
电子工程专辑讯 近日,OpenAI在官网隆重介绍了一款文本转视频模型Sora。可以说Sora一出,再次引爆生成式人工智能的无限可能,尤其在视频模型领域。科技圈以及资本市场的投资焦点再次聚焦在OpenAI上。
从ChatGPT到文本转图像模型Dall.E,再到文本转视频模型Sora,据科技数据平台CB Insights报告指出,OpenAI现在是全球最有价值的科技初创企业之一,仅次于字节跳动和SpaceX。
纽约时报援引消息人士称,OpenAI已经完成了一笔交易,估值达到了800亿美元或更多。在不到10个月的时间里,OpenAI的估值增长了近两倍。
什么是Sora?
根据OpenAI官网介绍,Sora是一个 AI 模型,可以根据文本指令创建现实且富有想象力的场景,也就是文本转视频模型,可以生成长达一分钟的视频。OpenAI的定义是,我们正在教授人工智能理解和模拟运动中的物理世界,目标是训练模型来帮助人们解决需要现实世界交互的问题。
在OpenAI官网上从多个维度展示了基于Sora大模型生成的视频风格,Sora 可以生成具有多个角色、特定类型的运动以及主体和背景的准确细节的复杂场景。该模型不仅能够理解用户的提示词,还能了解提示词中所需要的物理世界中的存在方式。
此外,Sora可以在单个生成的视频中创建多个镜头,且保留角色的视觉风格。
当前存在的缺点分别有,Sora难以准确模拟复杂场景中的物理原理,以及事件发生的因果关系,比如,一个人咬了一口饼干,但这个饼干可能没有咬痕。还有就是空间细节问题,不能精准描述随着事件推移的事件。

图/OpenAI的论文:Video generation models as world simulators
值得一提的是,以往的图像和视频生成方式需要通过将视频调整或裁剪为标准尺寸,Sora可以采用宽屏1920x1080p 视频、垂直 1080x1920 视频以及介于两者之间的所有视频。解决了原生宽高比不同的设备之间,也可以完成视频内容创建。
目前,Sora并未完全开放。在Sora可用之前,OpenAI还需要采取一些重要的安全措施。OpenAI正在与红队成员(错误信息、 有害的内容和偏见等领域的领域专家)合作,这些红队成员将以对抗性的方式测试Sora模型的安全性。比如,在 OpenAI 的文本分类器中,将检查并拒绝违反其使用政策的文本输入提示,例如要求极端暴力、性内容、仇恨图像、名人肖像或他人 IP 的文本输入提示。
在技术上,Sora是如何自动生成视频?
Sora是一个扩散模型, 与OpenAI的GPT模型类似,Sora也是使用transformer的架构。基于大语言模型(LLM)的成功启发,这些模型通过“数据”训练来获得通用能力。
在OpenAI公布的技术报告中,OpenAI 称,LLM 的成功部分得益于标记的使用,这些标记优雅地统一了文本代码、数学和各种自然语言的不同模式。在这项工作中,我们将考虑如何继承视觉数据生成模型的这些优点。LLM 有文本标记,而 Sora 有视觉补丁。我们发现,对于在不同类型的视频和图像上训练生成模型来说,补丁是一种高度可扩展且有效的表示方法。

图/OpenAI的论文:Video generation models as world simulators
LLM的文本标记,就是将文本序列转化为模型可以理解的单个单词、词语等。Sora则将视频压缩到低维潜在空间中,然后将其分解为“时间空间补丁”,从而将视频转化为补丁。
OpenAI训练的“视频压缩网络”技术,是该网络将原始视频作为输入,并输出经过时间和空间压缩的潜在表示,Sora 在这个压缩潜空间内进行训练,并生成视频。
OpenAI还训练了一个相应的解码器模型,将生成的“半成品视频”还原像素。
总的来说,OpenAI的文本转视频大模型的三个关键步骤分别是视频压缩网络、空间时间潜在补丁提取、视频生成的Transformer模型。而Sora就是这个空间时间潜在补丁的一个步骤。

