
推广AI PC这个概念的厂商,普遍在找寻AI真正落地的应用场景。我们之前就常说,AI时代,上游的芯片企业普遍在亲力亲为地为开发者们“发现”各种可能性,一边提供中间层和各类工具,一边还不忘做些应用——有些是为了展示,有些则可直接使用。
上个月英伟达亲自下场做了个Chat with RTX,专为PC用户准备的本地LLM对话机器人。而且因为是面向普通用户,所以追求的是一键安装,不需要进行繁杂的环境部署之类的操作。其实这东西算不上稀罕,从生成式AI概念大火开始,不少OEM厂商就陆续在设备上集成各种基于不同LLM模型的本地服务,手机和PC厂商都在搞。
不过最近的英伟达RTX for AI技术品鉴会上,我们还是看到了一些与众不同的东西:不只是Chat with RTX,还包括ACE(Avatar Cloud Engine)会讲中文了,Stable Diffusion XL有了更快的加速......
对英伟达而言,眼下要做的,都是在数据中心AI市场独霸一方以后,在端侧PC上也尽早构建起AI PC的技术与生态护城河。现在几家芯片厂在比的,说到底是谁的AI PC对用户而言更有用。

3月28-29日,由Aspencore主办的国际集成电路展览会暨研讨会(IIC Shanghai)将在上海召开。AI作为热点也是IIC的焦点议题之一,与IIC 2024同期举办的GPU/AI芯片与高性能计算应用论坛也将同步进行,届时顶尖的AI领域行业专家将分享他们对于AI技术的看法和展望,点击这里参考详情并报名参会。
本地AI对话,总算有用了
之前我们也见过不少本地LLM服务或app:芯片企业主打的无非是自家芯片很厉害,以及在中间件上做了多大程度的努力,才让大语言模型可在PC本地直接跑起来。但无论是ChatGLM,还是Llama,或者能写代码的StarCoder,在本地做AI推理的实用程度都堪称鸡肋;或者说本地LLM的智商,比起云上的ChatGPT/Copilot,那差的绝对不是一星半点。
