
电子工程专辑讯 近日,阿里云发布的三款Qwen-72B、Qwen-1.8B和Qwen-Audio大模型,在阿里云栖大会上宣布开源。通义千问大模型也升级到了2.1版本。

通义千问-72B(Qwen-72B)是阿里云研发的通义千问大模型系列的720亿参数规模的模型;通义千问-1.8B(Qwen-1.8B)是阿里云研发的通义千问大模型系列的18亿参数规模的模型。Qwen-72B和Qwen-1.8B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。
Qwen-Audio(Qwen Large Audio Language Model)是阿里云提出的大模型系列Qwen的多模态版本。Qwen-Audio 接受多种音频(人类语音、自然声音、音乐和歌曲)和文本作为输入,输出文本。
目前,通义千问共开源18亿、70亿、140亿、720亿参数的4款大语言模型,以及视觉理解、音频理解两款多模态大模型。通义千问成为业界首个“全尺寸开源”的大模型。
当前,阿里云的大模型社区“魔搭”已经有超过150万的模型下载量。据了解,目前,从企业/高校到创业公司,再到个人开发者,基于通义千问开发AI平台和应用的比比皆是,比如华东理工大学的X-D Lab,基于开源通义千问模型开发的心理健康大模型MindChat(漫谈)、医疗健康大模型Sunsimiao(孙思邈)、教育/考试大模型GradChat(锦鲤)等,并为下游客户开发基于行业大模型的产品。
Qwen-72B在 MMLU、AGIEval 等 10 个权威基准测评中,Qwen-72B 都拿到了开源模型的最优成绩,在部分测评中超越闭源的GPT-3.5和GPT-4。在英语任务上,Qwen-72B在MMLU基准测试取得开源模型最高分;中文任务上,Qwen-72B在C-Eval、CMMLU、GaokaoBench等基准得分超越GPT-4。在数学推理方面,Qwen-72B在GSM8K、MATH测评中也领先其他开源模型;代码理解方面,Qwen-72B在HumanEval、MBPP等测评中的表现大幅提升,代码能力也有质的飞跃。
