
在《集成显卡前尘往事》一文中,我们回顾了PC集成显卡(iGPU)一路走来的光辉岁月。抛开PC还有“北桥芯片”的古早历史不谈,当代集显或核显,可以简单理解为集成在处理器芯片单个封装内的图形单元。
可能很多同学对于“集显”的理解还停留在“亮机”、性能差的程度上。其实这两年PC平台的主流CPU厂商因为各种原因,都在卷集显性能——现在的集显已经在向3A游戏看齐。抛开发展轨迹差异较大的Arm阵营不谈,x86这边2019年的酷睿10代处理器上,Intel将核显堆到了64个EU(执行单元),次年酷睿11代处理器的核显追加至96 EU,让集显玩一些轻量级的3D游戏变得很轻松;
2022年的AMD Ryzen 6000系列处理器RDNA 2核显性能甚至超过了10年前的独显卡皇,核显有了正儿八经玩游戏的可能性;而去年底Intel推出酷睿Ultra处理器,核显的堆料再度推升了PC中央处理器的图形算力门槛...

华硕灵耀14 2024(UX3405MA)
从PC用户的角度来说,核显的性能提升,让轻薄本有了追求算力的依据——毕竟轻薄本基于形态和功耗考量,通常都不会选择独立显卡。最近我们拿到一台采用酷睿Ultra 7 155H的轻薄本华硕灵耀14 2024——有机会来看看现在的笔记本处理器核显进化到了何种程度。


华硕灵耀14与联想ThinkPad T410i
为了让这种“进化”呈现得更具体,我们也找来了一台14年前的联想ThinkPad T410i笔记本。这款笔记本搭载的是当年最夯的酷睿i5-520M。这个系列的笔记本处理器代号为Arrandale。Arrandale的独特之处在于,它是最早将GPU和CPU集成到一个封装内的酷睿处理器,也就是最早具备“核显”形态的集成显卡。ThinkPad T410i笔记本的低配版图形算力就全部交给了酷睿i5-520M处理器集成的图形单元。
借此我们来看看2024年的核显,和2010年的初代核显比起来,性能和功能大概有多大程度的进化。
有关初代核显,及其功能局限说明
关注PC历史的同学应该知道,酷睿第1代产品是在2008年问世的,微架构代号Nehalem,也就是酷睿正式以i7, i5, i3这样的方式来命名产品型号之时。我们手上的这颗酷睿i5-520M虽说比Nehalem晚了2年。但单就CPU die的部分,它基本可以看做是Nehalem的工艺进化版,核心代号Westmere——也就是32nm版本的Nehalem。
换句话说Arrandale其实也属于酷睿1代。所以我们这次不仅是拿PC平台最新的核显和初代核显做对比,也是拿酷睿Ultra 1代与酷睿1代做对比,也还挺有历史意义...


但在对比前先说几句。因为这台ThinkPad T410i实在是太老了。原机器拿到手,为确保跑测试的兼容性过关,我们给它装了Windows 10。考虑到这台笔记本4GB RAM以及320GB机械硬盘的存储配置会严重影响其性能发挥;所以我们将内存升级到该平台支持的最高8GB,硬盘升级为SSD——虽然是SATA。
则这次对比的两台笔记本配置表大致如下:
 原本我们想得挺好,按照常规先跑图形渲染测试(包括游戏),然后跑通用加速测试,跑多媒体内容创作(主要是视频编解码),以及跑AI推理测试——现代GPU的重点考察项主要也就这些了。
原本我们想得挺好,按照常规先跑图形渲染测试(包括游戏),然后跑通用加速测试,跑多媒体内容创作(主要是视频编解码),以及跑AI推理测试——现代GPU的重点考察项主要也就这些了。
直到我们跑PCMark测试时,发现某些测试提示至少需要GPU支持OpenGL 4.3;启动《彩虹六号:围攻》游戏时则发现,酷睿1代无法支持对应版本的DirectX;以及打开Photoshop时提示GPU兼容性问题,包括不支持OpenCL加速;DaVinci Resolve这样的视频编辑软件则干脆不让打开…
事实证明,不支持OpenCL让这台ThinkPad T410i的核显根本就无缘用于许多常规工作的加速。那么测试的主要落脚点也只能放在图形渲染上了——又由于OpenGL与DirectX版本支持低,要跑现在的游戏和图形渲染测试(如3DMark 11)就成为奢望。
这其实某种程度上能够体现随着时代进步和技术发展,GPU在“功能”上变得更加丰富,不光是用在诸如游戏、专业视觉之类的渲染上,更多也广泛用在了通用计算加速、AI、视频编解码等场景。酷睿Ultra 7 155H的核显就能包揽这些活儿。这也体现了核显的进步。
另外在正式揭晓跑分成绩以前还得强调一点。即便我们期望做的主要是面向GPU核显的synthetic测试,但很显然华硕灵耀14 2024与联想ThinkPad T410i这两个系统的差异大到各个层面的完全不同,比如CPU的核心数目,内存与SSD的带宽与延迟,操作系统甚至图形中间件的差异。所以下面的对比更像是系统性能测试,CPU, 内存, 中间件都有可能成为制约性能的瓶颈,而不单是GPU的问题。
简单谈谈Arc核显与HD核显
先大致浏览一下这两颗处理器的参数,尤其是核显部分:

比较有趣的是,从封装的角度来看,酷睿Ultra 7 155H和酷睿i5-520M的核显,都与它们各自的CPU部分不在同一片die上,而且CPU die和GPU die的制造工艺还不一样。
对于酷睿i5-520M而言,单芯片封装内有两片die,小的那片里面就有CPU,采用当时最先进的32nm工艺制造。大的那片基本可以视作北桥芯片,里面有集显图形单元、内存控制器和IO。即便称其为“核显”有些牵强,但起码也是个片上GPU。这片die用的是45nm工艺。

来源:Wikipedia
这两片die基于QPI(QuickPath Interconnect)互联。虽然QPI取代FSB(前端总线)达成当时看来更高的带宽和更低的延迟,但就现在的眼光来看,QPI互联也是制约集显性能发挥的一部分因素。酷睿i5-520M和同时代其他Arrandale的双die形态,的确更像是单纯将北桥移到了片内——当时被戏称为CPU与GPU的“胶水融合”。不过物理距离近一点也总有好处嘛…
当年这颗代号为Ironlake的HD Graphics初代核显,在发布伊始还是挺惊艳的——不少3D游戏至少变得“可玩”——虽然这个“可玩”主要说的是功耗发挥更有空间的台式机平台(Clarkdale)。台式机平台Clarkdale的Ironlake将12 EU规格的GPU堆在片内,也让Intel的核显性能首次达到或超过了当时的集显竞品(典型如AMD 790GX)。

这么看来,2023年Meteor Lake(酷睿Ultra 1代)在核显上的进步及格局,其实跟当时的Arrandale(酷睿1代)非常相似。它也在绝对算力上超过了隔壁AMD的“大核显”,矢量引擎对比前代(96 EU Xe-LP)多了33%(128 EU Xe-LPG);加上架构与工艺改良及其他固定功能单元用料增加,Intel宣传GPU性能和能效都做到了翻番。
Meteor Lake的核显也是Intel第一次为其冠以Arc graphics的称谓(犹如Arrandale的核显也是第一次叫做HD Graphics),主要在于其借鉴了不少属于Arc独立显卡的技术。对光线追踪、XeSS等特性作出支持应该都是其中的组成部分。

很凑巧的是,Meteor Lake上的这枚核显,与CPU也不处在同一片die上。我们之前分析过Meteor Lake处理器的封装结构,其中详述了核显位于Graphics Tile之上,而CPU核心主要放在了Compute Tile。从制造角度来看,这片Graphics Tiles所用的乃是台积电5nm工艺(Compute Tile用的是Intel 4工艺)。
更重要的是,这个时代的多die和十多年前的多die,封装层面的技术水平也根本上不同。酷睿Ultra 1代与酷睿1代的显著不同之处在于,前者的多die方案是基于Intel的2.5D/3D先进封装,die间互联是借助于FDI(Foveros Die Interconnect),通信延迟和带宽,相较于基板走线的Arrandale就不在一个水平线了。
Arrandale→Meteor Lake这十多年的进化,是真正浓缩了半导体行业技术的演进历史的。借此来看核显的进步,也就更有趣了。
图形、视频编解码与AI,几十倍性能差距?
