
今年NVIDIA的GTC大会期间,我们一群分析师在讨论说AI PC现在究竟在AI时代下扮演何种角色:是芯片厂生造的、用于促进PC销量的宣传用语,还是实实在在能够惠及用户体验的技术?最后得出结论,援引某金融领域分析师的观点:AI PC乃是整个产业链共同推进的一场阳谋。
在全球分析师采访会上,有人问黄仁勋(NVIDIA CEO),NVIDIA在AI PC趋势面前扮演何种角色。黄仁勋说:“能跑AI的PC基础在于RTX,尤其是其中的Tensor Core。”这是NVIDIA眼中AI PC的硬件基础。但更有趣的其实是软件。
“第二,我们之前做的一件事情是让Windows能跑CUDA。”黄仁勋特别提到CUDA对于WSL 2的支持。基于NVIDIA与微软的合作,Windows平台“有了WSL 2以后,PC用户就能用NIM了,下载以后马上就能跑。你就能跟你的PC对话,非常炫酷(crazy)。”

NIM(NVIDIA Inference Microservice)是这次GTC上,NVIDIA面向企业发布的重头戏:前不久我们撰文探讨过NVIDIA在NIM上的野心。简单来说,NIM是为企业准备的一套工具集合,企业用它可以轻松打造属于自己、专有的生成式AI——比如NVIDIA自己就用NIM搞了个辅助做芯片设计的聊天机器人,NVIDIA的硅工们可以直接和它对话。
这整套东西能搬到PC上。当然如此场景肯定是需要高端AI PC或笔记本了。当这样的AI PC用于实际生产,而且确切为企业产生价值,我们还能说AI PC只是个宣传用的概念吗?

可能对很多个人用户来说,暂时用不上NIM这么高端的东西。但在最近NVIDIA举办的一场AI PC品鉴会上,我们还是看到AI PC用于正儿八经的生产力的现状和潜力:尤其当我们还在说Stable Diffusion生图没什么用的时候,已经有艺术创作者拿他赚钱,有大品牌用它做商业宣传,有先驱开发者基于生成式AI定义工作流了...
那么这种时候,我们就不得不正视AI PC,无论它是不是整个产业链的阳谋...
“快没有意义”
品鉴会上,吐司/Tensor.Art社区发布《个人用户玩转Stable Diffusion的GPU配置推荐》,主要是对不同GeForce RTX40系显卡做AI benchmark,包括SD 1.5, SDXL等项目。基于测试,给予正儿八经想用Stable Diffusion干活儿的用户以参考,应该选择什么型号的显卡。
吐司/Tensor.Art在活动上披露了部分数据,比如我们印象比较深刻的RTX 4090 D相比于RTX 4060 8GB,SD1.5的性能差距在4.5倍左右,基本符合我们对于这两款显卡配置资源差别的认知。
比较有趣的一则对比是GeForce RTX 4090笔记本电脑GPU与Intel酷睿Ultra处理器核显(128EU Xe-LPG),前者基于TensorRT推理加速,后者基于OpenVINO推理加速,双方Stable Diffusion 1.5推理性能差距达到了27+倍。(如下图)
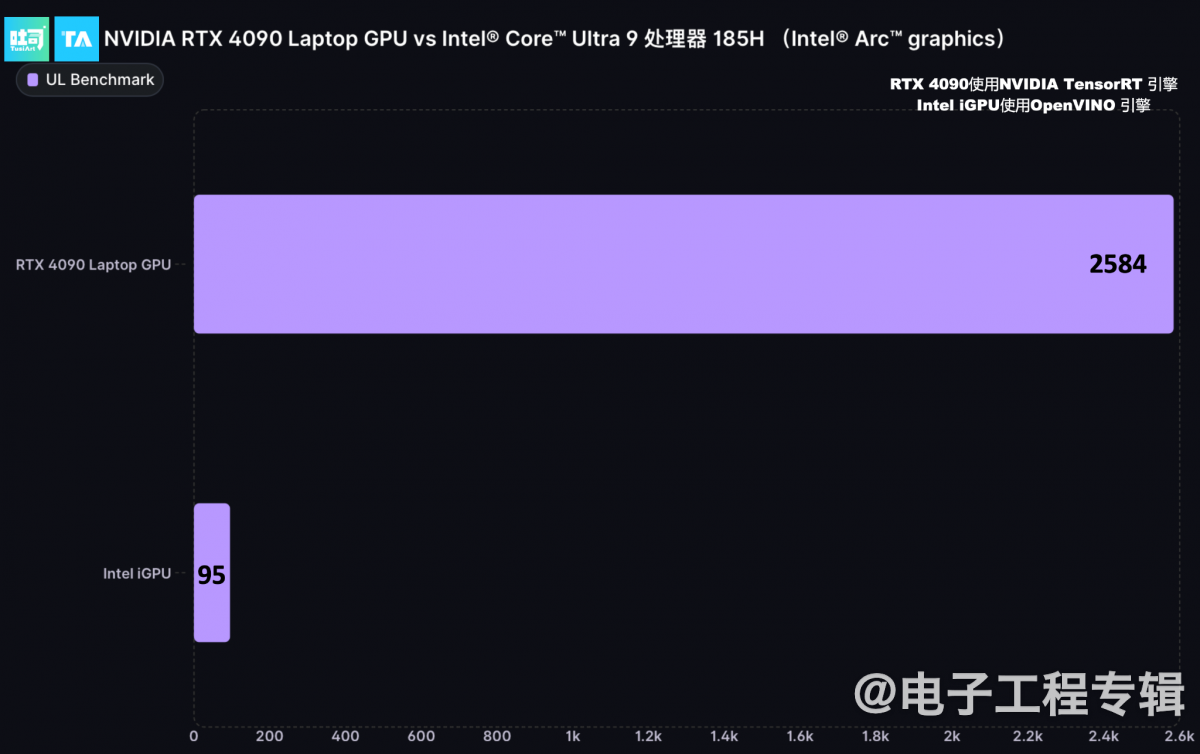
基于双方的堆料差异,我们认为这个结果并不算出乎意料,毕竟今年CPU厂商这边集合不同处理器的理论AI算力约在10-45 TOPS,而GeForce RTX 40系GPU的AI 算力在200-1300 TOPS区间。
沈振宇(吐司/Tensor.Art创始人)说除了GPU硬件层面的差别,内存访问带宽、TensorRT软件层面的成熟度也有很大关系。(后两个变量挺值得各位技术爱好者去深究一下的,尤其TensorRT和OpenVINO可能存在多少差距...)

