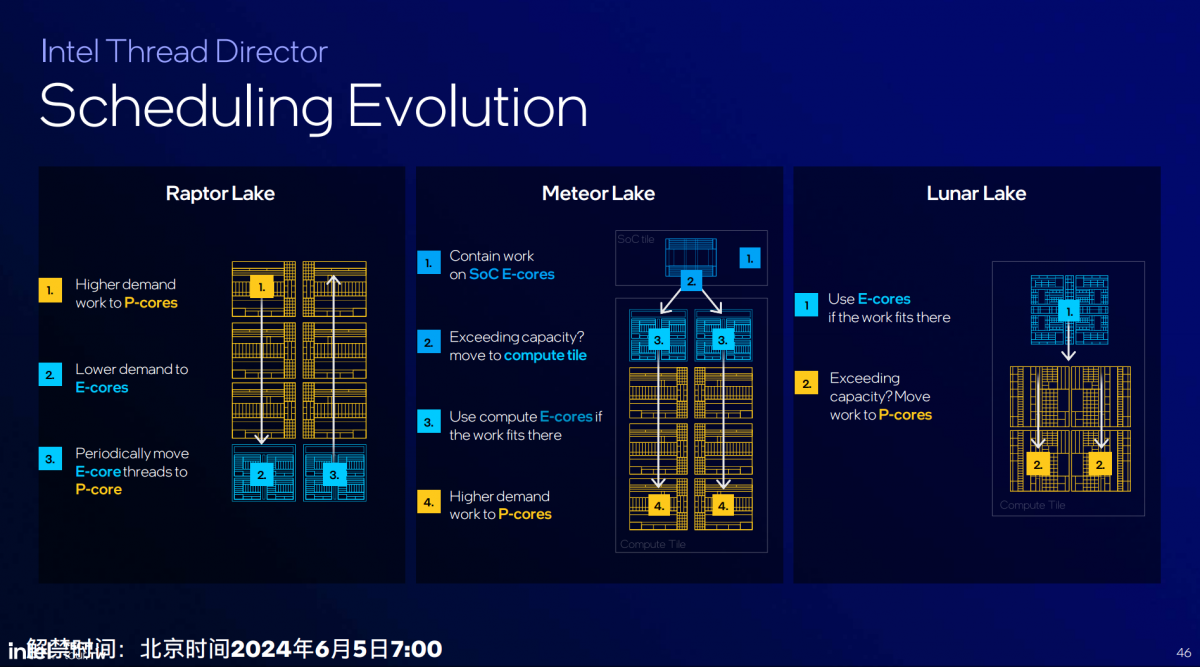
Lunar Lake的基本思路是先考虑E-core,当有更多性能需求时就迁移到P-core。Intel认为因为这一代E-core在性能上已经相当于过去的P-core,所以E-core可覆盖常见工作负载,唯有重载应用才需要往P-core迁移。
Intel总结新版ITD特性包括:第一,更智能的反馈,包括新的遥测方法、基于AI的预测、识别工作负载类型——确保体验连贯性。
第二,和微软合作的所谓containment zones:操作系统基于ITD可定义不同的zone,比如efficiency zone(效能领域)、compute zone(算力领域)、或者不做定义的zoneless。操作系统定义“领域”之后,可将工作限定在某些能效最高的核心上(比如限定Teams会议只跑在E-core)。实现最大化的资源利用。
第三,结合SoC电源管理。SoC电源管理引擎会定义包括最佳能效、平衡、性能这样的模式。“SoC电源管理引擎会基于AI机器学习判断,工作负载属于哪一种,做细分定义”,将工作负载归类为最佳能效SoC模式、平衡模式或性能模式。再“通过模式来更新负载的classification分类,后与ITD结合”,给OS scheduler提供更为优化的hint。
以Teams视频会议为例,在上述第二、第三项机制结合的情况下,Intel给出的数据是相比没有这两项机制,功耗能降低35%。 很显然Intel与竞品处理器对比Teams会议的功耗,应当很大程度借助了ITD的这一新特性。
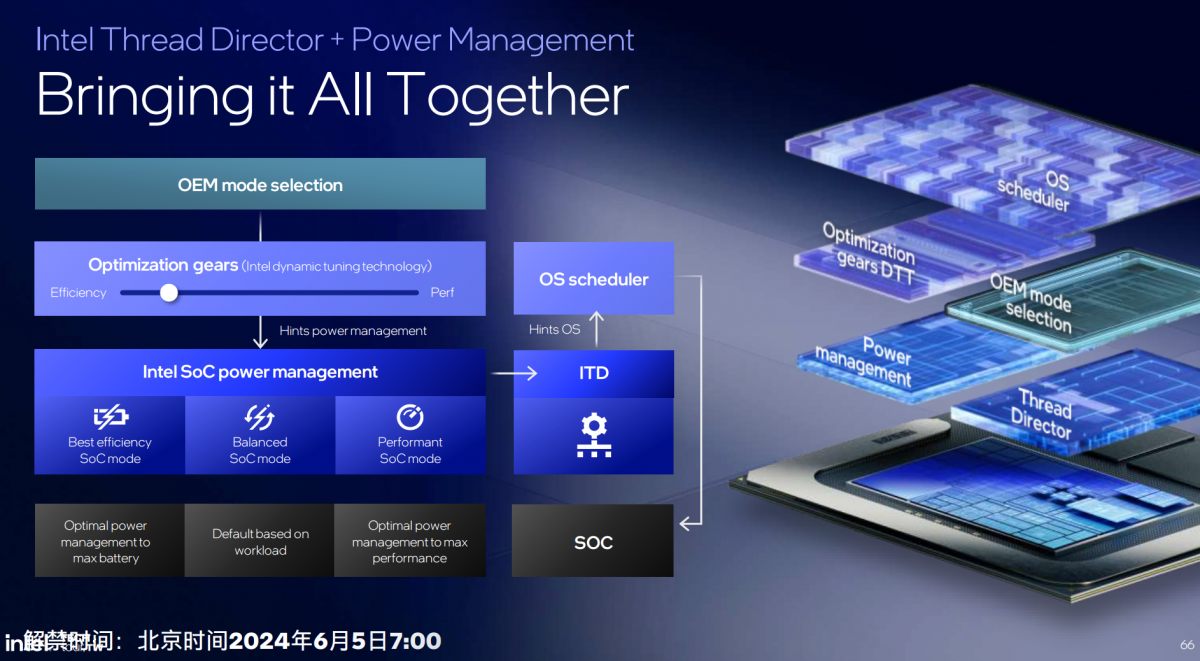
