
近期,GPT-40的发布再次引爆生成式AI话题——自ChatGPT出现至今,生成式AI堪称月月有爆点,这也让AI芯片热度持续不减。其中有一类与众不同的芯片,这两年正以其独特的架构吸引着产业界的关注。
存算一体,相比传统冯诺依曼架构,不仅避开“存储墙”限制;而且借着AI发展的东风,显得格外有潜力。亿铸科技作为市场上为数不多基于存算一体技术的AI大算力芯片企业,正计划从芯片到板卡、服务器,最终将算力横向扩展至大规模运算集群,并最终借助存算一体技术在生成式AI时代站稳脚跟。


对此,我们采访了亿铸科技创始人、董事长兼CEO熊大鹏博士,解读AI浪潮下大算力AI芯片的新形态——基于ReRAM的全数字存算一体芯片。
大算力存算一体芯片何时商用?
传统冯诺依曼架构芯片的“存储墙”问题日益严重。在需要海量数据搬运的场景内,传统芯片不仅面临计算单元闲置导致系统效率降低的问题;还面临存储、通信和数据搬运的功耗开销都远高于计算的“能耗墙”问题。除此之外,亿铸科技此前在中国临港国际半导体大会上,还提到“编译墙”问题——即动态数据流调度复杂,编译器无法在静态、可预测情况下自动优化可执行程序,依赖手动调优等情况。以上三点都极大限制了资源日益紧缺、功耗大幅增长的AI产业的发展。
对此,熊大鹏博士在主题演讲中曾提到“阿姆达尔定律(Amdahl Law)”,谈到存算一体相比传统GPGPU在做加速时的优势在于数据搬运量大幅下降,令访存限制趋近于0,实现有效算力密度的增长;其数据访问模式可预测,数据流和控制流简单,易于算子和可执行层代码自动优化。
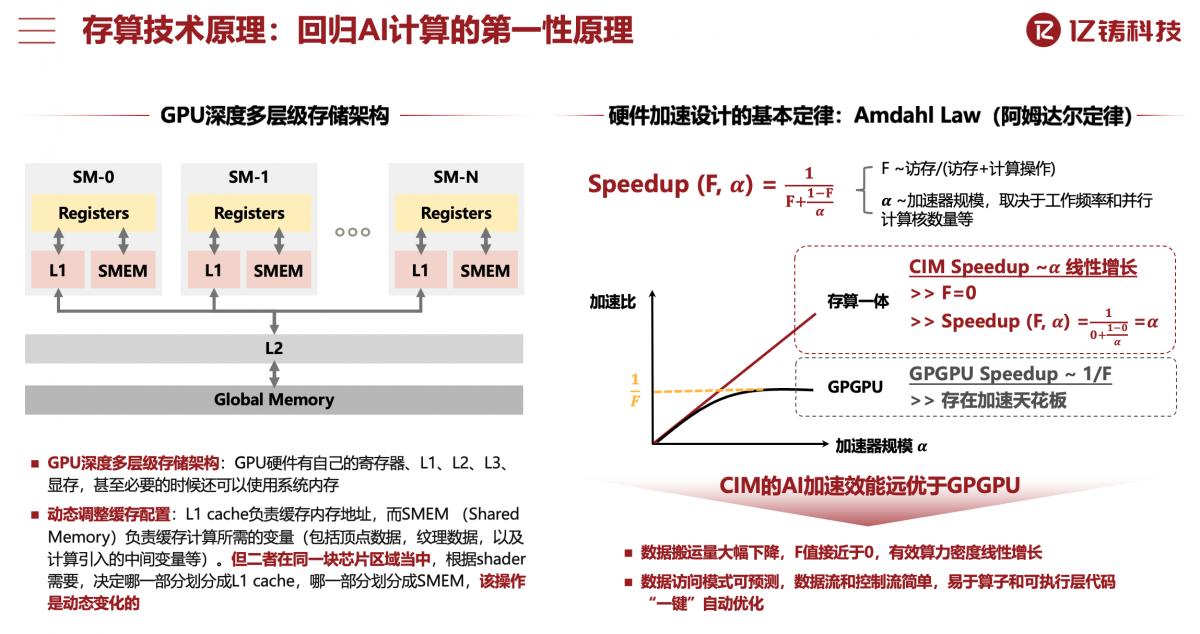
基于以上优势,在性能和效率方面,存算一体芯片能够以成熟制造工艺比肩基于先进制造工艺的冯诺依曼架构传统芯片,并实现更低成本。“存算一体芯片的算力密度更高,拥有更好的能效比,”熊大鹏博士在接受采访时表示,“用更少的晶体管达成相同的算力”“而且存算一体可以减少数据搬运量和距离,这也是实现更高能效比的主要原因”。
即便存算一体芯片的优势已经被越来越多的人所知,但这类芯片到现在尚未全面占领大众视野。熊大鹏博士认为存算一体芯片是新技术,“不管是架构设计、软件生态,都还面临着相当程度的挑战”。熊大鹏博士透露,亿铸在和昕原半导体合作,“目前市场公认能够实现ReRAM这类新型存储量产的,只有昕原和台积电,这两家的制造工艺也都比较成熟。”
“但在AI大算力、大模型等应用方面,存算一体技术落地,从架构设计等各方面细节来看,还是存在不少挑战。”“大算力存算一体芯片毕竟也是最近两三年才出现的,新技术推向市场也需要时间磨合。” 熊大鹏博士强调,“2025-2026年,大算力存算一体芯片应该会逐步在商用市场推广开来。”
全数字化存算一体如何解决技术挑战?