另外,体现算力的数字还包括在ComfyUI(Stable Diffusion)下,RTX 4090 D能实现8张图/秒的出图速度;用Stream Diffusion则能够达成120fps的出图速率等等...
基于算力差异,PC领域内,NVIDIA给自己的定位还是很明晰:是相比于“非RTX AI PC”,能够执行重量级AI需求的RTX AI PC。这听起来和早年核显、独显玩游戏的逻辑还是类似的;不过其内在,尤其生态层面会比纯图形GPU时代更复杂。
“算力首先决定的是应用能跑多快。”NVIDIA产品经理强调,“但只是快其实没有意义。”“因为生产力必须可控,才能生成足够高质量的内容和资产。可控的能力,决定了生产力水平。”“我们有强大的生态支持。开发者和尖端用户基于我们的硬件,打造出非常具有生产力的工作流。这其实才是我们除了算力之外最重要的优势。”
有没有感觉这番独白相当的凡尔赛?其实说句大白话就是:我们生态支持好。剖开来看,可以做两个层面的理解。首先是NVIDIA AI从硬件底层到应用层全栈的生态构建;其次是生态的成熟度,或者说AI应用的可用性和生产力价值。注意,此处所说的主要是AI PC。后面咱详细谈一谈。
对于生产力,AI PC有价值?
一般呈现给用户的AI应用,不管是聊天机器人,还是视频会议的眼神注视功能,其下方都有一大堆层级结构。这个结构的最下层是芯片和硬件,往上层去就会有CUDA这样的系统软件层、中间件和库,再往上有TensorRT、AI模型,最上层就是开发者开发的AI应用。
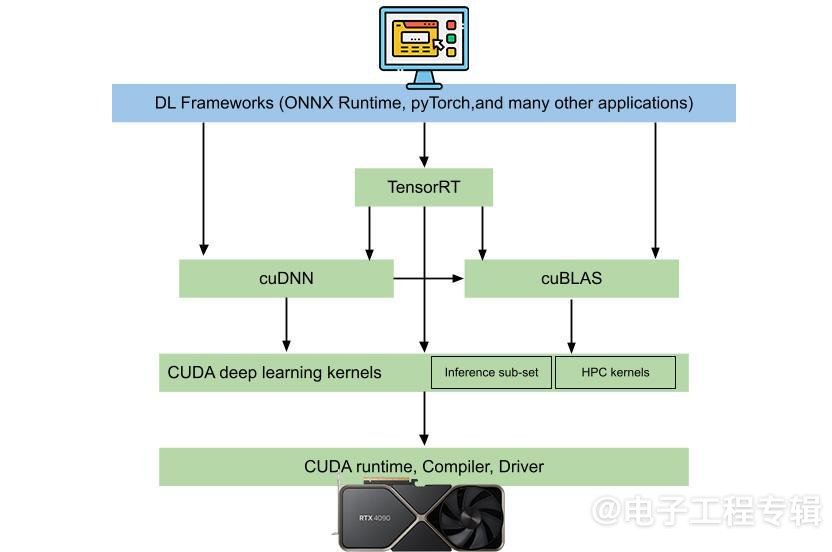
详情参见这里
这是简化过的AI推理全栈结构;AI训练会相对更复杂一些——我们之前都撰文探讨过,本文不做赘述。在训练和推理的两套框架内,NVIDIA还真是什么都做。从预训练模型,到这个库、那个框架的,还有微服务,以及亲自做了一堆应用层的东西——虽然绝大部分还是以API和开发工具的形式给到开发者。所以叫“端到端”,这在整个行业应该说都相当罕见。
虽然“端到端”的这种优势,主要还是体现在数据中心AI领域,不过这就是我们日常所说具备碾压实力、其他AI芯片企业难以挑战的CUDA生态。RTX AI PC是其中一部分:在GPU普惠到通用与AI加速时,构建了十多年的CUDA生态现在开始在PC平台发力。
其实NVIDIA产品经理说“快没有意义”的凡尔赛,本身并不是光靠硬件堆料达成的。各种Diffusion文生图模型的快速出图,其中就饱含了软件生态层面这些年来的完善和推进。所以“快”本身也是生态成熟度高的结果。