还有一项机制是面向OEM厂商的,Intel提供软件API(在上图中的optimization gears层级),让OEM可以根据各自需要去影响ITD和最终OS scheduler的调度。
上面这张图是将上述机制放在一起。芯片往上是SoC电源管理引擎,以及ITD——两者结合来给OS scheduler提供调度hint。OEM厂商则借助于optimization gears来影响SoC电源管理,最终也对scheduler构成影响,以调整负载所在核心及频率配置。
总的来说,这也是实现低功耗的组成部分。从Intel的PPT来看,ITD未来还会在场景颗粒度、机器学习技术应用和跨处理器的IP调度方面做出进步。
有关Lunar Lake实现低功耗的技术,我们暂时就只听到这么多。感觉其中最有价值的还是E-core的强化及其配套周边(如memeory side cache),辅以供电与电源管理的考量。ITD则是在此基础上的引导措施。另外还要考虑台积电的工艺红利——虽然Intel没谈,但估计这也非常重要。
核显图形性能1.5倍提升,矩阵引擎加进来
现在核显或集显也堪称是PC CPU厂商追逐的焦点:似乎越来越多的人指望用核显玩3A游戏,虽然画质不能太奢求,但能“可玩”已经不成问题。更何况核显也扮演着AI加速的角色。
上代Meteor Lake的Arc核显已经实现了游戏性能2倍的跃升,还真是摸到了低画质3A游戏能玩的门槛,也在隔壁AMD的“大核显”面前扬眉吐气了一把。
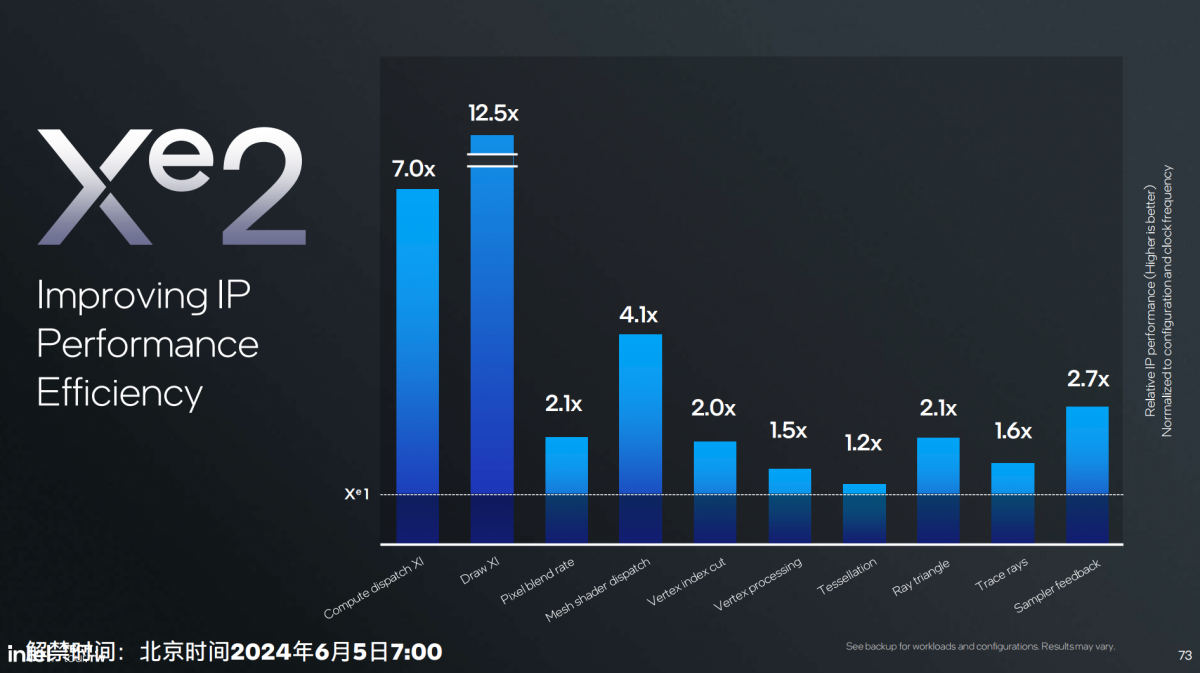
Xe2核心层面,不同图形测试对比上代核心的性能变化