一般看GPU的图形渲染理论性能,大概3DMark测试是个不错的选择。但如前所述,3DMark Time Spy, Fire Strike之类的现代测试都是基于DirectX 11, 12,咱们这酷睿1代处理器完全跑不了。所以只能退而求其次地选了支持DirectX 9的3DMark 06,和以前还挺流行的Unigine Heaven Benchmark。得到的结果如下:
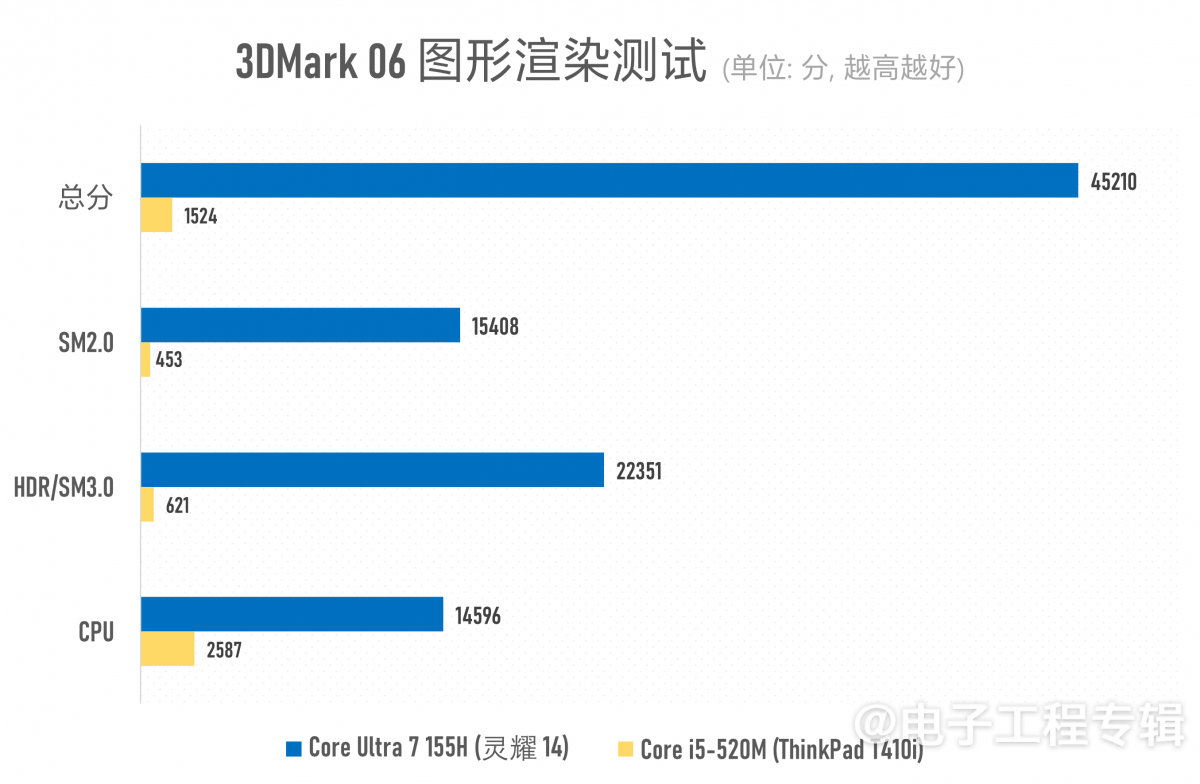
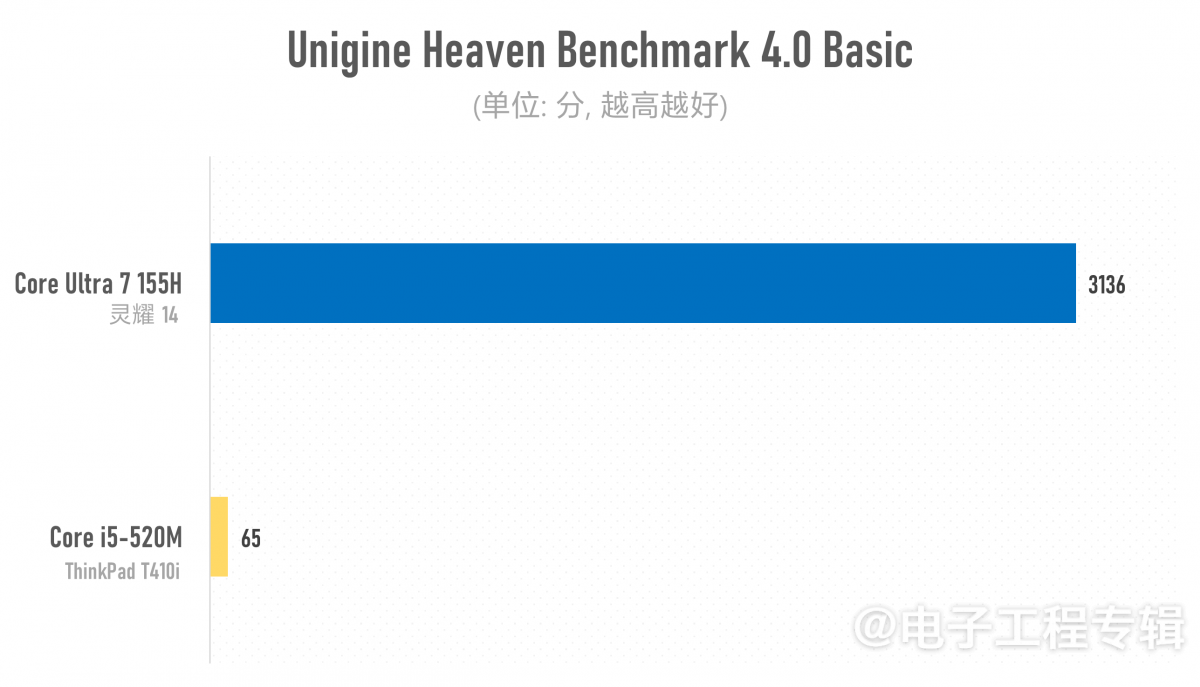
在3DMark历史版本的06版测试中,灵耀14的成绩大约是ThinkPad T410i的30倍。而Unigine Heaven Benchmark 4.0基础测试,前者的图形性能更是达到了后者的48倍——Unigine Heaven渲染测试基本也是即时演算一个复杂的3D场景。酷睿i5-520M平均只能跑到2.6fps的画面帧率,而酷睿Ultra 7 155H则能跑到124.5fps。
看来加速器是更能观察半导体行业摩尔定律发展的窗口…
其实对于酷睿Ultra 7 155H而言,单纯做DirectX 9的测试也是不怎么公平的。毕竟后续的DirectX版本引入了更多的图形新特性,都是历史版本所没有的。所以我们也简单为酷睿Ultra 7 155H做了3DMark 11的两项主流测试,供有兴趣的同学做参考和对比:

谈到随技术进步,GPU逐步引入更多新特性:前文已经提过,酷睿i5-520M的核显除了搞搞基于旧版图形API的渲染,也做不了别的。Windows平台的主流测试基本也都印证了这一点,要不就是提示兼容性问题,要不就是干脆不让跑。
在GPU额外特性的支持方面,至少媒体引擎、AI是现在很多PC用户都相当关注的。毕竟PC作为生产力工具时,视频内容创作与AI都越来越渴求GPU的性能。先谈谈媒体引擎。
一般我们现在习惯上把媒体引擎、编解码加速器当作是GPU的一部分。那当年的酷睿1代核显有没有这部分呢?答案应该是有的:从Wikichip的资料来看,这颗核显支持Intel Clear Video——这是一种涵盖AVC, VC1, MPEG-2等格式硬件解码加速、DVD upscale、蓝光播放优化等支持的技术。
现在看来这些当然都属于标配。酷睿Ultra 1代对HEVC, VP9, AV1等新格式都做了编解码支持,视频规格也来到了8K 10bit HDR。可惜有关视频内容创作的测试,酷睿i5-520M是一个都跑不了,Pugetbench Premiere Pro跑到崩溃,DaVinci Resolve则连界面都进不去。其实媒体引擎部分基本也没什么对比的悬念。
但我们还是想玩点恶趣味,看看核显这14年来的真正进步:既然酷睿Ultra支持AV1编解码——这东西对当年的酷睿1代而言还是个超未来向事物。那如果让酷睿1代单纯靠CPU的力量,实现AVC→AV1转码,对比酷睿Ultra 1的AV1硬件编码加速会怎么样呢?