图/OpenAI的论文:Video generation models as world simulators
Sora 能给定输入的噪声片段(以及文本提示等调节信息),经过训练后,它可以预测原始的 "干净 "片段。Transformer模型在语言建模、计算机视觉、和图像生成等多个领域都表现出显着的扩展特性。
随着训练计算量的增加,样本质量明显提高。

图/OpenAI的论文:Video generation models as world simulators
OpenAI表示,“训练文本到视频生成系统需要大量带有相应文字说明的视频。我们将DALL·E 3 中引入的重新字幕技术应用于视频。我们首先训练一个高度描述性的字幕模型,然后用它为训练集中的所有视频制作文本字幕。我们发现,在高度描述性的视频字幕上进行训练可提高文本的保真度以及视频的整体质量。与 DALL·E 3 类似,我们也利用 GPT 将简短的用户提示转化为较长的详细字幕,并发送给视频模型。这使得 Sora 能够准确地按照用户提示生成高质量的视频。”
未来,OpenAI在视频制作上提供了便利,只要输入图像和提示词,Sora就可以生成视频。
如何权衡Sora模型带来的机会与隐患?
新模型Sora在视频内容制作方面让人感到震撼的同时,尤其是广告界或将迎来重大的转折点。以往视频广告的制作成本高昂,新模型Sora也将为一些中小企业提供了制作视频广告的新机会。
360公司创始人、董事长兼CEO点评道,AI不一定那么快颠覆所有行业,但它能激发更多人的创造力。Sora可能给广告业、电影预告片、短视频行业带来极大的颠覆,但它不一定那么快击败TikTok,更可能称为TikToK的创作工具。这次Sora只是小试牛刀,它展示的不仅仅是一个视频制作的能力,它展示的是大模型对真是世界有了理解和模拟之后,会带来新的成果和突破。同时意味着,通用人工智能(AGI)实现将从10年缩短到两三年。

不过,图灵奖获得者、Meta 首席科学家 Yann LeCun(杨立昆)则表示,“我从未预料到,看到这么多从未对人工智能或 ML 做出任何贡献的人,其中有些人在邓宁-克鲁格尺度(Dunning-Kruger scale)上已经走得很远,却告诉我关于人工智能和 ML 的种种错误、愚蠢、盲目、无知、误导、嫉妒、偏见、不合群等等……”

图/X:截图自Yann LeCun
与此同时,深度伪造也将成为一大隐患。根据民调机构YouGov调查显示,有将近85%的美国人对AI伪造表示非常或者有些担忧。
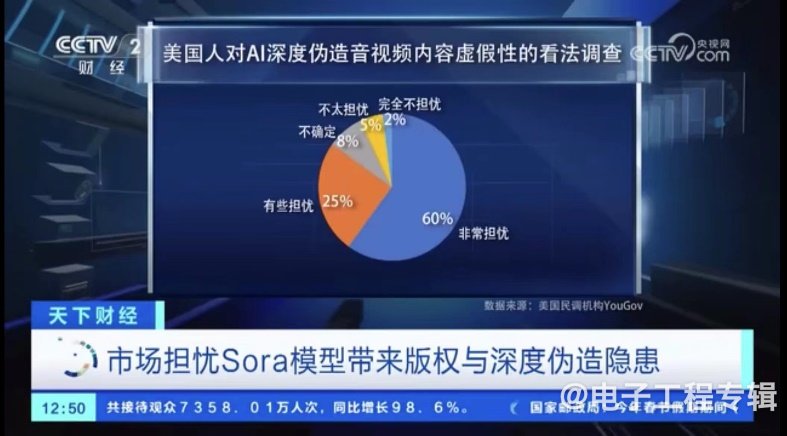
人们惊呼:“真实世界将不再存在。”
不少科技公司被加强要求对AI生成内容的管理力度,美国Meta公司2月6日称,该公司将推出一种检测并标识AI生成图片的技术,并将应用于该公司旗下Facebook、Instagram和Threads社交平台,为AI生成图片“打上标签”。不过,Meta公司也表示,该技术暂不适用于视频及音频。
不过如何识别不同平台的AI内容还是难点,目前该技术尚未成熟,不过Meta公司希望能够借由此项技术的推出“创造一种势头”,并“鼓励行业内其他企业跟进”。
本文参考自央视财经、OpenAI官网等内容报道

