
在英伟达建立起数据中心AI霸权地位以后,我们一直非常好奇,在数据中心处理器出货量上占据最大市场的Intel是怎么看的——或者他们打算以何种方式来应对现如今的格局。
因为现实就是,加速器正在蚕食通用处理器原有的市场价值。所以Intel这些年一直在以CPU为基础,推XPU策略,各类加速器也都提枪上马。但这还不够,因为加速器不是Intel的主场。
我们说英伟达在AI HPC市场的成功,根源不在GPU本身,而在于生态。英伟达HPC和AI全栈工具的成熟度、完整度几乎难逢敌手。所以起码在AI HPC市场上,一切其他竞争对手都应该考虑的绝对不是按照英伟达走过的路再走一遍。
过去两年Intel开始强调软件的重要性,也开始向媒体传达软件方面的大力投入。从中大致可以看出,Intel的应对策略是借助自己的XPU和内部软件投入,外加开源开放的力量,来尽快补齐短板。尤其以制定开放标准、共建生态的方式,和其他合作伙伴联合起来,获得与英伟达一战的实力。
这算是个常规思路。所以这一年多我们看到oneAPI可以for NVIDIA GPU, OpenVINO可以部署到Arm平台,还真的算是把开放的思路落到了实处...

很自然地,今年Intel Vision媒体预沟通会上,我们听到最频繁的的几个词组包括“open ecosystem(开放生态)”、“open standard(开放标准)”、“choice(选择)”、“without vendor lock-in(不锁死在一家供应商,英伟达:???)”...大致上就是这个思路…
基于这样一个基本思路,这次除了发布新的Xeon 6处理器、Gaudi 3加速器面向的数据中心与企业AI市场,有关生成式AI时代的到来,Intel还谈了三个关键:(1)软件很重要,开放的软件生态更重要;(2)发挥AI能效,要从系统层面着手——所以这次也强调了networking的重要性,甚至宣布了新的AI NIC;(3)边缘AI也很重要——包括AI PC;
基于这次Intel Vision活动,我们仔细谈谈Intel打算以怎样的方式在AI时代挑战英伟达。本文仅基于活动之前的媒体预沟通会——Intel Vision期间,Pat Gelsinger(Intel首席执行官)会发表主题演讲,后续我们还会参与媒体采访,更多内容我们还将做进一步的报道。提示:这篇文章也不会把重点放在新发布的Xeon 6 CPU和Gaudi 3加速芯片上。
思路是要开放、不要“专制”
Sachin Katti(Intel高级副总裁、NEX业务总经理)分享来自IDC的数据,预计到2026年全球80%的企业都会使用生成式AI;2027年企业在生成式AI上的开销,预计会是2024年的3.8倍,达到1510亿美元。
但现在的问题是,大量企业面对内部的“非结构化数据(unstructured data)”——或者说无序数据,并不清楚如何部署生成式AI——不管是面向企业内部,还是应用到产品中;更进一步的,还有如何在安全性、可靠性上令诸多现成的LLM大语言模型达成企业级应用——企业专有数据的隐私性、模型幻觉问题如何解决都很重要。
Sachin还补充了一点:“现在(的方案)没有开放性。现在企业可以获取到垂直整合的解决方案,但没有选择性可言。硬件和软件层级都绑定在一个解决方案中,企业无法对客户做定制。”这明显就是在说英伟达——英伟达的整套方案,是自下而上完全端到端,且自有生态的。

Intel认为,现在“企业数据”和“AI模型”整体上是割裂的。现在的目标应该是把这两个东西真正接合起来。如此才能达成真正的“企业AI”。
从需求上来看,企业是要“可触达、有选择余地(三番五次强调...)、提供保密性的计算基础设施”,这样的基础设施还需要能够形成可弹性伸缩的系统——不同规模的企业才能选择到自己所需的系统,“而不是被迫采用一种完全垂直整合、他们根本就不需要的系统。”真正有价值的系统“应该是有参考基准的(reference-based),这样一来不同的合作伙伴才能联合起来构建系统”,“这不应该是个仅来自一家供应商的方案。”(英伟达再次满脸问号)
基础设施之上的软件,尤其是AI软件也必须是安全、可信、可靠的,“如此,企业在内部部署AI,才能确保不会出现模型幻觉、结果偏差等问题,企业自己也可以做调整、检查和改变;只有这样,企业才有信心采用AI技术”。

最后,从整个应用生态的角度,仍然是“我们需要开放的生态系统”,“ISV(独立软件开发商)、GSI(全球系统集成商)等角色能够将这些软件组件组合起来,为企业构建定制化的解决方案,在企业内部加速AI”。
安全、可靠、保密、可管理与透明之类的属性对企业而言都只能说是基本款,参与企业产品竞争都必须满足这些。它们也不光是AI进驻企业市场的必备条件,应该说是所有产品为企业所有的必备条件。所以我们认为,Intel在此要强调的关键还是“开放”,包括软件生态的开放、基础设施层面的开放、应用的开放...