有关第二个方面,基于这一生态的AI应用问题,也就是生态的成熟度——应用的数量和质量,开发者及用户粘性是真正反映这一全栈生态的发展水平的。NVIDIA给到的数据是,RTX AI生态内有“超过1亿用户、500款RTX 应用和游戏”,“其中与生产力相关的应用超过110款”。
比如AI绘画,典型如Stable Diffusion;AI平面设计,AI技术引入到Adobe, Topaz全家桶等软件,涵盖抠图、降噪、超分等特性;AI视频编辑,Pr, Ae, 达芬奇做对象遮罩、场景检测、对象追踪等;AI 3D创作,用于3D渲染器的降噪,实时渲染器的DLSS...;还有各种视频会议与直播AI增强、视频超分与HDR效果加强等~
可见NVIDIA对于RTX AI PC的关键定位非常明确:生产力。换句话说,这东西是能产生实际价值的。以Stable Diffusion为例,NVIDIA强调RTX AI PC是“使用Stable Diffusion的最具生产力工具”。

现场展示用于建筑设计的工具,名为“即致AI”,模型是自研的;随意在左边的画布上画两笔,右侧就有实时的建筑效果图生成;而且可以切换各种不同风格…
比如在室内与建筑设计领域,“快”的价值在于让设计师在图上勾勒几笔,AI模型就能立刻生成室内设计草图,或者建筑设计用于推销的前期方案。现场做demo演示的前沿建筑设计师、艾哎集瑟科技联合创始人言萧说,“很多业主并不清楚自己需要的效果,过去我们会去网上找很多意向图,然后再花时间去建模;业主推翻,我们再改...”
以前“从手绘到建模、渲染、打光,进3DMax, Vray这样的渲染器,出图至少要1-2天。”“现在能快速出图,跟业主的沟通也就加速了。”设计实时出图、快速迭代,实际上就已经是AI PC产生商业价值的某种体现了。
不过在NVIDIA看来,“真正将Stable Diffusion用于生产力的用户,需要更复杂的工作流,需要更复杂的软件支持。”NVIDIA描绘RTX AI“支持最先进的SD工作流”,PPT中列举了一些词条:LoRA, ControlNet, 微调, AnimateDiff等。这里的“SD工作流”体现的应该就是NVIDIA强调的生产力的“可控”。

已经有人用Stable Diffusion和AI PC赚钱了
我们在活动现场和数字艺术家 & 策展人的土豆人Tudou_man 聊了聊——他借助Midjourney, Stable Diffusion, Stable Video Diffusion, Deforum等工具,为包括麦当劳、奔驰、雅诗兰黛、联想等品牌制作宣传概念图与视频。
可以说土豆人Tudou_man就是个典型的AI数字艺术家,他创办工作室的主要业务方向全都着眼于AI。在给我们展示商业作品时,他说以前一年做2-3个品牌的合作就已经是极限了,还需要跨团队合作;现在1-2个人,1年时间能就能和20个品牌合作。

