
人工智能(AI)是一股不可阻挡的力量,正开始渗透到我们社会的方方面面。ChatGPT和类似的生成式AI工具的出现已经风靡全球。尽管许多人对这些生成式AI工具的功能赞不绝口,但这些模型的环境成本和影响却常常被忽视。这些系统的开发和使用极其耗能,其物理基础设施也需要大量能源。
部署AI给以CPU为中心的传统计算架构带来了巨大的技术挑战。通过基于软件的管理和数据控制,数据要在网络、CPU和深度学习加速器(DLA)之间多次移动。这就造成了并行命令之间的多重冲突,从而限制了DLA的利用率,浪费了宝贵的硬件资源,并增加了成本和功耗。

NeuReality公司Moshe Tanach
如何在利用AI优势的同时减少其碳足迹?NeuReality公司首席执行官兼联合创始人Moshe Tanach在与笔者的讨论中表示,减少AI碳排放的关键在于简化运行和提高效率。他认为,从以CPU为中心的资源密集型模型过渡到NeuReality以AI为中心的模型和片上服务器解决方案,可以降低成本、减少能耗并提高吞吐量。
Anne-Françoise Pelé:推理AI到底是什么?它与ChatGPT等大语言模型(LLM)的生成式AI有什么关系?
Moshe Tanach:下面我就来详细解释一下,为什么推理AI和NeuReality的特定技术系统与生成式AI和ChatGPT以及其他类似LLM的经济可行性相关。
首先,任何神经网络模型都始终遵循底层架构,例如卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆(LSTM)以及现在用于LLM和生成式AI的基于Transformer的模型(编码器/解码器)。有了它,你就可以在未来生成语言、图像和其他可能的事物。你可以让它运行多久都行,给它新的上下文或新的输入。这就是为什么在ChatGPT中,你会看到“重新生成”功能。因此,生成式AI是神经网络模型或AI类别的又一个例子。
其次,所有神经网络模型,不管是哪一种,都必须经过训练才能完成预定的任务。开发人员向其模型提供一个精选的数据集后,它就能“学习”有关它待分析的数据类型所需的各种知识。ChatGPT(生成式预训练Transformer)擅长分析和生成类人文本。ChatGPT使用互联网上的所有数据进行训练。
一旦它使用了所有互联网数据,并找到了不同字母和单词之间的所有连接点,所有数据就会在ChatGPT内部形成结构。
第三,一旦它被冻结并使用新的上下文或输入,你就可以进行推理,也即使用已训练模型的过程。要理解推理,可以想象一下教人通过声音识别乐器。一开始,你先弹吉他、小提琴和尤克里里琴,并解释这些乐器会发出不同的声音。之后,当你介绍班卓琴时,他就可以推断出它所发出的独特声音与吉他、小提琴和尤克里里琴相似,因为它们都是弦乐器。
NeuReality专注于推理阶段,而不是训练复杂的AI模型。相反,我们为数据中心以AI为中心的推理创建了底层架构和技术堆栈,从而以更低的成本和能耗实现最佳性能,并使其易于使用和部署,让所有企业都能从中受益。
Pelé:NeuReality的推理AI解决方案如何帮助解决生成式AI问题?
