
本文是关于卷积神经网络(CNN)特性和应用的系列文章的第二篇,CNN主要用于模式识别和物体分类。在第一篇《人工智能与卷积神经网络》中,我们介绍了在微控制器中执行经典线性程序与卷积神经网络的区别及其优势。讨论了利用CIFAR网络对图像中的猫、房屋或自行车等物体进行分类,或进行简单的语音模式识别。本文将介绍如何训练这些神经网络来解决问题。
神经网络的训练过程
CIFAR网络由不同层的神经元组成,如图1所示。32×32像素的图像数据呈现给网络并经过网络各层。CNN的第一步是检测和研究待区分物体的独有特征和结构,为此需要使用到滤波器矩阵。虽然设计人员对诸如CIFAR的神经网络进行了建模,但这些滤波器矩阵最初仍是未确定的,网络在此阶段仍无法检测模式和物体。
提高准确性或减小损失函数:这一过程被称为神经网络训练。对于常见应用来说,在开发和测试过程中需要对网络进行一次训练,之后就可以正常使用了,不需要再调整参数。如果系统正在对熟悉的物体进行分类,则无需进行额外的训练。只有当系统需要对全新的物体进行分类时,才有必要进行训练。

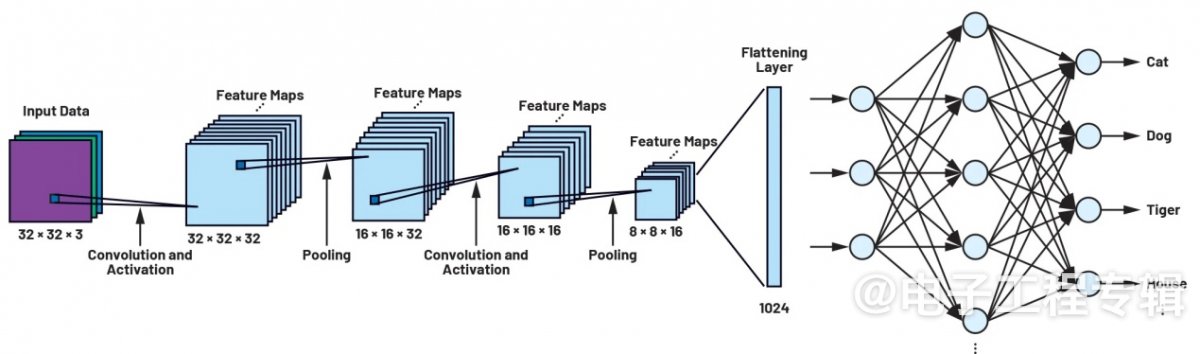
图1:CIFAR CNN架构。
训练网络需要训练数据,之后再使用类似的数据集来测试网络的准确性。例如,在我们的CIFAR-10网络数据集中,数据是十个对象类别中的一组图像:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。但在训练CNN之前,必须对这些图像进行命名,这也是整个人工智能应用开发过程中最复杂的部分。本文将要讨论的训练过程,是根据反向传播原理进行的;连续向网络展示大量图像,同时每次传达一个目标值。该例中,这个值就是相关的对象类别。每次显示图像时,都会对滤波器矩阵进行优化,使对象类别的目标值和实际值相匹配。完成这一过程后,网络就能在图像中检测出它在训练过程中没有看到的物体。
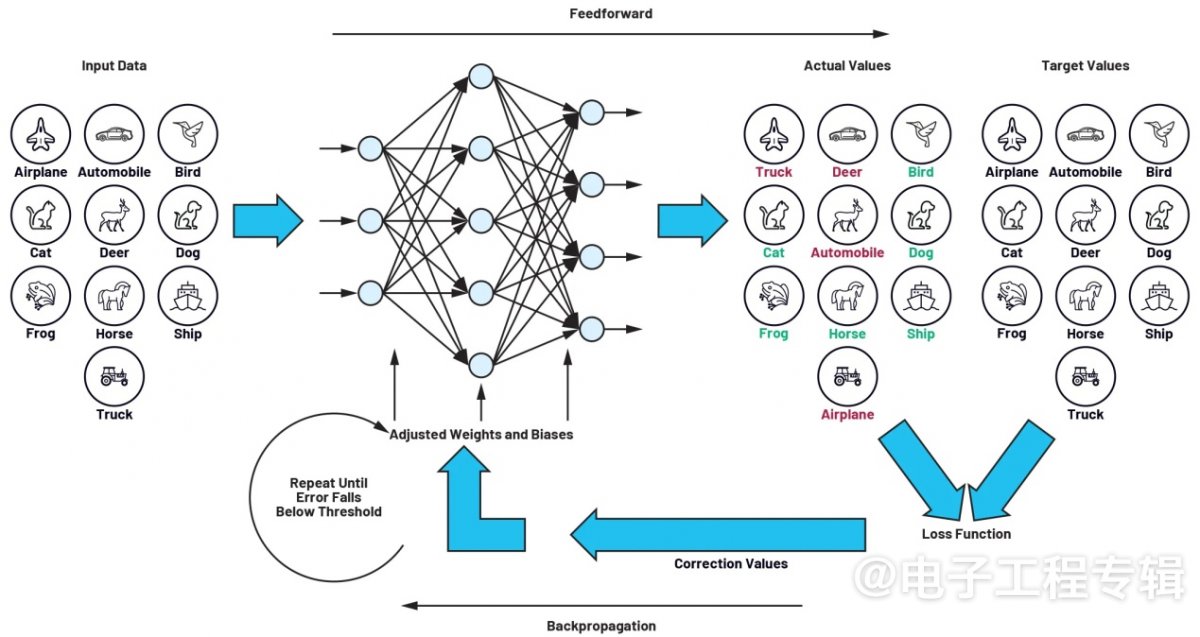
图2:由前馈和反向传播组成的训练环路。
过拟合和欠拟合
