
与EDA一样,IP是芯片产业的上游核心技术,IP的开发及使用有效地降低了芯片开发成本、缩短芯片开发周期、提升产品竞争力,以IP复用为基础的SoC设计成为集成电路行业的重要发展方向。数据显示,全球芯片IP市场规模预计将从2022年的66.7亿美元增加到2025年的100+亿美元。
在IIC ShangHai 2024同期举办的“IP与IC设计论坛”上,国内外IP行业专家均表示,未来,随着物联网、人工智能、智能汽车以及大数据等新兴市场的发展,各类电子设备对数据感知、传输、存储、处理的需求不断提高,市场对IP的需求仍将保持高位。
创新IP赋能超小型端侧设备
生成式人工智能(AI)和大型语言模型正在占据头条新闻,但许多人没有意识到AI已经在嵌入式设备中得到了海量的应用,并且在家庭、城市和工业领域中发挥了重要作用。
安谋科技产品总监陈江杉在演讲中指出,“人工智能对于利用我们产生的大量数据中的智能,以及实现物理世界和数字世界之间更加无缝的交互至关重要。”为此,芯片供应商需要更加努力,以便在小型嵌入式设备成本和功耗受限的前提下,使其获得更多的AI能力。

安谋科技产品总监陈江杉
为此,Arm在此前Cortex-M55/M85的基础上,推出了新产品Cortex-M52,这也是Arm在物联网领域的最新尝试。Cortex-M52此前在中国市场被称为“星辰”STAR-MC2,是一款Arm和安谋科技研发工程团队的合作产品。
Cortex-M52是专为人工智能加速应用设计的体积最小、成本效益最高的处理器,有望为物联网设备提供"增强型"人工智能功能,而无需单独的计算单元。资料显示,这款处理器采用了Arm Helium技术,为Armv8.1-M Cortex-M系列(包括Cortex-M55、Cortex-M85)增加了150条新的标量和矢量指令,是专为人工智能加速应用设计的体积最小、成本效益最高的处理器。与上一代Cortex-M相比,Helium指令可将机器学习算法的性能提高5.6倍,将数字信号处理(DSP)工作负载的性能提高2.7倍。

“我们相信,Cortex-M52将在继续消除ML在最小设备上的采用和部署障碍方面发挥关键作用,通过实现创新和规模化,使每个人都能接触到AI,同时确保开发人员能够继续利用我们广泛、经过验证的软件和工具生态系统的支持。”陈江杉说。
助力Chiplet产品落地
