
生成式人工智能应用的爆炸式增长,刺激了对人工智能服务器和处理器的需求飙升,而这些处理器中的大多数(包括AMD和英伟达的计算GPU,英特尔的Gaudi或AWS的Inferentia、Trainium和FPGA等专用处理器)都采用高带宽内存(HBM),因为它提供了当今最高的内存带宽。根据TrendForce早些的数据,三家存储器制造商(美光、三星和SK海力士)在2023年度计划将高带宽内存(HBM)的产量增加一倍,并在2024年进一步增加。该计划也为存储行业带来了挑战。

图1:美光存储器发展路线图。(来源:美光)
但有很多人工智能处理器,特别是那些为运行推理工作负载设计的处理器,还有HPC处理器,都要用到GDDR6/GDDR6X甚至LPDDR5/LPDDR5X存储器。不过,通用CPU也可以运行人工智能工作负载(针对特定指令进行优化),其中采用的是商用内存。这就是为什么在未来几年,人们将会看到把容量和带宽都有显著提高的MCRDIMM和MRDIMM内存模块。不过,HBM仍将是带宽之王。

表1:存储器带宽与容量比较。(来源:embedded.com)
HBM:不惜代价的带宽
考虑到现代类型存储器的性能规范和功能,HBM在带宽密集型应用中如此受欢迎的原因显而易见。在每个堆栈约1.2TB/s的情况下,没有任何传统存储器能够在带宽方面胜过SK海力士的HBM3E。但带宽是有代价的,在容量和成本方面也有一些限制。
“由于间距小,HBM不仅具有优越的带宽,而且还有卓越的低功耗性能。”人工智能工程联盟MLCommons执行董事David Kanter表示,“不过其主要缺点是需要先进封装,从而限制了供应,也增加了成本。尽管如此,HBM几乎肯定会一直占据一席之地。”
正是由于HBM的这些缺点,使得DDR、GDDR和LPDDR类型的内存也存在于许多带宽密集型应用,包括AI、HPC、图形和工作站。美光表示,这些容量和带宽优化型存储器的开发正在迅速进行,因此人工智能硬件的开发工程师对其有着明确的需求。
“HBM是一项非常有前景的技术,其市场在未来有很大的增长潜力。”美光计算和网络业务部门高级经理Krishna Yalamanchi表示,“目前,其应用领域包括人工智能、高性能计算和其他需要高带宽、高密度和低功耗的应用。随着越来越多的处理器和平台采用它,市场预计将会快速增长。”
与此同时,Rambus则表示,市场显然需要提高带宽和容量。该公司开发、许可并帮助实现各种应用、包括用于人工智能工作负载处理器的内存控制器。
“人们在人工智能市场上继续看到的是,数据集越来越大。”Rambus负责产品营销、接口IP的副总裁Joe Salvador表示,“性能需求、内存带宽和内存容量都在呈指数级增长。一件有趣的事情是,自2012年以来,训练模型以每年10倍的速度增长,而且似乎没有放缓的迹象。”
特别有趣的是,那些需要HBM的公司,往往会在一夜之间采用该标准的最新迭代,Rambus表示,HBM2E几乎还没开始用于设计,其新迭代却已登场。
“今天,几乎还没有看到什么新的HBM2或HBM2E设计,市场风口就已经发生了转变。”Salvador说。大多数新芯片设计要么使用HBM3,要么使用全新的HBM3E,Rambus的存储控制器的数据传输速率高达9.6GT/s。Rambus表示,集成具有9.6GT/s功能的HBM3E存储控制器,其功耗不应该增加太多,不过可以肯定的是,HBM3E PHY和9.6GT/s HBM3E堆栈的功耗肯定要高于普通的HBM3 PHY和HBM3堆栈。
HBM生产艰难