Tanach:想象一下每天在像ChatGPT这样的LLM和其他类似的LLM上进行的数十亿次AI查询。
与传统模型相比,对这些AI查询进行分类、分析和回答所需的计算机能力是天文数字,系统成本、效率低下和碳排放也是如此。微软和OpenAI自己都公开表示,仅运行ChatGPT每天就要花费数百万美元。
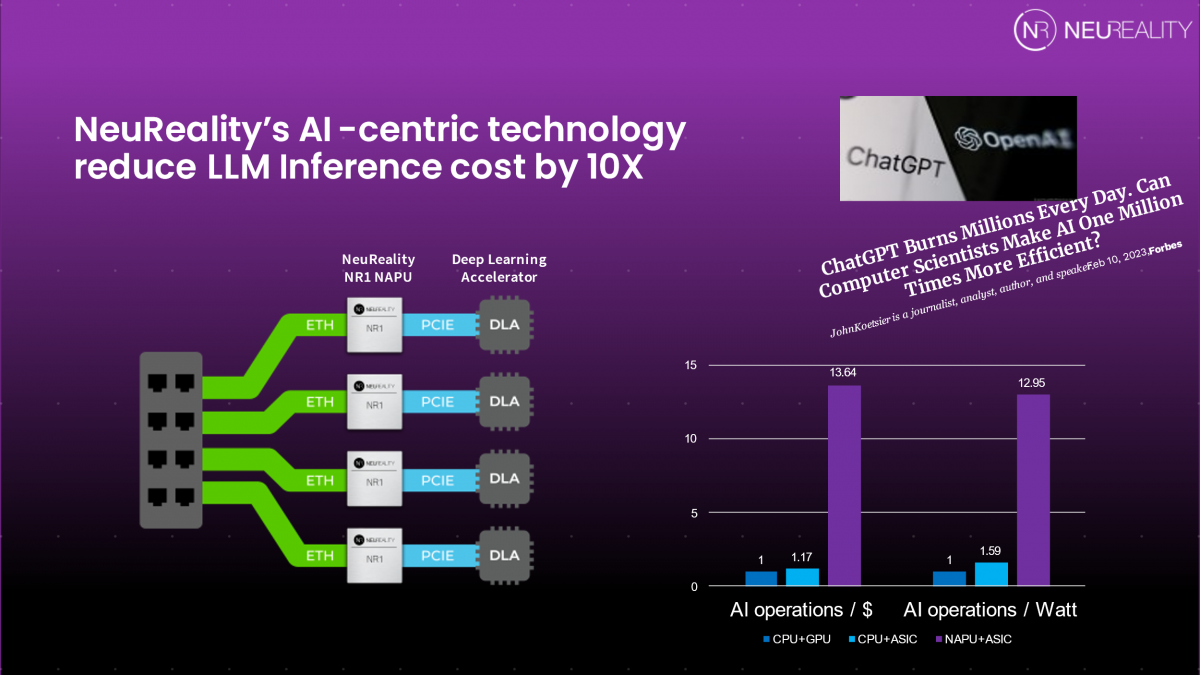
事实上,生成式AI所需的输入比以通用CPU为中心的系统少10倍。NeuReality设计的网络可寻址处理单元(NAPU)的运行功耗要低得多。因此,我们可以帮助公司节省资源,同时减轻全球能源系统的负担——这在与IBM Research合作的测试案例中得到了验证。
Pelé:为什么减轻推理对环境的影响对于在商业应用中有效推广生成式AI模型至关重要?
Tanach:与图像分类、自然语言处理、推荐系统和异常检测模型等其他模型一样,生成式AI也受到以CPU为中心的架构的影响。
NeuReality正在重塑推理AI,以满足生成式人工智能和所有其他依赖推理的模型当前和未来的需求,从而在不耗费资金的情况下扩大规模。当一家公司依靠CPU来管理深度学习模型中的推理时,无论DLA有多强大,CPU都会达到一个最佳阈值。
相比之下,NeuReality的AI解决方案堆栈不会不堪重负。系统架构的运行效率更高,能效更高,能耗更低。
Pelé:训练生成式AI模型的碳足迹是多少?
