
作为一套经优化、集成和验证的平台,Arm Neoverse计算子系统(CSS)汇集了构成系统级芯片(SoC)核心的关键技术,“为最重要的工作负载优化其TCO,并为芯粒(Chiplet) 等新兴关键技术提供支持”是其核心价值所在。
进入2024年,Arm Neoverse的旅程开启了新的篇章,主角是两款全新的Neoverse CSS产品:Neoverse CSS N3和Neoverse CSS V3。官方数据显示,与Neoverse CSS N2相比,Neoverse CSS N3的每瓦性能可提高20%;Neoverse CSS V3单芯片性能可提高50%。
同时,Arm全面设计(Arm Total Design)生态项目也已吸引超过20家来自各方技术合作伙伴的加入,他们已在方方面面携手合作,从验证 IP、定制固件,到在全球先进的工艺节点上打造芯粒。
人工智能基础设施迎来巨变
Arm高级副总裁兼基础设施事业部总经理Mohamed Awad指出,AI时代,计算正变得越来越专用化,现代化数据中心系统架构中需要更多定制而非通用CPU。“NVIDIA GH200 Grace Hopper正是这种理念的体现。“他说,与传统架构中单个CPU管理多个GPU不同,Grace Hopper中的GPU和CPU之间建立起了一对一的高性能连接,并在整个系统层面实现内存一致性,从而大幅提高了GPU的效率。
事实也的确如此——72颗Arm Neoverse核心与NVIDIA GPU的组合,让Grace Hopper的AI性能较基于x86架构的系统提升了10倍。
采用类似设计方法的不止NVIDIA。AWS第四代基于Arm Neoverse平台的处理器Graviton4相比上一代产品,处理速度提高了30%,核心数量增加了50%,内存带宽增加了75%。
“此方法之所以能发挥作用,是因为客户比任何其他人都更了解自己产品的工作负载,他们可以对系统的各个方面,包括网络、加速甚至是通用计算进行调优,以优化效率、性能和总体拥有成本(TCO)。“Mohamed Awad表示,AI正变得无处不在,它不仅应用于服务器和数据中心,也正成为网络、安全和存储等诸多领域不可或缺的一部分,从而使其应用领域拓展到包括小型终端到交换机、路由器和基站等各种设备在内的整个基础设施中。