Lunar Lake的核显部分换代到了所谓的Xe2架构,图形性能提升50%+,AI性能则是前代的3.5倍——理论算力67 TOPS;媒体引擎部分新增对于H.266(VCC)的解码支持;显示引擎部分支持DisplayPort & HDMI 2.1,以及新增eDP 1.5 LP port支持,3路显示管线支持。
简单谈谈这次的核显性能是如何达成提升的:
这代核显从核心数字来看仍然是8个Xe核心,但核心宽度加宽了,固定功能单元对应增配;另外终于加上了XMX矩阵单元。这种类似tensor core的单元以往只出现在Intel Arc独显,所以AI性能可得到显著提升,尤其游戏XeSS超分特性大概能更进一步——上一代核显的XeSS超分靠的是DP4a指令,效率并不高。
前文已经提到,Xe2架构将来也会用于代号Battlemage的下一代Intel Arc独显——Intel也算是完成了规模缩放的GPU架构设计目标。下面这张图就是这代新架构下1个Xe核心的构成简图:XVE是矢量引擎,XMX是更专注MAC运算的矩阵扩展引擎。
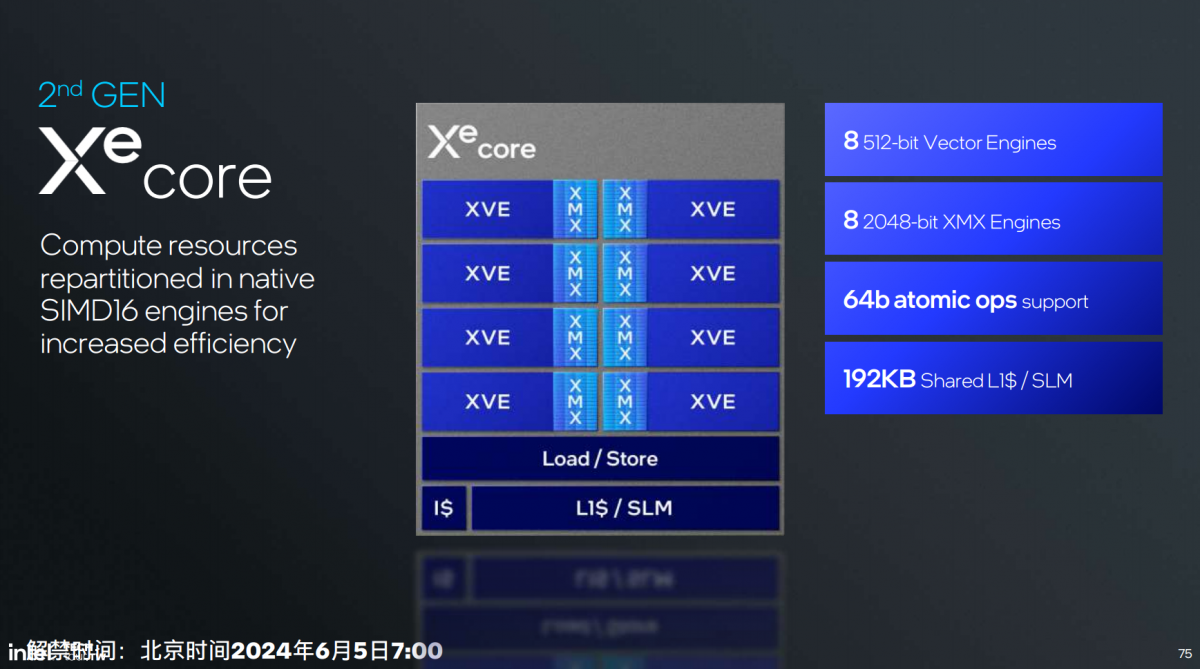
每个Xe核心8个矢量引擎——单论所谓的EU个数比前代减了一半;但每个矢量引擎搭配一个XMX矩阵扩展,数据宽度如图——这个位宽似乎也比早前的Xe HPG翻倍;L1 cache 192KB。相比前代的一大变化是整数与浮点的SIMD16原生支持ALU,前代是SIMD8宽度, “更适配现在一些游戏和AI应用。”
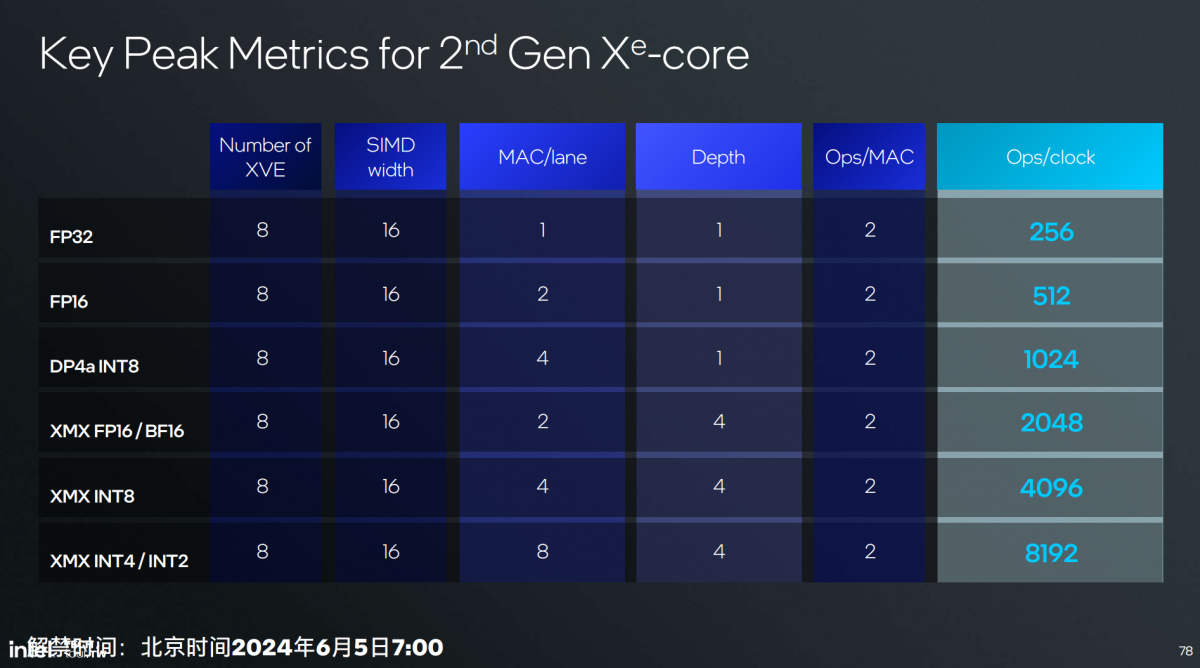
XMX引擎支持包含Int2/4/8, FP16, BF16在内的格式精度,“适配更多AI模型”;扩展数学运算和FP64支持;3-way co-issue同时处理浮点、矩阵和整数计算。
