
机器学习(ML)是人工智能的一个分支,现已成为人们生活中不可或缺的一部分。它支持人们利用深度神经网络算法等技术从数据中进行学习和推理,可以完成图像分类和语言建模等数据密集型任务,并由此催生出许多新应用。
机器学习过程分为两个阶段。首先是训练阶段,通过将信息存储和标记为权重来开发智能,这是一种通常在云端执行的计算密集型操作。在这一阶段,要给机器学习算法输入一个给定的数据集,并对权重进行优化,直到神经网络能够以满意的准确度进行预测。
接下来是推理阶段,机器利用第一阶段存储的智能来处理新数据。推理的主要运算是权重矩阵和输入矢量的矩阵矢量乘法。例如,在训练模型进行图像分类时,输入矢量包含未知图像的像素。
权重矩阵由所有用于识别图像的不同参数组成,并在训练阶段作为权重加以存储。对于大型和复杂问题,该矩阵可分为不同的层。输入数据通过神经网络“转发”后用于计算输出结果:预测图像中包含的内容,例如一只猫、一个人或一辆车。
在技术方面,输入和权重通常被存储在传统的存储器中,然后被取出并放进处理单元中进行各种运算。因此,对于复杂问题,需要四处流动的数据量很大,从而影响了能效和速度,并留下了大量的碳足迹。
不过,如果(部分)运算工作能够在存储器内完成,则可以避免大部分数据的流动。如果以节能方式来实现,这种存内计算还可以减少推理对云的依赖,并在很大程度上改善时延和能耗指标。
模拟存内计算的通用架构
与传统的存储器运算不同,存内计算不是以单个内存单元为粒度来进行的。相反,它是利用阵列级组织、外围电路和控制逻辑,在一组存储器件上执行的累积性运算。常见的步骤是乘法累加运算(MAC),即计算两个数的乘积,再将结果加到累加器中。
虽然存内计算能以数字化方式进行,但这项工作的重点是利用实际电流值或电荷值而实施的模拟实现。与数字化存内计算相比,模拟存内计算(AiMC)具有诸多优势。只要多级编程是可行的,每个单元都能更容易地表达多个比特的信息(包括权重和输入),从而减少存储器件的数量。此外,根据基尔霍夫电路定律,利用电荷或电流进行MAC运算,几乎是一种很自然的方法。
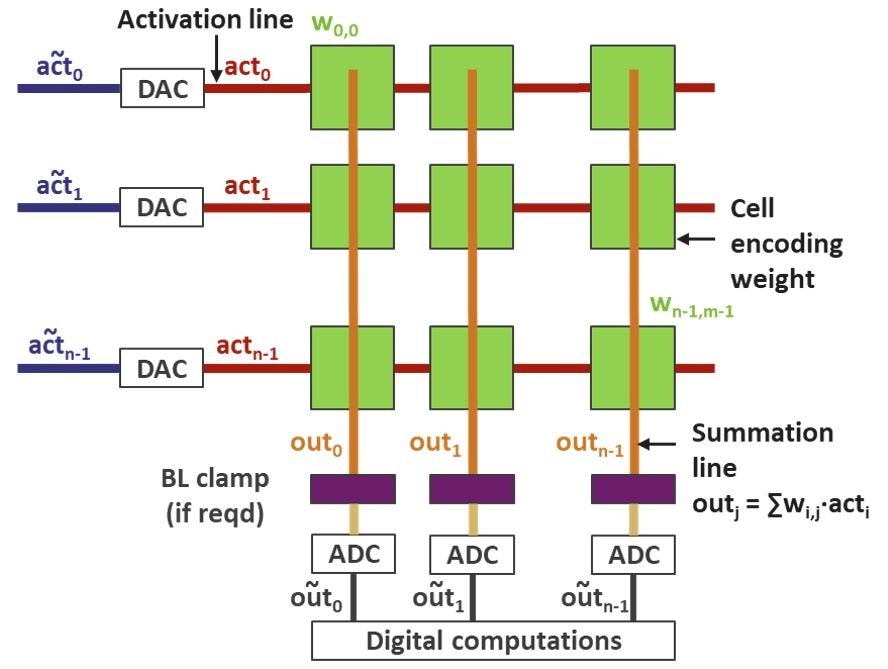
图1:AiMC多矢量乘法的总体概念。
在一般的AiMC架构中,首先通过激励通道上的数模转换器(DAC),将来自输入层(或上一层)的激励信号转换成模拟信号(见图1)。然后,将模拟激励信号(acti)与权重(wij)相乘,再将结果存储在存储单元阵列中。每个单元将该乘法运算结果(wij.acti)作为电流或电荷输送到求和线路上。在求和线路上,输出是所有乘积的总和。然后将输出转换为数字值。经过后处理之后,结果被传送到下一层或缓冲存储器中。