TrendForce并不是唯一对HBM存储器的未来做出乐观预测的公司。Gartner也预计,2027年高带宽存储器的需求,预计将激增至惊人的9.72亿GB(2022年为1.23亿GB),这意味着HBM比特需求占DRAM总量将从2022年的0.5%增至2027年的1.6%。这一激增归因于传统人工智能和生成式人工智能应用对HBM的需求不断增加。

图2:三星的HBM3堆栈。(来源:三星)
Gartner分析师认为,HBM的收益将从2022年的11亿美元上升到2027年的52亿美元,尽管其价格将比2022年的水平下降40%。另外,由于技术进步和存储器制造商的投入不断增加,HBM堆栈的密度也将增加,将会从2022年的16GB增加到2027年的48GB。与此同时,美光似乎更为乐观,预计2026年左右就会推出64GB HBMNext(HBM4)堆栈。HBM3和HBM4规格允许构建16-Hi堆栈,因此可利用16个32Gb器件来构建64Gb HBM模块,但这将要求存储器制造商减少存储器IC的间距,包括使用新的生产技术。
鉴于英伟达占据了计算GPU市场的最大份额,该公司很可能是该行业最大的HBM存储器消费者,并将持续一段时间。该公司的A30配备了24GB的HBM2,A100配备了80GB的HBM2E,H100具有80GB的可用HBM2E(PCIe)或HBM3(SXM),H200提供了141GB的HBM3E,而GH200是第一个具有96GB HBM3或141GB HBM3E的产品。
但从根本上讲,生产HBM KGSD(已知良好堆叠裸片)比生产传统DRAM芯片更复杂。首先,用于HBM的DRAM器件与用于商用存储器(例如,DDR4、DDR5)的典型DRAM IC完全不同。生产商必须先生产8或12个DRAM 器件,通过测试后再将其封装在预测好的高速逻辑层上,然后再进行完整封装测试。该过程成本高,耗时又长。
HBM堆叠基于3D堆叠DRAM架构,该架构利用硅通孔(TSV)垂直连接多个裸片,这与商用DRAM有着根本的不同。这种带TSV的堆叠架构支持非常宽的内存接口(1024位),高达36GB的内存容量,并支持超过1TB/s的高带宽操作。为了支持这种并行宽接口,DRAM排列和数据结构都经过了彻底重新设计。
尽管HBM体系结构很复杂,但由于生产方法是众所周知的,总体上不应该非常昂贵,在内存领域拥有多项专利的DataSecure首席技术官兼布尔实验室首席技术官/首席科学家Michael Schuette如此认为。
Schuette说:“这些并不是一个可怕的成本加法器,工具和方法是从3D NAND建立的,可以为连接做硅通孔,所需要的只是从3D NAND移植到现有的TSV方法上。”
但是用于HBM的DRAM器件必须具有宽接口,它们在物理上比常规DRAM IC更大,故成本更高。因此,美光首席执行官Sanjay Mehrotra表示,为满足人工智能服务器的需求,HBM存储器产量的增加将影响所有DRAM类型的供应。
“HBM的生产将成为行业比特供应增长的逆风。”Mehrotra在最近的一次电话会议上表示,“HBM3E裸片的尺寸大约是等效容量DDR5的两倍。HBM产品包括逻辑接口裸片,并且封装堆叠从本质上更复杂,从而影响产量。因此,HBM3和3E的需求将吸收行业中相当比例的晶圆供应。HBM3和3E产量的增加,将降低整个行业DRAM位供应的总体增长,随着更多产能被转移到HBM上,对非HBM产品的供应产生了特别影响。就提升比特供应能力而言,美光正在经历的,与之前规划HBM3E时的艰难爬坡相类似。”
HBM3E本质上是具有显著减速带的HBM3,因此,尽管DRAM制造商必须确保可观的产量,然后调整生产方法,以更有效地构建8-Hi 24GB和12-Hi 36GB HBM3E KGSD,但新型存储器不会代表HBM生产的重大转变。相比之下,它的“继任者”可能会。