在此前的主题演讲中,熊大鹏博士曾提到存算一体的“三把刀”,或者说三大类方案,分别是模拟、数模混合与全数字化的方案。
在一般模拟的存算一体系统中,数据以模拟信号的方式存储,以存储单元内不同的电压电平来表示,基于欧姆定律和基尔霍夫定律(Kirchhoff’s Laws)执行MAC等运算。这种方案的最大问题在于精度,模拟电路噪声和各种变量是其中原因。“不管是制造工艺还是工作环境,都会让忆阻器代表的完整数有误差或漂移”。数模混合方法尝试平衡效率和精度问题,但依旧不能保证高精度。
所以亿铸的方案是基于ReRAM的全数字化存算一体。因为是全数字化,数据以二进制的方式放进存储单元内,“一个忆阻器(ReRAM)只表示一位,也就只有高低电平、高低电阻、高低电流的区别,这种情况下就能做到可靠”。
熊大鹏博士在谈到存算一体芯片的算力大规模扩展时,提出当前面临的三大挑战。其一是精度不可信的问题;其二,基于模拟计算,数模模数转换带来了能耗、die size和性能的瓶颈;其三,AI大模型对容量有要求。全数字化路径能够很好地解决这些问题,这也是亿铸科技做AI大算力推理芯片的依据。
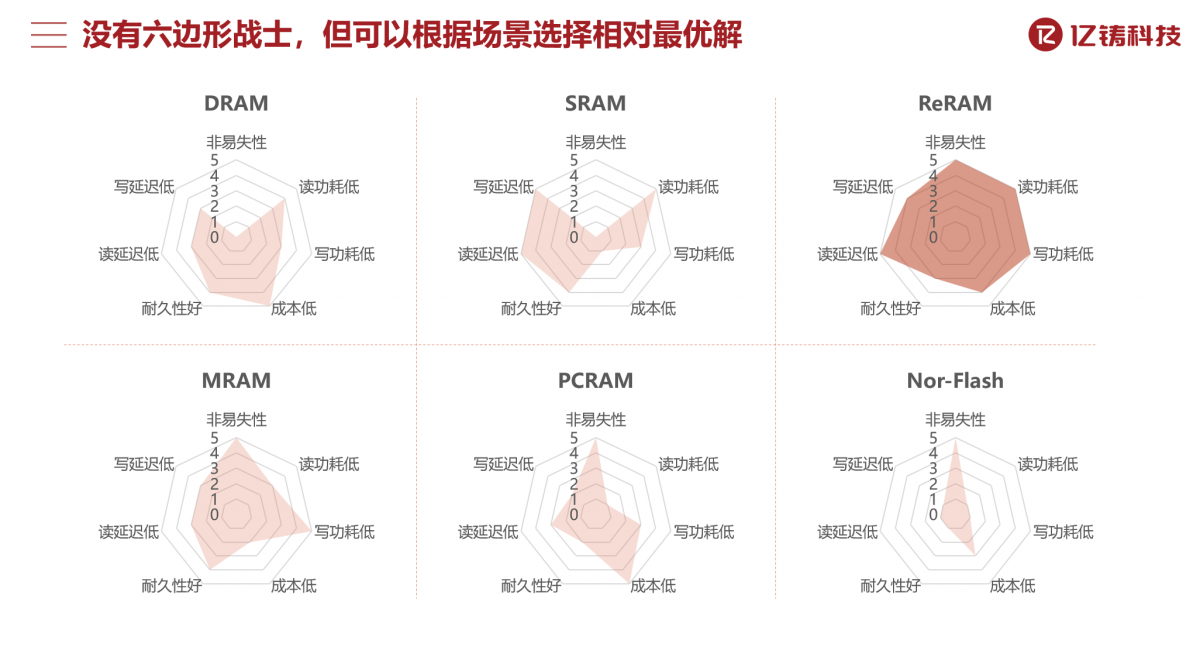
而存储介质选择ReRAM(Resistive Random Access Memory),“是性能、能效比、容量密度、工艺成熟度等方面的综合考虑。”“ReRAM技术本身也在不断提升。”另外ReRAM是CMOS兼容的,能够基于标准CMOS工艺制造,享受CMOS的很多先进技术,实现密度持续提升及未来更高的算力与能效比。

在解决技术问题以后,去年亿铸科技点亮了基于ReRAM的高精度、低功耗存算一体AI大算力PoC芯片。“无论是能效比还是算力,都超出了我们的预期。”熊大鹏博士谈到,“我们也运行了一些典型的demo,比如以图搜图,比如(基于)LoRA跑比较小规模的Transformer网络,结果都远超竞争对手。至于量产芯片,目前处于设计冲刺阶段。”
亿铸的芯片会是什么样?
