
继2018年推出第一代Versal自适应SoC之后,日前,AMD宣布推出第二代Versal AI Edge系列和Versal Prime系列,前者面向AI驱动型嵌入式系统,后者则面向经典嵌入式系统。按照AMD自适应与嵌入式计算事业部(AECG)Versal产品营销总监Manuel Uhm的说法,“两代产品定位不同,彼此间并没有交集,属于互补性质。”
不得不提的ACAP
谈到Versal,就十分有必要先回顾一下曾经的赛灵思在2018年推出的全新产品类别——ACAP(Adaptive Compute Acceleration Platform,自适应计算加速平台),毕竟Versal是行业首款ACAP架构产品。
ACAP是一个高度集成的多核异构计算平台,能根据各种应用与工作负载的需求从硬件层对其进行灵活修改。其研发周期历经四年,累积研发投资逾10亿美元,有超过1500名软硬件工程师参与该项目的设计,公司上下对其寄予了极高的期望。

从当时公布的结构框图来看,ACAP平台结合了分布式存储器、多核SoC、高度集成的可编程I/O、SerDes收发器技术、前沿的RF-ADC/DAC、集成式高带宽存储器(HBM)、以及一个或多个软件可编程且同时又具备硬件灵活应变性的计算引擎(DSP/AI等),并全部通过片上网络(NoC)实现互连。软件开发人员既能够利用C/C++、OpenCL和 Python等软件工具应用ACAP系统,也能利用FPGA工具从RTL级进行编程。
Versal的名字来源于两个词,一个是多样性,一个是通用性。第一代产品组合包括Versal基础系列(Versal Prime)、Versal旗舰系列(Versal Premium)系列和HBM系列。此外,还包括AI核心系列(AI Core)、AI边缘系列(AI Edge)和AI射频系列(AI RF)。
一些指标性的硬件架构包括采用台积电7nm FinFET制程工艺、集成双ARM Cortex-A72应用处理器和双ARM Cortex-R5实时处理器,等等。另外,赛灵思还引入了革新性的引擎——平台管理控制器,可对整个器件进行控制,可满足自上而下的设计,实现软件的可编程。