Intel强调XMX引擎Int8 4096 OPS/clock和FP16 2048 OPS/clock算力水平远高于矢量引擎,还是在于对AI性能的追求,是这次Intel一再提到整颗处理器总共120 TOPS AI算力的关键构成之一。
这也引出一个很有趣的话题:Intel好像真的没有打算在酷睿Ultra处理器的XPU策略上,把生成式AI算力担当完全交给更专用的NPU。虽然今年NPU的算力水平大幅提升,肩负责任也变重,但依旧无法和在绝对性能上加了XMX的核显相较。就这一点来看,Intel的思路跟部分竞争对手还真的不大一样。
言归正传:每4个上述这样的Xe核心构成一片render slice(所谓的渲染切片)。在render slice层面当然还有一些别的配套功能单元和新增特性,如下图。
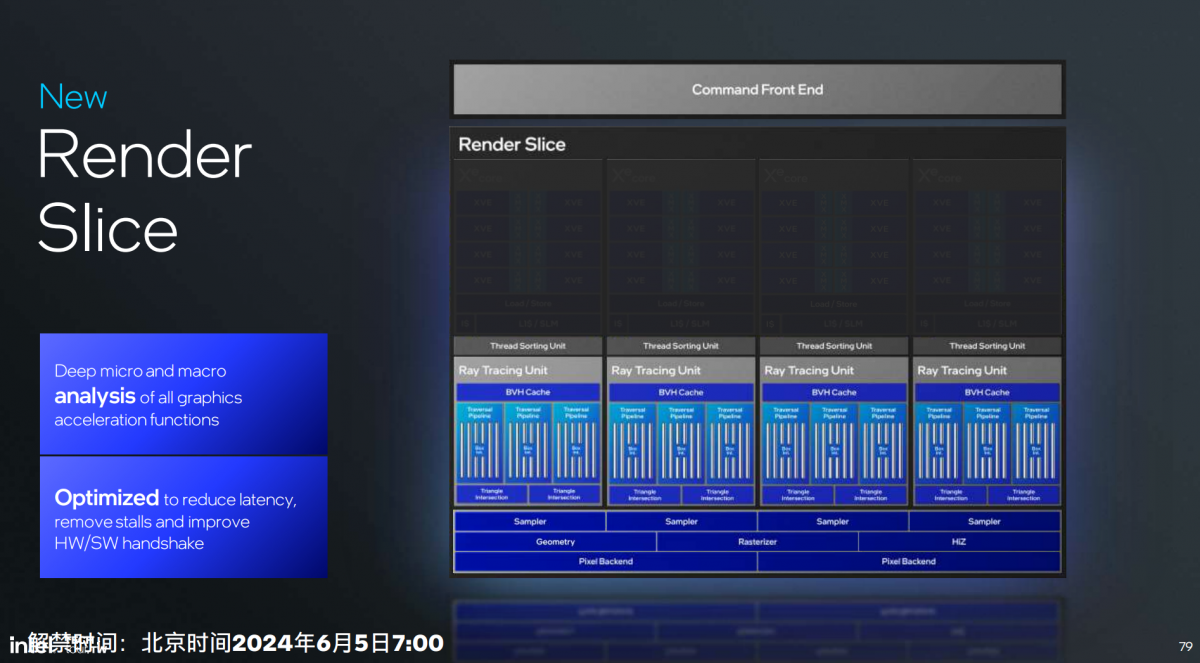
比如说Execute Indirect硬件支持——某些原本需要CPU发号施令的工作,可以由GPU独立完成;几何单元改进达成顶点获取(vertex fetch)吞吐提升3倍,mesh shading性能提升3倍;
cache部分,纹理压缩率更高提升L1 cache利用率,sampling吞吐2倍提升;HiZ cache增大;pixel后端的blending吞吐2倍提升,pixel color cache 1.33倍提升,render target预取到L2…;还有L2 cache内达成8:N压缩比,支持快速的fast clear特性…
另外上面这张图最显眼的单元应该就是RTU光线追踪单元了。新架构的RTU也做了拓宽,3条Traversal遍历通道——18 x Box intersections,2 x Triangle intersections。光追加速的吞吐量就增大了。不过这部分应该主要是给将来的独显准备的。