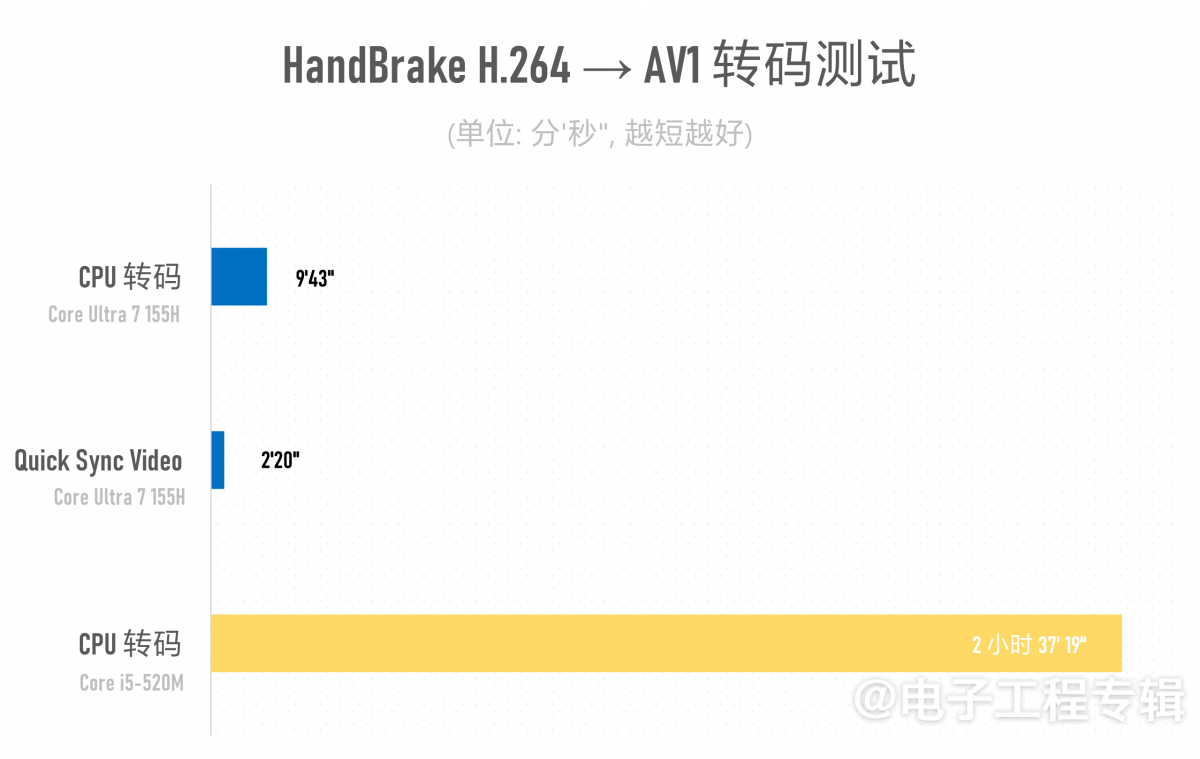
将一段3分钟1.2GB大小的4K分辨率H.264(AVC)视频素材,通过HandBrake转为AV1格式(Fast 2160p60 4K AV1)。酷睿i5-520M借助双核CPU的九牛二虎之力,耗时2小时37分19秒;而酷睿Ultra 7 155H,如果靠16个核心的CPU软件转码,则耗时9分43秒;换用Intel QSV调用Meteor Lake的媒体引擎做加速,则只需要2分20秒。
果然固化电路才是效率的王道啊(虽然此处没有考虑转码质量问题):单纯在这一个任务负载上,酷睿Ultra 1代比酷睿1代快了67倍……当然这么比是有点不厚道的,但行业里热衷于这么比的可不止是我们(某水果牌)…
聊完图形渲染和媒体引擎,接下来谈谈AI。一般我们说Windows平台下做AI推理需要WinML或DirectML支持,那么酷睿i5-520M又是没资格上AI牌桌的。但CPU作为通用处理器的价值就在于它不仅能做视频编解码,还能做AI推理:不用DirectML,还可以用Intel的OpenVINO。
所以我们很欣喜地在AI推理测试Procyon AI inference for Windows测试中看到,借助OpenVINO,也能让酷睿i5-520M跑AI推理,当然GPU支持就别想了,综合测试只能跑在CPU上。至于酷睿Ultra 7 155H这边,OpenVINO本身就可以把AI工作分派给CPU, GPU, NPU等不同处理器,所以我们针对每一种处理器做了测试,结果如下:
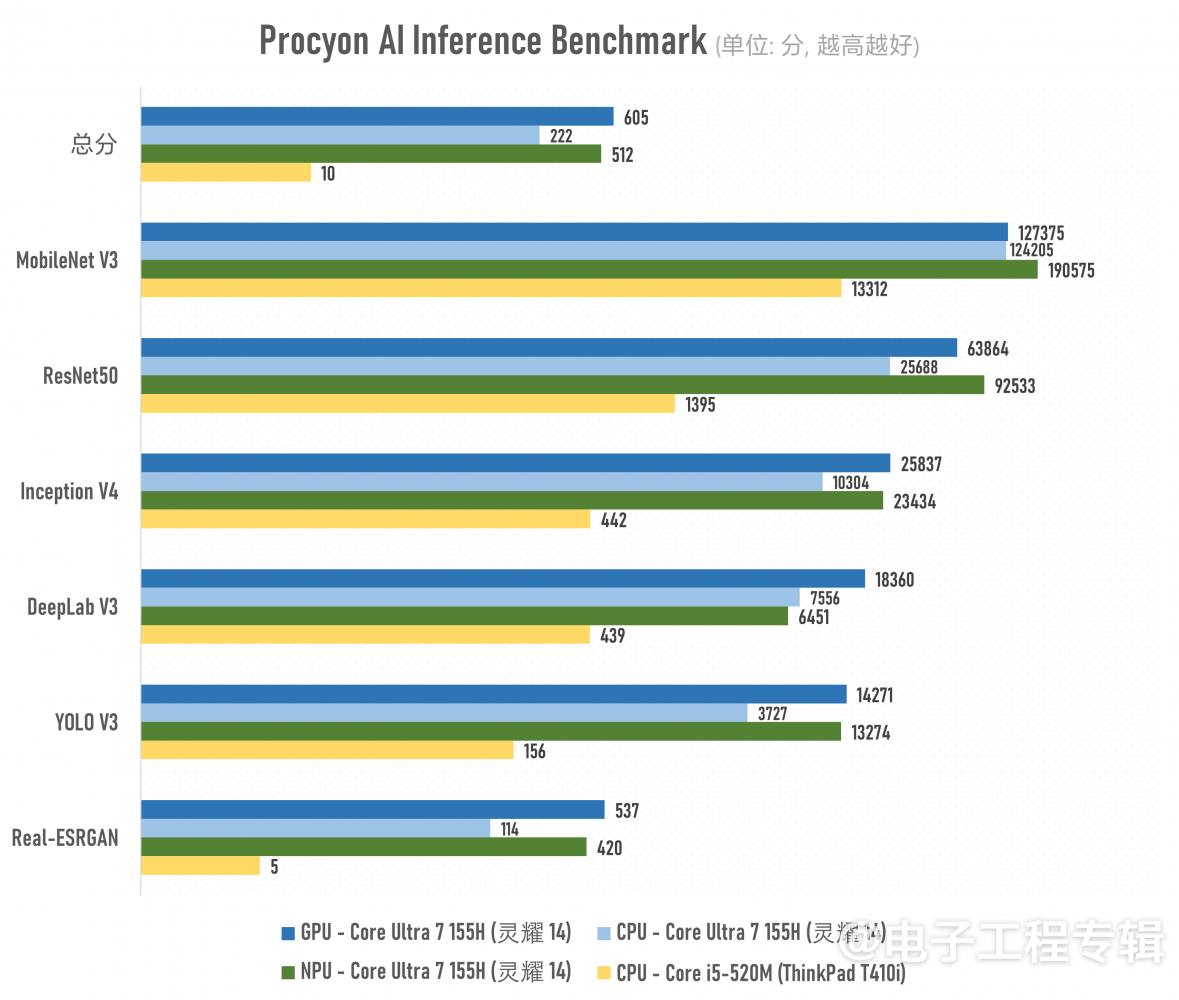
注意:这张图的横坐标为对数坐标,而非线性比例。因为酷睿i5-520M跑出来的分数实在是太低了,比如总分只有10分,再比如Real-ESRGAN这个模型下只能跑出5分…如果用线性比例来画柱状图,则酷睿i5-520M的柱子就被淹没到看不见了。所以别看黄色柱子和蓝绿柱子的长度接近,实则数值上差别非常大。
这则对比让我们没怎么想到的是,酷睿Ultra 7 155H的CPU和NPU的AI推理性能也都不错。因为在我们的认知中,Meteor Lake的NPU虽然是个专用的AI推理加速单元,但它规模小;而CPU是个通用处理器,却在某些测试子项中,表现出与GPU, NPU相似的性能。