当前,AIGC正在推动算力需求快速增长。数据显示,模型规模每年10倍速度增长,AI系统算力需求每2-3个月翻一倍。由此产生的直接效应是,20年间,算力增长90000倍。然而与此同时,内存带宽只增长了30倍,互联带宽增长了300倍,使得互联与内存成为算力扩展的关键。
奎芯科技高级产品经理王尚元指出,以系统级多颗芯片互连和封装级多颗芯粒(Chiplet)互连为代表的先进集成,正成为当前行业为突破这一瓶颈而采用的主要技术手段。

奎芯科技高级产品经理王尚元
作为一家互联IP和Chiplet产品供应商,奎芯科技希望在这个市场中扮演重要角色。据王尚元介绍,奎芯科技目前拥有LPDDR、PCle、SerDes、MIPI、USB、HDMI、DP、HBM等互联接口IP,以及基于UCIe标准的D2D IP、高带宽内存的HBM3 IP以及高速PCIe4、PCIe5和SerDes IP。
以LPDDR 5X PHY为例,这是奎芯科技最新研发成功的一款高性能内存物理层IP,通过采用全新的架构设计和优化算法,相较于前代产品LPDDR5速度提升17%,延迟降低15%,对5G通信性能、汽车高分辨率增强现实/虚拟现实和使用AI的边缘计算等应用场景有显著的收益提升。
在HBM3国产化落地方面,基于对整个封装供应链的整合能力,奎芯和客户一起打造了一款标准的带HBM3的2.5D全国产封装大芯片。这其中,奎芯提供包含HBM IP、interposer设计、2.5D封装设计在内的完整“交钥匙方案”。
基于这些高速接口IP,奎芯科技还提出了一个基于IP计算体系互联架构方案M2link——通过将HBM/LPDDR的接口协议转成UCIE的协议,组合成标准Chiplet模组,与主SoC合封,以实现降低主芯片成本和封装成本、扩大内存容量和带宽、提升性能等目的。目前,M2link主要包括三种Chiplet方案,分别是跟串型总线的接口相互联的C2IO、跟内存总线相连的C2M以及计算Die之间互联的C2C。
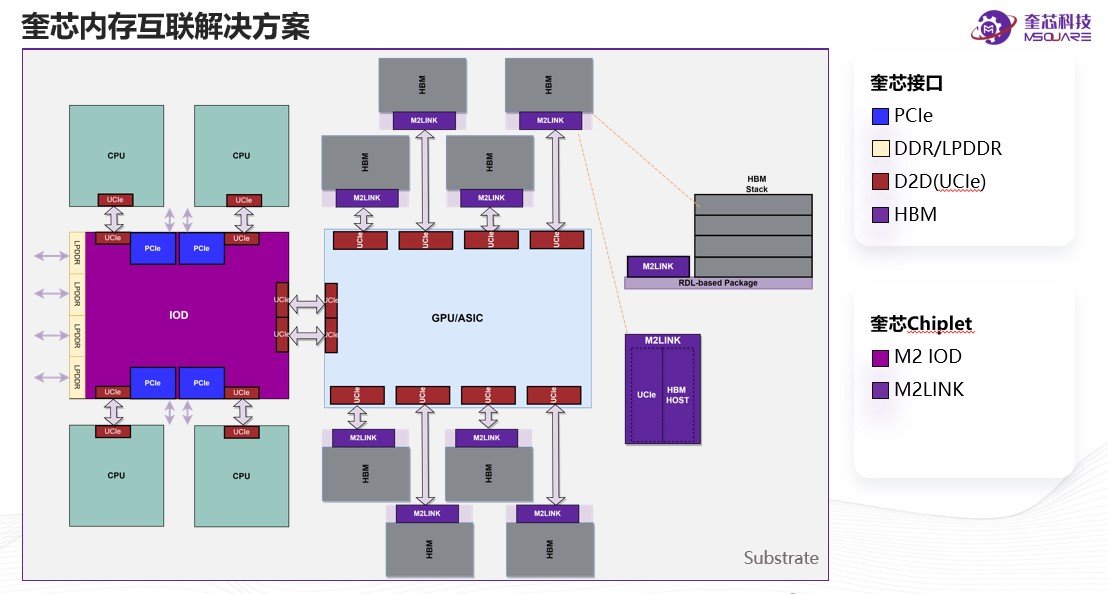
王尚元表示,奎芯科技的愿景是建立一个开放生态的一站式Chiplet服务平台,除了提供IP/Chiplet裸die以外,也可以为客户提供系统设计、封装资源的对接。换而言之,客户只要提供其核心die,以及跟他算法强绑定的一些系统算法,其他一些底层的工作就可以交由奎芯科技来完成。
