
前不久苹果发布了M4芯片。除了CPU和GPU迭代以外,NPU是这次的更新重头戏——当然苹果是称其为NE(Neural Engine)的。苹果特别强调了NE的理论性能是38TOPS,比2017年A11上的NPU快了60倍,“比现在任何AI PC上的任何NPU都要强”…
很显然苹果在AI PC的问题上是有点着急了。如果你有仔细留意过苹果历史上的发布会就会发现,苹果非常少用“AI”这个词,而在大部分情况下说“机器学习”;但这场发布会已经开始毫不避讳地AI、AI、AI了。6月份的WWDC苹果开发者大会上,我们大概能听到大量有关于苹果版AI PC的开发生态信息。
无论最早提出AI PC一词的是谁,最早打响AI PC战役的一定是Intel,随后AMD、英伟达、高通也相继入局。如果再算上潜在要入市的联发科(一直有传言联发科很快就要发布面向Windows PC的芯片,而且可能会和英伟达联手),则就芯片市场来看,AI PC的竞争者主要包括苹果、Intel、AMD、英伟达、高通、联发科。
谈论AI PC首先要明确两点。其一AI PC尚处在概念成型期,或者说其发展还相当初期。其二,AI PC是整个产业全价值链在共同推进的东西——即便在用户看来,现阶段其噱头大于实际,AI PC的推进也不可阻挡的。
这篇文章我们就来尝试谈谈现如今的AI PC竞争格局——虽然电子工程专辑此前已经写过不少AI PC的文章,但大多是从单个企业的角度谈生态。本文期望概览这一领域不同市场玩家的布局和现状,探讨未来的不同可能性。
NPU在AI PC上,究竟是个什么角色?
今年2月库克就面向股东说过,采用苹果芯片的Mac已经是出色的AI设备了,比市面上的AI PC都要好。这话的依据在我们看来应该是苹果的确从2017年开始,就已经在A11芯片中加入了专用的神经网络硬件单元,也就是我们常说的NPU。很自然的,Mac在换用Apple Silicon的同时,就已经全线用上了NPU。
如果说内置NPU就算AI PC,那么2020年采用M1芯片的MacBook Air就算得上是AI PC了。所以很显然,我们不能简单用芯片内是否包含专用AI加速单元来评判某台电脑是不是AI PC。
更重要的是,英伟达GeForce相关业务当前也正在热推AI PC的概念。如果我们定义必须有NPU才算AI PC,英伟达大概是头一个不同意的——人家做的是GPU;何况英伟达的整体AI生态还远优于其他竞争对手,自然在谈论AI PC时有一席之地。
还有件事可能是很多读者不知道的:即便Intel在各种宣传Meteor Lake处理器(即酷睿Ultra 1代)是AI PC的芯片基础,以及Meteor Lake首次内置了NPU;这代处理器的NPU仍然只能用小规模来形容,它并不是个很大的处理器模块——在跑绝大部分生成式AI负载时,也并不作为主角存在。

酷睿Ultra处理器中的NPU