HBM4:更宽,迈向3D
HBM4将把存储器堆栈接口扩展到2048位,这将是自八年前引入这种存储器类型以来HBM规范最重大变化之一。将I/O引脚数量增加两倍,同时保持相似的物理占位面积,这无论对存储器厂商、SoC开发人员、代工厂,还是外包组装和测试(OSAT)公司来说,都极具挑战性。三星表示,HBM4将需要从目前用于HBM的微凸块键合(这已经很难且昂贵)过渡到直接铜到铜键合,这是一项最先进的技术,将在未来几年用于多芯片设计的集成。

图3:采用Xperi的DBI Ultra技术的3D堆叠内存解决方案。(来源:Xperi)
“如果看看即将推出的HBM4规格和2048位宽接口,引脚数量将达到约5500个,这与大多数服务器CPU或GPU(就引脚数量而言)处于同一水平。”Schuette说,“如果试图以小的占位面积来设计布线,最终的再分配层/中介层将会多达20层,如果选择更大的占位面积和更少的层,最终就会超过允许的最大走线长度。”
SK海力士甚至设想HBM4必须在系统级芯片上进行3D集成,以实现最大效率,但这将进一步增加成本。“在未来几年,我们可能会通过更紧密的集成(例如3D堆叠)获得更高的性能和效率,但这可能会更昂贵。”Kanter说道。
Schuette认为,由于HBM4的极端引脚数量,如果再采用中介层和再分配层的传统方法,将具有2048位接口的HBM4堆栈连接到主处理器可能会非常困难。“哪怕是最微小的弯曲,都会导致连接不良。”Schuette解释道,“如果只是一个地引脚,设计师可能不会注意到,但如果它是一个信号引脚,就完蛋了。”
但3D封装技术将需要更复杂的设备,因此很可能(至少是初始阶段)只有代工厂才有这种能力,在2025~2026年实现HBM4集成。
据报道,为了保持DRAM单元尺寸的缩小和内存功耗的控制,三星打算在HBM4中使用FinFET晶体管。通过FinFET的引入,有望优化即将推出的HBM器件的性能、功耗和面积微缩。然而,这项技术对成本的影响仍不确定。此外,三星何时能在标准DRAM IC中实现FinFET也尚未确定。目前,三星只确认了FinFET将用于HBM4。
Salvador说:“HBM4仍然会有成本问题,也还会有实施问题,故HBM3/HBM3E的使用寿命可能会延长,特别是在成本更敏感的地方。”
“人们可能会想采用最快的版本,但这也并非是一个准确的假设 。对于HBM来说,许多因素都会影响存储器技术的选择,如成本、供应链限制、平台准备情况以及性能要求。”Yalamanchi说道。
由于架构和封装成本的根本不同,HBM仍将是一种昂贵的存储器类型,服务于不断增长的利基市场。Schuette部分赞同这一观点,并认为,尽管HBM能够很好地服务于其目标市场,但很难应对更广泛的市场。“HBM似乎仍然是一种小众产品,而且很可能一直都是这样。”Schuette说道。
那么,HBM是否会在成本上与商用内存或专业内存竞争?
“不能说永远不会,但这真的是一段很长的时间。”Kanter说,“不过,HBM要想具有成本竞争力,就需要大幅降低封装成本,除非是GDDR的成本大幅提高。或者出现一个根本性的技术转变,比如,GDDR从高速铜信号切换到光学信号。不过不确定到那时是否还是GDDR。”
LPDDR:低功耗选项
虽然HBM在性能方面无与伦比,但对于许多应用来说,它既昂贵又耗电,因此有些开发人员选择在带宽要求高的应用中选用美光的LPDDR5X,因为这种类型的内存提供了价格、性能与功耗之间的平衡。
