
我们总说英伟达GPU虽然彪悍,但不及其生态系统那么彪悍,各种加速库、模型、开发工具、中间件,构建起了超强的生态系统护城河。仰仗生态的优越性,来赚GPU硬件的钱,是英伟达这家公司很重要的业务逻辑。今年GTC开发者大会的更新也不例外,尤其是NVIDIA NIM这类进一步凝聚生态的新东西,以及终提上日程的Omniverse Cloud API,和尝试将AI拉进现实生活、而不光是数字世界的Project GROOT等等...
但普罗大众关心的似乎主要就是英伟达的新硬件、新GPU。这次GTC的最大亮点在我们看来是NVIDIA NIM,但毫无疑问最受瞩目的,必然是黄仁勋站在台上发布的Blackwell GPU芯片,以及这颗芯片构成的新系统。那么这篇文章我们就单纯谈谈英伟达新发布的新硬件,其他有关NVIDIA AI和Omniverse的更新和发布将另外撰文。

进一步下注生成式AI
回顾英伟达的历史,不难发现这家公司对HPC和AI的投入,绝不仅限于最知名的Ampere和Hopper架构这两代,尤其是几乎人尽皆知的A100和H100加速卡。因为这一波AI技术崛起,自AlexNet图像分类至今已经走过10多年了,迄今也还没有遭遇传说中的AI winter。
在此期间英伟达的GPU架构历经了Kepler、Pacal、Volta,以及近两代的Ampere和Hopper。当然期间还伴随着NVLink、NVSwitch之类的互联技术诞生,以实现算力扩展。这期间的一些标志性事件包括Kepler架构的Tesla K10全面开启数据中心加速计算市场;Volta架构引入tensor core;
Ampere架构时期英伟达带来了NCCL和TF32支持;Hopper架构新增Transformer Engine引擎支持,实现对基于Transformer的模型——也就是现在很多的成式AI模型的加速。
自去年初生成式AI以ChatGPT和Dall-E为代表的爆发至今,有关AI算力需求的暴增是人所共知的,几万亿、几十万亿参数量的模型、对于LLM在推理时追求更多数据的输入、推理要求更快响应速度之类的问题早就被说烂了。所以前一阵Pat Gelsinger和Sam Altman才探讨了接下来究竟需要建多少foundry厂才能满足GPT-7的算力需求问题。这种问题的本质无非是AI芯片需求更大算力。
这是英伟达这次发布Blackwell芯片的背景。
两片大尺寸chiplet组成的芯片
主题演讲中,没能听到黄仁勋详述这颗Blackwell芯片的架构。不过有一些数据是可以分享的。首先制造工艺是基于TSMC 4NP(应该是N4P的某个定制版本);

其次一个封装内有两片die——英伟达在预沟通会ppt的标注中写着“reticle-sized die”,应该是指达到了光刻机可处理的reticle limit尺寸。一般现在i193和EUV光刻机可处理的最大die尺寸大约是850mm²。不过英伟达没有明确标注这一尺寸。
黄仁勋的主题演讲中提到,Blackwell芯片之上单片die的晶体管数量达到了1040亿,所以两片die就是2080亿,相比于Hopper多了1280亿颗晶体管。(这样一颗2-die封装的芯片即为B100;两颗构成B200)

Blackwell与Hopper的尺寸对比
我们知道突破reticle limit限制的方法无疑就是chiplet和先进封装。所以这两片die必然用上了先进封装,英伟达提到NV-HBI 10TB/s高带宽接口;除此之外,片内还封装了192GB的HBM3e内存,带宽8TB/s;另有1.8TB/s带宽的NVLink扩展支持。英伟达说这是“没有任何妥协”、相比整片die性能保持一致、“其他multi-chip架构未曾达到的”AI超级芯片。
芯片性能方面,有一些粗略的数据:20 PetaFLOPS的AI性能(FP4),10 PetaFLOPS FP8理论算力水平。主题演讲中提到其AI性能是Hopper的5倍——结合后文将提到的新Transformer引擎,加上堆料,推理性能的5倍提升是相对合理的。(另更新功耗数据:根据系统差异,单片Blackwell功耗最多可定在1200W)
媒体预沟通会上提到了一组更有趣的数据:“4倍于Hopper的训练性能,30倍的推理性能,能效高出25倍”。 30倍是不是听起来相当违反摩尔定律?黄仁勋在主题演讲中其实没有提30倍,但这30倍也是有出处的——而且我们认为这个数字也有价值。后文会提到其限定条件。另外在算力扩展方面,Blackwell支持超过10万个GPU部署量级的AI数据中心。(更正:黄仁勋在系统层面对比时,也提到了推理性能30倍的提升;我们会在后续的文章里,对此做更进一步的解读)