所以Intel打算这么搞
思路有了,接下来的问题就是Intel具体打算怎么做了。下面这张图对应了Intel Enterprise AI在上述每个层级的部署或看法。
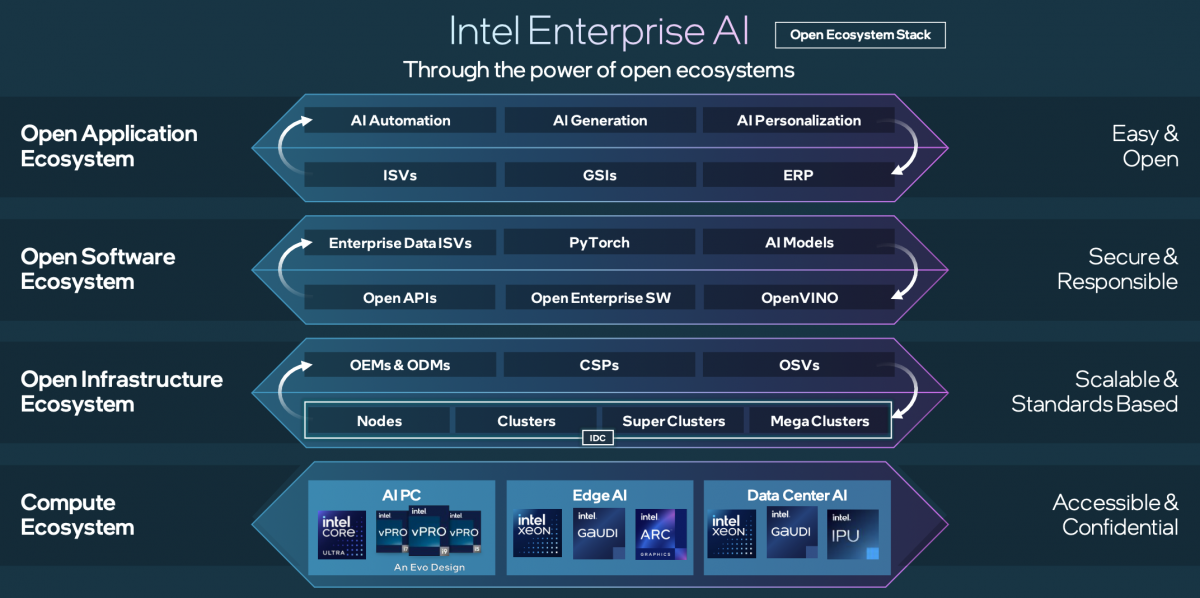
最底层当然是Intel处理器产品——既是维系上层的算力基础,也是芯片厂商赚钱的根本。在面向基础设施时,尤其是面向数据中心,底层提供算力的硬件会以节点、集群的形式面向上层。这部分的工作主要是OEM、CSP云服务提供商、OSV操作系统供应商要做的。
再往上的AI软件生态,Intel认定PyTorch框架会是未来企业构建AI的绝对参照基准。这个层级当然还有Intel的OpenVINO。对Intel软件熟的同学应该知道,这是个AI推理部署工具。
OpenVINO虽然主要是Intel发起并维护的,不过它也是个开源项目——前文也提到了OpenVINO现在还支持Arm处理器。在Intel的AI生态里,OpenVINO显然是部署AI的软件基础,从数据中心到AI PC。此外,这个层级当然还涵盖了各种各样的AI模型,从几十亿到上万亿参数规模的不同模型。
最上层是应用层,需要ISV, GSI之类的角色去做各种AI应用和解决方案。
回顾英伟达在这些层级对应都有些什么,会发现英伟达以一己之力涉足了上述所有组成部分的构建。做芯片不用多说,英伟达自己也是搭建系统的OEM,往上是AI训练、推理的中间件、各种库、预训练模型更是英伟达的杀手锏,甚至在应用层英伟达都做了很多东西——即便大部分还是提供给ISV做API引用的。
所以不难理解,这张图为什么处处写着“open(开放)”。Intel甚至在谈到软件生态这一层的时候,特别说“我们也和整个生态系统协作,确保无论行业想采用什么样的开放标准,用户都有选择”。
细究企业AI软件栈,怎么和CUDA竞争…
具体到上述全栈结构的软件层,Intel把这一层的结构细分成下图这样:

近两年对Intel多有关注的读者对此应该不会陌生。最底下的芯片和硬件产品之上的最低层级是oneAPI——它在角色上类似于CUDA,提供了包括优化kernel, 通信库之类的基础。oneAPI作为UXL Foundation的一部分,是得到了谷歌、高通、Arm等企业的支持的。
应该是从某个大版本开始,PyTorch就集成了oneAPI的深度神经网络库(DNN library)。Jeff说今年晚些时间,会有相关原生PyTorch优化支持Intel加速器的发布。
所以再上一层,模型开发围绕PyTorch生态——Intel认为PyTorch是这类框架de-fragmentation(去碎片化)之后的未来。当然,OpenVINO作为AI的推理和部署工具也是Intel这些年在努力推广的。据说过去3个月OpenVINO的使用率提升很快,今年Q1的下载次数超过了100万次。这一点估计和AI PC的推广有很大关系。