卓越性能、高度灵活性和强大生态系统,是Mohamed Awad认为Arm能在基础设施领域收获累累硕果的三大原因。“过去的几年里,Arm工程团队坚持不懈地实现产品迭代提升,赋能技术合作伙伴定制芯片,以支持其专用的工作负载和系统,而非采用一体适用的方案。同时,得益于我们在软件、IP和芯片生态系统中提供的出色性能和灵活性,降低了配置的总成本并加速产品上市。“他说。
以此为基础,Arm推出了Arm Neoverse CSS和Arm全面设计生态项目,核心目的是希望能够帮助合作伙伴快速交付基于Neoverse CSS的定制SoC,帮助降低合作伙伴的创新成本,并将其想要构建的定制数据中心计算系统更快推向市场。微软首款专为计算中心打造的定制芯片Azure Cobalt 100 CPU正是基于Arm Neoverse CSS打造,该芯片具有128颗 Neoverse内核。
在Neoverse CSS 中,Arm负责配置、优化和验证一套完整的计算子系统,并针对基础设施市场的各种关键用例进行配置,从而让合作伙伴能够专注于针对特定系统级工作负载塑造差异化竞争优势,比如软件调优、定制加速等。此外,客户还能从CSS中额外获得加速产品上市时间、降低工程成本、前沿处理器技术等优势,芯片栈的管理也变得和软件/系统栈管理一样便捷。
Arm Neoverse旅程的新篇章
“温故才能知新”,不妨先简单回顾一下Neoverse平台的PPA设计原则和发展历程:
目前,该系列分为V/N/E三大平台:V系列旨在提供最佳性能,需要添加更大的缓存、窗口和队列,相对来说会消耗更多面积和功耗;N系列强调性能、功率、面积得到同等考量,擅长可扩展;E系列主要关注效率,对于网络流量和数据应用程序非常有效,在功耗和面积的缩减上进行优化。