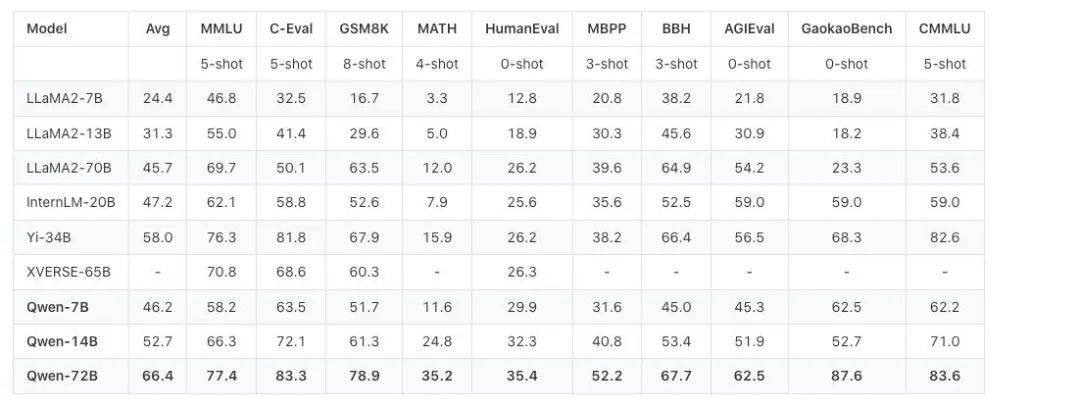
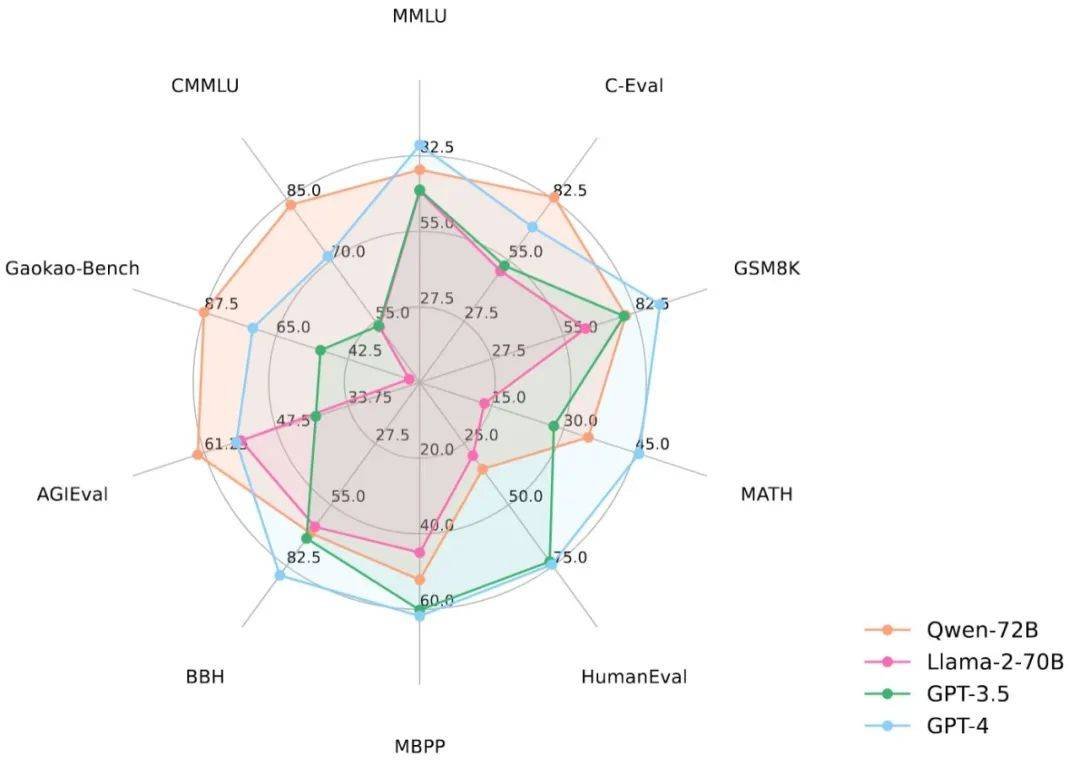
通义千问720亿开源模型成绩
国内外大模型分为闭源和开源两大路线。国外,比如OpenAI走闭源路线,除了ChatGPT还没有具体的产品应用,对外则通过提供接口和投资的方式繁荣生态,相反的,Meta旗下的Llama走开源路线;国内,比如阿里云就是走开源路线,腾讯云和百度云的大模型采用的是闭源路线。
对于闭源路线来说,只要能够提供成熟、稳定的产品,客户付费购买后就可以直接使用。而开源路线则可以帮助开发者或创业公司基于开源大模型开发属于自己的模型和应用。
开源与闭源路线,实际上是“生生态,后商业”还是”先商业,后生态“的选择,按照以往的科技发展趋势大多是先建立生态和落地应用,再逐步商业化。
对于阿里云当前开放的三款Qwen-72B、Qwen-1.8B和Qwen-Audio大模型,720亿参数规模的模型则是有意对标顶尖开源模型。此前,中国大模型市场还没有出现足以对标Llama 2-70B的优质开源模型。Qwen-72B填补了国内空白,以高性能、高可控、高性价比的优势,提供不亚于商业闭源大模型的选择。基于Qwen-72B,大中型企业可开发商业应用,高校、科研院所可开展AI for Science等科研工作。18亿参数规模的模型则是消费侧落地的探索;而Qwen-Audio则是多模态的新探索。
阿里云则坚持以开放为主要发展路线,阿里巴巴集团董事会主席蔡崇信在云栖大会上表示,我们坚信,不开放就没有生态,没有生态就没有未来。同时,我们要始终攀登技术高峰,只有站在更先进、更稳定的技术能力之上,才有更大的开放底气。
阿里云CTO周靖人表示,开源生态对促进中国大模型的技术进步与应用落地至关重要,通义千问将持续投入开源,希望成为“AI时代最开放的大模型”,与伙伴们共同促进大模型生态建设。