猜测其中原因包括OpenVINO的优化,令某些模型在NPU中表现得尤为高效(典型如MobileNet V3和ResNet50);另外当代Intel处理器的CPU部分也加入了VNNI之类的指令集加速构成,堆多核心亦为其加分良多。
UL Procyon AI inference测的主要是CNN卷积神经网络模型,比如DeepLab V3是主要用于语义分割的CNN模型,ResNet50和Inception V4则常见于图像分类,Real-ESRGAN是个用来做超分的AI模型。这次的测试我们就暂且不讨论LLM之类的大模型了——有关LLM, Stable Diffusion等AI相关测试,我们会放到后续的文章里做探讨。
游戏测试,要看核显硬实力了
理论性能测试过后,就该真刀真枪地上真实场景测试了。还是一样:ThinkPad T410i的核显跑不了渲染之外的其他测试,所以GPU的真实性能测试,也只能看游戏了;而且基本只能选< DirectX 9的游戏。我们挑选的普遍是2010年前后的游戏作品。
这份游戏对比测试,将画质全部调整至最低 + 720p分辨率(除了《武装突袭2》有个3D分辨率,在极低画质时锁定为960x540);除了《LoL(英雄联盟)》依托于游戏回放来做帧率测试,其他几个游戏都有内置的benchmark做参照,很容易做复现:
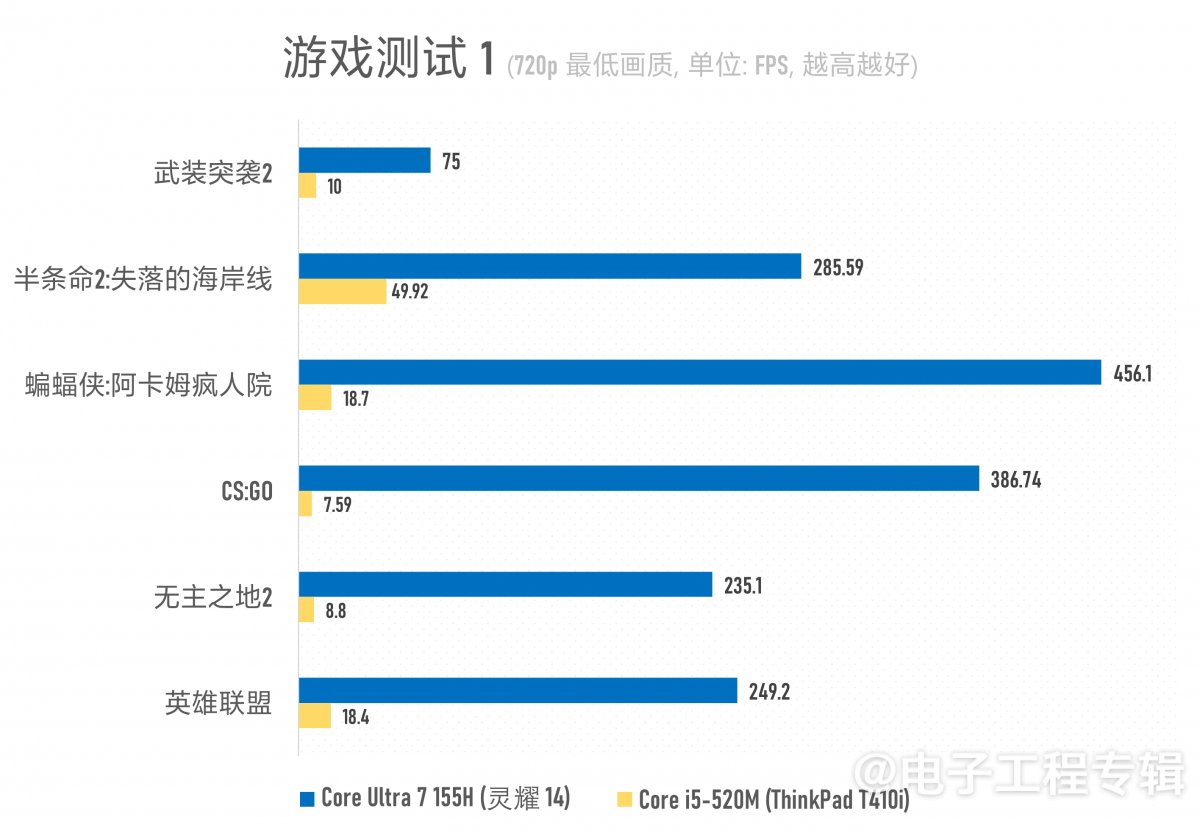
这局面和前面的图形理论测试结果也差不多,除了个体游戏存在代码水平差异。比如《半条命2:失落的海岸线(Half Life 2: Lost Coast)》这个游戏优化得似乎挺不错,不仅画质好(注意看下图的水面效果),而且在ThinkPad T410i笔记本上还能跑出49.92fps的平均帧。

另外ThinkPad T410i在《LoL》游戏里虽然只跑出了18.4fps的平均帧,但我们感觉还在“可忍受的可玩”范围内。似乎这类固定视角游戏对帧率要求并没有那么苛刻…