2018年10月,Arm首次宣布推出面向云到边缘基础设施产品Neoverse及其初步路线图,并承诺平台效能30%的年增长率指标将持续到2022年及以后。2019年初,Arm推出了Neoverse N1和E1;2020年9月,Neoverse家族又新增两个全新的平台—Neoverse V1平台以及第二代N系列平台Neoverse N2;两年后,Neoverse V2平台、Neoverse E2和Arm CMN-700 mesh互连技术面世,并引入若干Armv9架构安全增强功能。
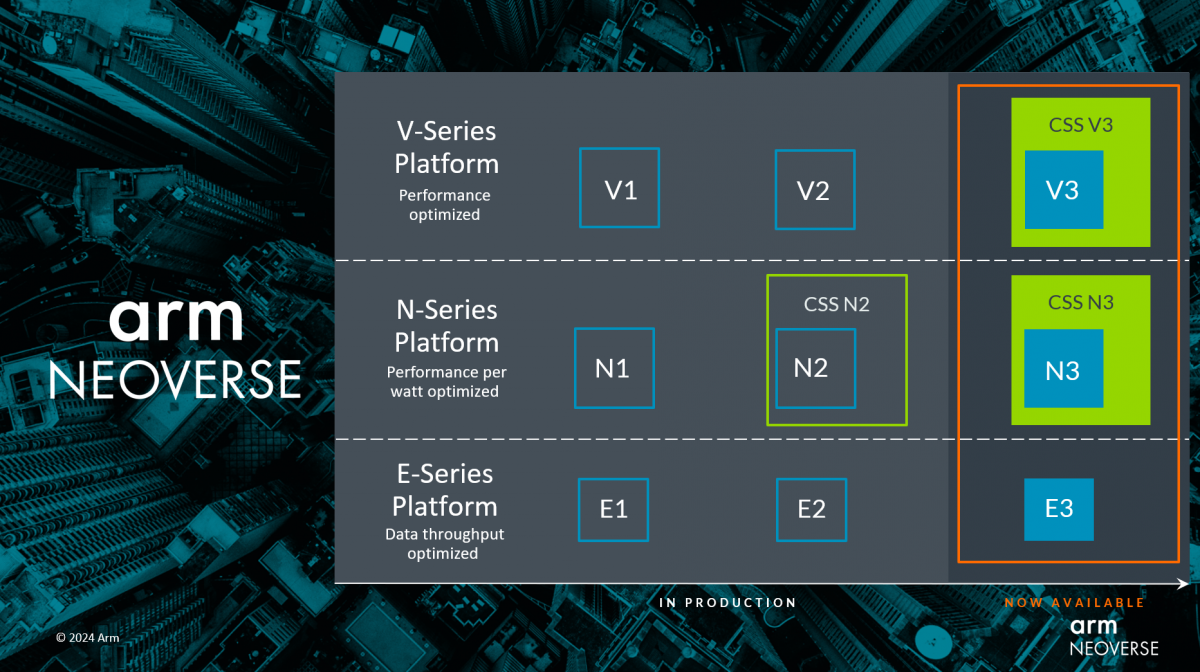
根据Arm基础设施事业部产品解决方案副总裁Dermot O’Driscoll的介绍, CSS N3 的首个实例可提供32核,热设计功耗(TDP)低至40W,可覆盖电信、网络和DPU等一系列应用。同时,考虑到横向扩展云配置需要,Arm为新的N系列引入了Armv9.2功能,能为每个核心提供2MB的专用L2缓存,并支持最新的PCIe、CXL I/O标准以及UCIe芯粒标准。
CSS V3在单芯片上最多可扩展至128核,并支持最新的高速内存和I/O标准,CSS V3 基于Arm新的 Neoverse V3 核心打造,这是Arm目前单线程性能最高的Neoverse核心,专为Arm机密计算架构(CCA)提供硬件支持。与N3核心一样,V3核心也可提供专用L2缓存。
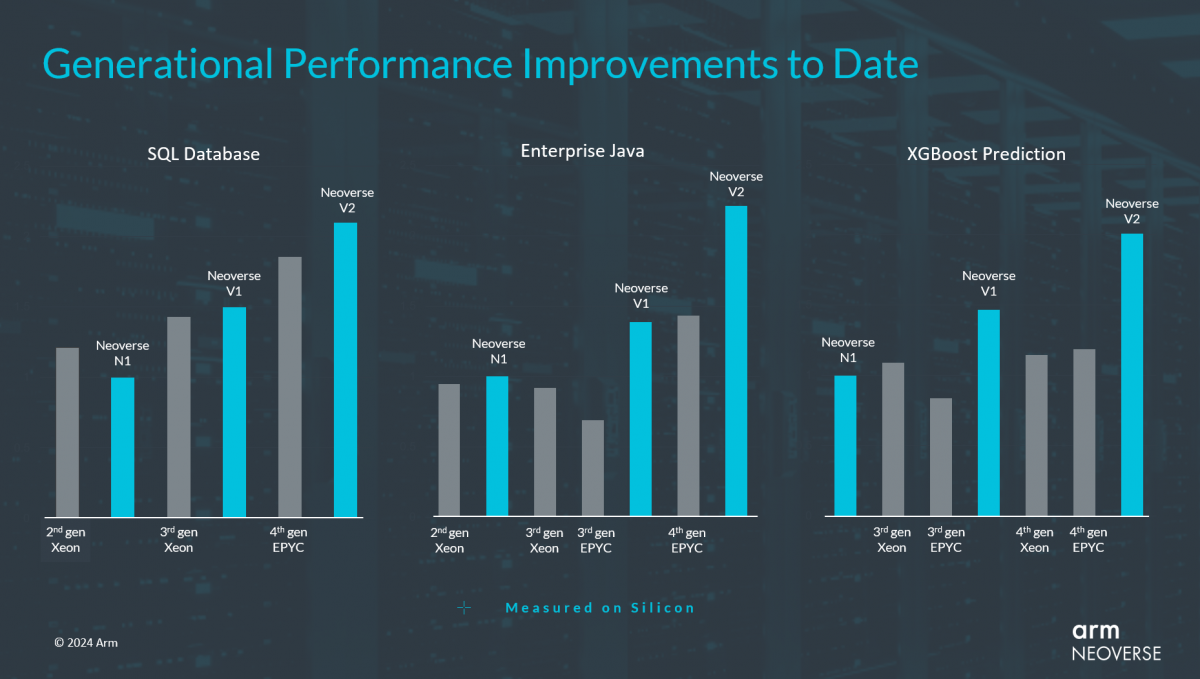
基于Neoverse N系列和V系列打造的芯片在一些关键工作负载下的性能数据
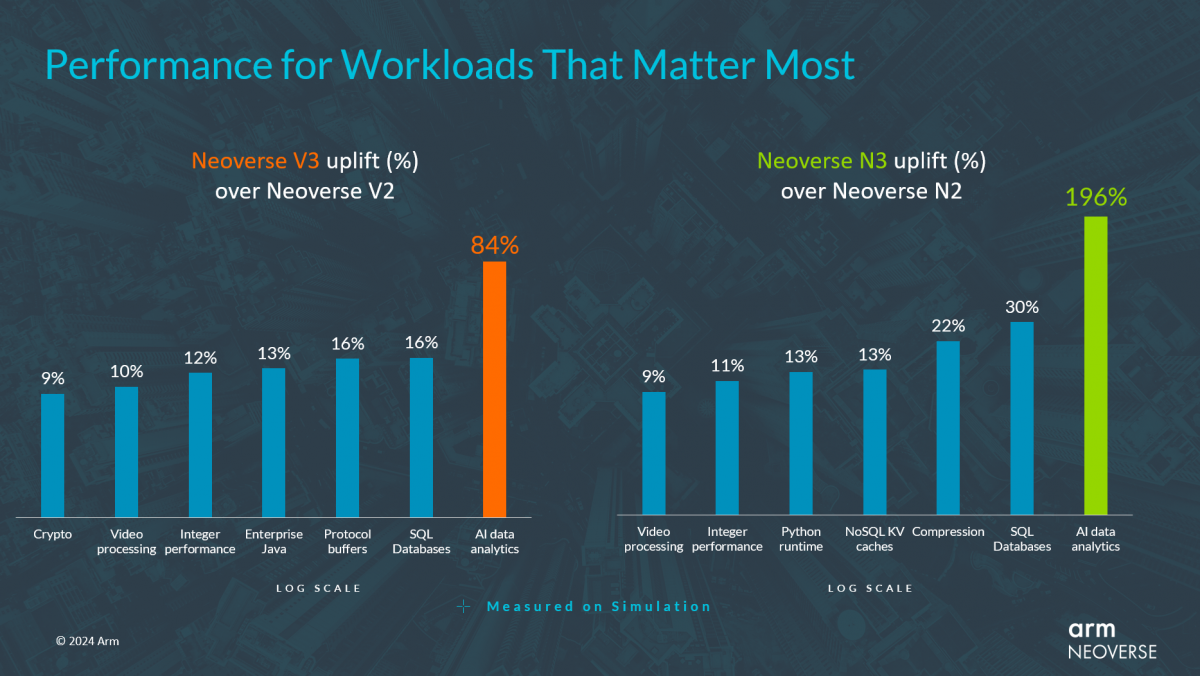
Neoverse CSS N3和Neoverse CSS V3的性能提升对比
“通过分析合作伙伴的关键工作负载核心的特定关键任务算法,我们能够明确并实施对提升性能最有效的微架构调整方法,包括改进分支预测、更好地管理最后一级缓存和相关内存带宽,以及大幅增加L2缓存,这也是为什么N3在基于XGBoost库的AI数据分析方面有高达196%性能飞跃的原因所在。”Dermot O’Driscoll说。