这些是Intel推广AI生态的基础,对Intel来说也异常重要——它们的成败与否,基本就直接决定了Intel在AI时代能否站稳脚跟。

基于Intel在软件生态构建上的现有资源,在预沟通会的答记者问阶段,有人问Intel拿什么和英伟达CUDA生态竞争。Intel从两个层面回答了这个问题,笔者个人感觉还是挺精彩的。
第一还是在于开放。Sachin说从模型开发者的角度,模型训练上,“我们支持PyTorch,PyTorch是开放的”;“而在PyTorch之下,的确有很多开发者选择来自单一供应商、专用的CUDA”。
“但行业正在朝着寻找替代方案、更多选择的路子上走,典型的比如Triton(由OpenAI开发,也用于GPU编程);要确保能够以开放的方式、像是用MLIR,让所有的kernel跑起来。”Sachin表示,“我们想要确保我们的软硬件都是开放的。”
从模型用户的角度(主要是指AI应用开发者,和企业用户),“他们将模型部署、融入到他们的应用中,获取模型是第一步,然后是部署到不同的硬件上。OpenVINO让这个过程变得很方便,它是开源的,既能部署到Intel平台,也能支持基于Arm的平台。”“没有限制(no lock-in),基于他们的硬件选择,软件栈是开放的。”
还有个回答来自Jeff McVeigh(Intel副总裁、软件工程团队总经理),他是从另外一个角度回答的这个问题,先是提了一下Intel oneAPI的重要性,以及它是支持跨架构开放规格的开放平台。另外“如果我们去看软件栈的下一个层级,像是OpenVINO这样的inference runtime,大概95%的开发者和数据科学家都工作在这个层级或更高层级。”
“只有很少一部分人是工作在CUDA或者oneAPI层级的。这个层级固然在优化和支持上非常重要,但毕竟会需要用到它的开发者少。”Jeff说,“而且我们认为,未来这部分群体还会变得更少。”“尤其现在随着抽象层接入,Triton语言、MLIR能力、各种编译基础,实现跨架构更广泛的支持,编程模型更低层级的角色不会那么重要。”
这个问答我们觉得还是挺在这次探讨的点上的,具有相当的代表性,对于表达Intel的态度也十分关键,所以此处花了比较多篇幅做呈现。
这番回答也部分强调了开放生态的重要性。不过有关软件生态构建,前文已经提到,企业遭遇的问题还在于专用的、私有非结构化数据如何利用,AI模型的安全性、可靠性、模型幻觉等问题。会上谈到有关处理器层面 Confidential Computing 之类的问题(Intel Trusted Domain Extensions)就不多谈了,这在企业应用中都算是必然。