宣传中提到了Blackwell的6大关键特性:第一就是超越reticle限制的AI超级芯片;其次是加入了第2代Transformer引擎;第三是提供secure AI(所谓不牺牲性能的confidential computing);
第四,第5代NVLink,扩展支持最多576个GPU互联;第五,内置RAS引擎实现自身的可靠性(RAS应该是指可靠性、可用性、可服务性,一种自动的纠错、容错机制;黄仁勋原话是说能对芯片上的每个gate、每bit存储,及其连接的所有内存做检测);第六,新的解压缩引擎,数据处理速度提升20倍。
有关新Transformer引擎与NVLink
其中两个关键特性是英伟达特别提及的。这里的第2代Transformer引擎对应的主要是Hopper架构中的初代Transformer引擎。实际上Transformer引擎本身并不是一个特定的硬件单元或模块;而更像是个用于加速在GPU tensor core上执行Transformer模型的库,尤其是对FP8的充分利用,属于软硬件结合的引擎。
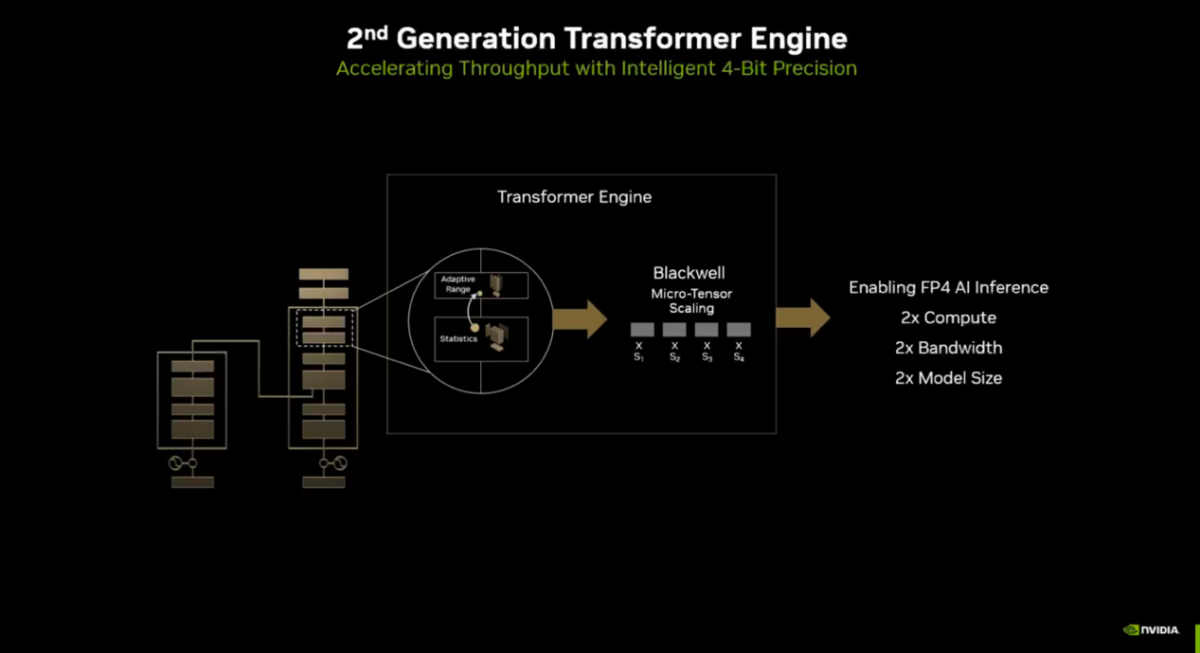
这次迭代的Transformer引擎是硬件上对于“micro-tensor scaling”的支持,在sub-tensor的颗粒度上,追踪单层的值区间范围,最终“实现FP4数据格式AI推理”。基于这种机制(micro-tensor scaling),实现FP4成倍的算力、带宽和模型尺寸提升。总体就达成了特定性能的翻番。
还有个重要更新是NVLink相关的。英伟达认为,随着多模态(multi-modality)模型以及MoE模型(混合专家模型)参数量的增大,扩展更多GPU来跑这样的模型会成为常规。而现状是,跑这类大模型的过程里,60%的时间都是用来做互联通信的,剩下40%的时间才真的用来做计算。
所以英伟达这次也发布了新的NVLink架构和NVLink交换机,及对应的系统来缓解这一问题。新一代NVLink技术更新中的一大关键应该是新发布的NVLink Switch芯片——这颗交换数据的芯片就有500亿晶体管,承载总共4组NVLink,每组1.8TB/s带宽。这颗芯片是多GPU全互联的关键。