起初我们对于Chat with RTX的看法也是这样,无非是英伟达简化了LLM与RTX加速本地部署的流程,英伟达期望给出基于GeForce显卡加速的LLM对话机器人展示罢了。但在品鉴会活动上发现,这东西的真正价值可能在另一个叫RAG(Retrieval-Augmented Generation,检索增强生成)的技术点上,第一次让我们自己也有动力去用Chat with RTX了。
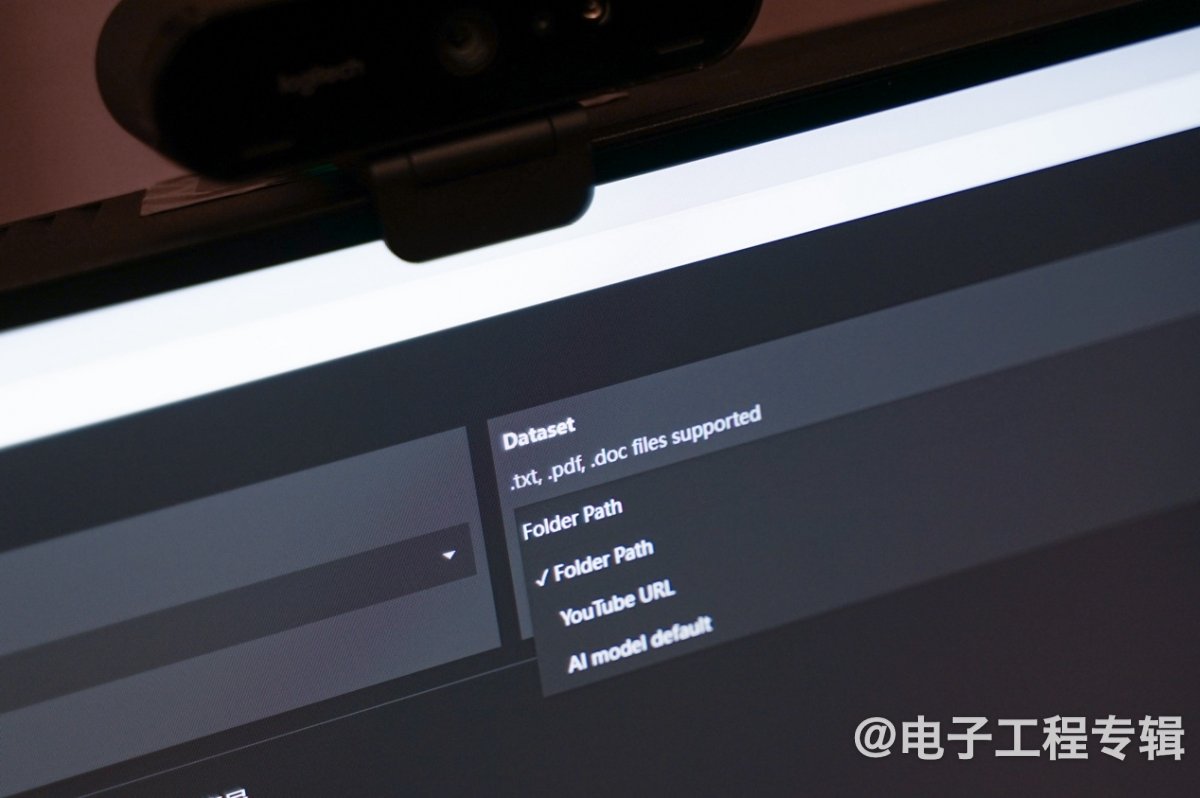
Chat with RTX的用户界面上,除了AI模型选择和对话的文本输入框以外,还有个“数据集路径”——可由用户选择本地文件夹(也可以输入油管视频的URL路径),Chat with RTX就会扫描文件夹中的内容,并在与用户的问答过程里,结合其中的资料内容。目前文件支持类型涵盖.txt,.pdf,.doc/.docx,.xml。
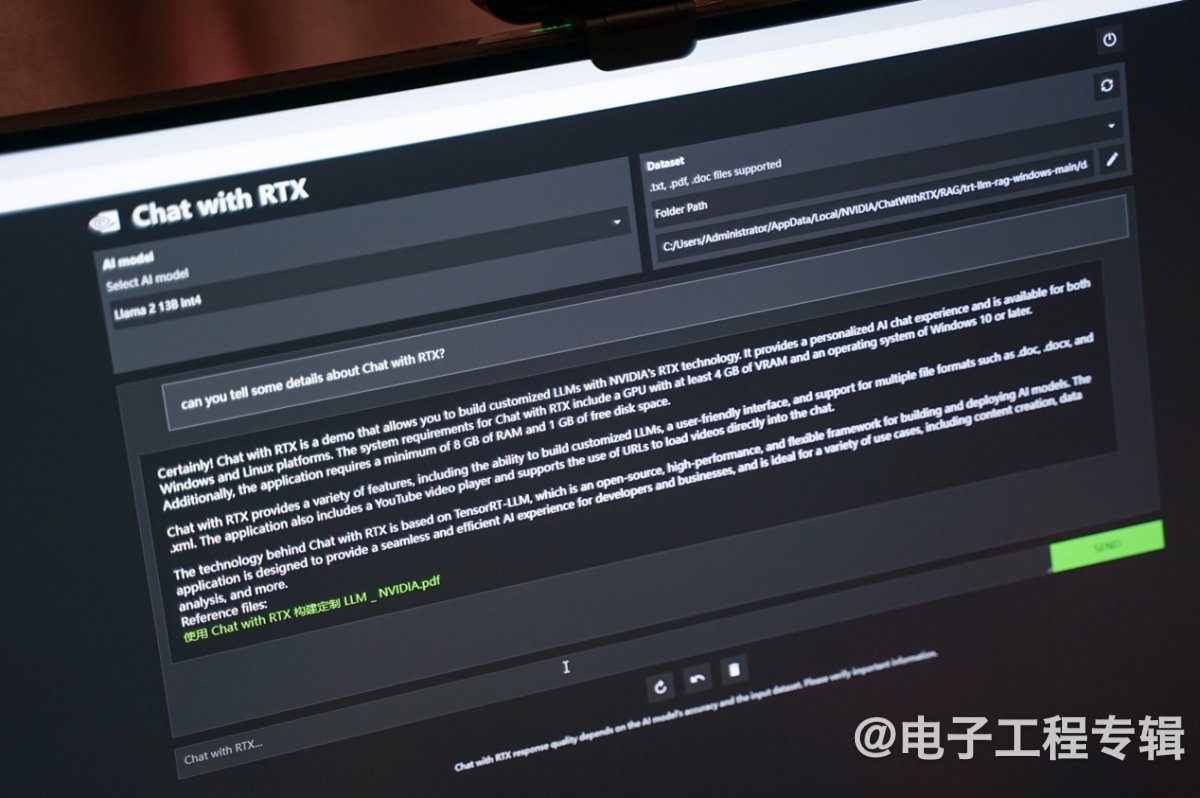
活动现场,基于本的Llama 2模型,我们发出问题“介绍一下Chat with RTX”。由于现有Llama 2 13b模型根本就没有相关数据,我们自然无法得到有价值的信息回复。一般对于更新的信息,或者定制的数据集,我们需要对模型做基于数据集的重新训练和部署——这对一般个人用户而言不大现实。
所以英伟达的工程师现场找到Chat with RTX的官方介绍页面,将整个页面另存为PDF文档(其中包含图文混排),然后将其放到“数据集路径”指向的文件夹内。再问Chat with RTX相同的问题,它就能很准确地给出回答,并且在最后给出回答参考的PDF文档来源(下图)。
