
作为一家人工智能芯片初创公司 ,位于加利福尼亚州圣克拉拉市的Lemurian Labs,发明了一种专为人工智能加速而设计的新对数数字格式,并正在为数据中心的人工智能工作负载构建一种利用该格式的芯片。
“2018年我在为机器人技术训练模型时,所用模型中包括部分卷积、部分Transformer和部分强化学习。”Lemurian首席执行官Jay Dawani在接受《电子工程专辑》采访时表示,“即便如此,在多达1万片(英伟达)V100 GPU上训练该模型,仍需要6个月时间……而如今,模型数量呈指数级增长,但很少有人有足够的算力来尝试(这种训练),于是很多工程师的好想法就这样被放弃了。于是,我便一直试图为那些有好点子、但又缺乏算力的普通机器学习工程师构建合适的模型”。
对Lemurian尚未推出的首款芯片进行的仿真结果显示,在新的数字系统和定制设计芯片加持下,其性能将超过英伟达的H100(基于H100最新的结果)。在离线模式下,针对MLPerf版本GPT-J的Lemurian芯片,仿真结果为每秒每片可处理17.54次推理(而H100在离线模式下每秒可处理13.07次推理)。从数字上看好像快得并不多,但Dawani透露,该仿真结果可能还不到真实芯片性能的10%,而且他的团队今后还打算从软件中挖掘更多性能。他认为,通过软件优化再加上稀疏性,还可将性能再提高3~5倍。

对数数字系统
Lemurian的秘诀在于其称之为PAL(并行自适应对数)的新数字格式。
“之所以乐于采用8位整数量化,是因为从硬件角度来看,这是我们所拥有的最有效东西。”Dawani解释道,“其实,并没有哪位软件工程师一定要8位整数!”
对于当今的大语言模型推理而言,INT8的精度已被证明是不够的,因此业界已转向FP8。但Dawani解释说,人工智能工作负载的性质,意味着数字经常处于非规格范围——接近零区域,而FP8在该区域能表示的数字很少,因此精度较低。FP8在非规格范围内的覆盖率存在差距,这也是许多训练方案需要BF16和FP32等更高精度数据类型的原因。
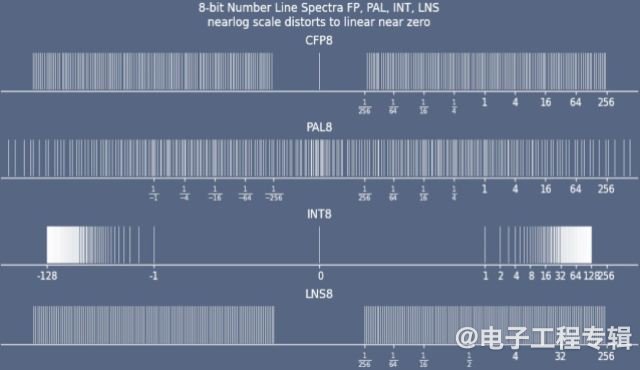
图1:各种数字格式的覆盖范围比较。与可配置的浮点8(CFP8)、整数8(INT8)和现有对数数字系统8(LNS8)相比,Lemurian的8 位对数数据类型PAL8能够更好地覆盖非规格范围。(来源:Lemurian Labs)
Dawani公司的联合创始人Vassil Dimitrov提出了一个想法,即利用多个底数和多个指数,对已在DSP领域应用了几十年的现有对数数字系统(LNS)进行扩展。
“可以通过交织多个指数的表达式,来重建浮点的精度和范围。”Dawani表示:“这样可以让覆盖范围更广……它自然而然地创建了一个锥形轮廓,在非规格范围内、在重要的地方具有非常高的精度范围。”
这一精度范围可以通过偏置覆盖所需的区域,这与浮点的工作原理类似,但Dawani指出,与浮点相比,它可以对偏置进行更精细的控制。
Lemurian开发的PAL格式从PAL2一直到PAL64,其中14位格式与BF16相当。与FP8相比,PAL8获得了额外的精度,大小约为INT8的1.2倍。Dawani希望其他公司今后也能采用这些格式。
“希望更多的人去采用它,因为该摆脱浮点了。”Dawani表示,“PAL可用于目前使用浮点的任何应用,从DSP到HPC以及两者之间,而不仅仅是人工智能,尽管这是我们目前的重点,也更有可能与其他公司合作(为这些应用构建芯片),促进他们采用该格式。”
对数加法器