像上面这张上海武康大楼戴围巾的平面作品,他的AI创作流程大致是这样的:首先去现场实拍与采集;再藉由Midjourney之类的工具去尝试生成建筑戴围巾的素材——完成“调性和基础材质引导”;再通过Photoshop执行基础形象拼接;
随后进入到Stable Diffusion工作流,进行成百上千次的结果迭代。迭代过程包括“修改提示词、图片引导、ControlNet引导”(* TensorRT新版现在也支持ControlNet加速了),“中间结果可能还需要进入Photoshop做手动调整”。
这工作流,还真是端云AI结合的典型...... 而“传统的创作过程涵盖了创意发想、草图、讨论,到小稿、精修、完稿等等一系列流程。”“有了AI工具之后,这个流程就变成了想法、结果、结果、结果、结果...”“1000遍的结果。”这就是创作工作流的颠覆了。平面作品制作周期大约在两周左右——土豆人Tudou_man说这已经是个慢工出细活儿的过程了。

土豆人Tudou_man作品:左,流光若梦(for Mercedez Benz);右,复写苔原(概念创作,旨在表达AIGC未来的内容产生会像青苔一样覆盖整个世界)
视频方面,在Sora这类逐渐实现了physically accurate/stable的模型普及以前,现阶段AI制作的视频还是具备很明确的AI不稳定性、逐帧千变万化的内容特点(似乎也成为了一种创作风格)。不过似乎品牌商现如今也很赞许这种风格。土豆人Tudou_man给我们展示为奔驰新款车型创作“流光若梦”的视频作品,总共15秒。
这个视频作品的制作“进行了600轮迭代”,“将其中最有价值的片段挑选出来重新剪辑”,“还专门为这款车训练了LoRA的模型,保证相对稳定性。”制作周期大约3周到1个月。土豆人Tudou_man说,工作室的底层硬件是多台RTX 4090并行工作。
 Simon阿文作品:将电影《低俗小说》做AI风格化处理,包括雕塑风、皮影戏风格等…
Simon阿文作品:将电影《低俗小说》做AI风格化处理,包括雕塑风、皮影戏风格等…
除了土豆人Tudou_man的例子,还有活动现场的Blender艺术家Simon阿文很早就用Disco Diffusion画贴图,用于3D模型;到后续直接借助AI转绘,来转换场景风格,不用再借助AI贴图;以及将经典电影场景,借助ControlNet和AnimateDiff做风格转换;甚至还有像IPAdapter这样的工具,不需要再藉由LoRA做训练,输入一张图,模型就能理解图片风格...
这些受限于篇幅就略过不做详谈了。
不过上述案例基本串联起了NVIDIA PPT中提到“支持最先进的SD工作流”的主要关键词。NVIDIA之所以有底气说,只有NVIDIA做到了AI PC的生产力“可控”,以及高质量的生产力,就在于CUDA与NVIDIA AI生态的高度成熟,目前还是其他竞争对手难以比拟的。所以绝大部分需求高算力的AI应用,开发之初着眼的原生硬件和平台就是NVIDIA GPU和AI平台。
这是几名参与活动的AI艺术家,都提到的用GeForce RTX显卡跑AI应用、做创作在算力之外,“更稳定”的根源。
“好的生产力,需要强大的生态支持。”NVIDIA产品经理说,“我们刚才看到的实时绘画、肖像生成等背后所有的软件、工作流,都能够无缝运行在CUDA和RTX AI生态上。这个生态在行业中是独此一家的。”
简单来说,即便看起来只是任意拍张照,后结合证件照模板,就能立刻生成个人的“影棚级”证件照这样一个简单的AI应用,其下层都对应了复杂且成熟的软件层级,对AI模型开发者而言则意味着成熟的开发生态...现如今的RTX AI PC也就不是一夕之功了。

