
OpenAI 早期投资人 Vinod Khosla 去年曾在 X 发文称,“美国的开源模型都会被中国抄袭。”然而近日大模型“套壳”的回旋镖,打到了美国的身上——硅谷科技圈发生了一起引人注目的抄袭事件,简直啪啪打脸。
据称,斯坦福大学的AI研究团队被指控抄袭了中国清华系明星创业公司面壁智能开发的开源模型“小钢炮”MiniCPM-Llama3-V 2.5。这一事件在网上引起了广泛的热议和关注。
事件起因与争议点
5月29日,几位毕业于斯坦福大学的研究人员团队发布了一个名为Llama3-V的开源模型(EETC编按:严格意义上来说他们不能算斯坦福的团队,所以我们称其为“Llama3-V团队”),宣称仅需500美元就能训练出一个性能超越GPT-4V、Gemini Ultra、Claude Opus等的SOTA多模态大模型。
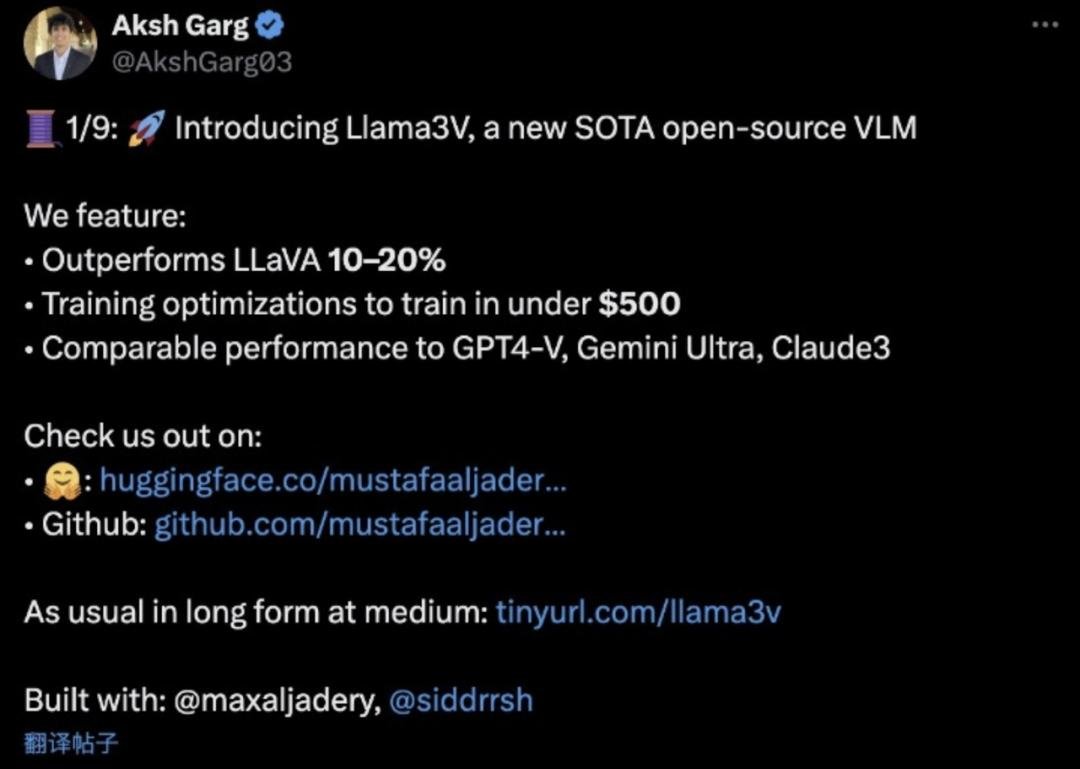
然而不久后,有网友发现Llama3-V的模型结构和代码与面壁智能不久前发布的MiniCPM-Llama3-V 2.5惊人相似,仅修改了部分变量名。
面壁智能的MiniCPM-Llama3-V 2.5项目具有独特的功能,如识别“清华简”——一种罕见的中国战国时期(公元前 475 年至公元前 221 年)古文字。而Llama3-V不仅也能识别出“清华简”,而且连错误的识别结果都与 MiniCPM 模型完全一致。