合适的存储器技术
目前,大多数基于AiMC的机器学习系统,都依赖于传统的静态随机访问存储器(SRAM)技术。但事实证明,基于SRAM的解决方案价格昂贵、功耗高,而且难以扩展至更高的运算密度。为了克服这些问题,人工智能领域正在研究替代性的存储器技术。
针对高能效推理应用,在IMEC之前所提交的一份不同存储器技术的基准研究报告中,将电路设计与技术选项及要求联系在一起,预测能效为每秒每瓦1万太次运算(TOPS/W)。实际上,该能效超过了最先进的数字解决方案。研究人员将大单元电阻或低单元电流、低变异和小单元面积确定为关键参数。
然而,上述这些关键参数限制了最流行单元类型的利用,包括自旋扭矩传递磁性RAM(STT-MRAM)和电阻性RAM(ReRAM)。电阻性存储器将权重存储为电导,并将激励编码为电压电平。不过,电阻性存储器存在一个问题,就是激励与求和线路上都会出现IR电压降,从而影响输出。
此外,为了优化阵列内单元的访问,还需要一个选择器,这将增加单元面积,也给电压分配带来了挑战。相变存储器(PCM或PCRAM)也受到类似问题的限制。对于自旋轨道力矩MRAM(SOT-MRAM)来说,器件切换所需的大电流和单元的小电流之间的开关比是一个优势,但并不突出。
在所有研究过的存储器技术中,IMEC发现,基于铟镓锌氧化物(IGZO)的双晶体管单电容(2T1C)器件,最有希望成为AiMC的候选器件。2T1C单元最初是针对DRAM应用提出的,与SRAM相比,它在AiMC应用方面有如下两大优势。
一是它能大大降低待机功耗。其次,IGZO晶体管可以在芯片的线路后端(BEOL)处理,能够堆叠在位于线路前端(FEOL)的外围电路之上。这样,在构建存储器阵列时,就不需要FEOL基底面。此外,IGZO技术还支持将多个单元上下堆叠在一起,从而实现更密集的阵列。
基于IGZO的2T1C器件工程设计
余下来的挑战包括优化增益单元的保持时间,探索多电平编程的可能性,以及验证阵列配置下的MAC运算。不过,在不久前举行的国际存储器研讨会(IMW)上,发现这些问题已被IMEC所解决。
权重矩阵中的每个存储单元,都由一枚电容和两枚IGZO晶体管组成。一枚晶体管作为写入晶体管,连接着第二枚晶体管的栅极,用于将权重编程为(存储节点)电容上的电压。第二枚晶体管被设计为读取晶体管,充当电流源元件,支持非破坏性读取。
流经读取晶体管的电流大小,取决于激励输入和存储节点电容中存储的权重。因此,该电流自然代表了wij.acti。由于读出电流得到了放大(相较于存储电荷电流),因此2T1C单元也被称为“增益单元“。
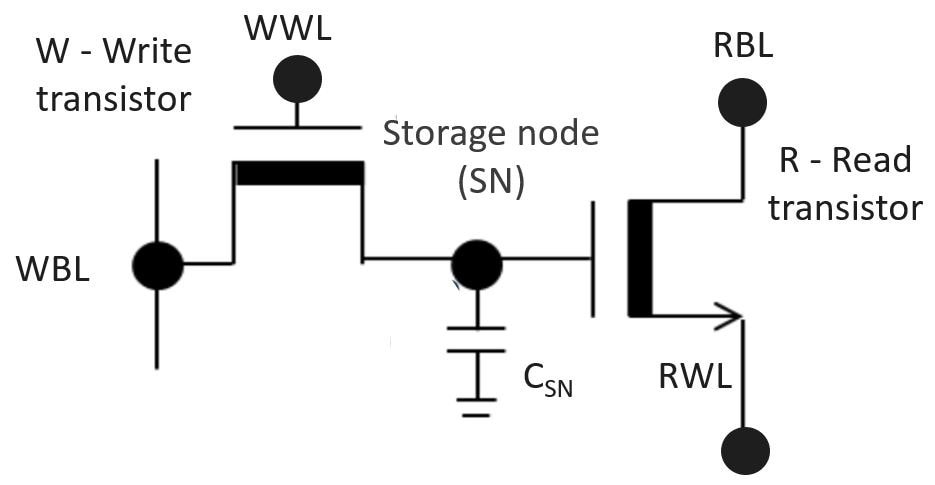