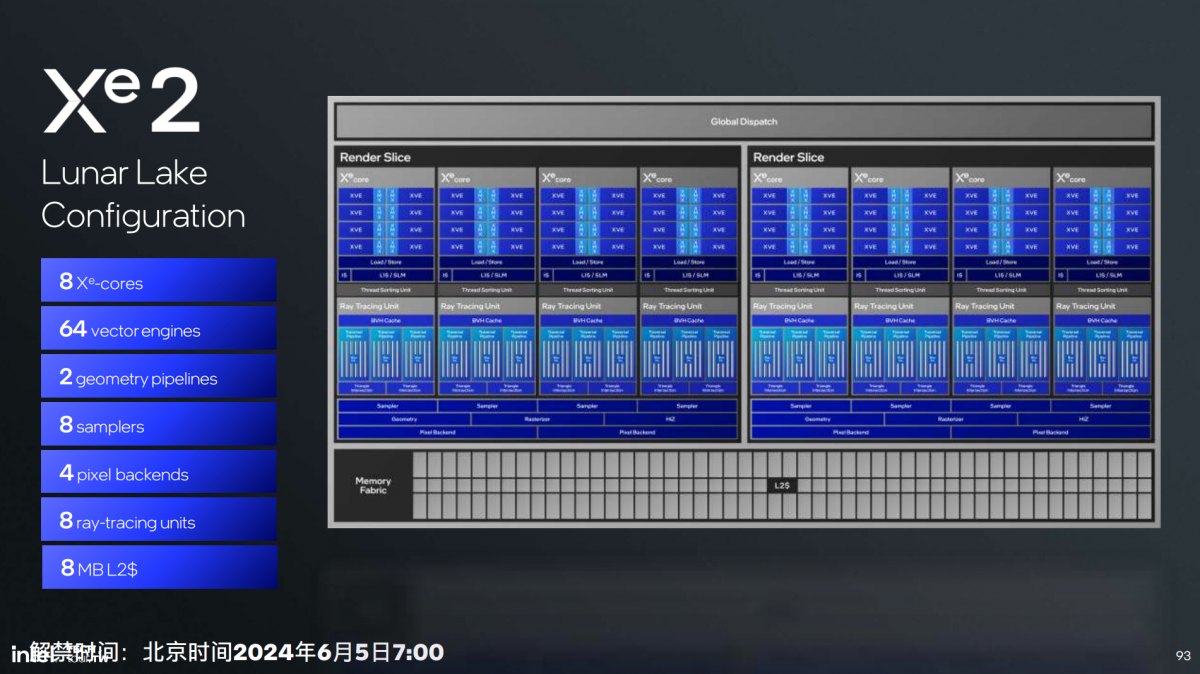
再到Lunar Lake的核显完全体:2片render slice,总共8个Xe核心,64个矢量引擎,8MB L2 cache。光看资源模块个数意义不大,Intel给了比较具体的核显性能比较:
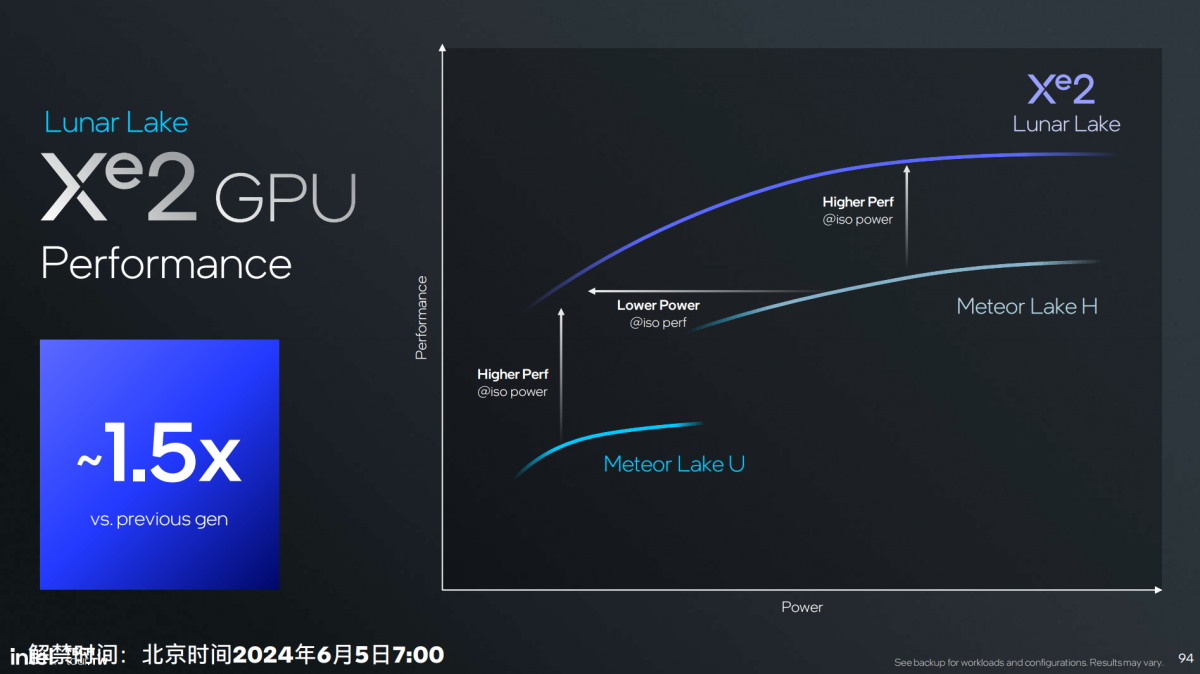
Lunar Lake核显全功耗段图形性能全面超过上代Meteor Lake核显,综合提升1.5倍(现在大家都跟苹果学坏了,画个图比例尺也不标)。但Intel在讲解中提到,Meteor Lake在22-25W左右达成满载的性能,Lunar Lake在<15W的功耗下就能达到,能效提升也相当不错——轻薄本畅玩《星穹铁道》不是梦啊…
AI性能部分,67 TOPS的数字已经提过。Intel给了个更直观的demo,跑Stable Diffusion,Meteor Lake耗时13秒多,Lunar Lake耗时6.3秒。Intel在资料中还提过,Lunar Lake跑Stable Diffusion 1.5的性能比高通骁龙X Elite强1.4倍。不过这个对比考验的可能还是XPU综合性能,只不过核显的确还是跑Stable Diffusion最高负载部分(Unet)的中坚力量。
有关核显部分的显示和媒体引擎,本文不做赘述。其实在酷睿Ultra处理器做多die设计开始,媒体引擎和显示引擎与iGPU图形单元的摆放位置就渐行渐远了。当然Lunar Lake的显示和媒体引擎也位于Compute tile之上。我们习惯上还是把这两部分与核显放在一起讲。
