
自2022年底 ChatGPT发布以来,引发了全球范围内对于生成式人工智能技术(AIGC)的关注。ChatGPT的“火出圈”也给大语言模型(LLM)领域带来了更多的玩家,模型数量和参数量在过去一年均不断激增。据不完全统计,仅中国目前的大模型数量就已超过110个,这同时也带来了对于AI算力需求的剧增。
据英伟达数据显示,在没有以Transformer模型为基础架构的大模型之前,算力需求大致是每两年提升8倍;而自利用Transformer模型后,算力需求大致是每两年提升275倍。基于此,530B参数量的Megatron-Turing NLG模型,将要吞噬超10亿FLOPS的算力。
随着大模型参数量增长,ASIC芯片的弱通用性难以应对下游层出不穷的应用,GPGPU受制于高功耗与低算力利用率。如今很多大模型的参数量已经超过了万亿规模,这意味着需要更大规模的算力平台才能进行如此规模大模型的训练。在这样的背景下,存算一体将有望成为继CPU、GPU架构之后的第三种算力架构,背后还涉及了HBM(高带宽存储)、Chiplet等新兴技术。
更大规模的平台还会带来另外一个问题,即卡与卡之间、不同的节点之间的更多通信,大模型的训练需要融合多种并行策略,对卡间P2P互连带宽以及跨节点互联带宽提出了更高的要求。随着模型参数量进一步增加以及GPU算力的成倍增加,未来需要更高的互连带宽才能满足更大规模模型的训练需求。

只有解决上述问题,才能充分挖掘大模型时代的红利,让所有人感受到AI时代的便利。11月23日,“2023 中国临港国际半导体大会” 在上海临港新片区成功举办,同期举办的“AI芯片与高性能计算论坛”邀请到来自芯片原厂、上游IP厂商、终端应用厂商以及研究机构的嘉宾,聚焦人工智能、云计算、物联网等领域的发展趋势,探讨如何利用先进的芯片技术来推动高性能计算的创新。
回归AI计算的第一性原理
随着大模型时代的到来,数据搬运量大幅增加,导致计算能耗急速增长,计算效率大大降低,运营和建设成本极高。同时,AI应用进入2.0时代,模型参数量呈现出更快的增长速度,数据搬运速度的剪刀差也越来越大,然而每一次推理计算都需要搬运整个模型参数,存储墙成为最大痛点。

亿铸科技创始人、董事长兼CEO 熊大鹏博士
亿铸科技创始人、董事长兼CEO 熊大鹏博士在主题为《回归AI计算第一性原理,存算一体迎大模型时代》的演讲中表示,回归AI计算的第一性原理,也就要回到硬件加速设计的基本定律——阿姆达尔定律(Amdahl Law),而存算一体架构,可以从根本上解决存储墙带来的能耗和算力瓶颈的问题。
据介绍,亿铸在今年首次提出了基于忆阻器的超异构芯片,以存算一体AI加速计算单元为核心,同时将不同的计算单元如GPGPU,CPU进行3D异构集成,即实现更大的AI算力以及更高的能效比,同时提供更为通用的软件生态,使得CIM AI大算力芯片真正满足AI算力增长第二曲线的需求。目前公司原型技术验证芯片(POC)首次流片已回片并点亮,这也是首颗面向数据中心、云计算、自动驾驶等场景的存算一体AI大算力芯片。
Transformer面临参数规模过大问题
现在以Transformer为代表的各种AI大模型火爆全球,因为在精度跟并行度上的优势,很多领域现在都能看到它的身影。但这类大模型目前面临参数规模太大的难题,且还在呈指数增长,现有内存发展跟不上就会频繁遭遇“存储墙”。