基于两颗NVLink Switch芯片的NVLink交换机(Switch Tray)提供14.4TB/s的总带宽;另外SHARPv4(Scalable Hierachical Aggregation and Reduction Protcol)支持则实现了FP64/32/16/8的AllReduced计算。整个交换机采用液冷方案。
组成GB200 NVL72系统,以及30倍性能提升
现在一般有芯片,就有对应的系统级产品方案。这次发布基于Blackwell GPU的系统名为GB200-NVL72。这里的GB指的是Grace + Blackwell,命名上类似于之前的GH200(Grace Hopper)——所以GB200本身也是个板级系统;后缀NVL72,数字72是指内部总共有72个Blackwell GPU芯片,NVL则是指借助NVLink实现全连接,另外也配套了最新的交换机。

整个机柜每个计算槽位有4颗Blackwell GPU。据说NVLink全连接所有的GPU用到了5481根线缆,机柜后方的线缆长度达到了1.5英里。
GB200 NVL72的AI训练总算力为720 PetaFLOPS,推理则为1440 PetaFLOPS。“如果要看总的模型尺寸,在整个NVLink域内,可以容纳27万亿参数,以及超过130TB/s的带宽”。另外由于新增SHARP支持,多节点AllReduce操作时,NVLink能达成有效带宽翻番。

拆开来看,每两颗Blackwell GPU搭配一颗Grace CPU——这样一个单位即为GB200(如上图);一个计算槽有2组GB200,也就是2颗Grace CPU和4颗Blackwell GPU;每组GB200可配最多864GB快速内存,所以一个计算槽就有1728GB快速内存;每个计算槽4条NVLink连接,每条连接1.8TB/s带宽。

有关NVLink交换机前文已经提到过,提供整个机架的主干网络数据交换支持。
最后是性能相比Hopper架构H100的对比。相同数量Hopper GPU,与GB200 NVL72相较,对于1750亿参数的GPT-3而言,后者推理速度快7倍;而在1.8万亿参数的MoE模型推理工作上,GB200 NVL72性能高出30倍——猜测这应该是预沟通会上英伟达提到Blackwell推理性能快30倍的来源。
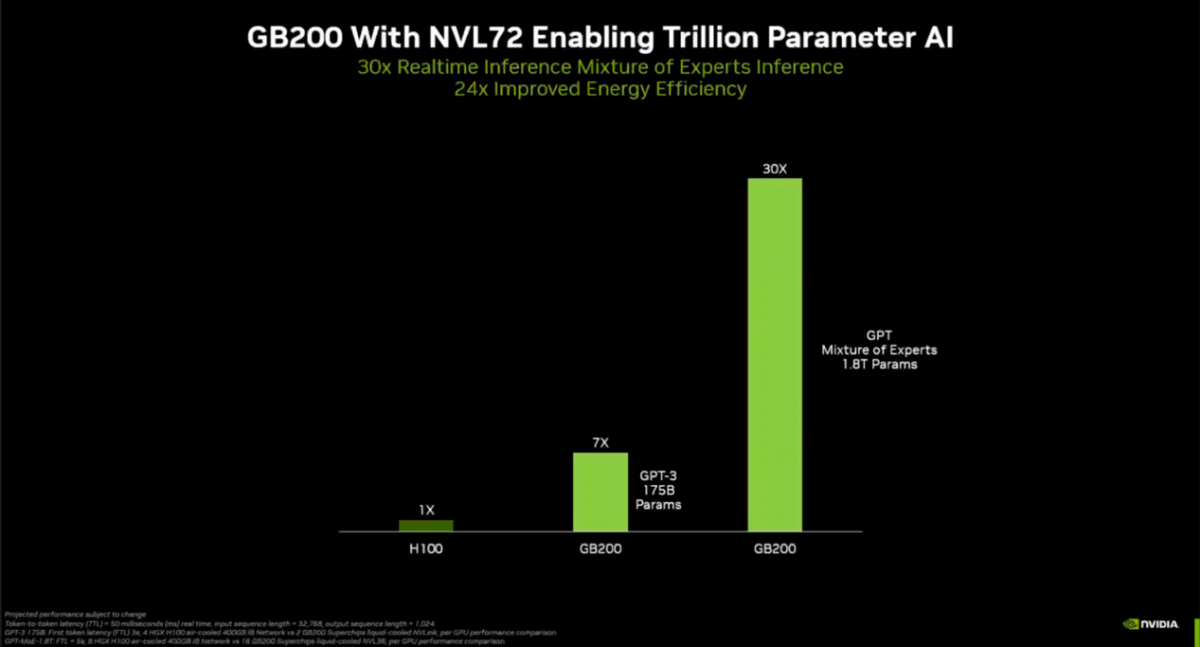
不知道这里对比的H100具体是放在怎样的系统下,应该不是Grace Hopper构成的平台...30倍这个数字,很大程度上还是体现了系统层级,包括新互联技术及整个系统的优越性;毕竟单纯凭借摩尔定律,就算再堆上chiplet,以及新的Transformer引擎,单芯片层面其实很难做到30倍。