采访中我们还是获悉了有关亿铸这颗要问世的AI大算力芯片的少量细节:性能方面,亿铸的芯片 “有效性能、能效比都会有优势”,即便是相较竞争对手 “最新的解决方案”,“也不会输”,虽然“不敢说打开垄断局面,但至少也能撕开一条缝,给用户新的选择”。
另外对于存算一体芯片的“通用性和可编程性”,鉴于“采用异构结构,存算一体本身只做大规模矩阵计算,通用性和可编程性要依靠通用处理器,包括SIMT(single instruction multiple threads)。”熊大鹏解释道,“我们定义了一套完整的ISA。”CPU指令集主体为RISC-V,“SIMT、存算一体,和其他组成部分,将不同架构、不同体系计算单元融合在一起,最终“将通用计算与存算一体有效融合”。
“另外以前的AI芯片主要基于CNN(卷积神经网络),造成了很大的通用性局限,对现在主流Transformer的支持不是特别友好。”“亿铸的芯片兼顾CNN和Transformer。”与此同时,“不少科学家工程师也在探讨Transformer替代方案。我们也会关注未来AI模型、算法会往哪个方向演进。”“不管是Transformer 2, Transformer 3,还是多模态、MoE,各种流派都在往前走。”

以上是芯片层面的信息。对于要实现算力扩展的AI芯片而言,芯片、板卡系统与节点间的高速互联是当代系统层面AI性能发挥的瓶颈。所以熊大鹏博士特别提到,“芯片互联、板间互联、节点互联是非常关键的技术,我们也花了不少精力去做。”
个中细节熊大鹏博士并未透露,不过他提到不同层级的互联会采用开放标准,“比如RDMA”。他还强调了DPU的重要性,对于大模型而言,“DPU扮演的角色越来越清晰,作用也越来越重要”,“我们会跟合作伙伴一起去开发针对大模型的DPU”。 系统层面,“我们会和合作伙伴一起,做到服务器级别”,将来算力扩展至整个大规模计算集群。
如何构建存算一体软件及应用生态
对于加速器类型的芯片而言,软件开发生态是另一大难点。“从用户的角度来看,亿铸的芯片就相当于一颗GPGPU,只不过是基于存算一体的GPGPU。”存算一体架构对开发者是不可见的。“很多企业、前人基于GPGPU做了各种各样的开源开发工具和生态构建,我们都用得上。”
“现在我们打算集中力量,在AI大模型应用场景上发展。比如说Llama 2-70B等等,容量大的、小的模型,我们都会去支持。”熊大鹏博士谈到,“存算一体自身的特点,决定了对算子的优化相对简单,更容易支持典型的AI大模型。所以在支持典型AI大模型的基础上,泛化到其他AI模型。”
从AI大模型角度切入,实则涵盖了终端应用领域的方方面面,包括数据中心、金融、游戏、安防、教育、工业、机器人、交通等等。
“建立软件团队要一步步来。先是围绕芯片建立团队,这一步基本已经达到了目标。后续还要针对用户使用、部署、各类工具等等完善软件团队。”“生态构建是需要打磨的,也关乎用户接受度方方面面的问题,这些都需要时间。”

亿铸科技在宣传中提到,团队具备数字化存算一体全栈研发经验及垂直整合能力——研发团队申请的专利已经超过40项,国际最早先进工艺非冯体系架构设计和芯片流片;具备主流架构SoC量产交付能力——团队此前的SoC设计、量产及销售的芯片已经有20+颗;
更重要的是在软件和编译器方面,也有200+和350+案例的团队系统软件研发交付经验;加上还具备“国内外一线公司算法积累”,到最终应用场景和生态可能都只是时间问题。
结语
最后,熊大鹏博士表示,中国要发展自己的AI芯片与技术,首先要“立足国内的供应链”,并强调,“不立足国内供应链,即使做出来能够达到国际先进水平的芯片,最终也会受到各种限制”;“其次,一定要走不同的技术路线,才有机会实现换道超车。”而亿铸科技就在走这样一条明确的道路:与国内Foundry与IP供应商合作;走与众不同的存算一体路线,这也让亿铸科技的大算力全数字存算一体芯片更加值得期待!