要知道,这些古文字数据是面壁智能团队花费数月时间从清华简上逐字扫描并人工标注的,且从未公开过。在未公开的实验性特征上与MiniCPM-Llama3-V 2.5表现出高度相似的行为,这些特征是Llama3-V团队模型抄袭的铁证。
包括X 用户 @yangzhizheng1 在内的网友提出的其他抄袭证据包括:

- Llama3-V的模型架构和代码与MiniCPM-Llama3-V 2.5几乎完全相同,仅有一些变量名和格式化的差异。
- Llama3-V使用了MiniCPM-Llama3-V 2.5的分词器(tokenizer),并且连同MiniCPM-Llama3-V 2.5定义的特殊符号也出现在了Llama3-V中。
- 将从HuggingFace下载的Llama3-V模型权重中的变量名改成MiniCPM-Llama3-V 2.5的,模型可以用MiniCPM-V代码成功运行。
- 如果往 MiniCPM-Llama3-V 2.5 的 checkpoint 添加高斯噪声(由单个标量参数化),出来的模型跟 Llama3-V 就像是一个模子刻出来的。
删库、道歉、甩锅
面对抄袭的质疑,llama3-V 项目的作者首先上演了一出“删库跑路”的好戏。GitHub和Hugging Face上的相关项目均显示404,无法访问;X上的官宣模型已删除。
Llama3-V团队最初辩称,他们的工作早于面壁智能的MiniCPM-Llama3-V 2.5,只是使用了他们的tokenizer。然而他们的解释再次遭到了质疑,因为一款模型及其详细的 tokenizer 往往是在其发布后才能被外人知晓,那么斯坦福这支 AI 团队如何能在 MiniCPM-Llama3-V 2.5 发布之前就获取到这些信息?
随后他们在Medium上的道歉声明被删除,且最新的回应也被撤回。
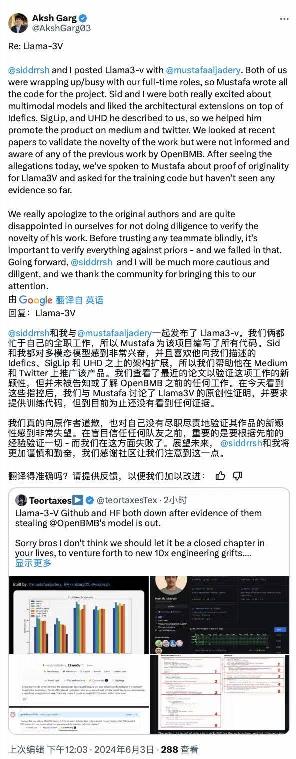
Llama3-V 团队最初发表的回应,目前已经撤回不可见
在舆论压力下,北京时间6月4日凌晨 1 点 27 分,Llama3-V 团队再次发文回应。两位作者森德哈斯·沙玛(Siddharth Sharma) 和阿克沙·加格(Aksh Garg) 在社交平台 X 上就这一学术不端行为,向面壁 MiniCPM 团队进行了正式道歉,并承诺将撤下所有 Llama3-V 模型。

有网友也扒出了抄袭作者的背景,虽然是妥妥的名校生,但也是抄袭惯犯,之前写的教材也是一整个大抄特抄。
公开信息显示,Siddharth Sharma 与 Aksh Garg 均是斯坦福大学计算机系的本科生,曾发表过机器学习领域的相关论文。
其中,Siddharth Sharma 曾在亚马逊实习过一段时间,目前主要从事于 AI 和数据相关工作。
而 Aksh Garg 的实习履历,那叫一个丰富,涵盖 SpaceX、斯坦福大学和加州理工学校等知名企业机构。
至于被这上述两位作者称为“代码搬运工”的穆斯塔法·阿尔贾德里(Mustafa Aljadery),是南加州大学出身,在舆论发酵之后,目前 X 账号已经被设为隐私状态。