这次Intel的媒体会是详细到把显示引擎和媒体引擎的内部结构都谈了一遍,也算难得。将来有机会我们可以特别就这类硬件单元撰文。
有一些技术点还是可以讲的,比如说显示引擎的其中一个像素处理管线有高级电源管理设计,属于低功耗设计构成;还有eDP 1.5也新增了节能特性(early transport),能够在网页浏览、显示闲置、全屏看流播视频等场景显著降低功耗。而媒体引擎的宣传点是对VCC H.266的解码支持,VCC的特性此处不再多谈…
设计理念的战未来
最后简单提两句NPU:如文首所述,有关AI的部分我们将单独撰文,所以本文针对NPU不做详解。Lunar Lake的这一代NPU被Intel冠名NPU 4,应该是还叫Movidius VPU的时候就以外置的方式存在过两代,所以Meteor Lake上的NPU叫NPU 3。
NPU 4的改进三个方面:增加执行引擎数量、提升频率、提升架构。48 TOPS的理论AI算力,相较NPU 3提升了4倍多。从堆料规模的显著扩张就能感知到其中变化:
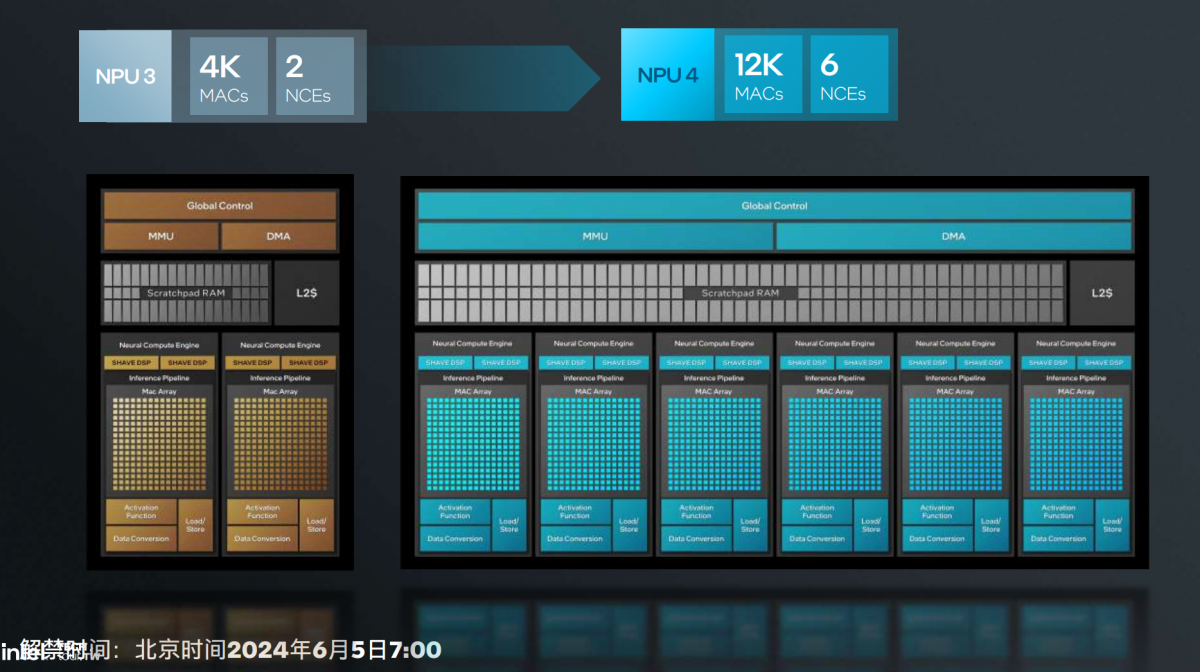
在工艺与架构的双重改进下,效率也多有提升,同功耗下NPU 4相比NPU 3最多可达成2倍性能提升。同样跑Stable Diffusion 1.5迭代20次的情况下,Lunar Lake比Meteor Lake快了3.6倍,但功耗只提升24%。更多NPU相关内容且等后续文章吧。
本文的最后谈谈有关Lunar Lake的架构“设计理念”问题——这是Intel介绍Lunar Lake时反复提到的词。整颗芯片架构的基本思路是“Lunar Lake的SoC架构做到了IP、分区(partitioning,应该是指tile)无关性(agnostic)”,“同时致力于提供所有组件的一致性,并实施分层一致性结构。”