既然能自己找到相关资料,为什么要把它放进Chat with RTX的参考资料库,然后再问它呢?这不是多此一举吗?
一方面是如果资料来源的内容非常多,比如是一篇paper,或者像视频那样有长达万字的脚本,以这种方式从中找到所需内容就会很方便;另一方面,当个人资料文档数量庞大,比如说工作了几年积累的文字与数据资料,要追溯历史信息,靠我们手动去找会非常辛苦——Chat with RTX此时对于生产力而言就会非常高效。
比如说对应文件夹里放进过往打车的所有行程记录(如滴滴打车自动生成的),那么随时都能向Chat with RTX提问过去某个时间段自己去过哪儿;或者将旅游攻略都放进去,就能让Chat with RTX协助安排去往某地的行程...英伟达说,不同使用习惯的个人能用它来实践不同的价值。多提一句,Chat with RTX对于油管视频来源的支持,是基于页面上的文本脚本(即字幕)。
去年末,英伟达官方博客也介绍了这种RAG检索强化生成技术。RAG这个词最早是2020年的一篇paper中被提及的,现在似乎已经有大量paper和商业服务开始应用——AWS, 谷歌, 微软等企业都在用。这是一种借助外部信息来源,增强生成式AI模型精度和可靠性的技术方法。我们知道LLM作为一种神经网络,其智商水平主要取决于包含的参数量。RAG是把生成式AI服务与外部来源做了结合,以很方便的方法提高其智商。
RAG技术的发明者将其称作“一种通用的fine-tuning方法”,因为它适用于几乎所有的LLM模型。前两年Nvidia NeMo LLM Service发布时,英伟达似乎就已经准备在企业版Nvidia AI上应用这种技术。