对于企业数据的AI利用,Intel的答案似乎是RAG(检索增强生成)。RAG的确已经在很多积极利用AI技术的企业间成为了标配。其实在前不久的GTC大会上,英伟达就提到过RAG更像是企业前期采用AI技术的PoC(概念验证),因为RAG相对简单、低成本。
Intel则认为现阶段企业AI应用的关键就是RAG,“检索(retrieval)就是处理企业数据、非结构化数据,解决如何将这些数据放到模型里去的问题。”Jeff甚至认为,RAG目前在企业AI市场所处的位置,和当年针对container技术有专用、也有开放解决方案时期的Kubernetes很像。
不过对于RAG和fine-tuning而言,包括embedding、矢量数据库(VectorDB)、Prompt Engine、Safety Guardrail等在内的构成和组合还是很复杂。

这次Intel发布的重点之一,应该也在于将各组成模块,放到RAG解决方案中去的参考系统。 “市场上已经有了专用解决方案,可以做到端到端部署”,“是来自单一来源的解决方案,价格高、供应受限。”(英伟达:&*&^!@)
简单来说,是把“RAG, fine-tuning和其他综合AI管线的碎片化组成部分都放到一起,加速企业AI部署”,“解决关键需求,利用基础设施高效部署,与企业软件栈整合,以高度可靠性、可用性为基础,并且还要支持多架构,确保解决方案的可信与弹性可缩放”。
从预沟通会来看,Intel应该是为此搭建了某些开放框架,或者说“可伸缩的系统策略”。不过会上没有透露太多,Intel Vision活动举办的这一周时间会有更多相关资讯放出。其中核心还是强调“开放”,以及企业“有选择”,不管是硬件还是软件。
而且问答环节Sachin说Intel的确计划引入端到端的系统参考设计,“包括通用和加速计算两者”,涵盖了“networking、内存、软件”等构成,而且是“经过了验证的参考设计”,“和生态一起合作,解决如何为不同行业、不同企业定制、分发的问题”。
处理器之外,要考虑系统角度
这次发布的处理器产品并非本文要谈的重点,这里稍微提几句:包括新发布5nm的AI加速芯片Gaudi 3,FP8算力提升2倍,BF16算力提升4倍,网络与内存带宽分别增加2倍、1.5倍。
Gaudi 3加速卡在宣传上也是专为生成式AI打造,Intel称对比英伟达H100,其LLM模型训练时间快40%,推理则快50%。加速卡今年Q2面向OEM供货,目前至少有Dell, Super Miro, 联想, HPE等OEM会有产品推向市场。
Das Kamhout(Intel副总裁,数据中心与AI团队高级首席工程师)在谈到这颗芯片时也不忘强调用Gaudi 3更开放,用户选择更多…因为“有各种基于以太网的交换选择”(英伟达:!!!)。