在神经网络建模过程中,经常会产生神经网络应该有多复杂的问题。也就是说,它应该有多少层,或者说它的滤波器矩阵应该有多大。这个问题没有简单的答案。与此相关,讨论网络的过拟合和欠拟合也很重要。过拟合是模型过于复杂与参数过多的结果。不过,可以通过比较训练数据损失和测试数据损失,由此来判断预测模型与训练数据的拟合程度,进而判断是过低还是过高。如果在训练过程中损失较低,而当网络遇到从未见过的测试数据时损失会过度增加,就充分说明网络已经记住了训练数据,而不是泛化模式识别。在网络参数存储空间过大或卷积层过多的情况下,才是导致这种情况的主要原因。在这种情况下,应缩小网络规模。
损失函数和训练算法
学习分两步进行。第一步,向网络展示一幅图像,然后由神经元网络对图像进行处理,生成输出向量。输出向量的最大值,代表检测到的物体类别,比如该例子中的狗,在训练场景中不必非要正确。这一步骤被称为前馈。
输出端产生的目标值与实际值之间的差值称为损失,相关函数为损失函数。损失函数中包括网络的所有元素和参数。神经网络学习过程的目标,是以最小化损失函数的方式来定义这些参数。这种最小化是通过一个过程来实现的。在这个过程中,输出端产生的偏差(损失=目标值减去实际值)通过网络的所有组件向后反馈,直到到达网络的起始层。这部分学习过程也被称为反向传播。
这样,在训练过程中,就形成了一个以阶梯方式确定滤波器矩阵参数的循环。这种前馈和反向传播的过程一直重复进行,直到损失值降到预先确定的阈值以下。
优化算法、梯度和梯度下降法
为了说明该训练过程,图3显示了一个仅由x和y两个参数组成的损失函数,而z轴对应的是损失值。函数本身在这里仅用于说明,并不起实际作用。如果仔细观察三维函数图,就会发现该函数既有全局最小值,也有局部最小值。
可以采用大量的数值优化算法来确定权重和偏差。最简单的算法是梯度下降法。梯度下降法的基本思想是从随机选择的损失函数起点出发,利用梯度逐步寻找通向全局最小值的路径。梯度作为一种数学运算符,描述了一个物理量的变化过程。在损失函数的每一点上,它都会产生一个向量,也称为梯度向量,指向函数值变化最大的方向。向量的幅度与变化量相对应。在图3所示的函数中,梯度向量指向右下方某处的最小值(红色箭头)。由于表面平坦,所以幅度较小。在靠近峰值的更远区域,情况会有所不同。那里的向量(绿色箭头)会陡然向下,并且由于起伏较大,梯度向量的幅度也较大。