其价值是显而易见的,首先明确与LLM特定话题的对话,而且有据可循;其次是基于个人或企业私有数据,是本地属性的;与此同时,实现过程很方便,相比于重新训练模型,速度更快、成本更低。
当然具体的能力——比如给出一堆数据,让Chat with RTX总结趋势——还是取决于模型本身。起码现在用于端侧的LLM模型数据抽象能力还不怎么行。但潜在价值还是在于“私人助理”的实现,比如对辅助医生做医疗相关的索引,或者帮助金融分析师链接市场数据,都是相当不错的选择。
Chat with RTX现在官方支持的模型有Mistral-7b与Llama 2-13b。英伟达在本次演示中外挂了国内的ChatGLM 3-6b。英伟达工程师说:“后续中文模型我们会做官方支持。”
文生图“所见即所得”秒出图
值得一提的是,除了前面着重提到的RAG之外,Chat with RTX也用上了TensorRT-LLM加速;现场看来,其响应速度还是相当快——虽然现在我们还没有可量化的数据,毕竟演示用的是GeForce RTX 4090D。英伟达是在去年10月发布的TensorRT-LLM for Windows,实现了GeForce显卡单卡在Windows平台上,对LLM推理的加速。
要了解什么是TensorRT-LLM可以参见这篇文章。除了针对LLM以外,同期英伟达也特别为Stable Diffusion WebUI做了TensorRT加速扩展。后来很快又更新了对Stable Diffusion XL与SDXL Turbo的TensorRT加速。这些应该说是充分表达了英伟达要发展AI PC的决心的。