自2023年以来,生成式AI和大语言模型(LLM)成为了AI行业当仁不让的热点。随着生成式AI广泛应用于实际业务场景,推理将成为工作重点,有分析师预计,已部署的 AI服务器中将有高达80%专用于推理,且这一数字还将持续攀升。这一转变意味着要找到合适的模型和模型配置,并加以训练,然后将其部署到更具成本效益的计算基础设施上。这其中,高吞吐量、易于部署、支持各种软件框架、且具备低成本和高能效等优势的CPU,是行业追逐的热点。
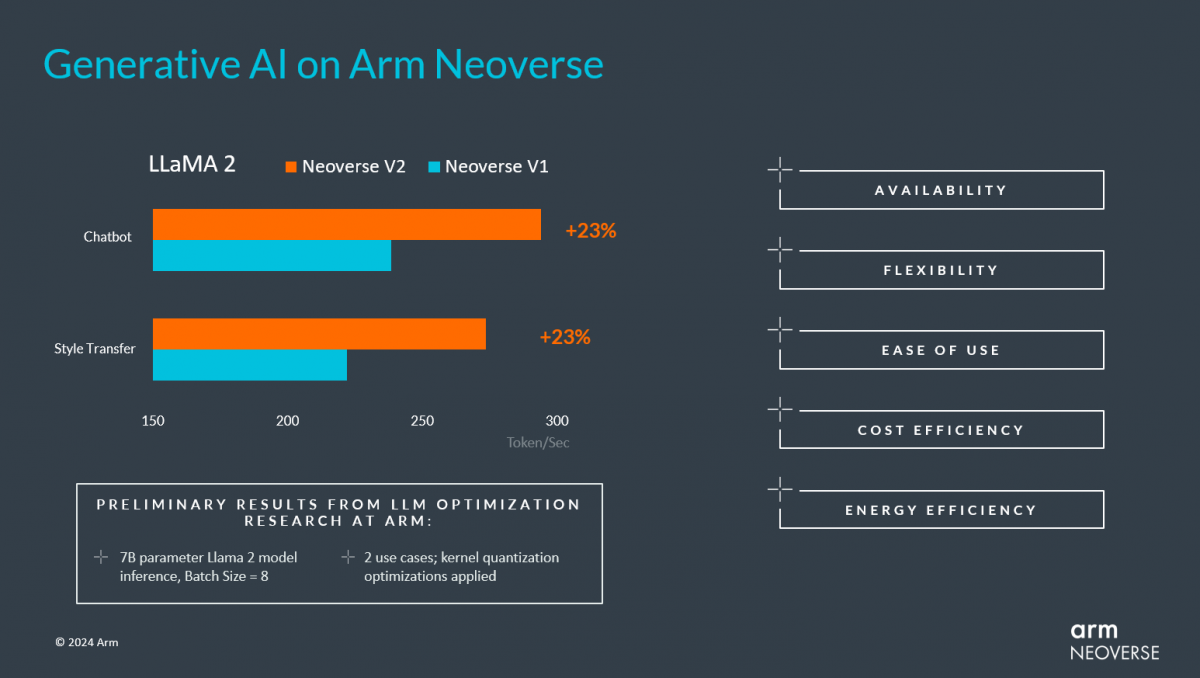
Arm在LLaMA 2大型语言模型上的AI推理基准测试
但显然,并非所有AI处理都将在CPU上进行。打造AI加速器的公司非常多,据最近统计,这一领域的公司已接近80家,而且每家公司都想取得NVIDIA那样的成绩。Dermot O’Driscoll表示,像微软(Cobalt 100)这样的厂商迅速采用Neoverse以便快速整合自己的芯片设计并投入使用,证明了Neoverse CSS策略非常成功。
通过Neoverse CSS,Arm可以为针对自身工作负载优化性能的客户简化开发,特别是那些只需要经过验证的CPU IP模块来与其定制加速器设计配对的客户,Neoverse CSS能提供客户所需的所有接口,以便选择耦合自身的加速器。“这种方法既可以在需要CPU时提供CPU,又可以在需要AI 加速器时提供AI加速器,两全其美。”
同时,基于生态伙伴的反馈意见,Arm还发布了芯粒系统架构(Chiplet System Architecture, CSA),旨在定义一个功能强大、支持通用的芯粒生态系统。以通用芯粒互连技术(UCIe)为例,这是一项旨在解决芯粒物理层兼容性问题的行业标准,因为目前的协议层存在PCIe、CXL和AMBA等多种标准,设计人员在系统架构层面仍面临诸多难题:例如,怎样在设计时对芯粒进行逻辑分区?如何设置直接内存访问(DMA)和中断、电源和安全等管理功能?等等。要建立可互操作的生态系统,就需要在生态系统层面一致地解决这些问题。
在Dermot O’Driscoll展示的未来路线图上,尽管不是太详细,但Neoverse E/N/V系列核心已经被分别命名为Lycius/Dionysus/Adonis,对应的计算子系统也获得了代号,分别为N系列的CSS Ranger和V系列的CSS Vega,将在未来推出。

