
人工智能(AI)之所以成为一个重要的讨论话题,很可能是因为OpenAI等大规模AI引擎及其生成式预训练Transformer(GPT)语言模型架构的能力不断增强。虽然这些系统是在数据中心级别运行的,由GPU提供处理能力,但较小规模的AI工作负载可以改善资源高度紧张的嵌入式终端产品的性能和用户体验。

在支持AI的电子猫门中,可以训练ML来区分一只猫和另一只猫,从而只为获准进入的猫开门。(来源:Alif Semiconductor)

以支持AI的电子猫门为例。使用机器学习(ML),首先可以训练它将猫与其他动物或物体区分开来。经过进一步训练后,它就能学会将一只猫与其他所有猫区分开来,然后只为这只猫开门。这样一来,家里就不会有其他猫了,而我们的猫也不需要戴上RFID项圈或类似不舒服的老式技术就能进入家门。在这里,AI极大地改善了宠物和主人的用户体验。
如果这个或其他AI增强型嵌入式应用需要使用电池供电,那么低功耗就是一个关键要求。如今,大多数此类资源有限的小型应用都基于通用MCU。虽然使用MCU可以实现ML功能,但这些器件难以快速执行AI任务,而且在执行AI功能时功耗过高。服务器规模的GPU可提供数倍嵌入式应用所需的处理能力,但其成本和功耗远远超出预算。
要设计出电池供电、支持AI的产品,设计人员需要一种更好的方法来实现ML工作负载,同时还能保留通用MCU的熟悉工具和指令集。Alif Semiconductor公司开发的一种方法将新的处理架构与Arm Cortex-M实时内核相结合,提供了一类全新的AI优化MCU,可轻松应对在电池供电的条件下实现AI的挑战。我们将展示与传统MCU相比,这种方法在执行AI工作负载时如何能提高性能和能效。
AI工作负载的特殊性
GPU之所以被用于大规模AI部署,是因为它能够并行执行许多进程,这对于创建有效的AI训练环境至关重要。神经网络通过同时处理多个大型数据集来学习。
举例来说,即使是一张图像,也是由图像的高度和宽度以及每个像素上的数据定义的一组大型数据集。当我们将其升级到视频时,我们会在训练过程中添加像素数据随时间变化的函数。与并行处理GPU不同的是,通用MCU中的标准CPU是串行处理数据的,每次扫描一个像素,而不是像GPU那样感知整个图像。这意味着,为了与相对较慢的GPU一样快地执行相同的图像识别任务(例如,准确识别一只宠物猫),MCU的CPU在扫描每个像素时必须以更高的速度运行。
这种运行方式往往会使CPU内核长时间处于最大工作频率。由于现在几乎所有的处理能力都分配给了AI任务,MCU的整体性能可能会受到影响。与此同时,器件的功耗也会增加,以至于电池运行不再可行。由此可见,要在基于传统通用MCU的电池供电产品中实现有用的AI功能是多么困难。
TinyML可实现简单的AI工作负载,但可能无法满足猫门场景
虽然基于通用MCU构建AI增强型电池供电产品具有挑战性,但也绝非不可能。一种解决方案是降低工作负载的复杂性,直到设备的功耗和性能处于可控范围内。TinyML是ML的一个子集,其运行功耗仅为毫瓦级,而不是用于大规模AI工作负载的GPU所消耗的数十瓦功耗。
通过利用专门设计的软件库进行资源受限的AI训练和实现,TinyML使电池供电的设备能够运行简单的AI工作负载,例如利用加速度计进行手势识别——这种类型的模型可用于智能可穿戴设备,以区分用户进行的不同运动。
尽管如此,TinyML工作负载很简单,所需的内存和处理能力远低于面部识别等高级AI任务。虽然有一些TinyML工作负载是针对图像处理的,例如对象跟踪,但这些工作负载还达不到为我们的AI增强猫门识别单只猫的水平。TinyML在改善最终产品的用户体验方面具有许多优势,但电池电源所需的低功耗是以牺牲更高级别的AI功能为代价的。
Arm Cortex-M55和Helium可在一定程度上实现类似GPU的操作
在设计AI增强型产品时,另一种解决方案是选择配备专为该任务设计的处理内核的MCU,例如Arm Cortex-M55。由于采用了新的矢量指令集扩展——Arm的Helium技术,Cortex-M55器件能够并行执行算术运算,从而实现了与GPU类似的操作,尽管规模较小。
这一点,以及Cortex-M55浮点单元(FPU)等MCU架构的其他开发成果,使Cortex-M55内核能够处理比典型TinyML应用更具挑战性的AI工作负载。虽然这一解决方案大大降低了使用通用MCU实现AI工作负载的复杂性,但仍然存在功耗问题,超出了电池供电产品的可行范围。
适用于通用MCU的AI加速器
解决这一问题的秘诀在于Arm设计的全新处理架构:Ethos-U microNPU。这种专用神经处理单元大大提高了Cortex-M内核的性能,可用作嵌入式物联网设备的AI/ML加速器。在需要Cortex-M MCU控制功能的AI增强型终端产品中,AI/ML计算可直接在这种新型microNPU架构上运行,其效率远远高于Cortex-M CPU。
将AI/ML工作负载转移到这一特定功能的内核上,还能让主Cortex-M内核在睡眠模式或低功耗模式下运行,从而在AI运行期间节省大量功耗。此外,该microNPU还能使用AI筛选数据,这样就可以只在microNPU推断出应用有需要时,才启动Cortex-M内核的高级功能。通过使用Ethos-U microNPU,通用Cortex-M MCU不会因AI/ML工作负载而负担过重,因此可以在不牺牲性能或电池寿命的情况下运行标准操作。