这一点对Lunar Lake产品宣传似乎没什么价值,但对Intel的芯片产品布局及未来产品迭代应该会很有价值。

比如针对IP之间的无关性,引入Fabric Gen 2,“将物理层和协议层分开”,“在统一的物理层上传输不同的功能协议”。
而分区的无关,是指在不同的tile和工艺节点之间也可以“无缝”迁移IP。上图中两片die之间借助D2D互联,“它用于承载相同结构的物理协议,并充当结构的组成部分;使得两个tile可连接为统一的系统”,“使得Lunar Lake实现了分区的不可知性。”
另外Lunra Lake也实现了分层的一致性(hierarchical coherency):提供整体一致性的Home Agent(memory side cache?),不同核心集群的一致性Agent,实现对多计算集群的原生支持等。“这种结构我们会带到下一代SoC中去。”
总体上这个思路叫“extended scalability”:扩展的可伸缩性。这种设计方法之所以重要,在于芯片高度集成趋势下仍然要保有灵活性和前瞻性。“使得每一个细分市场都能选择正确的芯片”,并且“在成本和性能间取得权衡”。
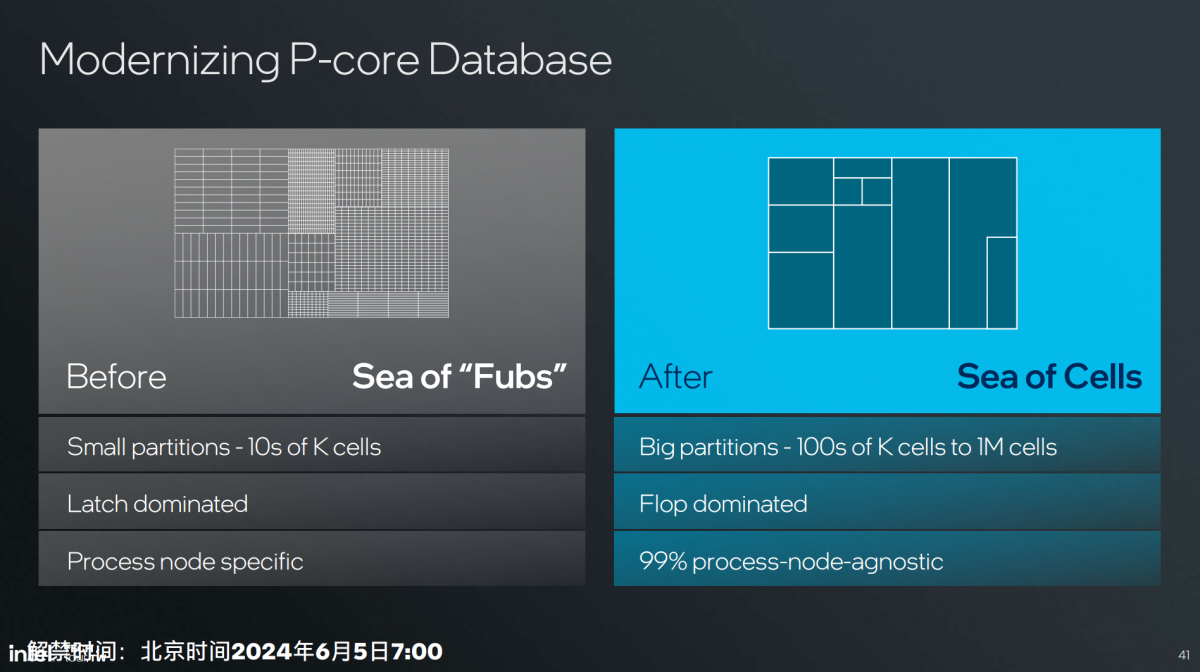
在我们看来,这一思路更多的也延续到了Lion Cove和Skymont核心的设计上的。Intel在谈Lion Cove的特点时特别提到“现代化设计数据库(database)”,是“芯片设计的重大变革”,而且会“深远地影响到未来的迭代”。