比如说借助Intel OpenVINO来跑Stable Diffusion文生图这样的AI工作,默认情况下负载要求最高的部分(Unet)仍然是交给酷睿处理器中的核显iGPU去完成的,NPU负责其他环节。当然也可以指派NPU去完成最耗时的部分,但这样一来,文生图的等待时间会更久。
Intel推行的是XPU策略,即AI负载按照特性分配给CPU, GPU和NPU。其中GPU才是更专注在性能并行和吞吐方向的;Intel对NPU单元的定位也非常明确:追求高能效,以及持续性的AI负载,比如视频会议时用于实现眼神校正、画面超分或语音降噪之类——但这些都算不上生成式AI。
那究竟什么是AI PC呢?有一项依据:去年我们尝试在采用酷睿13代处理器的笔记本上跑生成式AI,也完全行得通——不管是Stable Diffusion,还是LLM大语言模型——酷睿13代处理器可没有内置NPU。甚至酷睿7代处理器接上Intel软件栈,也能跑生成式AI,虽然性能是不大能接受的。
所以如果我们擅自定义AI PC的概念,那么大概是:能够以较好的体验,跑生成式AI的PC。至于如何量化“好的体验”,那是另一个课题。毕竟不同的模型都有不同的算力需求,比如Stable Diffusion XL推理,也只有高端独显才称得上“好的体验”;而规模显著更小的Stable Diffusion 1.5,生成一张512x512分辨率的图片,则核显+NPU也能接受。
另外,如果真的采用这一AI PC定义,那么但凡用上了独显的PC(甚至不需要是最新的),都有资格称得上AI PC。在PC领域,虽然参与者们普遍强调NPU的重要性,但事实就是起码现在NPU还没有太大的价值。不仅因为NPU在算力和用料规模上都完全无法与独显相提并论,而且其仅有的那点儿使用场景也完全可以被包括核显在内的其他硬件取代。
高通对于骁龙X Elite之上NPU的宣传
Chips and Cheese前不久发布酷睿Ultra NPU的架构和性能分析。单就功耗来看,酷睿Ultra的核显能飙到20W功耗,而包含NPU在内的System Agent出全力也干不到7W。
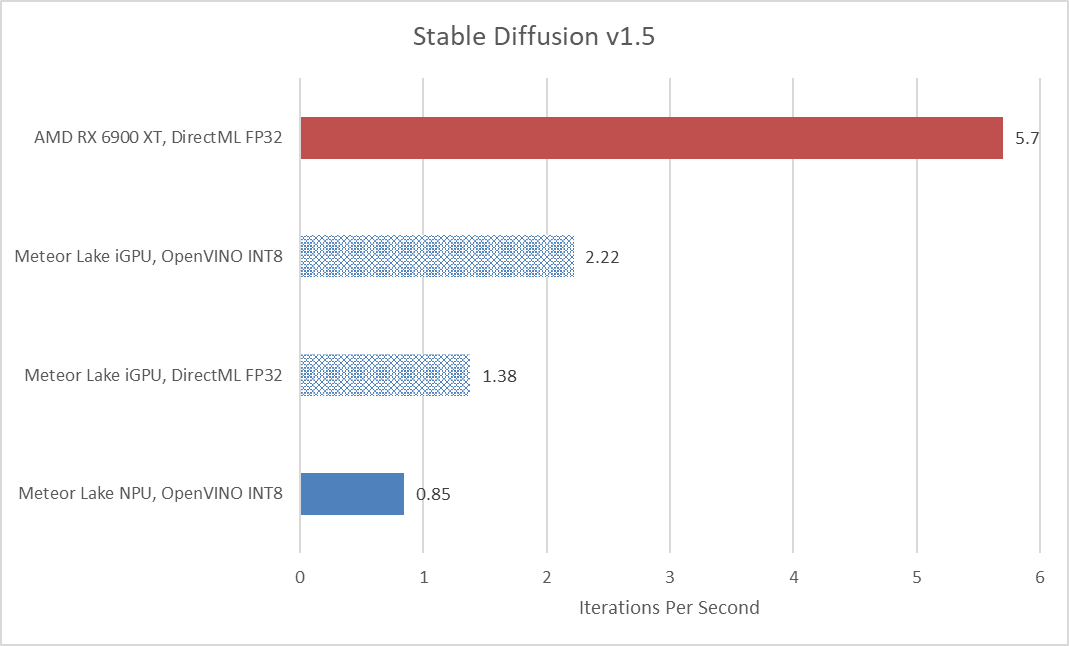
从我们此前的测试来看,NPU表现出了远高于核显的效率,但其整体性能不及核显,还要考虑到后者有着更好的硬件灵活性。Chips and Cheese在测试中尝试将Stable Diffusion的Unet全部工作交给NPU来完成,相比全部给核显(iGPU)完成,性能上还是有差距的——如下图。
来源:Chips and Cheese
这张图中,另有两个对比项是用Olive+DirectML直接跑原生SD 1.5模型——分别跑在核显和独显(AMD Radeon RX 6900 XT)上,似乎更能说明我们对于AI PC的“擅自定义”是存在很大问题的。对于开发者而言,不需要做什么额外的工作,模型就能跑在GPU上,而且GPU对模型的支持也比NPU更加广泛。