2024.3.24 更新:黄仁勋在主题演讲中给出了这张图,其中最下方的蓝线表示Hopper,紫线则表示单纯用B200(2颗Blackwell GPU的加速卡)——不考虑新一代NVLink、FP4适配支持带来的提升,绿线表示充分利用本次技术更新的GB200。当然,整体上仍然是系统间的对比,和前一张图对比的是一回事。
这张表的横坐标可理解为AI推理时的token生成速度,纵坐标则为吞吐(吞吐可代表生成每个token的成本)。则GB200相比于H200,这根曲线最大差异处的的差距是30倍。如我们预想的,新一代NVLink以及第二代Transformer引擎,在其中应该是起到了非常大的作用的。
很快包括AWS、Google Cloud、微软Azure和Oracle Cloud这几家云服务提供商都将提供GB200 NVL72资源;如果单纯要说Blackwell及其不同配置的系统的话,初期累计的客户数量,似乎就是此前Hopper刚发布时的几十倍了。
还有一些硬件和系统方面的更新
除了Blackwell GPU和对应的新系统,英伟达在这次的GTC上还更新了InfiniBand和以太网交换机,当然宣传上也是说为万亿量级参数AI做准备。更新产品分别是Quantum-X800和Spectrum-X800,对应的应用了ConnectX-8 SuperNIC和BlueField-3 SuperNIC网卡。这两者应该也是前述新系统组建的重要组成部分。交换性能及特性如图:

更高层级及算力扩展,基于GB200 NVL72的DGX SuperPOD也发布了。这种系统一般就是为各类大规模的行业应用准备的了,比如医疗领域的药物发现,金融服务与欺诈检测,到现在互联网服务随处可见的推荐系统:总共最多配8个GB200 NVL72,也就是288个Grace CPU和576个Blackwell GPU;240TB内存、FP4算力11.5 ExaFLOPS。像这种系统标称30倍推理性能提升、4倍训练性能提升、25倍节能就显然好理解多了。
媒体会上还有个一带而过的HGX B200和DGX B200,应该是更具兼容性的选择。标准风冷散热的DGX B200标称算力提升水平是推理提升15倍、训练提升3倍、节能12倍。基于这组数据,可见单芯片与上代对比,要做到30倍性能提升还是不现实的。
最后值得一提的是,GB200 NVL72系统自然也能再扩展:除了前述8个GB200 NVL72构成的计算单位(compute racks),黄仁勋展示“全数据中心”可配32000个Blackwell GPU,累计AI性能654 ExaFLOPS。
所以也就不意外GB200 NVL72也要入驻到NVIDIA DGX Cloud云了,自然也是和AWS、Google Cloud、Oracle Cloud合作。去年12月原本英伟达宣布和AWS合作搞个名为Ceiba的项目,构建DGX Cloud的AI超级计算机,现在也做了升级,准备基于GB200 NVL72来搭建整套系统,预期提供AI算力400 ExaFLOPS,HBM3e内存容量达到了惊人的4PB;准备在今年内完成落地。

最近有关英伟达的信息普遍是市值一夜暴涨1.1万亿美元、逼近2万亿美元、超过2万亿美元......感觉和市值增长相比,开发者和行业企业都很难跟上英伟达GPU及其系统的迭代速度,以及性能增长的速度了。不知道新更新的系统在OpenAI眼中,是否足够发展未来的生成式AI系统。
电子工程专辑正在圣何塞现场参与英伟达GTC大会:如文首所述,其实在我们看来Blackwell和GB200 NVL72的硬件迭代并不如生态系统层面的更新精彩,比如NVIDIA NIM、Omniverse Cloud API等。这些我们将在后续文章里再做更新。
另外也不要忘记将在本月底于上海由Aspencore举办的IIC Shanghai活动,同期举办的GPU/AI芯片与高性能计算应用论坛也将同步进行,届时顶尖的AI领域行业专家将分享他们对于AI技术的看法和展望,点击这里参考详情并报名参会。