例如,在LPDDR成为一种趋势之前,苹果的个人电脑多年来一直采用LPDDR内存。目前,苹果已经很好地完善了基于LPDDR5的内存子系统,其性能是其他竞争解决方案所无法比拟的。其高端台式机(内置M2 Ultra SoC的Mac Studio和Mac Pro)采用两个512位内存接口,带宽达到惊人的800GB/s。而AMD最新的Ryzen Threadipper Pro,配置12通道DDR5-4800内存子系统,峰值带宽也才达到460.8GB/s。
其实,像苹果那样,在所有设备上采用LPDDR5还有一些额外的好处,例如可在不同的SoC中重复利用LPDDR 5控制器IP和PHY,再就是大批量采购可得到更好的价格。苹果当然不是将LPDDR内存用于带宽密集型处理器的唯一用户,Tenstorrent也将这种内存用于其Grayshell AI处理器。
“如今,它们似乎服务于不同的利基市场,而且存在着广泛的差异趋势。”Kanter说,“HBM更面向数据中心,LPDDR更面向边缘。实际上,在面对类似的市场时,设计师通常采用不同类型的内存。比如在数据中心的推理设计中,HBM、GDDR、常规DDR与LPDDR皆有用到。”
LPDDR存储芯片的明显优势之一,是其相对宽的接口和相当快的操作。典型的LPDDR5和LPDDR5X/LPDDR6T IC具有32或64位接口,支持高达9.6GT/s的数据传输速率,这比大规模生产的DDR5所支持的数据速率要宽得多,也快得多。此外,移动内存自然比客户端PC和服务器的主流DDR内存功耗更低。
对于利用Tenstorrent来开发的应用来说,内存带宽当然重要,但功耗也是至关重要的,这就是为什么LPDDR的使用范围如今远远超出智能手机和客户端PC。
GDDR:性价比之间的平衡
Tenstorrent为业界带来了另一种类型的内存,将用于即将推出的虫洞和黑洞AI处理器。同时,英伟达将GDDR6和GDDR6X用于各种人工智能推理的GPU。

图4:三星的GDDR6内存。(来源:三星)
“GDDR内存已用于AI和其他应用,其实对于人工智能推理应用也是好选择,因为相较DDR ,GDDR 能够提供更高带宽与更低延迟。”Yalamanchi说道,“GDDR的 成本低,并且技术上也没有HBM那么复杂。 例如, GDDR6用于英伟达的特斯拉T4 GPU,该GPU用于人工智能推理,而L40S则用于人工智能推理和图形应用。”
GDDR6的功耗通常比LPDDR要高,而最新的GDDR6/GDDR6X芯片具有32位接口(比LPDDR5X窄),但GDDR6/GDDR6X/GDDR7存储器运行速度要快得多。
事实上,GDDR7运行速度可高达36GT/s,对于如此高的数据速率,基于它的内存子系统将会大大快于那些采用LPDDR5X的系统,特别要记住,我们谈论的是潜在宽内存接口,如384或512位。即使在32GT/s的数据传输速率下,384位LPDDR7内存子系统的峰值带宽也可设置到1536TB/s,这远高于512位LPDDR5X-9600内存子系统(614.4GB/s)。不过,可以想象得到,LPDDR7内存子系统的功耗将比采用LPDDR5X的内存子系统更高,但考虑到其性能,这也是合理的权衡。
MCR-DIMM与MR-DIMM
如果没有MCR DIMM和MR DIMM,关于高性能内存解决方案的故事就不完整。这是一种主要为服务器设计的新型双列DDR5内存模块,目前正在开发中。该技术的理念是,在每个CPU的内核数量持续增长的情况下,进一步提高内存模块的效率,并将其峰值带宽提高到DDR5支持的速度之上。

图5:海力士的MCR-DIMM模组。(来源:SK海力士)
MCR-DIMM与MR-DIMM