从这个角度来看,AI PC时代NPU的价值可能更在于战未来。对普通人而言,NPU的价值暂时停留在视频会议换背景、眼神校正之类的痒点问题场景,可能顶多加上NPU还用于安全检测之类一般人感知不到的地方。这是所有PC处理器厂商都面临的问题。
我们仍然赞同NPU对于AI PC的价值,但不是现在。Intel预告下一代酷睿Ultra(Lunar Lake)的NPU算力将提升3-4倍;商用AI PC发布活动上也提到,未来计划将更多工作负载交由NPU完成。则NPU的战未来属性也就愈发明朗了。
英伟达,与其他竞争者的角色差异
除了在PC市场只做加速器的英伟达之外,苹果、Intel、AMD、高通(包括联发科)都在自家的PC处理器中集成了AI推理加速单元,虽然各家对这个加速单元的叫法不同,但行业习惯上称其为NPU。
各家最新的PC处理器,其中NPU标称算力(每秒Int8 MAC操作)为:高通45TOPS(骁龙X Elite),苹果38TOPS(M4),AMD 16TOPS(Ryzen 8000)——涵盖不同处理器的算力总和为39TOPS,Intel 11TOPS(酷睿Ultra 1代)——涵盖不同处理器算力总和45TOPS。
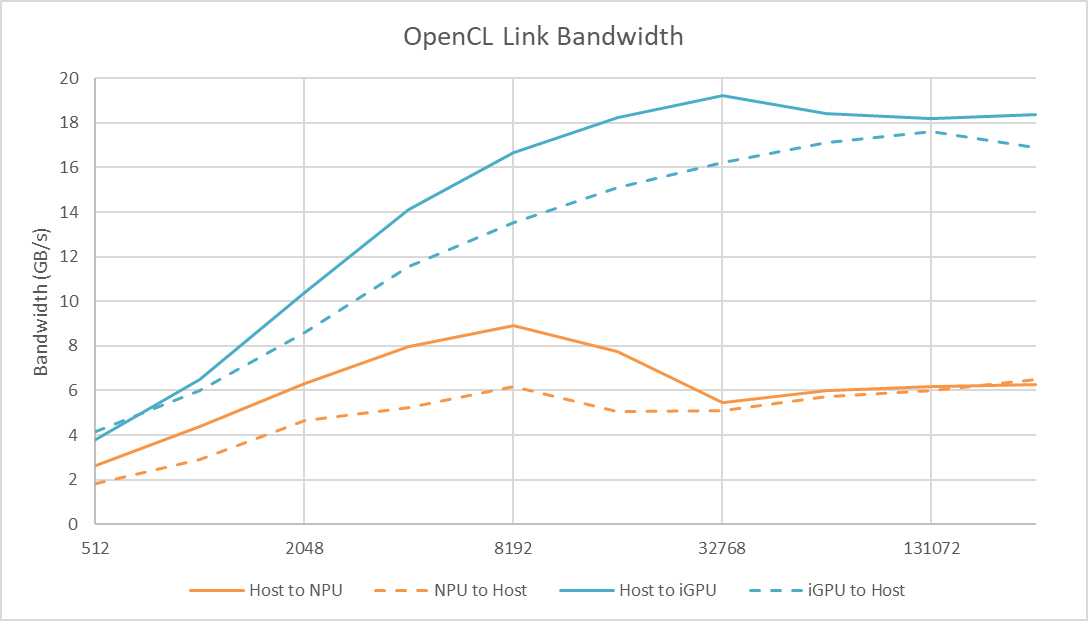
这个数字的意义大不到哪儿去,但也可作为算力参考的依据。也不只是算力,在访问主存带宽之类的问题上,NPU都可能还有很大的提升空间——有兴趣的还是建议去看一看Chips and Cheese的microbenchmark。从这两个角度来看,NPU和独显的性能完全不在一个量级。
如果考虑PC领域的独立加速器赛道,英伟达最新的GeForce RTX 40系GPU,AI标称算力在200-1300TOPS区间。当然Intel和AMD也做PC独立显卡,且覆盖了生态,但这两家主推的AI PC概念目前集中在自家集成NPU的芯片上;PC主力出货量的笔记本独显统治者毫无疑问是英伟达;而且前两者在独显高端市场几乎无力与英伟达一战。
这很容易让人联想到图形与游戏显卡市场的传统定位:当你只有简单的图形和视频编解码加速需求时,用核显/集显即可;有更高图形与视频编解码算力需求时,考虑选择独立显卡。在AI加速器的问题上,初看应该也是如此:基础算力由Intel、AMD、高通提供,更高算力需求由英伟达或者其他参与者的独显提供。
但AI加速器生态现状,决定了事情并没有那么简单。不同的芯片厂商都在发展各自相对独立的生态,决定了在绝大部分情况下生态难以兼容。比如英伟达在AI PC上,也在发展以CUDA为基础的开发生态——该生态具有更大程度的排他性。则在AI PC时代,英伟达与Intel、AMD形成了某种程度的生态竞争关系。这是在显卡单纯用于游戏这一领域时,并不存在的竞争格局。这一点也将在后文详述。

英伟达于AI PC市场发展的最大弱点,在我们看来在于这家公司并不做PC通用处理器。这决定了英伟达的市场基础将显著弱于竞争对手,在每年2-3亿PC出货量中,仅有少部分会搭载独立显卡(基于保有量数字可能在30%左右)。