这次活动现场,英伟达也演示了在没有TensorRT加速、采用Xformers库做加速、选择TensorRT插件加速这三个场景,在用Stable Diffusion XL WebUI出图速度上的区别:英伟达期望表达的应该是TensorRT加速效率更高。

从现场的演示来看,Xformers和TensorRT插件加速的结果差不多,不过这仍不是个完整可量化的综合测试:理论上前者是特别针对图像生成所作的加速库,而后者是英伟达官方出品、推理应用范围更广的加速库,即便插件是特别针对Stable Diffusion WebUI的;而且现场演示的文生图负载还是太轻度了,还应用了超分模型,不足以充分表征二者差别。
当然无论怎么比,也都是动用了RTX加速的方法明显更快。而且Stable Diffusion XL和Turbo版,在出图质量上也明显优于此前的Stable Diffusion 1.5。
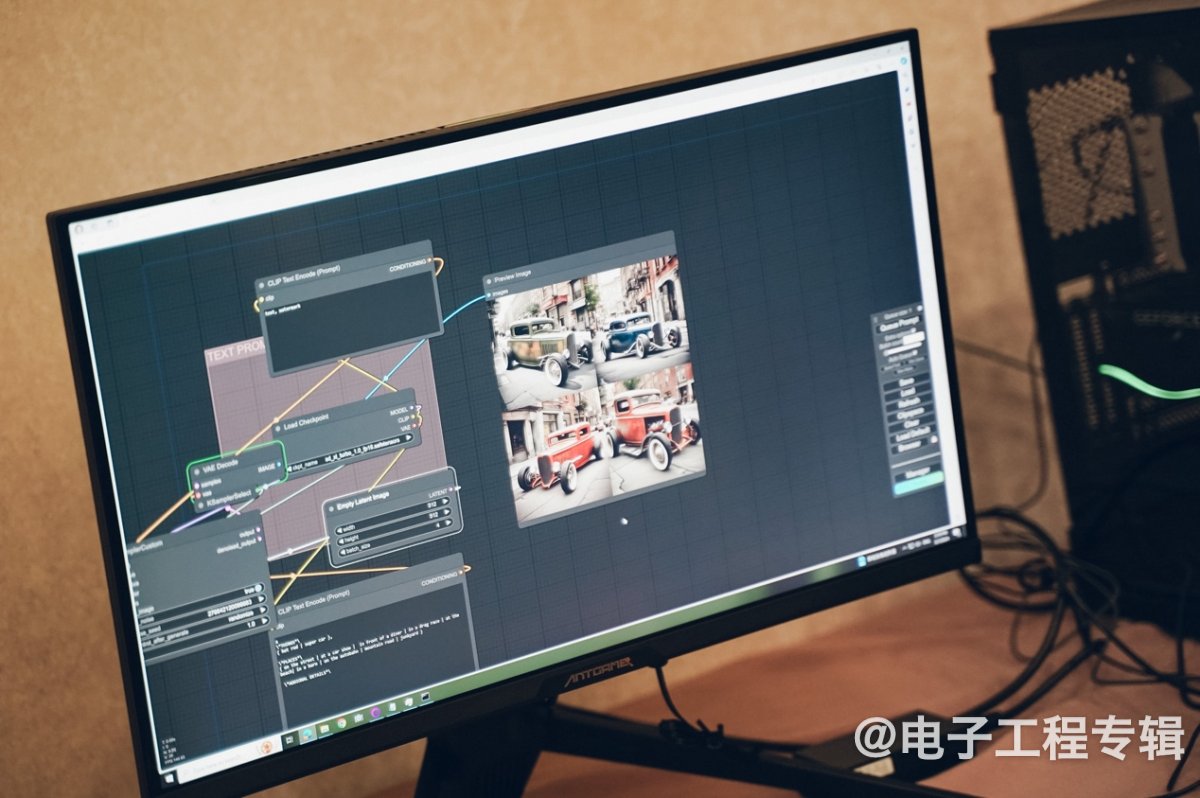
另外,这次英伟达还特别演示了Stable Diffusion ComfyUI。这是个相比更多人所知的WebUI版,更加符合直觉、且可控的Stable Diffusion GUI。特点主要在于,它把Stable Diffusion的流程拆分成了不同节点,以Stable Diffusion的实现管线、流程图的方式,给出更加可控、更有弹性的使用体验。
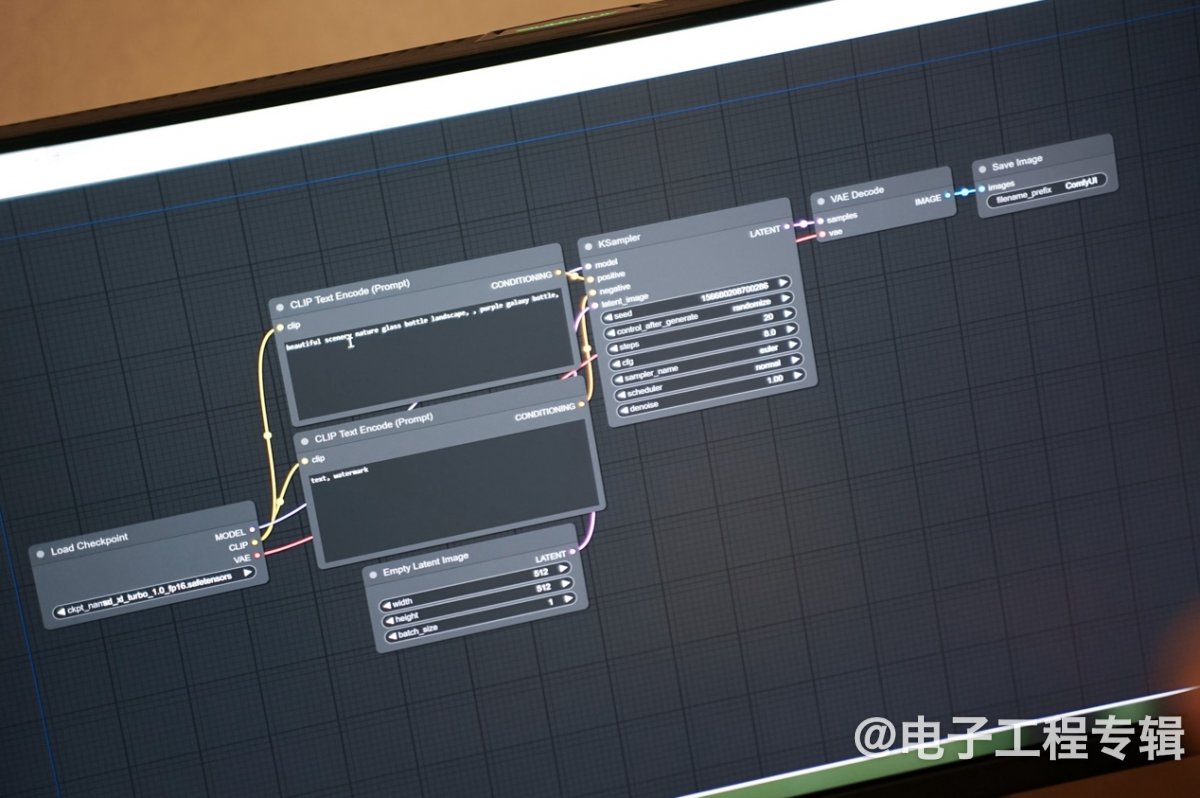
比如说基于默认的流程图,文生图推理的全过程切分成了checkpoint loader, 正向与负向的文字提示词, 图像尺寸, KSampler与VAE Decode, 图像保存节点等。不过ComfyUI的一大特点是流程的可定制,用户可以按照需求来增删不同操作的节点,比如说可以增加个额外的图像后处理步骤;另外也可以调整流程中的各种参数,比如采样方法、decoder结构等...