Tanach:NeuReality以AI为中心的架构采用了能效更高的NAPU(一种全新的定制AI芯片),大大降低了功耗。
相比之下,当今的生成式AI和LLM因其高能耗和由此产生的碳排放而引发了严重的环境问题。分析师认为,单次AI查询的碳足迹可能是普通搜索引擎查询的4到5倍。据估计,ChatGPT每天消耗117万GPU小时,相当于15万服务器节点小时,每天排放约55吨二氧化碳当量。这相当于一辆普通汽车一生的排放量,假设稳定使用,每年累积起来相当于365辆汽车一生的排放量。
以下三项研究概述了当今以CPU和GPU为中心的生成AI模型目前对环境造成的负面影响:
- 2019年,马萨诸塞大学阿默斯特分校的研究人员对多个LLM进行了训练,发现训练一个AI模型会排放超过626,000磅(约283,948.59千克)的二氧化碳——相当于五辆汽车一生的排放量——早在2019年,MIT Technology Review(麻省理工学院科技评论)就分享了这一数据。
- 最近的一项研究做了类似的类比。该研究报告称,使用1750亿个参数训练GPT-3消耗了1,287兆瓦时的电力,导致了502吨碳的碳排放量。这相当于驾驶112辆汽油动力汽车一年。
- 微软概述了Azure实例的计算成本。
Pelé:我们怎样才能让这些模型比其前身性能更强,同时又不会对环境造成更严重的影响?
Tanach:我们对于构建性能更高、成本更低,同时又能减少我们碳足迹的推理AI解决方案有着强烈的紧迫感。我们是要做“和”而不是“或”。这样,我们就能可持续地满足生成式AI和其他AI应用在欺诈检测、翻译服务、聊天机器人等方面当前和未来的需求。
目前的基础设施主要在两个方面存在不足:
- 系统架构使用非AI专用硬件,因此无法完成推理服务器的真正工作。
- 尽管深度学习模型将软件卸载到了硬件上,但仍有太多的周边功能在软件中运行。它并没有完全卸载到提高能效所需的程度。
这些系统缺陷降低了目前所使用的GPU和DLA的利用率,而效率的缺失会造成更严重的能源消耗,进而影响环境。
NeuReality能让这些模型以更低的价格更好地运行,同时减少对环境的影响。我们为AI设计了系统架构,而不是修改旧架构。我们的新NAPU将剩余的计算功能卸载到Arm内核上,这些内核的成本和功耗都较低。通过消除CPU瓶颈,我们还提高了DLA的利用率。
所有这些因素加在一起,即可使以AI为中心的解决方案运行得更好,同时不会对环境造成更严重的影响。
Pelé:运行推理的碳足迹是多少?
Tanach:让我们以Google为例,Google拥有庞大的数据中心,处理从Google搜索到Google Bard的各种任务。根据2022年2月的Google Research数据,在过去三年中,机器学习训练和推理每年仅占Google总能耗的10%到15%。而且,每年都是2/5用于训练,3/5用于推理。与其他拥有大型数据中心的巨头一样,根据Statista及Google自己的内部消息,Google的总能耗也在逐年增加。机器学习的工作负载增长尤其迅速,每次训练运行的计算量也是如此。
虽然推理AI在总能耗中所占的比例已经较小,但它在支持饥饿的生成式AI应用方面却越来越受欢迎。选择合适的高能效基础设施来优化模型,并实施软件工具和算法来减少推理过程中的计算工作量,这一点至关重要。这正是NeuReality推出新型NR1时所做的事情。
Pelé:我们如何通过更可持续的推理来实现更绿色生成式AI?有哪些选择?
Tanach:NeuReality在三年前开始这一征程时就展现出了远见卓识。我们要解决的问题是如何在系统层面设计最好的AI技术,以及如何设计出适合推理AI日益增长的需求的软件工具。
努力实现高性能、可负担和易使用的AI——同时减少对环境的影响——应该成为更广泛的可持续发展战略的一部分,在这一战略中,大大小小的企业都要考虑其AI模型在整个生命周期中对环境的影响。
有多个因素需要权衡,包括用于训练和推理的高能效硬件。这包括GPU、TPU和定制DLA,旨在以更高的能效执行AI工作负载。
当然,NeuReality也知道这些芯片并非最佳选择,因此提供了一个明确的替代方案,即使用能耗更低的小型模型。
Pelé:NeuReality成立于2019年,旨在开发新一代AI推理解决方案,摆脱以CPU为中心的传统架构,实现高性能、低延迟和高能效。为什么必须开发以CPU为中心的AI推理架构的替代方案?