图2:2T1C DRAM增益单元原理图。
为了适合高能效的MAC运算,单元的三个关键组件需要满足以下指标,分别是较长的保持时间、较低的关断电流和合适的导通电流。
增益单元的保持时间决定了该单元可以保持所编程权重的时间长短。保持时间越长,单元刷新的频率就越低,就越有利于降低功耗。此外,多电平运算需要较长的保持时间,以确保在存储节点电容上存储不同电压电平的能力。
外部电容、读取晶体管的栅极氧化物电容和寄生电容决定了存储节点电容的大小。所编程的权重会因泄漏电流而改变,这就对外部电容和IGZO晶体管的漏电流提出了一个要求,即后者必须具有较低的关断电流。
读取和写入晶体管的主要区别在于所期望的导通电流不同。读取晶体管需要较低的导通电流来限制IR压降,而写入晶体管的导通电流则必须足够大,以便在合理的写入时间(>1µA/µm)内完成权重的编程。
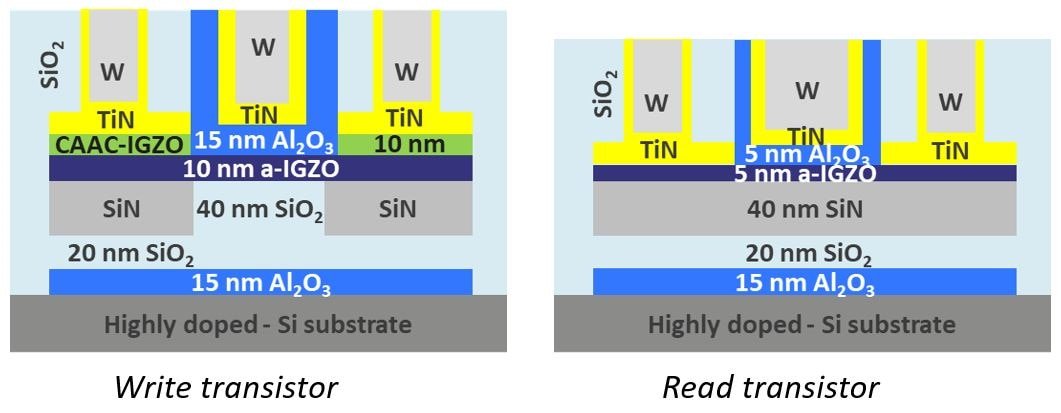
图3:写入(左)和读取(右)晶体管的堆栈原理图。
基于非晶IGZO的晶体管和电容设计符合不同的标准,其制造已在300mm晶圆上成功实现。所提出的解决方案与CMOS和BEOL兼容,故在制造这种存储器阵列时,不需要FEOL基底面。
写入晶体管的高导通电流和低关断电流,其实现方法是通过采用带有氧隧道模块和凸起源极/漏极触点的栅极末端配置、以及利用相对较厚的栅极电介质(15nm)。读取晶体管则采用了更薄的IGZO沟道(5nm)和更薄的栅极电介质(5nm)。至于外部电容,则实现了9nm厚的基于Al2O3的金属-绝缘体-金属(MIM)电容。
实验验证
由于读取和写入晶体管的设计不同,因此最好是将它们集成在不同的层上,这样可有效发挥IGZO晶体管的三维堆叠性能,从而实现更高密度的阵列。不过,如果只是要通过MAC运算的概念性验证,则读写晶体管的实现可以与写入晶体管设计相类似。
首先,可以测量单个2T1C单元的保持时间和关断电流。实验结果表明,由于IGZO沟道材料的带隙较窄,其保持时间长达130秒,关断电流中值低至1.5×10-19A/µm。
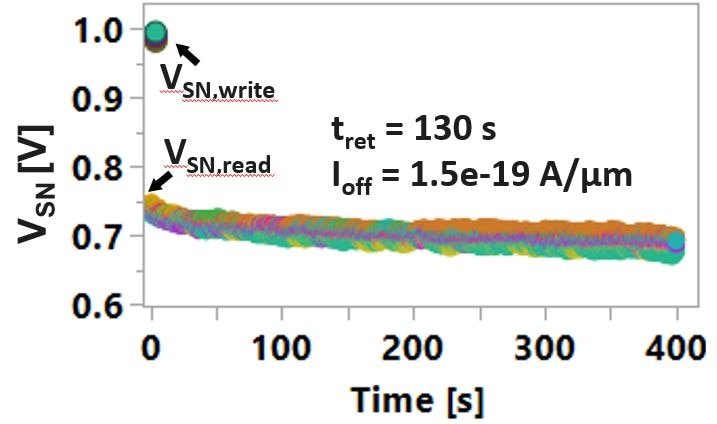
图4:多个器件的存储节点电压(VSN)变化可用来估算保持时间和关断电流。
为了演示多电平运算,将不同的器件编程到不同的权重水平,并监测存储节点电压的变化。即使在400秒后,仍能观察到不同的电压电平,这充分说明了单个单元的多电平编程能力。
其次,为了验证MAC运算,业界实现了采用2×2阵列配置的2T1C增益单元。当激活同一激励线路上的两个单元(电容节点上存储的权重相同)时,求和线路上的读取电流会增加。该电流几乎等于单独激励每个单元后获得的电流之和。