首批采用这种架构的MCU是Alif Semiconductor公司的Ensemble系列器件。在实际测试中,与其他Cortex-M器件相比,Cortex-M55实时内核与Ethos-U55 microNPU相结合,可将AI工作负载的能耗降低90%。
得益于microNPU内的离线优化以及先进的无损模型压缩算法,系统内存需求最多可减少90%,ML模型大小最多可减少75%。该系列为32位MCU领域添加了一类新的器件,既保留了通用MCU的熟悉性,又增加了高能效AI/ML推理的优势。
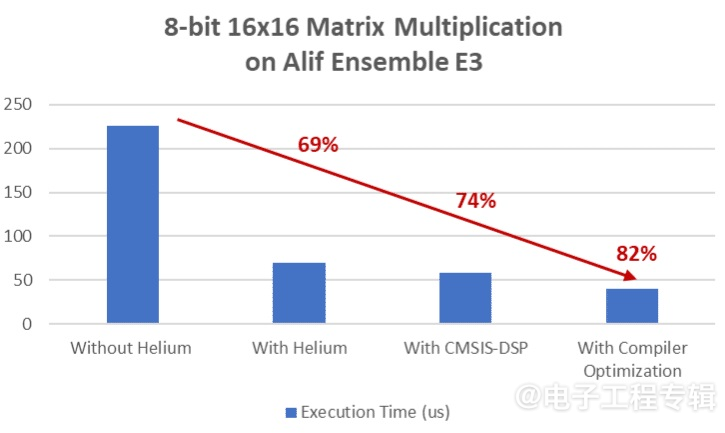
在一个用Alif Ensemble开发套件运行8位16×16矩阵乘法的真实示例的现场演示中,通过在Ensemble E3内部的Cortex-M55上启用Helium矢量加速,借助CMSIS-DSP本机库函数和编译器优化,Arm将执行时间缩短了82%。(来源:Alif Semiconductor)
AI/ML工作负载示例
通过堆叠多组Cortex-M和Ethos-U处理器组合,可以实现不同级别的AI/ML推理。例如,Ensemble系列中最基本的器件使用了单个Cortex-M55实时内核,并由单个Ethos-U55 microNPU AI/ML加速器提供支持。Ensemble E3是这一全新硬件加速MCU系列中第一个投入生产的产品。基准测试表明,在使用Alif的microNPU加速器的情况下,基于ImageNet数据集训练的MobileNet V2 1.0模型的执行速度比在单独使用Cortex-M55 MCU执行时快135倍,执行时间仅为20ms,而使用Cortex-M55内核时则需要近3s。
要知道,Cortex-M55的运行性能比上一代CM内核要高得多。经过测量,每次推理所用的能量也大幅下降。加速运行的能效是原来的108倍,仅消耗0.86mJ而不是62.4mJ。
更为有意思的是,该器件的双核版本在之前MCU的ML功能的基础上,增加了第二个更强大的Cortex-M55内核,并配备了按比例缩放的Ethos-U microNPU。与第一个内核结合使用时,可以创建一个两层推理系统,用于运行低级和高级的AI/ML工作负载。
在限制功耗的同时执行AI/ML任务的另一个关键是低功耗模式,在这种模式下,芯片的大部分都会掉电。在只有实时时钟和唤醒源仍处于活动状态的情况下,这些MCU的电流消耗约为1.0µA,这就使其成为了电池供电系统颇具吸引力的解决方案。当系统需要唤醒时,Cortex-M55内核可以以超低功耗运行,只需引导Ethos-U microNPU执行推理任务,以确定是否需要将Ensemble器件的更多部分上电。
现在来看看这项技术对我们之前谈到的AI电子猫门的影响。在前面的例子中,我们可以预计,猫最初是通过某种形式的运动感应、视频监控或两者的组合被检测到的。持续的视频输入和相关的AI推理会消耗大量的电能,因为它会试图识别我们的猫,而不管这只猫是否还在画面中。
为了节省功耗,双核Ensemble MCU可以利用第一个Cortex-M55内核的唤醒功能,首先使用低功耗传感器检测猫门前是否有动静。
一旦检测到运动,第一个Cortex-M55内核可以唤醒下层推理系统的Ethos-U microNPU,捕获几帧视频画面并分析数据,检查是否有猫出现;也可能是其他动物或异物从镜头前经过。如果在检查视频后发现有猫靠近猫门,第一个Cortex-M55就会唤醒上一层推理系统的第二个Ethos-U,检查它是否是我们的猫。
如果猫没有被识别出来,系统就会恢复到下一层的运动检测系统,直到有新的物体进入画面为止,从而节省能源。如果确定是我们的猫,那么第二个microNPU就可以唤醒第二个Cortex-M55系统,并启动让猫进来的机制。猫和它的家人仍然可以享受到AI设备带来的卓越用户体验,但通过使用由Ensemble器件中新颖的MCU设计实现的两层AI推理系统,功耗可以大大降低。
面对在电池供电的终端产品中实现ML的困难,这种处理架构所支持的两层推理系统可以解决高功耗和处理能力有限的问题。

Henrik Flodell是Alif Semiconductor公司的高级产品营销总监。Flodell在嵌入式行业拥有20多年的经验,他的职业生涯始于上世纪90年代初的医疗数据记录仪固件开发工作,此后一直负责管理开发工具、嵌入式软件部署系统、硬件开发平台、市场营销和业务开发团队,并参与了各种嵌入式设备的SoC产品定义工作。
(原文刊登于EE Times姊妹网站Embedded,参考链接:An MCU approach for AI/ML inferencing in battery-operated designs,由Franklin Zhao编译。)
本文为《电子工程专辑》2024年6月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。