视海芯图创始人、董事长 许达文博士
视海芯图创始人、董事长 许达文博士 在主题为《多模态AI终端芯片》的演讲中表示,由于精度高、具备全局特征和多模态、迁移性强等特点,当前很多AI模型的主干网络正从CNN转变为Transformer,并以机器人视觉、机器人主控和机器人大算力的路径,兼顾其他行业应用来开展具体业务,包括代码生成、AI对话、虚拟教室等应用场景也纷纷落地。
“但Transformer在终端芯片上遇到了因为参数规模太大,NPU利用率低的问题,为此视海芯图推出了SH1580 Transformer加速SoC芯片,采用自研NPU,配备高性能主核及图像处理,12nm工艺制造。”据许达文介绍,这款芯片的核心技术是自研PTPU架构,也称为多态张量处理器(polymorphic tensor processing unit),“由它打造的神经网络处理器可以对Transformer、Bert这些大模型做针对性加速,同时也能继续支持传统的CNN、RNN模型。”
高端IP对算力芯片极为重要
随着全球产业信息化向智能化跨越,半导体行业迎来算力等SoC芯片的需求爆发,芯动科技IP研发副总裁 高专 在主题为《高性能计算IP“三件套”:HBM/DDRn、Chiplet、SerDes》的演讲中表示,先进工艺大芯片是未来芯片产业的“主战场”,而这类芯片是IP堆积整合的结晶,既比拼高端工艺,更比拼高端IP。“没有IP,95%以上SOC公司做不出芯片。先进工艺大芯片,特别是Chiplet技术对成熟可靠的IP依赖更加严重。”
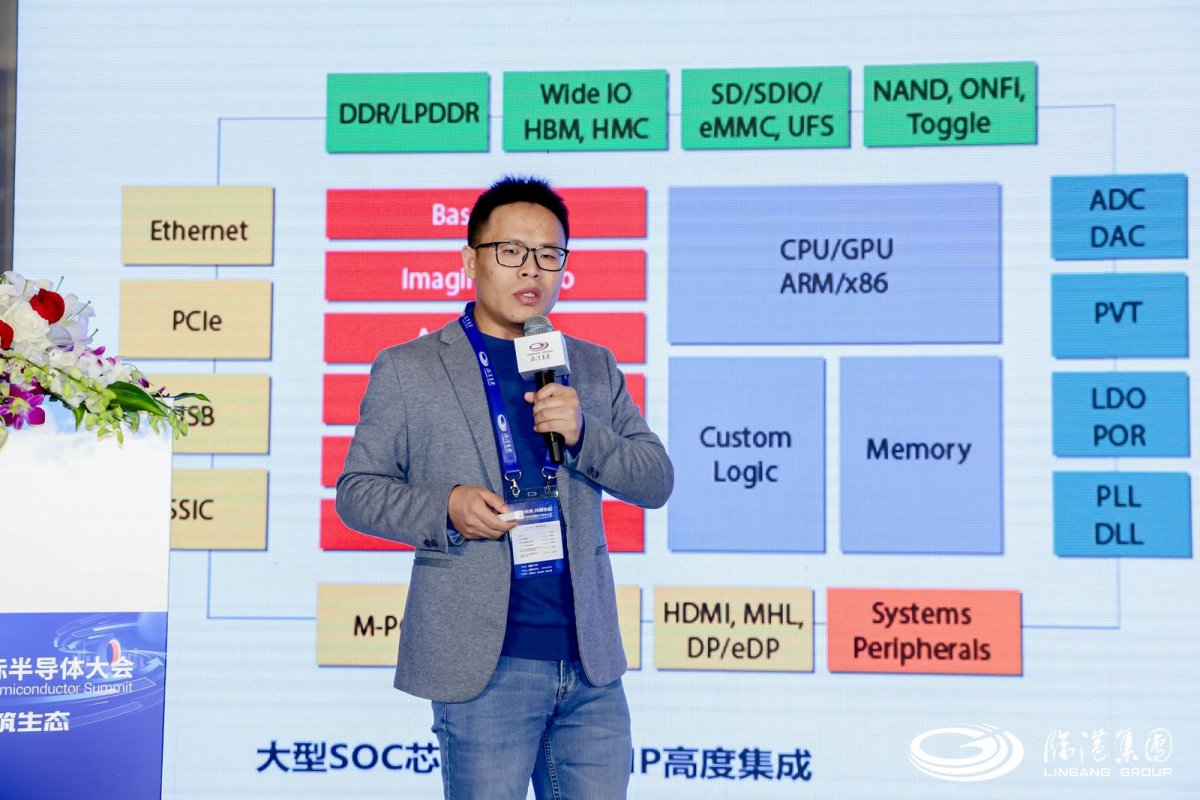
芯动科技IP研发副总裁 高专
芯动科技已在一站式高端IP和芯片定制领域耕耘17年,获得全球主流代工厂百万片晶圆授权,覆盖从55nm到3nm工艺全套高速IP核和ASIC定制解决方案,“尤其是12/10/8/7/6/5/3nm等先进FinFET工艺均已流片验证,全球知名客户过50亿颗SOC芯片背后有芯动技术。”高专说到。
为适应国内上下游企业和芯片产品的迫切需要,芯动推出了国产算力芯片IP“三件套”,包括高端HBM/DDRn系列、兼容UCIe标准的Innolink™ Chiplet系列、SerDes(PCIe6/5)系列,如今高端IP如GDDR6/6X、HBM2E/3、DDR5/LPDDR5/5X、SERDES、Chiplet都已实现量产验证。”
存算一体架构实现片上DNN训练
在PC通用性计算时代,CPU因为契合通用基础算力的需求获得了长足发展。在移动互联网/大数据时代,GPU则因为契合数据量激增后并行处理的需求,被众星捧月。然而,CPU不擅长大规模并行计算,GPU追求高算力的同时忽视了能耗,在智能化时代要满足海量数据的分析与处理需求,需要进行突破冯诺依曼架构的底层创新——存算一体,也称存内计算。