由于LNS简化了乘法运算,因此它在大多数运算为乘法运算的DSP工作负载中使用已久。LNS表示的两个数的乘法,其实就是两个对数的加法。然而,将两个LNS数字相加却比较困难。DSP传统上使用大型查找表(LUT)来实现加法运算,虽然效率相对较低,但如果所需的大部分运算都是乘法运算,这种方法已经足够好了。
对于人工智能工作负载来说,矩阵乘法需要乘法和累加。Lemurian的秘诀之一是用硬件实现对数加法,Dawani透露道。
“我们完全摒弃了LUT,创建了一个纯对数加法器。”他表示,“我们有一个比浮点精确得多的加法器。目前仍在进行更多的优化,看能否使它更便宜、更快速。目前,其PPA(功耗、性能、面积)性能已经比FP8高出两倍多。”
Lemurian已为这款加法器申请了多项专利。
“DSP成功的原因在于,对工作负载进行观察,并用数字方法理解它要做什么,然后加以利用,并在硅片上予以实现。”Dawani表示,“这与我们正在做的事情不谋而合。不过,我们并不是在构建只做一件事的ASIC,而是在研究整个神经网络空间的数值,并构建了一个具有适量灵活性的特定领域架构。”

图2:Lemurian数据流架构的高级视图。该芯片是围绕该公司的对数系统设计的。(来源:Lemurian Labs)
软件堆栈
要想高效地实现PAL格式,需要同时得到硬件和软件的支持。
“我们花了很多精力去思考如何让(硬件)更容易编程,因为除非能让工程师的生产力成为加速的第一要素,否则任何架构都不会成功。”Dawani表示,“不得已时,宁愿要一个(糟糕的)硬件架构和一个优秀的软件栈,也不要相反。”
Dawani透露,Lemurian早在开始考虑硬件架构之前,就已经构建了大约40%的编译器。如今,其软件栈已经开始运行,Dawani希望保持它的完全开放性,这样用户就可以对自己的内核和融合进行编写。
上述堆栈包含Lemurian的混合精度对数量化器Paladynn,可将浮点和整数工作负载映射为PAL格式,同时保持精度不变。“我们采纳了神经架构搜索中已有的很多想法,并将它们应用到量化过程中,目的是想让这部分变得更简单。”他补充道。
虽然卷积神经网络相对容易量化,但Transformer则不然。激励函数中存在需要更高精度的离群值,因此总体上Transformer可能需要更复杂的混合精度方法。不过Dawani表示,他们的多项研究工作进度表明,到Lemurian的硅芯片上市时,Transformer可能还不会出现。
未来的人工智能工作负载,可能会遵循谷歌的Gemini和其它产品设定的路径,即运行非确定的步数,这将打破大多数硬件和软件堆栈的假设。
Dawani认为:“如果事先不知道模型需要运行多少步,不知道该如何安排它,也不知道需要多少算力,那么就需要一些更动态的东西,这将影响我们的很多想法。”
该芯片将是一款300W的数据中心加速器,配备128GB HBM3,可提供3.5POPS的高密算力(稀疏性将稍后推出)。总体而言,Dawani的目标是打造一款性能优于H100的芯片,并使其在价格上与英伟达上一代A100具有可比性。目标应用包括(任何行业中的)内部人工智能服务器和一些二级或专业(非超大规模)云业务公司。
Lemurian团队目前有27人,分布在美国和加拿大,公司最近筹集了900万美元的种子资金,目标是在今年第二季度发布首款量产版软件栈,并在接下来的第三季度推出其首款芯片。Dawani透露,目前对于欲“深入了解详情”的客户,公司已可以提供虚拟开发工具包。
(原文刊登于EE Times美国版,参考链接:Can DSP Math Help Beat The GPU for AI?,由Franklin Zhao编译。)
本文为《电子工程专辑》2024年4月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