Tanach:现在,运行ChatGPT每天至少需要70万美元,因为底层架构不是为推理而构建的(现在ChatGPT可以浏览互联网,提供不再局限于2021年9月之前数据的信息,而NeuReality的推理能力更强)。ChatGPT实在太昂贵、太耗能,而且很可能迟早会遇到性能天花板。
我们的解决方案堆栈专为各种形式的AI推理而设计,无论是云计算、虚拟现实、深度学习、网络安全还是自然语言处理。市场和我们的客户迫切需要让生成式AI有利可图,而NeuReality能以极低的成本提供10倍的性能,换句话说,每天只需20万美元,而不是100万美元。
NeuReality解决了当今的挑战——无论是在经济上(客户总价值或总拥有成本)还是在环境上(更低的功耗和更少的碳足迹)。我们以AI为中心的架构之所以与众不同,主要是因为它考虑到四个模型特征:
- 强化数据移动和处理
- 强化目前在软件和CPU中执行的排序——因此,强化了我们的AI管理程序
- 在客户端和服务器之间建立高效的数据管理网络
- 结合解码器、DSP、DLA和Arm处理器的异构计算,所有这些都为高效运行进行了优化和扩展,以确保DLA的持续利用,并辅以多功能多用途处理器
这些功能内置于NeuReality的AI解决方案堆栈中,以降低每次推理操作的能耗,从而使其成为一种更环保、更高效的方法。
Pelé:NeuReality声称,它以AI为中心的系统级方法简化了大规模运行AI推理的过程。它是如何做到这一点的?又是如何降低能耗的?
Tanach:NeuReality与IBM研究人员合作测试我们的推理AI解决方案。结果显示,与基于CPU服务器的传统解决方案相比,我们的性能提高了10倍。从时间和资源密集型CPU转向NeuReality的NAPU还可以降低成本和功耗,这对营收、成本管理和环境都有好处。
许多因素共同作用,使NeuReality的系统架构降低了能耗:
- NAPU实现了AI计算资源分配的分解和兼容,只在需要时才使用资源,利用率达到100%。
- 运行完整的AI任务流水线(而不仅仅是DLA模型)可将密集型任务卸载到我们的NR1硬件上,与异构计算引擎而非软件应用程序并行,从而使我们的解决方案更具能效。
- 减少推理时间——通过硬件卸载实现并降低推理延迟——可使其适用于实时或低延迟应用。
Pelé:能否解释一下NeuReality的长期愿景和雄心?公司目前的状况如何?
Tanach:简而言之,NeuReality的目标是让AI变得简单。我们的终极愿景是建立一个可持续的AI数字世界,在这个世界里,我们能实现AI的大众化并通过AI技术加速人类的成就。
我们是一家年轻的公司,我们的愿景是让所有创新者都能使用AI,帮助他们治疗疾病、改善公共安全并将基于AI的创新想法付诸实践。
如今,我们已拥有真正的产品和合作伙伴,形成了一条价值链,帮助我们将产品推向市场。在过去的三年里,我们的团队努力制作(NR1-P)原型,然后设计出全新的NR1芯片(NR1),该芯片已经过验证并于台积电工厂制造,目前已实现发货。
我们的推理AI解决方案还包括另外三个组件:
- NRI-M模块是一款全高双宽PCIe卡,包含一个NR1芯片和一个网络附加推理服务,可连接到外部DLA。
- NR1-S推理服务器是带有NR1-M模块和NR1芯片的推理服务器原型设计,可实现真正的分解式AI服务。该系统不仅成本更低,能效比高达50倍,而且不需要IT人员为企业最终用户实施。
- 我们还开发了软件工具和API,以方便开发、部署和管理我们的AI接口。
NeuReality更大的愿景是让AI在经济和环境上可持续发展。我们打算通过丰富的系统工程专业知识,不断预测和构建未来。随着我们与技术领域内外的客户和合作伙伴保持同步,我们可以开始设计和构建未来一年、三年、五年或十年所需的技术基础设施和系统。
(原文刊登于EE Times欧洲版,参考链接:How to Make Generative AI Greener,由Franklin Zhao编译。)
本文为《电子工程专辑》2024年6月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