“替换全新芯片设计工具、流程和方法。”“过去我们把partition切分得很零散,每个small partition里面可能包含几万个cell。”“现在专项大规模partition,每个大模块里包含数十万、百万cell,使得设计中的物理边界减少——每条线就是一个物理边界。”
“转化为这种大模块设计的工具和理念以后,物理边界减少带来利用率和硅片面积效率的提升。做集成整合时开销也减少了,也让迭代变得更容易。”
“大家会发现不久的将来,同样的Lion Cove,在Lunar Lake和Arrow Lake上其实是不太一样的。如此也就适配了不同的领域。Lunar Lake主打低功耗、高能效;Arrow Lake则覆盖更多定位。”这是一种战未来的典型思路。

这篇文章又过分长了。最后简单总结一下:刚刚才做了封装层面大更新的Meteor Lake,转头一年没到,Lunar Lake又在CPU和GPU架构上做了大改,实在是能体现出PC处理器市场疯狂卷的现状。
在我们看来,Lunar Lake的CPU、GPU,以及SoC设计上的更动都可以大踏步来形容,尤其CPU E-core的设计革新堪称惊艳;而SoC整体的功耗设计预计还会给明年的Windows笔记本带来真正的长续航。
不过竞争对手的步子也很紧,比如Lunar Lake的CPU多线程性能可能会在现如今的PC市场上非常被动。现在的PC处理器市场颇有一种你方唱罢我登场的热闹气氛。
我们仍然非常期待看到,即将问世的Lunar Lake现如今在有着M4, 骁龙X Elite这样高手林立的市场上会给出怎样的成绩单。
后续我们将进一步更新有关Lunar Lake NPU及CPU详解的文章。尤其NPU部分,Intel的技术分享细致到了谈Transformer结构模型怎么跑在NPU上,哪个部分在哪个位置跑,不同数据格式如何分配等等,还是挺有看点的…