但也因此,Stable Diffusion ComfyUI的用户定位更偏向开发者、研究人员和对Stable Diffusion相对熟悉的创作者。
虽然没有借助于TensorRT加速,不过从英伟达的演示来看,ComfyUI的推理效率似乎是远高于WebUI的,尤其是再度修改提示词以后,基本是秒出图——比如把图中鸭子的帽子从黄色改为红色,在流程图中做修改之后,输出图片能做到马上响应,“所见即所得”。除了采样和解码比较高效、可定制推理流程以外,不需要重新扩散(re-diffusion)是秒速出图的关键。
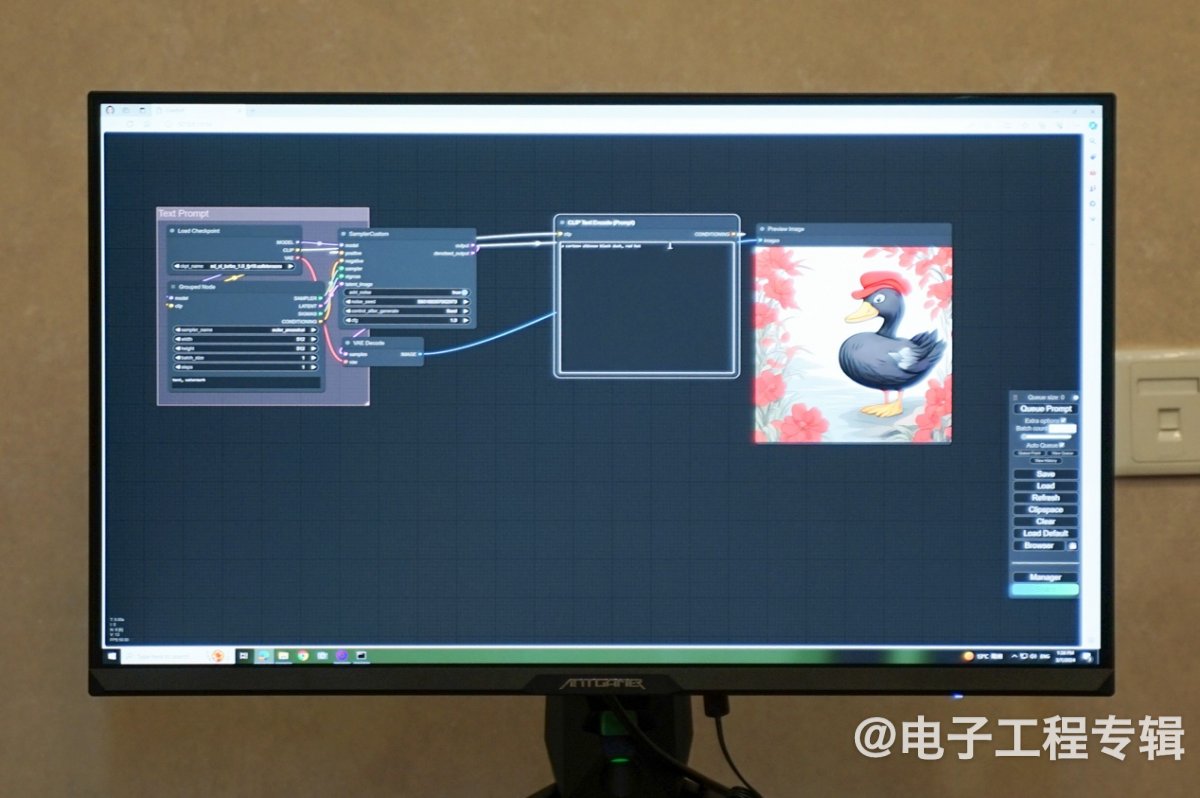
秒出图的价值在于实现高效的参考设计,基于设计灵感来任意更动设计方案。有兴趣的同学可以自己上手体验一下——虽然现场没有对比,不过大约CUDA加速在这其中也是起到了相当作用的。ComfyUI对于CUDA加速的支持应该是通过PyTorch框架完成的。
游戏NPC AI对话,现在也能讲中文了
这次另一个演示的重点,就是Nvidia ACE(Avatar Cloud Engine)。ACE的发布最早可以追溯到2022年,去年ACE游戏开发版发布,今年CES上我们也上手体验了这项技术:直接与游戏NPC人物对话,聊什么都可以——还能基于场景中的对象与NPC交流,比如让NPC关灯,或让他准备一碗拉面,以及询问这碗拉面是怎么做的等等。
虽然英伟达一直在强调,ACE是个云侧与端侧混合的AI实现——有关ACE的具体实现流程本文就不再重复了,此前我们做过多次介绍;不过ACE的技术核心,仍然是LLM——只不过LLM推理是放在云上进行的。