AI肖像模型InstantID展示,目前在Github拿到9.8k stars,模型作者:王浩帆
现在还只是个开始,AI PC会深入到工作流
NVIDIA曾在不同场合表达过,早在2018年为Turing架构GPU加入Tensor Core之时,那时搭载RTX显卡的PC就已经是AI PC了。因为最初用在游戏里的DLSS技术,其中就有AI模型推理的过程;Tensor core是专用的AI加速单元。
不单是DLSS,那时Transformer还没有现在这么火,各类网络结构都还争相发展之时;当时就“已经有很多设计师、艺术家用AI来辅助工作”,CV领域很流行的AI语义分割、图片识别、对象分类就已经在发挥作用了。前文提到Adobe、Autodesk等的商用工具其时也已经在集成不同的AI特性。
而生成式AI是在此基础上“更进一步”“提供全新的可能”,“超出原有工具的能力之外”。就像土豆人Tudou_man提到从传统工作流到Stable Diffusion创作“想法→结果→结果→结果→…”的转变。
很自然的,和NVIDIA合作了好几年的火星时代在这次活动上发布了《NVIDIA TensorRT Stable Diffusion创作加速指南》,着力于让更多创作者能够借助生成式AI来实现“商业创意落地”,约等于零基础学Stable Diffusion以及TensorRT加速(据说有了TensorRT加速,现在上课两小时能讲4、5个设计案例,以前撑死讲3个…)。
这本指南具体到怎么用Stable Diffusion做海报设计、电商设计、插画设计和室内设计——看看,我们还在谈论SD究竟有什么用的时候,人家都拿来做“商业落地”了。
从NVIDIA的角度来看,这属于AI PC商用的配套周边。火星时代的教研老师说现阶段Stable Diffusion在某些相对复杂的设计领域,还只能用来产生效果图。就像前文提到建筑设计的前期创意方案。
生成式AI和AI PC现阶段要深度参与设计行业更多阶段,“后面(的步骤)暂时有难度”,但“AI交互工作流的影响程度在不断加深”,“我相信未来我们只需要负责创意和想法,AI就能够完成其他的事情。”“除了我们列举的这几个商业场景,在整个CG领域,还有很多可以被AI加速的,比如工业设计…”
感觉NVIDIA对自家RTX AI PC的定位还是非常明确:高性能需求的娱乐、高性能需求的工作——这本来就是GeForce RTX显卡以往图形渲染时代的定位,只不过现在特别强调了AI加速属性。后者与前者的差异在于,AI可是NVIDIA占尽生态优势的绝对主场。

最后还是引用今年GTC 黄仁勋在分析师沟通会上提到的一个有趣观点:如果说万物皆可数字化(digitalized),那么万物就都可token化(tokenized)——token是生成式AI常用的一个术语。与ChatGPT或者Llama 2对话时,它们生成的词就可以认为是一个个token。
除了文本、图像之外,“其实我们还数字化了很多东西,包括蛋白质、基因、脑波等等——只要我们理解其结构,或者从中抽象出特定的模式,能够理解其内涵,就能做数字化。”黄仁勋说,“那么或许就能够对它们做‘生成’了。这就是生成式AI革命。”
生成的“token可以是化学、医疗、动画、机器人、3D图形”,“如果我们能够生成文本的下一个token,那就能生成图像、视频、机械臂的下一个token。”所以机械臂能在工业领域智能决策自己该怎么做。则原本那些需要由人类预先编码录入好,再去获取的模式就会被取代。他甚至认为,会有个特定的行业是专门生成token的,就像第二次工业革命以后的发电厂一样。
这个说法听起来还相当疯狂,但我们引用这段话的意思是,虽然这次NVIDIA列举的RTX AI影响范畴主要在图形、图像、设计领域,但随AI PC深入发展,AI深入到工作流更多步骤中,AI也将横向扩展至各行各业。
AI写代码已经是日常,视频创作是下一波热点,医疗领域药物发现已经在全面普及生成式AI…这些分支应用都会有跑在AI PC上的组成部分:就好像文首提到企业用NIM做个芯片设计助手,跑在员工的PC本地。
对于不同行业的AI潮流来袭,我们更多应该抱持的是接纳、拥抱的心态。就像土豆人Tudou_man和Simon阿文说的,最初见到生成式AI的能力很震惊、很焦虑,于是成为“第一波被AI打倒的人”,“打不过就加入”,去“发现变化、适应变化”。
最后的最后,简略更新本次AI PC品鉴会的另外几个发布:
- ChatRTX(支持RAG的本地聊天机器人)新增对于中文大语言模型ChatGLM3-6B的支持;新增对于CLIP模型的支持——基于文本对话就能进行本地图片检索;而且现在可以直接用语音输入(支持Whisper模型)。
- NVIDIA ACE(游戏NPC能和玩家直接语音对话的技术)展示了一个新的demo(名为Convert Protocol)。这次的demo相比此前拉面店demo,有着更完整的解谜逻辑,基于与多个NPC对话及游戏中的线索完成解谜…关注电子工程专辑微信视频号,我们会对该demo做简单展示…
- 另外,好像每次活动NVIDIA都要强调,Gaming仍是他们持续发力的业务,所以DLSS也是每次必展示的,近期主打的是支持DLSS 3.5光线重建的游戏。
- 生成式AI与图形渲染/游戏相交的,还有个很热门的技术RTX Remix,用于DX8/DX9的老游戏MOD制作,可以给老游戏加上光线追踪、DLSS;生成式AI主要体现在能够基于原游戏建模和贴图生成高分辨率的材质…