2020年推出的Versal Premium是当时业界带宽最高、计算密度最高的自适应平台。其系统逻辑单元从最小160万个到最高740万个,自适应引擎LUT数量从最低72万个到最高340万个,可提供比主流FPGA高3倍的吞吐量和2倍的计算密度,并内置以太网、Interlaken和加密引擎,专为在散热条件和空间受限的环境下运行最高带宽网络,以及那些需要可扩展、灵活应变应用加速的云提供商而设计。
揭开第二代Versal的神秘面纱
Manuel Uhm将AI驱动型嵌入式系统的处理阶段分为三段:预处理—AI推理—后处理,并指出,“AI为高度受限的系统带来了更高要求的工作负载,因此,只有三个阶段都在高性能嵌入式系统中进行加速,才能获得真正的全系统性能。”
但目前实际的系统构建思路,是在“预处理”阶段采用FPGA和SoC进行优化,在“推理”阶段使用矢量处理器SoC,在“后处理”阶段使用高性能嵌入式CPU。也就是说,其实是“没有一类处理器能够针对所有三个阶段进行优化”的,而且这种多芯片解决方案还带来了巨大的开销—从更高的功率需求、占板面积、内存需求,到更多的安全漏洞、组件报废、设计时间与工作量。
这解释了AMD为何选择在此时推出第二代Versal AI Edge系列和Versal Prime系列的原因——即希望利用下一代AI引擎、全新高性能集成CPU、以及AMD可编程逻辑,为嵌入式系统带来“单芯片智能”,或者说,希望在“单个器件中提供端到端加速”。下图清晰的展示了这一理念。
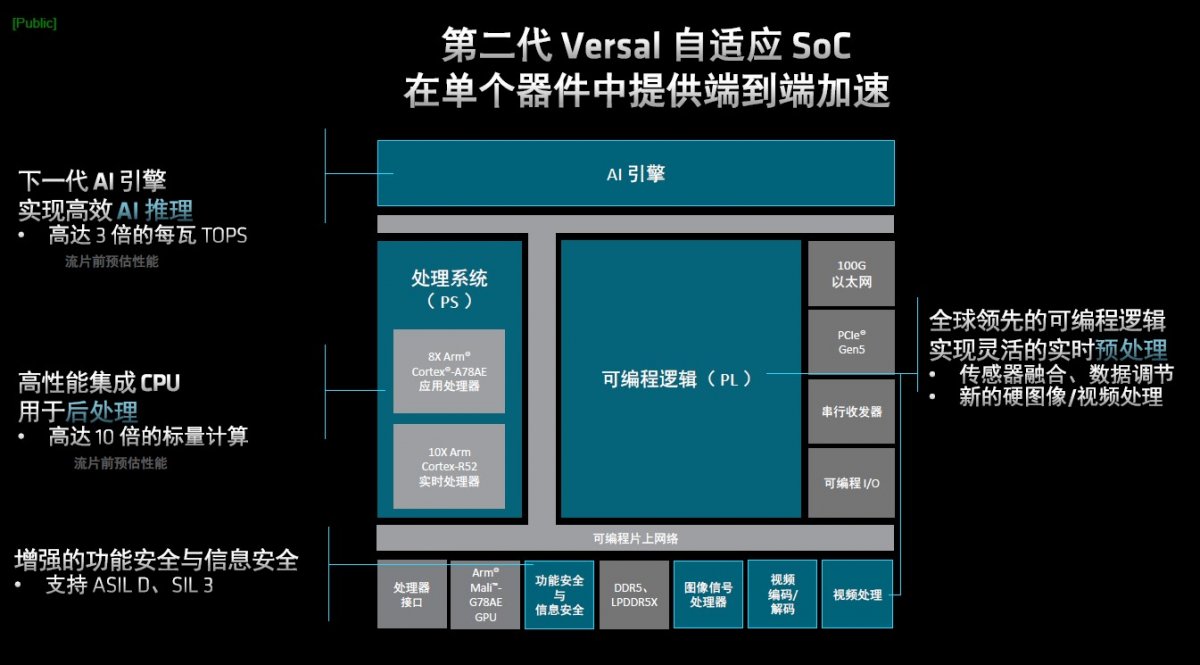
图1:第二代Versal自适应SoC在单个器件中提供端到端加速
不难看出,AMD在第二代Versal自适应SoC中集成了AIE-ML v2 AI引擎,能够实现相比上一代高达3倍的每瓦TOPS性能;可编程逻辑能够实现灵活的实时预处理,尤其是在面对传感器融合、数据调节、硬图像/视频处理时;CPU性能方面,通过集成8X Arm Cortex-A78AE应用处理器和10X Arm Cortex-R52实时处理器,标量计算能力提升10倍;同时,考虑到边缘应用对于信息安全和功能安全有着非常严格的要求,新产品加大了对功能安全和信息安全的支持力度,增加了对ASIL D/SIL 3等标准的支持。