处理器相关的,其次是发布Xeon 6 CPU。新发布的Xeon 6处理器有采用E-core(Crestmont)的产品,代号Sierra Forest,Q2出货。宣传中说,它带来2.4倍的每瓦性能提升,E-core的面积效益令机架空间得到2.7倍缩减。Xeon 6也有采用P-core(Redwood Cove+)的产品,代号Granite Rapids,产品发布时间相比Sierra Forest会稍晚。
仅从芯片角度出发驱动以AI为代表的现代应用是不够的。比如英伟达Blackwell 30倍性能提升,其中相当一部分都不是单纯靠芯片。构建起系统,消除其中各环节的瓶颈才是性能和效率大幅提升的关键。
Intel也早就意识到了这一点,否则Intel Foundry也不会强调自己是System Foundry。有关“系统”的发布,除了前文提到Intel考虑做系统参考设计,这次的沟通会也把较大篇幅放在了networking上——这些年,networking已经成为英伟达构建AI系统的绝对强项,英伟达在networking上的技术投入已经超过10年。

不过可能在Intel看来,10+年根本就不算什么,想当年以太网标准构建都有Intel的参与。所以Sachin不出意外地强调了对于构建AI networking,继续推进基于以太网的开放标准,而且是“取代InfiniBand”。与此同时,“用开放标准的高速SERDES来取代专用的Scale-Up links”。感觉再说下去就是“取代英伟达”了…
我们猜测,Intel后续会有相关高速数据传输与数据交换标准推进的新动作(或许本周内就会发布)——毕竟现在的标准其实很难说“取代”。
产品层面是今年年底之前Intel的IPU就要来了。Sachin说,IPU“会是非常成熟的适配器产品,赋能企业构建小型到中型的AI系统集群”;合作方面Google Cloud会在年底部署IPU,IPU将成为Google Cloud最新一批云实例的基础设施。

另外更重要的是,Intel宣布了AI NIC产品(网卡,Network Interface Controller),芯片层面是个ASIC。AI NIC应该是一个新的产品类别,采用来自UEC(Ultra Ethernet Consortium)的网络开放标准,“专为大规模AI部署打造”。
简单来说,AI NIC是扩展多CPU与GPU的networking fabric解决方案,让大规模的AI训练和推理更快更高效。只不过AI NIC的到来要等到2026年——这个动作就有点慢了。Intel的说法是,AI NIC届时将提供AI系统所需的“最新的(latest)”速度,与此同时还是开放标准(看这个PPT上又写着“选择”),由生态的标准来驱动产品…