上述实验结果还被扩展到了4×2阵列。在另一组实验中,当改变存储的权重或激励时,可以观察到求和线上电流的变化。这些测量结果表明,带有IGZO的2T1C增益单元可成功用于机器学习应用中的矩阵矢量乘法。
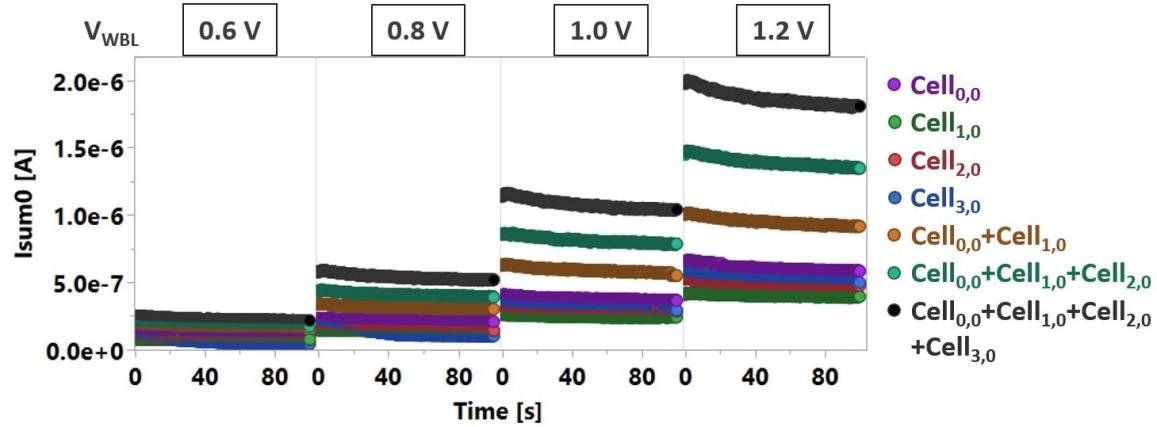
图5:采用2×2阵列的多电平MAC运算,其中的存储节点被编程为不同的权重。
从2T1C到2T0C
对于2T1C单元来说,通过优化晶体管和外部电容实现低关断电流和大的电容值,可以实现较长的保持时间。但是,IMEC在(3D)DRAM应用框架内开展的早期工作证明,在无电容的2T0C增益单元实现中,也可以做到较长的保持时间。
由于IGZO晶体管具有超低的关断电流,即使只将读取晶体管的栅极堆栈用作存储电容,也能实现较长的保持时间。省去外部电容具有一些显著的优点。不仅降低了成本,而且可以实现更小的面积(由于电容需要占用相当大的面积)。之前,IMEC展示过一种基于IGZO的2T0C DRAM单元,其保持时间大于103秒,这个结果得益于IGZO晶体管极低的关断电流。
最近,IMEC进一步将基于IGZO的2T0C器件的保持时间提高到了4.5小时以上,并实现了低于3×10-21A/µm的关断电流,该电流是迄今为止有报道的2T0C器件的最低值。取得这些成果的关键原因,是在2T0C器件有源模块的图案刻制中,利用了反应离子蚀刻(RIE)来代替离子束蚀刻(IBE)。
研究表明,RIE可以消除IBE引起的金属再沉积,从而抑制外漏路径并延长保持时间。RIE技术的另一个优势是,能够在非常小的尺寸(100nm以下)上进行图案刻制,从而进一步减少了面积消耗。
除了保持能力的改进,研究还展示了存储节点电压的出色稳定性,这也表明模拟行为有利于机器学习应用。进而成功证明了单个单元的2T0C器件上的多电平编程能力以及2×2阵列的MAC运算。

图6:用于MAC运算的2×2 2T0C阵列(a),其中单元1和单元3首先被单独激励(b)。当两个单元都被激励时,两个电流会在SUM线上相加。
结论
IGZO 2T1C和2T0C增益单元展示了AiMC的优异特性,因此也适用于实现机器学习应用的推理阶段。针对这些应用,它们已超越了在能效和运算密度方面擅长的传统SRAM技术(实际上2T0C单元在面积效率方面表现还非常出色)。
这项研究展示了多电平MAC运算的能力,进一步为这项技术的成熟和工业应用铺平了道路。
(参考原文:dram-for-energy-and-area-efficient-analog-in-memory-computing)
本文为《电子工程专辑》2024年1月刊杂志文章,版权所有,禁止转载。点击申请免费杂志订阅