图2展示了新产品为嵌入式应用带来的更高级别的系统性能提升:
- 在L2+/L3 ADAS应用中,由于加入硬图像处理功能,第二代AI Edge系列在具备相近功率资源的前提下,其图像处理能力提升了4倍。
- 在智慧城市场景中,第二代AI Edge系列在为边缘AI设备占板面积带来30%尺寸缩小的同时,却支持2倍视频流,意味着每路视频流占板面积缩小65%。
- 在视频流中,与Zyng MPSoC的效率相比,第二代Versal Prime系列能够为多端口编码与流媒体提供2倍的视频处理能力,使得每路视频流占板面积缩小35%。
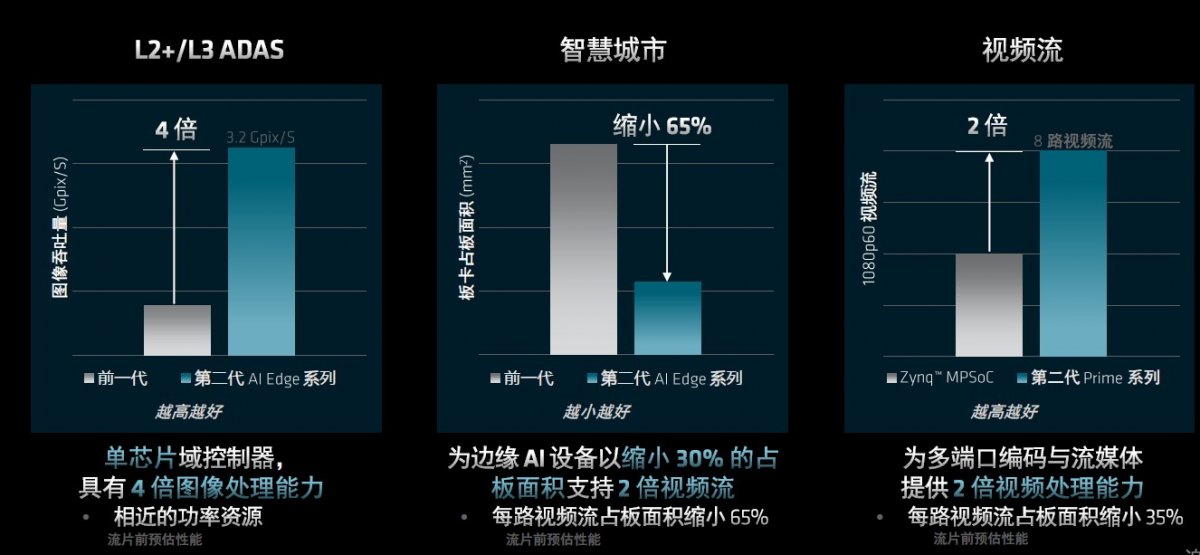
图2:第二代Versal自适应SoC为嵌入式应用带来更高级别的系统性能提升
“在预处理的时候,自适应就等同于灵活性。”Manuel Uhm指出,对客户而言,可编程逻辑最关键之处就在于它可以实时对硬件进行编程,可以适配不同的传感器、IO接口、数据类型,实现硬件的定制化。相比之下,处理器受限于指令集,很难做到这样的灵活性。
从CPU加速到系统中央计算
“我们希望第二代Versal自适应SoC能够成为面向AI驱动型以及经典嵌入式系统的中央计算,而不是更多进行CPU加速,这是与第一代产品最大的不同。”Manuel Uhm说。
以“预处理”环节为例。如果使用基于处理器的方法,面对不同的传感器和不同类型的数据,固定I/O与接口和硬ISP在处理过程中数量有限,缺少灵活性,有时还必须通过外部存储器来实现存储和缓存,导致高时延和低效率。与之相反,当采用可编程逻辑的方法时,这些缺点都将被转变为优点。
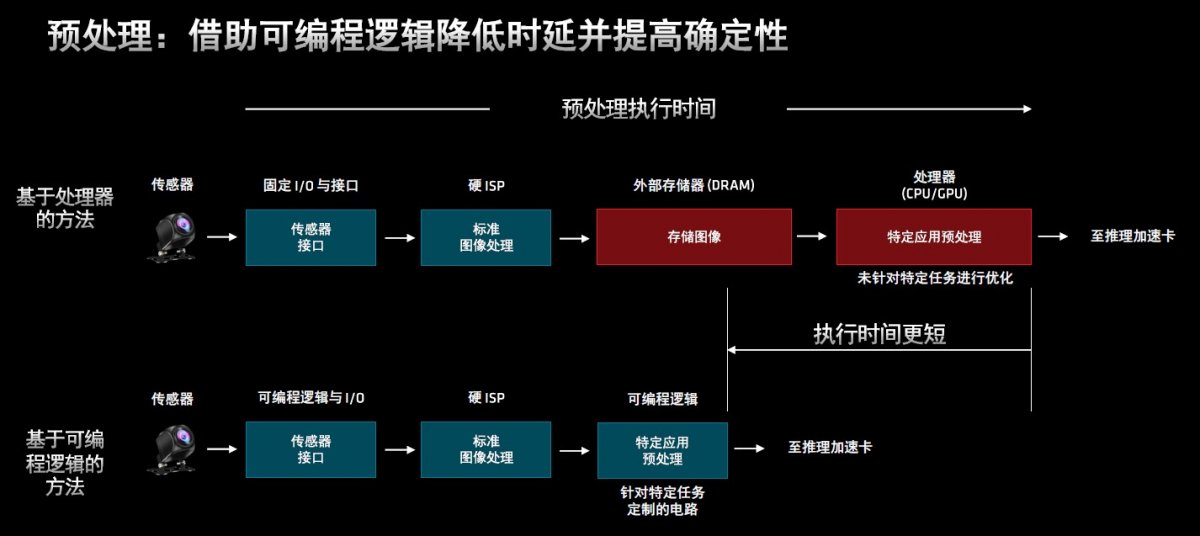
图3:借助可编程逻辑降低时延并提高确定性
进行“AI推理”时也是类似的。与第一代主要通过可编程逻辑来实现AI引擎控制不同,新一代产品的控制处理器包含在AI引擎阵列当中,并且进行了硬化处理,今后AI引擎控制的工作无需交由可编程逻辑处理,富余出来的可编程逻辑资源将被用于传感器和其他数据的处理工作。