而且这款游戏也表现出了两个平台在游戏测试里的系统性差异。《LoL》虽说是基于DirectX 9的游戏,但似乎在更高配的设备上能够还原更高版本图形API的某些特性。所以虽然都是跑同画质设定的《LoL》,但在ThinkPad T410i和灵耀14两台机子上仍然是不对等的。

《蝙蝠侠:阿卡姆疯人院》游戏画面
其他游戏基本也就看个热闹了,ThinkPad T410i无疑是和3A游戏彻底无缘的。观察游戏过程中的硬件瓶颈,所有被测游戏的帧率瓶颈都在GPU核显上,CPU的资源占用都是不满的。当年的PC用户或许能接受480p分辨率游戏?(或1024x768、800x600这类显著低于720p的分辨率)……
这些老游戏还是无法表现灵耀14 2024和酷睿Ultra 7 155H的核显优越性。所以针对灵耀14,我们也测了网络游戏中比较吃处理器资源的《原神》和《崩坏:星穹铁道》,以了解Arc核显的实用性。这两款游戏都是基于DirectX 11,酷睿i5-520M就真的没法跑了。
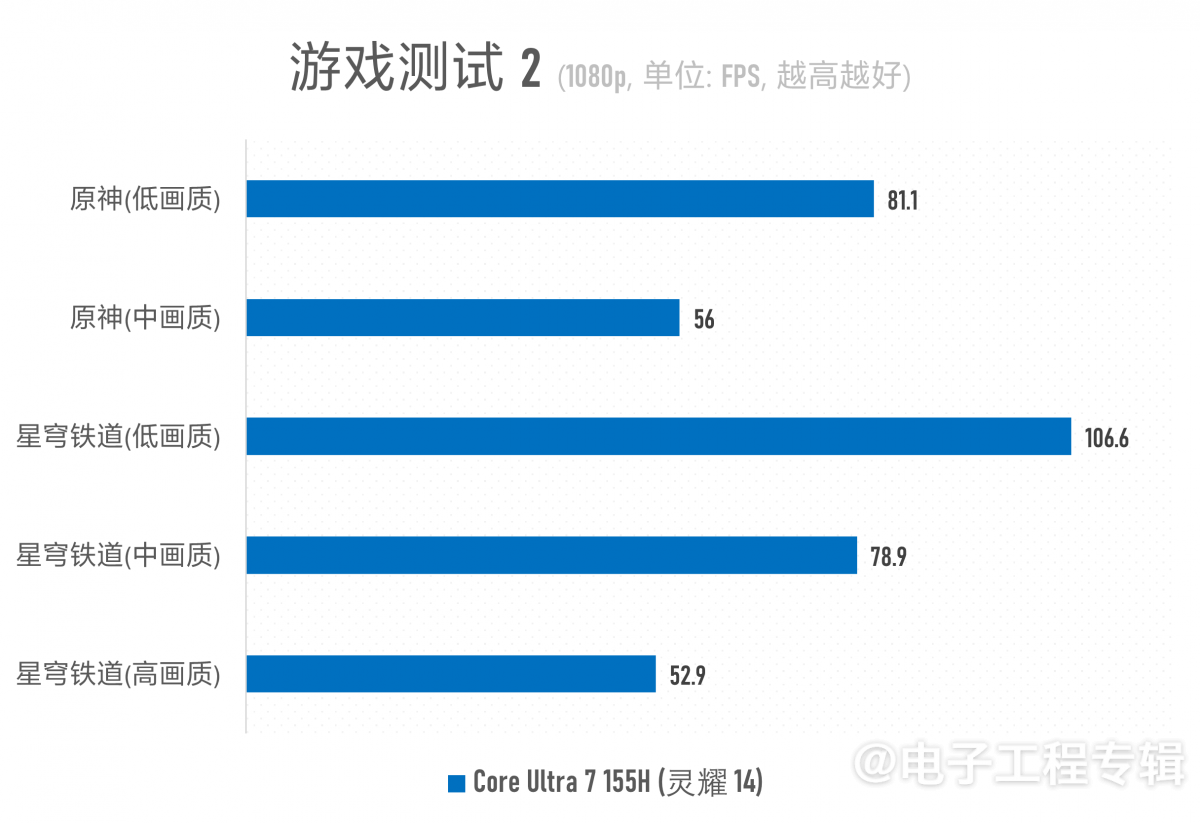
这两款游戏都没有自带的benchmark,所以针对《原神》我们选择的测试场景是须弥主城,针对《星穹铁道》则选择了罗浮仙舟的金人巷——这两个地点在游戏中对算力都是有一定要求的。不过这些数字也仅供参考,比如据我们所知《星穹铁道》刚刚更新的匹诺康尼场景,性能要求就明显高过了罗浮仙舟。
基于1080p分辨率及不同画质预设来做测试,平均帧的结果还是挺乐观的。Intel上一代96 EU的Xe-LP核显运行《原神》就只能以“极低”+720p分辨率勉强跑个50fps不到。这一代中画质+1080p都能上56fps了,是不是感觉Arc核显还挺香的?不过从系统角度来看,灵耀14性能调度保守+飘忽,实际游戏体验在1080p中画质下算不上理想。这台笔记本在我们到手以后,经过两次固件更新已经略有好转,但问题依旧存在。
无论如何Meteor Lake还是让我们看到了这个时代下,核显性能的显著进步。除了这两款游戏,再来一组3A游戏测试,设定为1080p + 最低或比最低画质高一档:
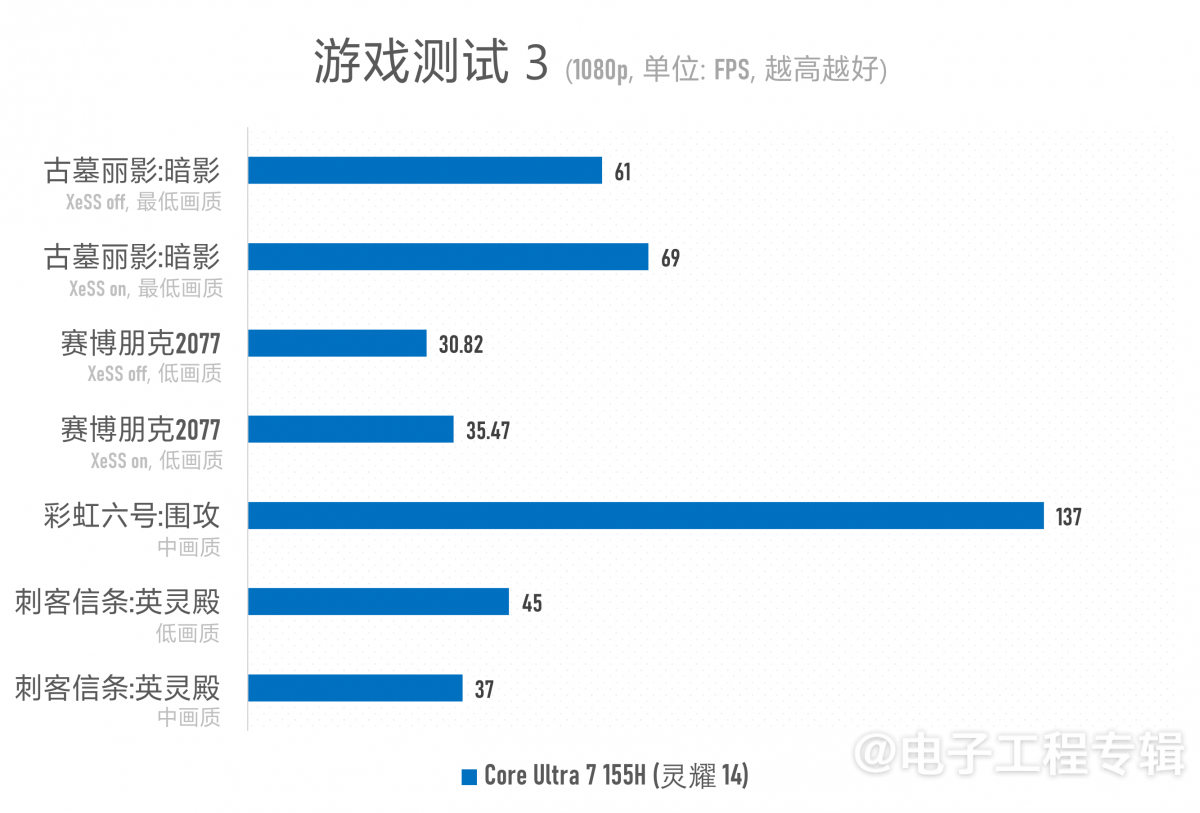