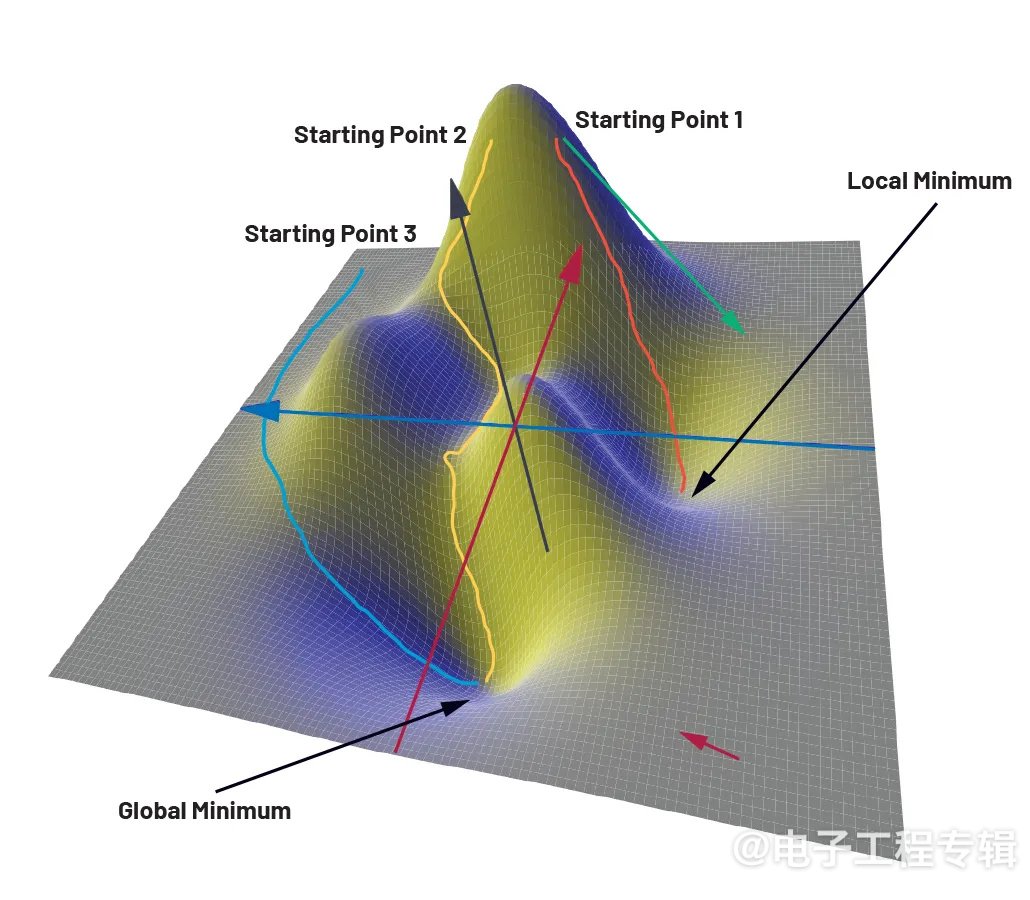
图3:使用梯度下降法到达目标的不同路径。
梯度下降法是从任意选择的一个点开始,迭代寻找进入波谷的最陡下降路径。这意味着,优化算法会计算起点的梯度,然后朝着最陡的下降方向先迈出一小步。在这个中间点,梯度被重新计算,进入波谷的路径继续延伸。这样,就形成了一条从起点到波谷中某一点的路径。这里的问题在于,起点并不是预先确定的,而是必须随机选择的。在二维地图中,细心的读者会把起点放在函数图的左侧。这将确保(例如蓝色)路径的终点位于全局最小值处。其他两条路径(黄色和橙色)要么更长,要么在局部最小值处结束。由于优化算法必须优化的不仅仅是两个参数,而是成百上千个参数,因此很快就会发现,起点的选择只能是偶然正确的。在实践中,这种方法似乎无济于事。这是因为根据所选起点的不同,路径可能很长,训练时间也可能很长,或者目标点可能不在全局最小值上,在这种情况下,网络的准确性就会降低。
因此在过去几年中,人们开发了许多优化算法,旨在绕过上述两个问题。其中包括随机梯度下降法、动量法、AdaGrad、RMSProp和Adam等算法。因为每种算法都有特定的优缺点,故实际采用的算法由网络开发人员决定。
数据训练
如前所述,在训练过程中,会为网络提供标有正确对象类别(如汽车、轮船等)的图像。在该示例中,采用了已有的CIFAR-10数据集。在实践中,人工智能的应用可能不仅局限于识别猫、狗和汽车。例如,如果必须开发一种新的应用来检测生产过程中螺丝钉的质量,那么也必须使用好螺丝钉和坏螺丝钉的训练数据来训练网络。创建这样一个数据集,可能会非常费力和费时,通常也是开发人工智能应用最昂贵的一步。一旦数据集编译完成后,就会被分为训练数据和测试数据。如前所述,训练数据用于训练,测试数据用于在开发过程的最后阶段检查受训网络的功能。
(原文刊登于EE Times姊妹网站Embedded,参考链接:Training convolutional neural networks,由Franklin Zhao编译。)
本文为《电子工程专辑》2024年4月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。