感觉英伟达之所以设定用于NPC响应的LLM是放在云上,主要是因为不同的游戏人物有其人格、角色、动作、记忆之类的设定,面向游戏开发者时更容易把这一开发生态掌握在自己手上。

从CES到现在,这则demo的两名NPC都已经会说中文了,虽然口音还非常奇怪,但起码是能说了——据英伟达所说,后续的更新里,ACE讲中文的能力也会大幅提升;NPC很快也会基于对话内容增加对应表情。
目前的ACE流程中,云上LLM+RAG响应主要是一家名为Convai的公司做的(并且Convai面向游戏开发者提供角色API),不知道英伟达后续是否会考虑在国内找这类服务的合作伙伴;或者让Convai在国内部署本地服务。毕竟此前英伟达就说过对应服务已经在和米哈游、网易、腾讯、掌趣之类的游戏公司合作。
其实无论是Chat with RTX, ComfyUI Stable Diffusion, 还是ACE游戏版,以及这次又演示了一遍的DLSS 3.5,英伟达现阶段似乎正拼命在为开发者和用户寻找AI PC的落地应用场景,不仅在为开发者提供AI工具,而且还尝试亲自下场做面向终端用户的app,推进基于GeForce显卡的AI PC是势在必行了。
实际上DLSS某种程度已经算得上游戏领域的AI杀手级应用,ACE则有这样的潜力;Chat with RTX是我们首次看到本地LLM推理能够切实推进生产力的落地。AI PC大概会在这样添砖加瓦的过程中一步步走向成熟。
3月28-29日,由Aspencore主办的国际集成电路展览会暨研讨会(IIC Shanghai)将在上海召开。AI作为热点也是IIC的焦点议题之一,与IIC 2024同期举办的GPU/AI芯片与高性能计算应用论坛也将同步进行,届时顶尖的AI领域行业专家将分享他们对于AI技术的看法和展望,点击这里参考详情并报名参会。