在DirectX 11/12的年代,最低画质跟DirectX 9时代都不是同一种“最低画质”,从《刺客信条:英灵殿》这类游戏的benchmark就能看得出来(如下图)。换用720p来玩这些3A游戏,如今也大多有了“可玩”的体验,放在以前还是不敢想象的。

《刺客信条:英灵殿》游戏画面
这一代Xe-LPG架构的Arc核显也支持XeSS,也就是画面的AI超分,将低分辨率基于AI超分为高分辨率,减轻GPU图形渲染的负担。只不过Meteor Lake的核显实际是不带XMX单元的——也就是Arc独显里面的AI加速部分;所以核显的XeSS支持是靠DP4a实现的。它仍然能带来一定程度的帧率提升——虽然我们没有进行太多相关AI超分的测试。
系统性能与功耗,看看效率变化
渲染相关的主要测试就上面这些了。其余的,我们还做了CPU与真实负载测试,包括Cinebench R15/R23, Geekbench 6, PCMark 10, UL Procyon Office Productivity。
之所以要做Cinebench R15这么老的测试,一部分原因是Arrandale甚至都还不支持AVX指令。另外PCMark 10作为典型的真实负载系统性测试,某些测试项原本是可以借助GPU做加速的,但如前所述酷睿i5-520M并不支持,所以也就只能当做是CPU性能测试了。
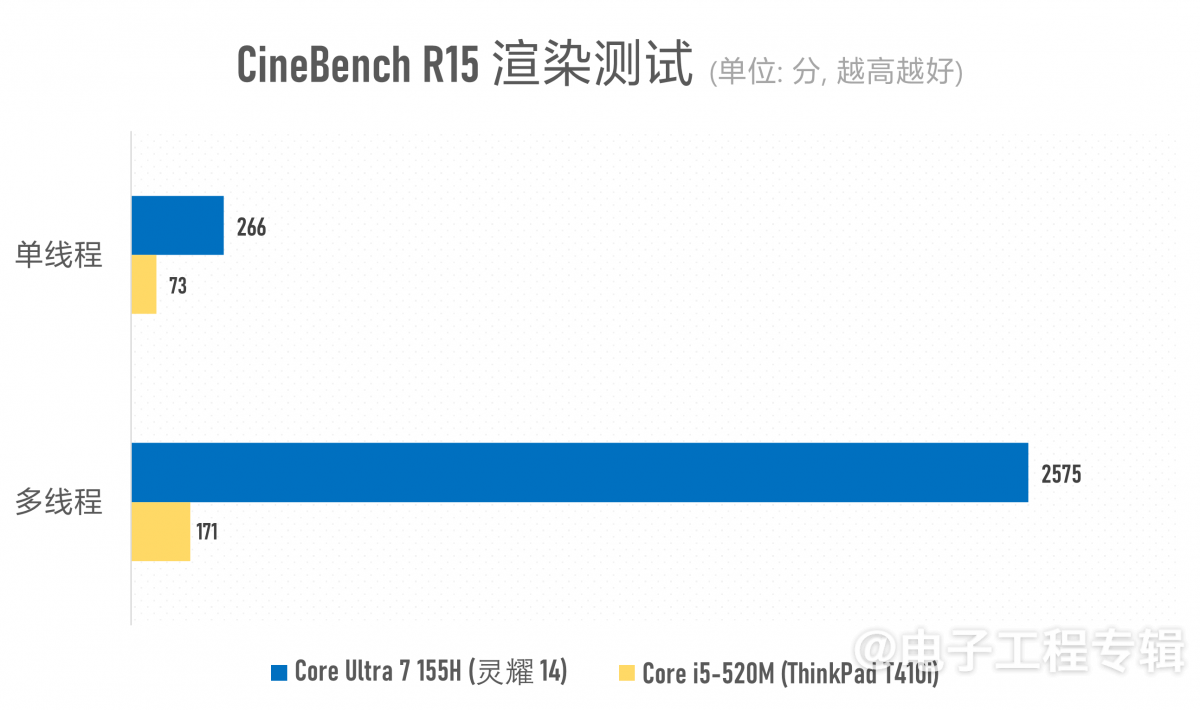
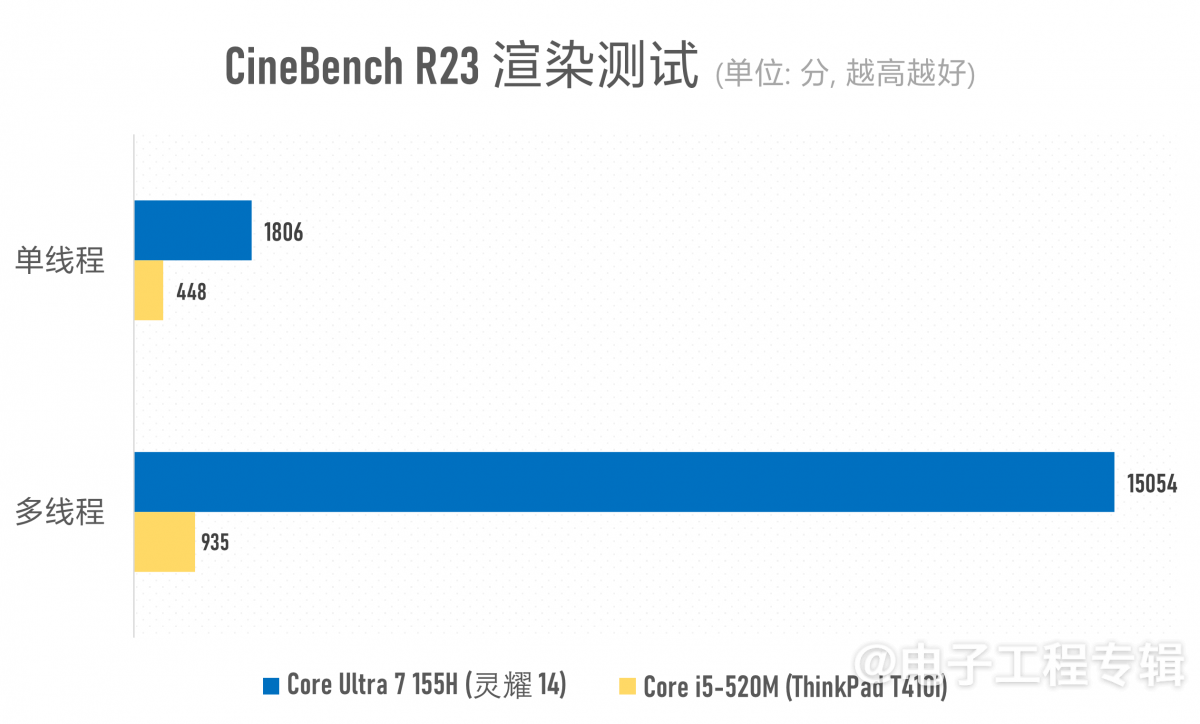
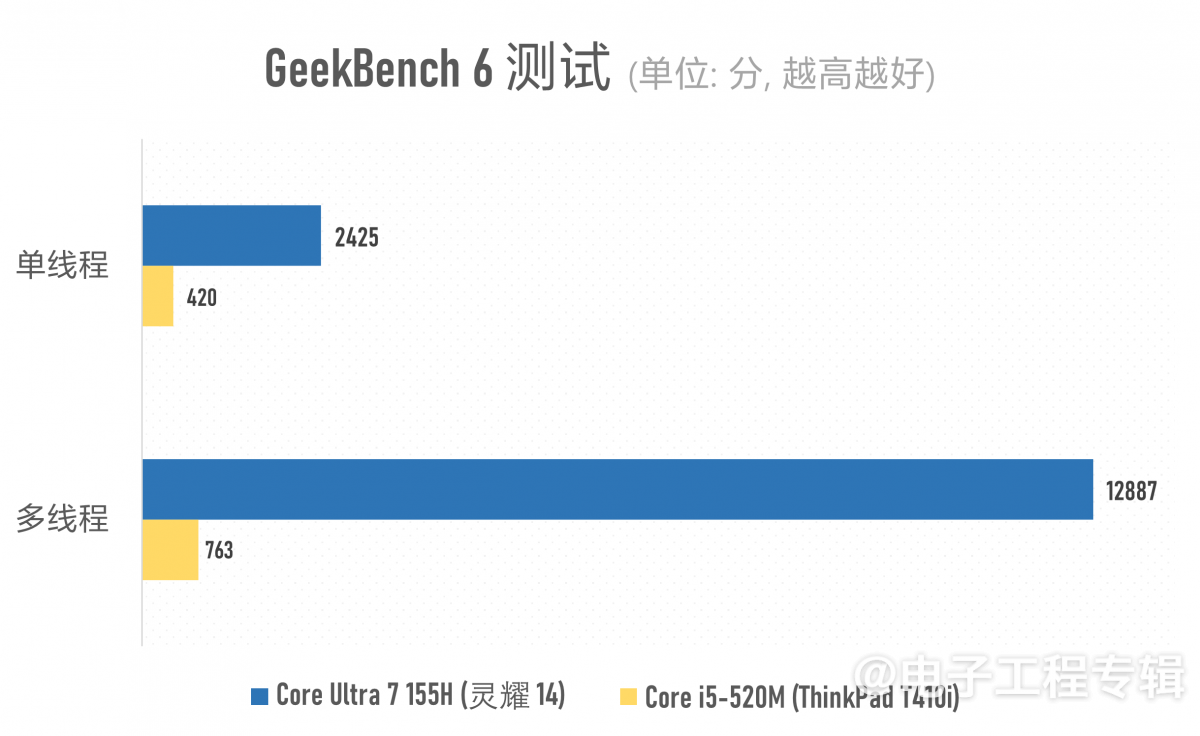
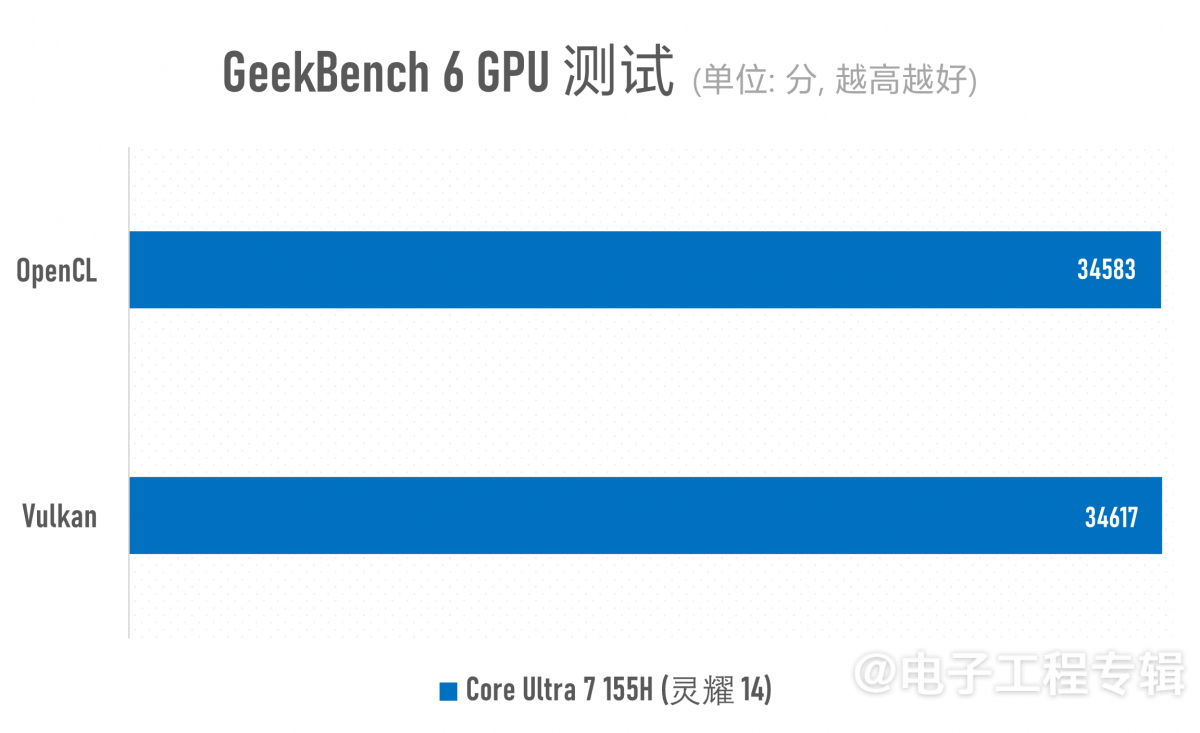
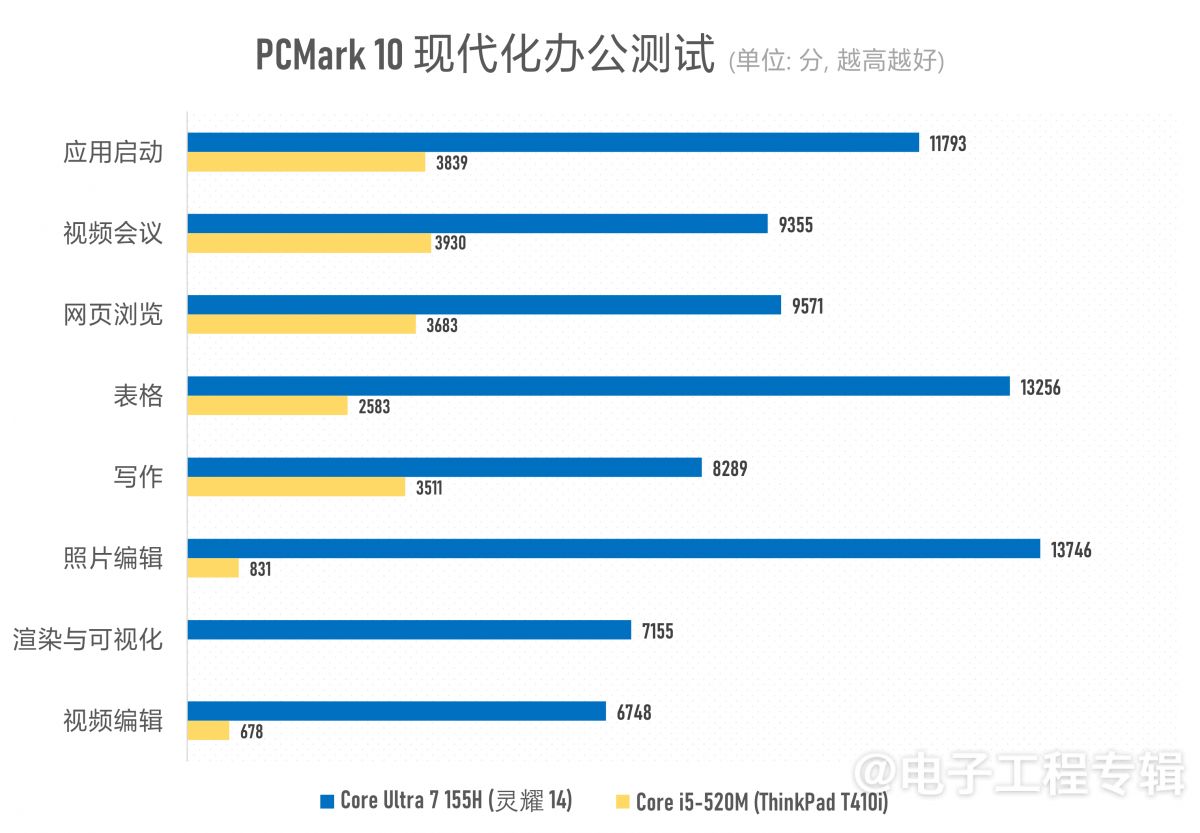
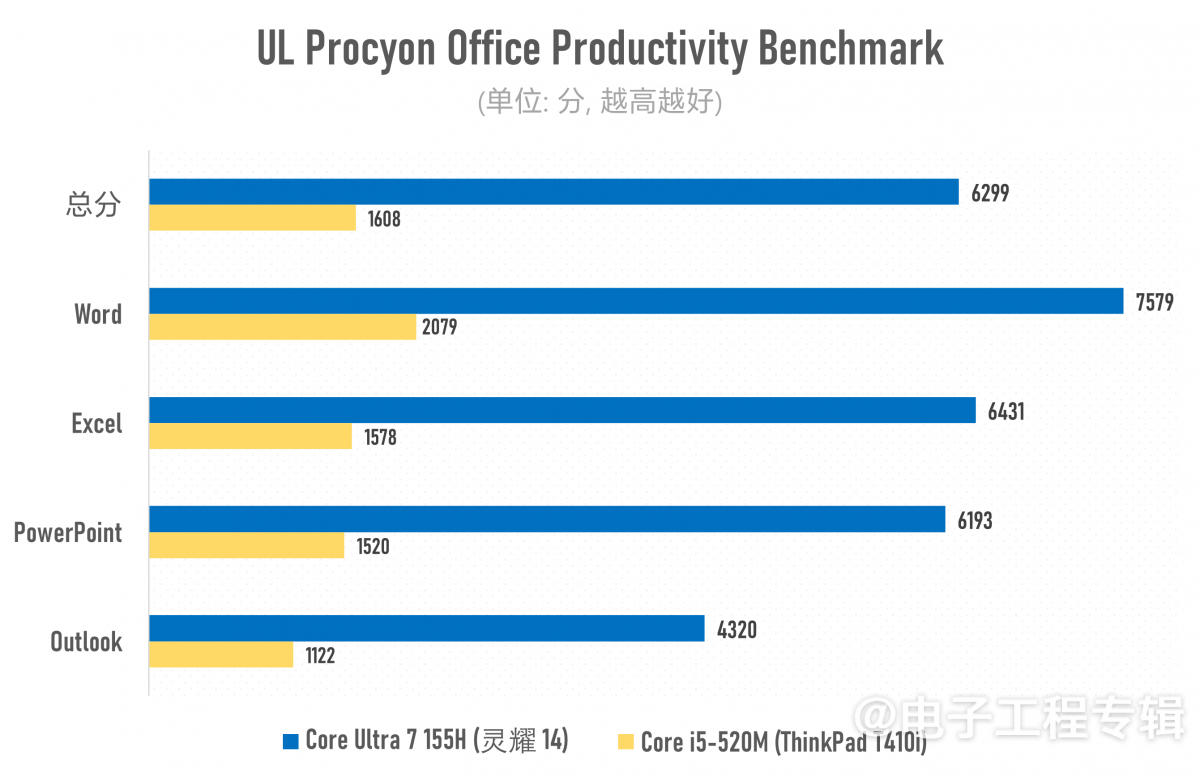
两者在常规办公应用方面的性能差距实则也就4倍上下(酷睿i5-520M似乎格外不擅长做Excel表格,每次都能在表格测试中卡很久…),存在巨大差距的主要还是多媒体内容创作,包括照片与视频编辑这些对存储、CPU多核性能与GPU加速存在多维度性能需求的应用。能较充分利用CPU多核心资源的Cinebench渲染和Geekbench系统性能测试就更不用多说了。