虽然在显卡还不做AI加速的时代,英伟达面对的市场也是如此;但如前所述,AI PC的生态有排他性,有时这会要求开发者在生态间做出优先序列选择。
不过英伟达在新战场的竞争中有两大优势。其一是以CUDA, TensorRT(包括TensorRT-LLM)为基础的AI生态发展最为成熟,这也得益于英伟达在数据中心AI市场的多年耕耘和现如今的霸权地位。基于此,大模型领域的很多项目在开发之初就会首先考虑英伟达GPU。现阶段我们从生成式AI艺术家那儿获取到的信息是,生成式AI在PC本地的部署和使用,也总是英伟达GPU更受欢迎,遇见的问题更少。
与此同时英伟达接下来极有可能借助企业AI生态的统领地位,带动商用AI PC的发展。尤其当NIM(NVIDIA Inference Microservice)深入到企业市场以后。企业定制版Copilot的其中一个载体就是AI PC。
其二也的确在于更高的算力,对应于严肃生产力市场。也就是说它是能正儿八经用来干活、赚钱的。比如Stable Diffusion文生图或图生图应用对大部分人并没有太大的实际用处——真正需要用SD生图的用户,大多是为了工作,用于提升生产力效率——无论是建筑设计概念图,还是平面设计辅助。对这部分人来说,NPU那几十TOPS的算力根本成不了事。
这也决定了英伟达独显面向的AI PC市场定位更为精准。类比于游戏领域内,真正的游戏爱好者必然选择独显。只不过在英伟达定义的RTX AI PC概念下,英伟达可能需要重新考虑GeForce和RTX专业图形卡的品牌和定位——这就是英伟达内部的问题了。

不过我们认为,英伟达的生态优势在端侧AI推理领域,并不像数据中心AI领域那么大。端侧推理生态的构建难度也远低于数据中心市场,何况Intel、AMD还有成本和主场优势;苹果则压根不和英伟达一起玩。这些变数也让AI PC的竞争局面变得尤为复杂。
但至少现阶段,除了苹果以外,因为算力规模差异,英伟达的AI PC竞争赛道仍然与其他参与者不大一样。这一点和游戏/图形领域核显与独显关系类似,但这两者的生态关系却没这么简单。
AI生态 vs 图形生态
走过GPU的图形渲染生态构建时代变迁,大概更能明白一个道理:图形渲染GPU生态,从最初显卡市场大乱斗及标准的多样化,发展到后来标准的一统(DirectX/Vulkan),是大势所趋。对消费者而言,现在选择游戏显卡时,在大部分情况下,都不需要因为标准,或者某品牌显卡玩不了某款游戏,而不得不做出生态上的选择。
换句话说,在Windows操作系统上玩游戏,生态话语权更大程度在微软或某些标准上;虽然也存在AI超分/补帧、光追,以及软件效率之类的差异,但起码游戏玩家不同品牌间的显卡切换成本并不太大。
这是不是就好比现在AI PC的应用生态处在早期大乱斗阶段,各家芯片厂有各自的开发工具和生态系统,随着市场走向成熟,最终也将有统一的标准,生态话语权将从芯片厂商那儿易手?可能现在要回答这个问题还为时过早。
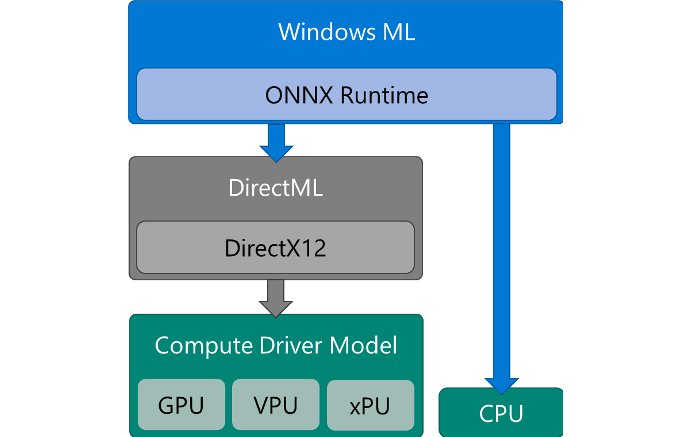