构建智慧芯片的存储底座
伪静态随机存取器(PSRAM)是一种较为新兴的存储器类型,它具有SRAM的接口协议;相比DRAM,它的内核是DRAM架构,但又不需要复杂的内存控制器来控制内存单元去定期刷新数据。因此,相比传统存储器,PSRAM具备更大的带宽、更高的容量、更低的成本、更小的尺寸和更广的应用。
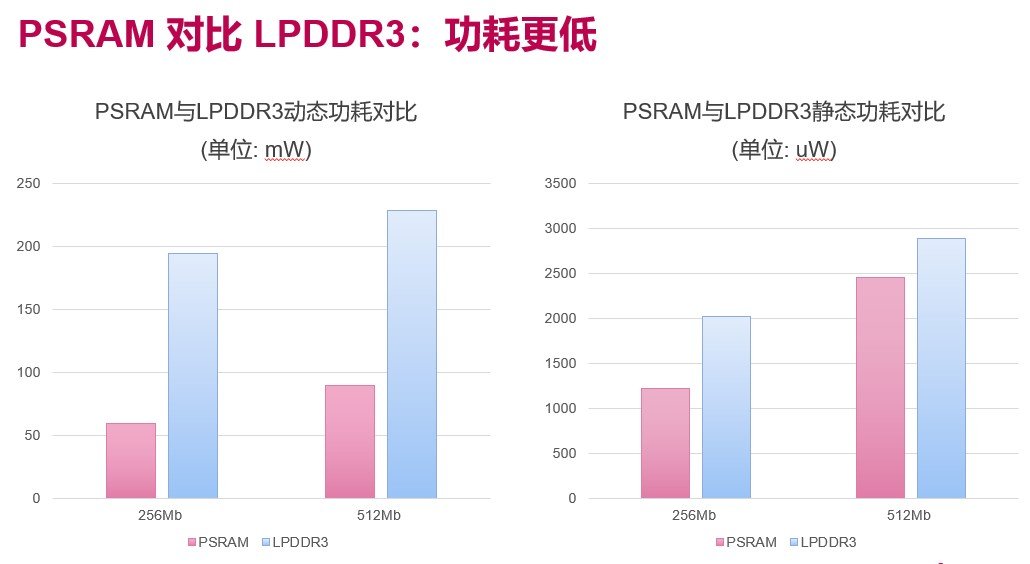
芯思原纯自研PSRAM接口IO解决方案涵盖400Mbps至1066Mbps范围,提供低速PSRAM全数字IP和高速PSRAM数模混合IP,可广泛应用于智能家居、可穿戴设备、汽车电子、物联网、监控等领域。

芯思原微电子销售总监束晨
根据芯思原微电子销售总监束晨的介绍,两款PSRAM接口IO解决方案——高速PSRAM(Max 1066Mbps)和低速PSRAM(Max 400Mbps)综合而言是对DRAM和SRAM的良好折中,弥补了两者之外的市场空缺;凭借低功耗、低引脚数、传输速率适中且性能优良、成本低等诸多优势赢得客户青睐。
接口IP,驱动人工智能技术发展的原动力
种种迹象表明,接口IP市场近年来正成为驱动人工智能技术高速发展的关键驱动力。
芯耀辉销售副总裁何瑞灵在演讲中援引相关机构的数据指出,2023年全球AI市场规模达到了5380亿美元,到2027年预计将达到10000多亿美元,年复合成长率达到19%。与此同时,全球AI芯片市场规模将从2023年的388亿美元,成长到2027年的1150亿美元,年复合成长率达到30%。

芯耀辉销售副总裁何瑞灵
AI高速发展固然令人惊喜,但它对算力的需求非常迫切。从模型算法来说,近些年大模型的参数量以平均每年超过7倍的增速在增长;而从训练所需的算力来看,许多主流模型训练所需的算力也以每年5倍的增速在上升,SOTA训练模型的算力需求每年平均增长超过10倍。
“依靠架构和算法来提升算力正成为一个越来越重要的手段。”但何瑞灵强调称,除了核心算力需要大幅提升外,存储以及各计算节点、模块之间的数据交换和并行计算协同对整体系统算力的提升同样起着至关重要的作用。
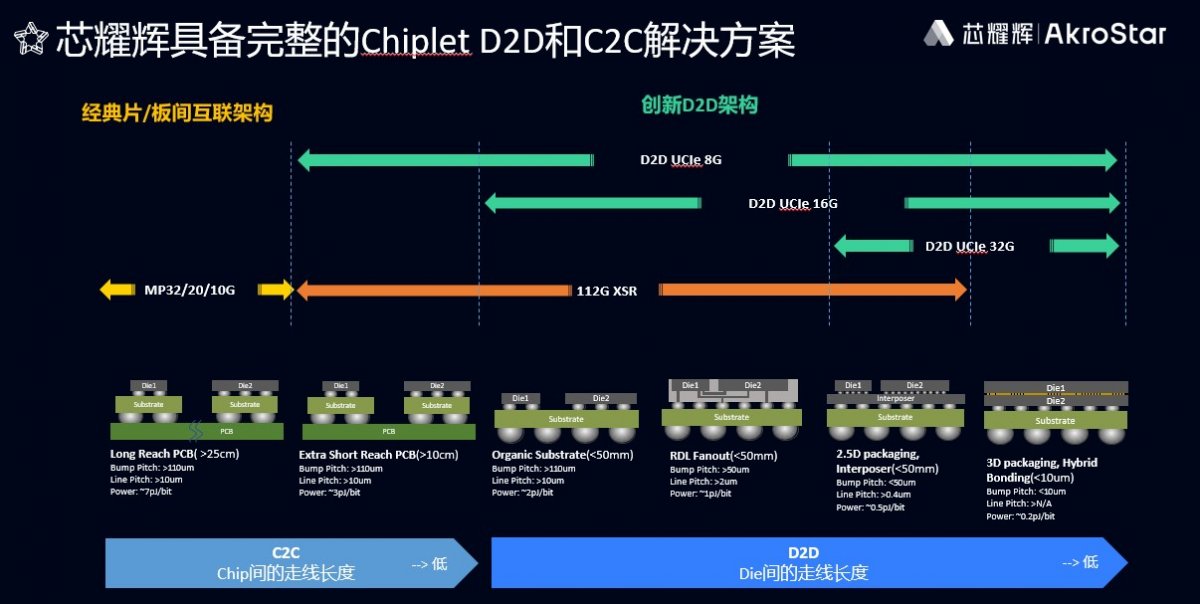