值得一提的是,从可查询的历史数据来看,我们测得的酷睿i5-520M的成绩有些过低,而酷睿Ultra 7 155H又有些过高。
原因其实也比较简单:酷睿i5-520M的历史测试数据大多是基于Windows 7的。我们给ThinkPad T410i装了Windows 10——新系统加装所有安全补丁以后,性能打个8折也并不稀奇。因为过去这14年,软硬件层面出现过好些安全问题,安全更新令系统性能产生了大幅折损。比如光是Meltdown和Spectre这两个安全事件,微软在为其打完补丁以后,对7代以前的酷睿处理器都产生了不小的性能影响。
另外双核处理器在现代操作系统中,经受的扰动似乎也天然得更大。但凡Adobe Creative Center、浏览器的后台驻留进程、Windows反恶意程序、Steam程序本体等等“背景噪音”有那么点风吹草动,CPU占用率就跟着“荡漾”。这也是没办法的事,即便我们已经最大限度关闭了后台可关闭的服务与进程。

至于酷睿Ultra 7 155H的成绩较高,主要是华硕两度更新了灵耀14笔记本的固件,令系统性能发挥有了较大程度的提升。所以我们测得这台笔记本的性能成绩,相较1-2个月前其他媒体发布的分数会更高一些。
最后我们还是看一看灵耀14与ThinkPad T410i就更高维度系统层面的性能释放策略,尤其是核显部分。虽说不是细粒度的能耗与效率对比,但也能看出PC处理器效率上的变化。下面这张图是进行5轮Cinebench R23测试时,酷睿Ultra 7 155H的CPU封装温度与功耗变化曲线:
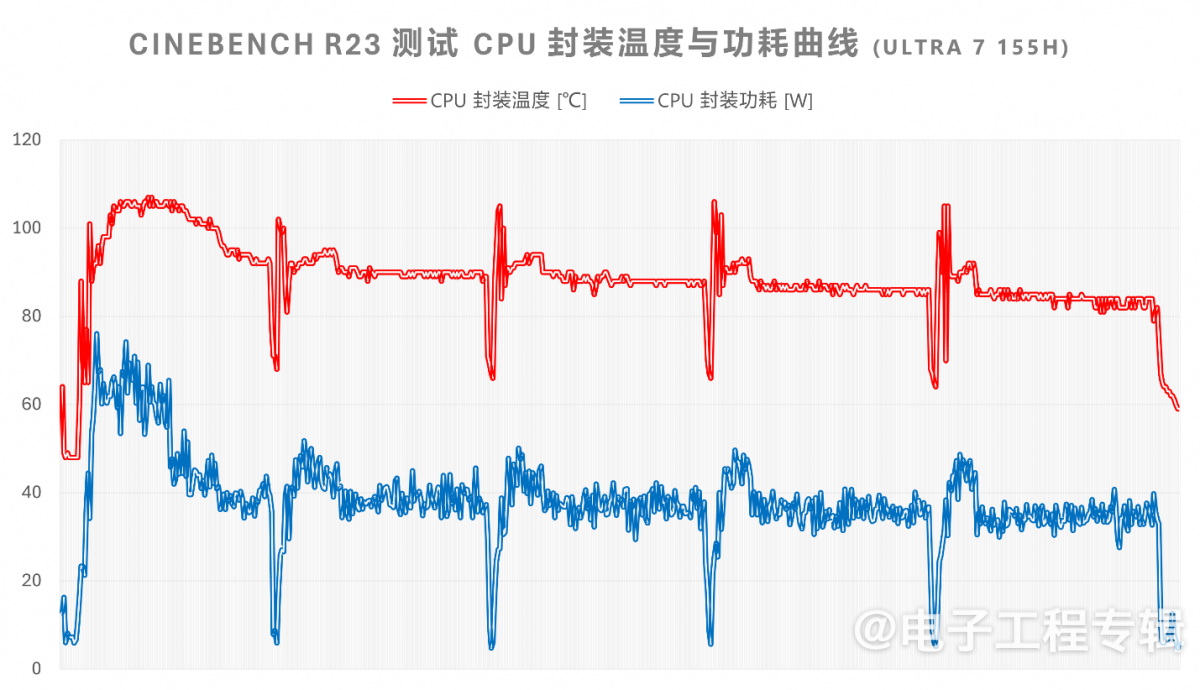
在灵耀14这台笔记本上(系统设定“最佳性能”,风扇“性能模式”下),酷睿Ultra 7 155H在跑第一轮Cinebench R23测试时,CPU封装温度能飙到105℃,记录得到的最高功耗点在74W左右;后续几轮的温度稳定状态会滑落到86℃附近,功耗稳定在35W上下。
FurMark甜甜圈单独对Arc核显做压力测试,可测得GT核心功耗——也就是核显功耗触顶在30W不到。