Llama3-V作者:Siddharth Sharma(左)、Aksh Garg(中)、Mustafa Aljadery(右)
这样看来,Llama3-V团队并不能算严格意义上的斯坦福团队,不过因为此事声誉受损的斯坦福大学至今没有采取任何公开措施。
网友不买账,斯坦福谴责,面壁智能表立场
对于 Llama3-V 团队的道歉声明,网友却不买账。例如,X 用户 @xprunie 指出,这哥俩将责任归咎给一个人的甩锅行为,莫不是“有福同享,有难你当?如果是老穆一个人写了所有代码,那你俩是干啥的,就发发帖吗?”
斯坦福 AI 实验室主任 Christopher David Manning 也站出来谴责这一抄袭行为,并且对 MiniCPM 这一优异的中国开源模型表示赞扬。
针对此事,知乎CTO、面壁智能CEO李大海对此事件做出了正式回应:“已经比较确信Llama3-V是对我们MiniCPM-Llama3-V 2.5套壳。”
他表示,“技术创新不易,每一项工作都是团队夜以继日的奋斗结果,也是以有限算力对全世界技术进步与创新发展作出的真诚奉献。我们希望团队的好工作被更多人关注与认可,但不是以这种方式。我们对这件事深表遗憾!一方面感概这也是一种受到国际团队认可的方式,另一方面也呼吁大家共建开放、合作、有信任的小区环境。一起加油合作,让世界因AGI的到来变得更好!”

面壁智能首席科学家刘知远也在知乎上发文表示,表示这次事件从另一个角度证明了中国创新成果的国际影响力,强调了开源共享的重要性,以及对原创精神的尊重。
开源社区,是时候重视中国大模型了
此事件在开源社区引起了广泛的讨论,有网友挑起了一个关键话题——开源社区是否忽视了来自中国的大模型成果?
前段时间,斯坦福大学人工智能研究院(Stanford HAI)发布了一份报告,表示美国在大模型领域遥遥领先。报告指出,2023 年 61 个著名的人工智能模型来自美国的机构,远远超过欧盟的 21 个和中国的 15 个。
数量多就是“遥遥领先”?非也。
谷歌DeepMind研究员、ViT作者Lucas Beyer在评论Llama3-V抄袭时提到,成本低于500美元,效果却能直追Gemini、GPT-4的开源模型确实存在,但相比于Llama3-V,MiniCPM得到的关注要少得多,“包括我自己也有所忽略。主要原因似乎是这样的模型出自中国实验室,而非常春藤盟校。”

Hugging Face平台和社区负责人Omar Sanseviero说的更加直接:“社区一直在忽视中国机器学习生态系统的工作。他们正在用有趣的大语言模型、视觉大模型、音频和扩散模型做一些令人惊奇的事情。包括Qwen、Yi、DeepSeek、Yuan、WizardLM、ChatGLM、CogVLM、Baichuan、InternLM、OpenBMB、Skywork、ChatTTS、Ernie、HunyunDiT等等。”
这次Llama3-V团队的模型抄袭事件说明,一直被认为在“追赶美国”的国产大模型,现在却成了被抄袭的对象。从更客观的大模型竞技场的角度看,此言不虚。
在模型一对一PK的视觉大模型竞技场中,来自零一万物的Yi-VL-Plus排名第五,超过了谷歌的Gemini Pro Vision。智谱AI和清华合作的CogVLM也跻身前十。DeepSeek、通义千问和这次遭到抄袭的MiniCPM系列多模态模型,也都有不错的表现。在更受到广泛认可的LMSYS Chatbot Arena Leaderboard竞技场榜单中,来自中国的大模型也同样在不断刷新“最强开源”的新纪录。