对于高级别,将多路复用器与DIMM(MCR-DIMM)列集成在一起,构成一种配备有多路复用缓冲器的双列缓冲存储器模块。该缓冲器可以同时从两个列中检索128字节的数据,与存储器控制器一起工作,速率高达约8800MT/s(基于Micron最近发布的路线图),这比原始DDR5规范指定的最高数据速率还高出400MT/s。这些模块除了提高性能,还简化了高容量双列模块结构。MCR-DIMM由英特尔和SK海力士支持,并计划用于英特尔的第六代Xeon可扩展“Granite Rapids”平台,而美光则计划在2025年初推出MCR DIMM。
而多级缓冲DIMM(MR DIMM)在概念上与上述模块非常相似,也是具有多路复用缓冲器的双列模块,缓冲器同时与两个列交互,并以超过DDR5设计速率的速度与内存控制器一起工作。该标准将从第一代8800MT/s的速度开始,第二代提高到12800MT/s,最终到第三代激增到17600MT/s。这项技术得到了JEDEC、AMD、谷歌和微软的支持。对于第二代MR DIMM,美光计划2026年开始出货。该类模块将提供巨大的带宽和容量,来应对数据中心CPU内的内核数量不断增加以及对带宽的迫切需求。
“如果不采用各种新的形状因子来进行分类存储,那将是愚蠢的!”Schuette说道,”服务器的要求与客户端的不同,服务器上总是需要ECC,而客户端电脑上则不需要。”
奇特的混合内存子系统
对于芯片和系统开发人员而言,虽然选用特定类型的内存可能是最公认的做法,但也有人选择采用不同类型的内存,来构成混合内存子系统。
例如,英特尔的Xeon Max CPU,HBM2e封装内配有64GB,并支持高达6TB的六通道DDR5内存,每个插槽最多使用16个DIMM。这些CPU主要针对高性能计算(HPC)环境,可以工作在纯HBM模式、HBM扁平模式(提供快速和慢速内存不同等级)以及HBM缓存模式。
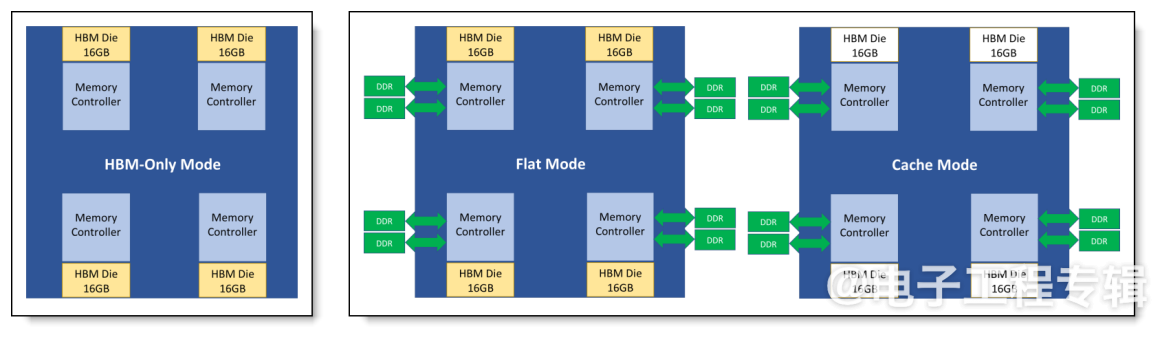
图6:Sapphire Rapids HBM的不同操作模式。(来源:联想)
另一个例子是D-Matrix的AI处理器,内置256MB的SRAM(150TB/s),支持高达32GB的LPDDR5内存,不过带宽有限。这些芯片主要用于推理,其架构是为此类工作负载量身定制的。
“一般来说,缓存或片上SRAM可以减少一些外部带宽需求。”Kanter说,“因此,就推理而言,如果能够使用小于100MB的神经网络,利用缓存将有所助益。同样,为了减少片外带宽,可以将存储器集成得更靠近一些。但对于真正大型的训练系统,如训练下一代LLM,许多前沿工作总是需要更高带宽。”
由不同类型的存储器组成的奇特的混合存储器子系统,尽管历史上已用于各式各样的应用,例如用于Xbox 360游戏机的、带有基于eDRAM“子裸片”的ATI Xenos GPU,或同时使用MCDRAM和DDR4存储器的Intel Xeon Phi 7200系列协处理器。不过,Schuette认为这种存储器子系统并不完全有效。“想两全其美是最糟糕的。”他说,“这是一个巨大的设计开销,而且非常复杂,使得故障排除成为一个大问题。”
另一方面,根据定义,所有带CPU和加速器的系统都采用混合内存子系统,并且它们已被证明是非常高效的。“目前许多人工智能系统都是混合系统。”Kanter说道,“例如,许多训练系统喜欢选择HBM用于加速器,而选择DDR用于(做实际工作的)主处理器,这有点类似于数据中心推理系统。”
(原文刊登于EE Times姊妹网站Embedded,参考链接:High-bandwidth memory (HBM) options for demanding compute,由Franklin Zhao编译。)
本文为《电子工程专辑》2024年4月刊杂志文章,版权所有,禁止转载。免费杂志订阅申请点击这里。
- 居然看完了。。。。