5分钟基于AIDA64的FP压力测试,外加FurMark对GPU同时施加压力测试,得到的CPU核心功耗与GPU核显功耗变化如下图:
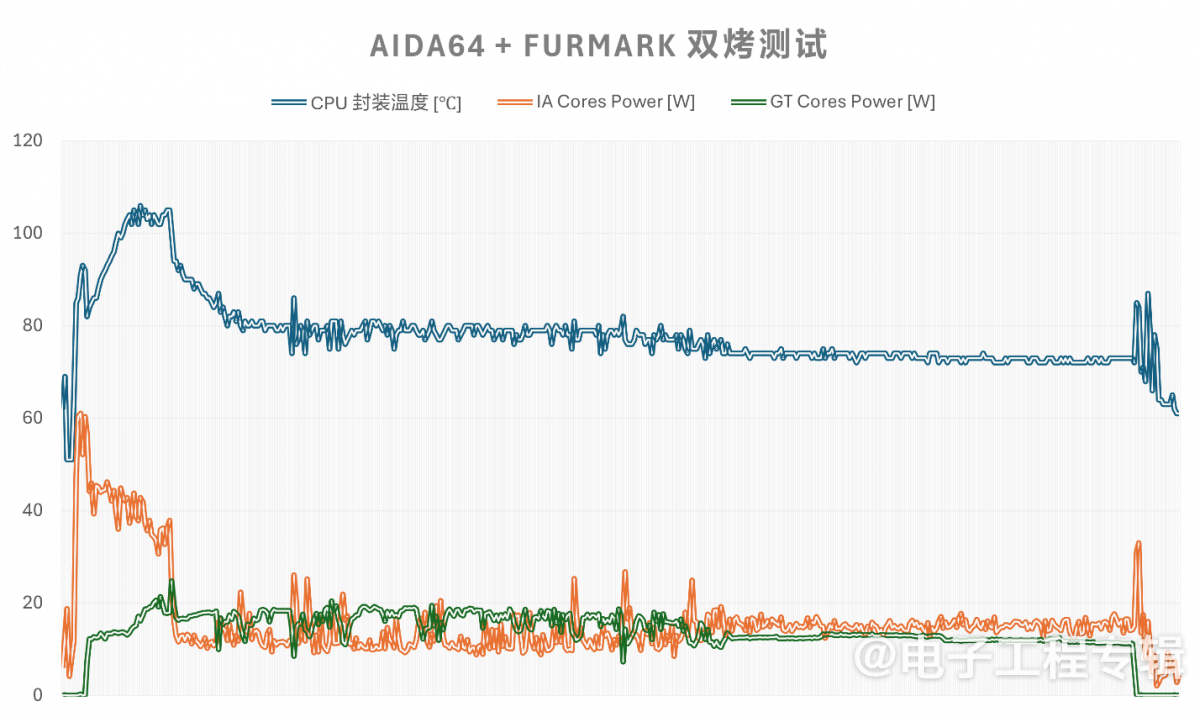
CPU与GPU核心总功耗加起来,稳定状态在30W上下浮动。注意此时的CPU封装温度还不到80℃。这可能与灵耀14散热设计做得并不特别理想有关:机身外部温度及风扇噪音都存在较高的问题,所以灵耀14在性能释放方面不得不做得相对保守。不过实际对于定位轻薄本,重量仅1.2kg的灵耀14而言,这种表现也很正常。
至于ThinkPad T410i和酷睿i5-520M这边,我们没有找到可获取其核显温度与功耗的方法——这主要取决于Intel给出的API,及其上选配的传感器;毕竟酷睿i5-520M的核显die和CPU die是分开的。
可测得酷睿i5-520M的CPU核心功耗(注意是核心功耗,而非封装功耗)在Cinebench R15测试过程中25W封顶——虽然无法一直保持在25W的位置,但会降低运行状态一小会儿之后反复尝试回到25W;核心温度策略也相对保守——有时会跑在83℃附近。
即便当代处理器的功耗相比10+年前普遍升高了不少,基于灵耀14可达成突发性能的CPU封装峰值功耗74W,相比于ThinkPad T410i的酷睿i5-520M大约增加了1倍多(基于CPU核心功耗25W,还需要加上封装内的其他组成部分),但Cinebench测得的多线程性能,前者却是后者的15倍。这应该是能够体现这些年来芯片效率的显著进步的。

其实PC处理器的核显历史上具有标志性意义的产品并不单是Arrandale和Meteor Lake这两者,还有前文提到的酷睿10代Ice Lake,加入了AMD图形die以及eDRAM的酷睿8代Kaby Lake-G等等。对这些产品做个集体测试更能体现处理器集显性能的演进历史。
只不过受限于时间和精力,做个一头一尾感觉也不错。从单纯的亮机卡,到现如今3A游戏都能玩,这中间经历的实际上还真的不单是一家公司所能达成的,而是从材料、装备,到芯片设计制造封装,及系统与软件层面各层级的努力。现在的轻薄本也算是浓缩了人类尖端核心技术了。