从当前的实际情况来看,具有超高带宽,超大容量的HBM3或者HBM3E是目前解决AI计算芯片存储瓶颈问题的最优方案;在互联方面,多颗算力芯片通过D2D IP互联,形成Chiplet系统,提高系统算力会是首选,而UCIe由于更好的通用性,会成为Chiplet D2D接口的主流选择。
作为国产IP厂商,芯耀辉过去几年实现了先进工艺平台国产IP的全覆盖,积累并充分验证了包括PCIe、Serdes、DDR、LPDDR、HBM、D2D、USB、MIPI、显示相关以及存储相关的几乎全部协议的IP产品,能够满足各类应用的需求,比如高性能计算、人工智能、存储、网络、通讯、汽车电子、消费电子等,并且获得了大量客户的使用、验证和量产。
“我们的IP具有更好的PPA、兼容性、可靠性、技术支持和差异化定制服务,在产品差异化、满足国内市场本地化需求方面也下了很多工夫,能够助力客户的芯片设计项目快速成功。“何瑞灵举例称,芯耀辉做出了业界同等工艺下速率最高的DDR5,解决了客户在次先进工艺上存储瓶颈的问题,并顺利进入量产阶段。
国产可编程逻辑IP核技术助力行业创新
中科亿海微电子科技(苏州)有限公司成立于2017年1月,是中国科学院“可编程芯片与微系统”研究领域的科研与产业化团队,按照国家创新驱动发展战略,发起成立的以“可编程逻辑IP核与EDA工具”为技术特色,以FPGA、自适应SoC、可重构计算系统等产品设计与服务为主营业务的高新技术企业。

中科亿海微总工潘勇
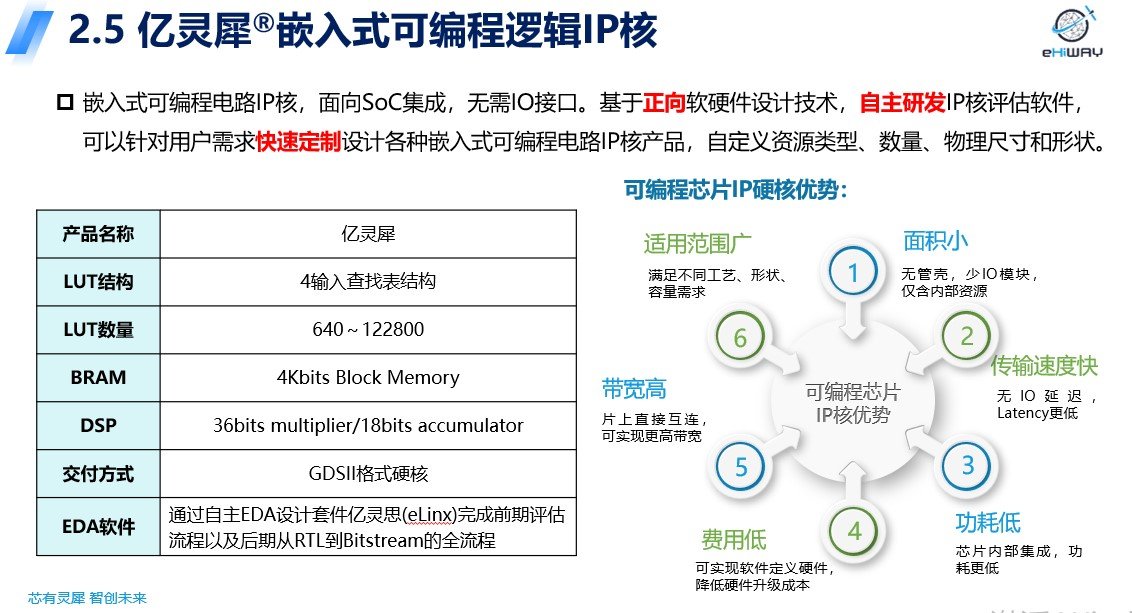
中科亿海微总工潘勇介绍说,目前公司产品包括三大类:可编程逻辑芯片产品、可编程逻辑芯片裸片产品、嵌入式可编程电路IP核产品。其中,亿灵犀(LinkSeas)嵌入式可编程电路IP核主要面向SoC集成,无需IO接口。基于正向软硬件设计技术,自主研发IP核评估软件,可以针对用户需求快速定制设计各种嵌入式可编程电路IP核产品,自定义资源类型、数量、物理尺寸和形状。
当具有硬件可重构特性的嵌入式可编程电路IP核与RISC-V用户自定义指令集特性相结合时,可充分发挥软件可编程与硬件并行处理的双重优势,能够在特定领域、数据中心、人工智能、高速通信、安全加密等数据处理加速方面,为用户提供灵活完整的本土SoC芯片解决方案。