最后,结合边缘和端侧的优势
受限于文章长度, Intel主场的AI PC与边缘AI此处就不花太多篇幅了,毕竟我们之前探讨AI PC的文章真的够多了。
如此前我们撰文提到的,英伟达虽然也在推AI PC,但鉴于加速器类型的芯片在端侧的市场价值问题,英伟达很难和Intel正面竞争。Intel预期2025年底以前,要向市场输送1亿AI PC;与100+ ISV合力建设生态;其中70%以商用的形式促进企业生产力推进…
PC之外的行业边缘市场,如零售、物流、通信、医疗健康等也要普及AI。预计到2026年超过50%的边缘部署会跑AI。不过这部分市场驱动AI推进的处理器类型可能主要还是CPU(不考虑主流嵌入式应用的话),很多场景根本就不需要加速器介入。所以这仍然是Intel主场。
有关行业边缘,今年MWC上Intel就发布了Edge Platform边缘平台,用于企业开发、部署、运行和管理边缘基础设施、应用。OpenVINO也作为其中关键给到了边缘的AI应用。这里反复强调的仍然是“选择”和“开放”…

不出意外,Intel也面向Edge Platform发布了新的处理器产品,涵盖Atom、酷睿和酷睿Ultra(PS系列,如上图),以及面向边缘的Arc GPU——这原本是面向PC市场的图形卡,据说Intel会提供额外的软硬件能力,方便在边缘做AI模型的部署和加速。
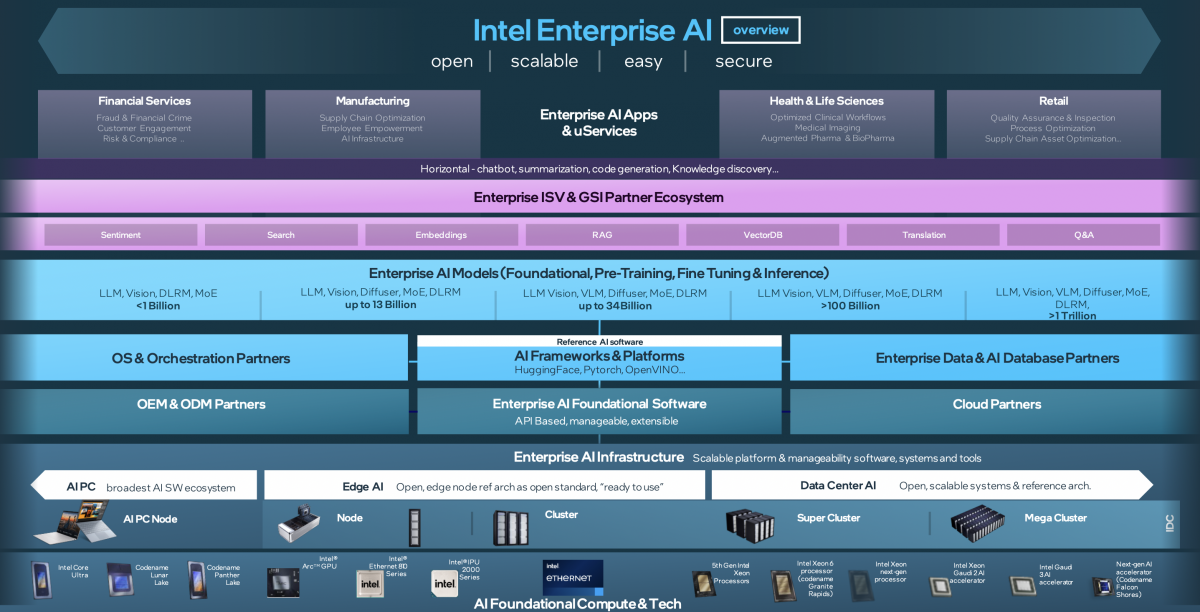
结合上面这张Intel的企业AI全栈布局图,这篇文章我们谈到了针对生成式AI时代,Intel的处理器和加速器;上层的软件栈构建;以及从系统层面——尤其networking——着眼AI基础设施部署;还要加上潜力巨大的边缘和端侧AI;和最最重要的,贯穿始终的“开放”方式。
Sachin概括的一句话是:“系统级的;开放选择;与生态合作伙伴共同为企业提供使用AI的工具”。在我们看来,今年的Intel Vision更像是Intel的企业AI策略宣导;框架思路很正确,其中细节还待Intel做持续填充:不管是为企业打造部署AI的完整模块示范,打造可弹性缩放的AI企业解决方案,还是树立跨多CPU/GPU、跨系统、跨节点的数据交换和networking新标准。
Intel认为,现在正是布局这盘棋的大好时机,因为已经开始用生成式AI的企业还不多;唯有基于企业自己现有基础设施,以及现有的ISV和生态,在此基础上给他们提供不同的开放选择,而不是做一整套新系统的投入,而且还是锁定了一家供应商的方案,才是这一战的取胜之道。这个逻辑对不对呢?且看企业接下来都会怎么选吧…