为了更好地解决AI推理过程中面临的吞吐量和精度挑战,第二代Versal AI Edge系列器件中的Dense TOPS情况也得到了提升:数据类型是MX6/INT8时,最高端可以分别达到370 TFLOPS和184 TOPS,前者提供了高达60%的每瓦TOPS提升,且具备相近或更高的精度。如果采用稀疏度指标的话,性能还可以再翻番。
同时,为了实现更好更快速的模型部署,AMD通过提供Vitis™ AI开发环境帮助开发者使用原本非常熟悉的开源工具,例如PyTorch、TensorFlow等,在Vitis当中进行优化和推理。

图4:利用Vitis™ AI开发环境实现快速模型部署
最后,再来看一看第二代Versal自适应SoC在“后处理”阶段的表现。如前文所述,新产品可以实现高达8倍的Arm Cortex-A78AE核心,每核心最高频率高达2.2GHz,并且具备高达200.3K的DMIPS算力,为复杂的后处理提供高达10倍的标量算力奠定了基础。针对控制功能的实时处理单元,RPU可以有高达10倍的Arm Cortex-R52核心,每核心最高频率高达1.05GHz,以及高达28.5K的DMIPS算力。此外,增强的功能安全性也大幅减少了对外部安全微控制器的需求。

图5:为复杂的后处理提供高达10倍的标量算力
斯巴鲁EyeSight视觉系统是使用第二代Versal™ AI Edge系列产品的典型案例。双方通过合作,使得下一代EyeSight视觉系统的碰撞前制动、车道偏离预警、自适应巡航控制和车道保持辅助性能得到了进一步的提升。而且,利用可编程逻辑,斯巴鲁还可以实时修改立体摄像头的处理算法,进一步强化了车辆安全性能。
基于摄像头的3D感知视觉流程是另一个案例。根据介绍,在整个模式过程当中,预处理完成之后的数据将被传输至具备3D性能模型(例如BEVFormer)的AI引擎中,然后再用处理器进行行为模式的规划或是其他的实时传感,让单独使用摄像头传感器就可以实现俯瞰的视觉效果,而不必再使用激光雷达。
根据规划,第二代Versal™ AI Edge系列和第二代的Versal Prime系列产品早期试用计划已经展开,早期的访问文档已经发布,目前正与包括斯巴鲁在内的主要客户进行接洽。芯片样片将于2025年上半年发布,评估套件和系统模块(SOM)将于2025年年中推出,量产芯片将于2025年末面市。