亿灵思(eLinx)则是一款拥有国产自主知识产权的大规模可编程逻辑芯片开发软件,可以支持千万门级以上可编程逻辑芯片的设计开发。eLinx软件不仅可以支持工业界标准的可编程逻辑芯片开发流程,即从RTL综合到配置码流生成下载的全流程操作,而且可以提供面向嵌入式可编程电路IP核定制开发的评估流程,帮助SoC用户定制嵌入式可编程电路IP核资源的规模和排布,并生成相应的芯片数据库,为终端用户提供EDA全流程服务。
基于NoC技术加速优化高性能SoC设计
当前,数据速率提高和功能日趋复杂致使超大规模数据中心、AI和网络应用程序的SoC大小与日俱增。随着SoC尺寸接近占满光罩尺寸,设计人员被迫将SoC分成较小的芯片,这些芯片封装在多芯片模块(MCM)中,以实现高产量并降低总体成本。然后,一个MCM中的多个较小芯片通过die-to-die互连进行链接,常见的片上互连方式包括Bus总线、Crossbar,以及片上网络(NoC)三种。
传智驿芯业务总监伍江华指出,与前两者相比,NoC独特的优势体现在——当片上使用互连的模块数量增加时,互连电路本身的复杂度并不会上升很多,同时NoC的传输层、物理层和接口是分开的,用户在传输层自定义传输规则时,无需修改模块接口。

传智驿芯业务总监伍江华
而且,考虑到异构计算架构SoC中的模块数量,已经从之前的几个上升到了数十甚至数百个,且随着该架构未来得到更多的应用,这类SoC中将集成更多的模块。届时,片上互连需连接更多的模块,NoC的重要性会进一步凸显。
但与此同时,做一个高性能的NoC难度却非常高,不仅要应对多核/异构SoC的要求,又要具备稳健的路由算法,保证互连网络不存在死锁,还要有很好的通信效率,以及配套的EDA工具,可快速配置网络参数和拓扑结构,可以进行快速模型仿真,并自动部署众多的信号连线。
作为Arteris在中国设立的合资公司,传智驿芯是Arteris NoC IP的价值和服务的延伸,其NoC IP等核心产品能够帮助客户降低功耗、提升性能、加快SoC开发速度,从而降低开发和生产成本。
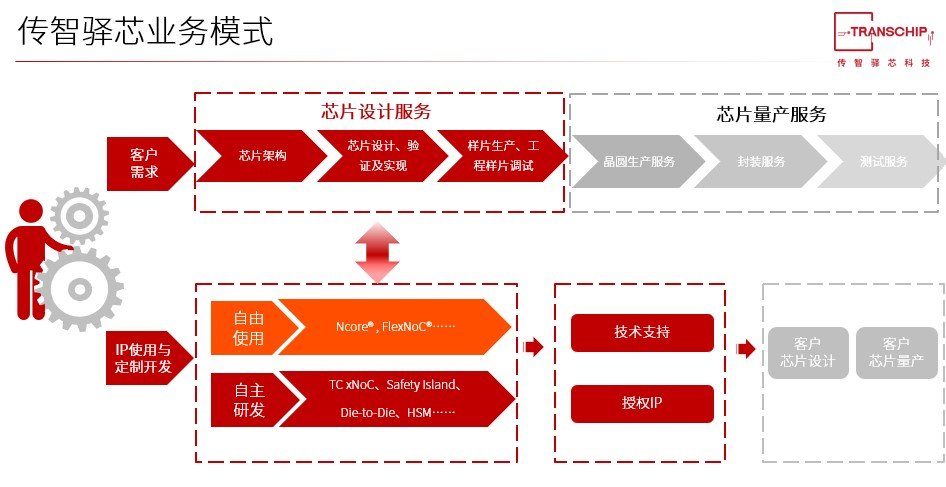
在子系统IP开放方面,传智驿芯打造了TC xNoC、Safety lsland以及Die to Die三大产品矩阵,其业务模式主要有两种:一种是IP模式;另一种是根据客户需求,提供芯片设计服务,汽车芯片、GPU/AI芯片、RISC-V芯片、以及FPGA芯片等厂商是其主要服务对象。