在AI PC这一概念尚未大规模推广之际,微软就已经发布了DirectML和Windows ML API,用以实现跨硬件的AI加速。对开发者而言,不需要管是Intel的CPU,英伟达的显卡,还是高通的NPU。就如同游戏接入DirectX标准一样,这会成为AI PC的未来吗?
起码我们认为,芯片厂商是普遍不乐于见到这种场面的——尤其是像英伟达这样自有生态相当有一套的市场玩家。而且从更实际的角度来看,WinML/DirectML作为跨平台、隐藏硬件细节的工具,在效率、性能方面和硬件厂商的工具(如英伟达的TensorRT、Intel的OpenVINO)是不能比的。借助benchmark就会发现,WinML与芯片厂提供的工具在性能层面差距显著。
如今的半导体行业,已经不似当年为了开发和用户体验可以毫无顾忌地搭建中间层。当年图形生态的一统,离不开摩尔定律作为时代发展背景。现如今摩尔定律的放缓是客观现实,在算力资源吃紧的今天,效率问题会尤为关键。即便未来AI PC生态的发展会经历某些拐点,也绝不会像当年的图形生态标准建立那么简单。

微软Teams会议AI特效的开发工具链路径
当代半导体行业发展的另一个趋势是:芯片厂商“管得越来越宽”。如果说以前关注芯片、compiler和基础开发工具即可,那么现在可能不仅要亲自下场做芯片构成的系统(和其中的诸多组成部分),而且要为开发者准备更全面的软件和工具,甚至亲自做应用。这也某种程度体现出摩尔定律难以为继的时代背景。英伟达在AI方面的“端到端”工作就无需多说了,Intel在宣传上从前年就开始反复谈在软件上的努力了。
比如此前我们撰文提过Intel的BigDL-LLM(后来似乎改做IPEX-LLM项目了),对主流的一些Tranformer模型做量化,降低PC本地硬件资源需求。英伟达甚至有专门的Efficient AI研究,各种剪枝、稀疏化、AWS权重量化。当然这类研究也不光是为了端侧PC,还在于很多边缘的AI应用。
一方面是能看到芯片厂商在相关模型、开发软件和工具方面的投入,另外也表现出不同硬件基础的开发生态处于各自为政的状态。即便Intel、AMD之类的市场玩家普遍更强调开放、开源,但某些AI相关组件的开放和开源在我们看来更是无奈之举。谁都期望构建起围绕自家AI PC的“标准”和生态。

不过微软在此间扮演的角色也并不简单。微软提出的ONNX中间层还是得到了广大芯片厂商的支持的。而且开发者似乎可以混搭来自不同市场参与者开发工具的不同层级做开发,比如用ONNX Runtime,搭配OpenVINO Execution Provider,也就是用ONNX Runtime API做ONNX模型推理,并且用OpenVINO工具作为后端。
从某个角度来看,微软和各芯片厂既有合作关系,也有生态的竞争关系。加上错综复杂的开放标准和来自不同供应商的开发工具及其间层级,现在的AI开发生态在高速的动态变化状态。这种格局可比GPU图形生态构建之初要复杂多了,可能和AI应用范围更广,以及还涉及到多种多样的AI模型、数据格式、训练与推理技术有关。
过去一年我们参加的不少峰会圆桌上,许多行业专家都认为AI PC与AI手机的生态最终会走向标准化,或者至少会实现“互操作性”(interoperability);但与此同时他们也非常好奇,在生态走向成熟以后,模型厂商、操作系统厂商、芯片厂商(乃至IP供应商)在此间扮演的角色会发生怎样的变化。这可能也是所有人好奇的问题。
苹果的动作,会是关键
就AI模型产生的角度来看,苹果在英伟达面前可能是不值一提的。但在AI PC领域,苹果接下来的动作在我们看来却可能非常重要——而且不光是AI PC,还包括苹果打算针对iPhone做出怎样的“AI手机”决策与营销。
苹果在上述探讨的芯片企业角色中是最为特殊的。苹果不单是芯片厂商,也是操作系统供应商、OEM厂商,以及应用开发者。所以苹果具备最与众不同的生态调度能力,也是macOS, iOS生态内唯一的统治者。每个人都在翘首期盼6月份苹果打算如何安排属于自家的AI盛宴。
很多人质疑苹果入局AI PC是不是太晚。实际上不要说苹果的开发生态,更大程度脱离其他PC价值链上下游参与者而自成一派;AI PC的整体发展状态都相当早期,Intel、AMD的那一点点先发优势可能并没有什么大不了,就连英伟达正式参与AI PC的竞争也是近半年的事。
而且苹果布局Core ML机器学习框架也是自iOS 11就开始的;在macOS 13.1和iOS 16.2版本,苹果就宣布Core ML针对Stable Diffusion做了优化,那是2022年末。对苹果而言,有关AI PC的推出,很大程度上也不过是新增个市场营销方案罢了。苹果大概也意识到了这一宣传方向的紧迫性,才会在发布会上大方谈AI PC…
另外,苹果与Intel、英伟达这类市场参与者的差别在于,其主力市场基本都集中在消费业务上。苹果对于终端用户体验的关注也是由来已久的。如何让生成式AI真正普惠消费用户,并据此诞生杀手级应用是所有人都关注的话题。毕竟发展早期的AI PC还并没有形成真正像样的爆款级AI应用。所以大众都在关注苹果交出的答卷。

我们常说像Stable Diffusion WebUI这样在PC端已经具备相当声量的AI应用,部署难且使用体验都只能用灾难来形容。这体现的其实是AI PC发展尚处早期的现状。
我们在市场上也看到了一些具备杀手级应用潜力的AI特性,比如融合RAG方法的LLM大语言模型助手——实现了办公或生产力的私人定制,或者从交互方式上做出变革的AI助手——比如让它打开昨天未完成的工作这类原本在机器看来很复杂、模糊的指令......只不过这些AI特性或应用现阶段都还没有以好的用户体验导向,融入到PC使用流程中。
大概这类应用仍待足够的时间做体验完善。当价值链上的诸多参与者都来参与这场盛宴、且期望从中分的一杯羹时,体验强化及爆款应用的涌现都不过是时间问题。即便如本文谈论的,无论从硬件还是软件角度来看,AI PC真的都还处在初级中的初级阶段。