苹芯科技产品市场总监 王菁
苹芯科技产品市场总监 王菁 在主题为《存内计算在智能计算领域的应用与展望》的演讲中表示,存内计算结构可以通过降低数据的移动,大幅提高DNN的计算效率。但是过去的存算结构专注于DNN推理,而并没有对于DNN训练有足够的研究。“相较于DNN推理,DNN训练对于计算精度有更高的要求,为了实现片上的DNN训练,浮点计算是一个必须的功能,同时对于张量操作也有更多要求,这对于存内计算的设计也提出了新的要求。”
鉴于此,苹芯科技提出了基于哈德玛积形式的BF16浮点存内计算结构,实现浮点的DNN训练,将存内计算技术更好的应用于DNN的片上训练,实现应用场景的可定制化,为存内计算技术支撑下一代可穿戴设备、AIoT等更为广泛的AI应用场景奠定了基础。“苹芯的PIMCHIP-S系列端侧AI推理芯片系列,搭载SRAM存算一体计算加速单元,能够高能效、低功耗、低成本地完成多种数据密集型任务。其中PiMCHIP-S300能够提供1T算力,待机功耗小于100uW,支持多模态,通用性强,工具链支持高级语言。”王菁说到。
大模型已经并将持续影响半导体行业
人工智能(AI)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。从1956年达特茅斯会议上首次提出“像人一样思考的计算机”,到2022年OpenAI发布ChatGPT,人工智能已经在计算机视觉(CV)、自然语言处理(NLP)、音频信号处理(ASP)等领域广泛使用。随着GPT系列模型的火出圈,全球科技企业从不同角度快速跟进,其中就包括华为在今年开发者大会(HDC)上发布的盘古大模型。

华为制造与大企业军团 行业解决方案总监 孙磊
华为制造与大企业军团 行业解决方案总监 孙磊 在主题为《智能世界展望:从高性能计算到大模型》中表示,GPT-4已初步具备自主学习和思考能力,在文本/图像/音频/视频/代码等脑力劳动场景中已达到人类80%的水平。“预计未来AI的发展将跨越拐点,从‘预测推断’ 走向‘内容生成’,从替代低端重复性工作的专用领域,走向替代较高端脑力劳作的通用领域。”
如今人工智能进入大模型时代,使用门槛大幅降低,边际成本逐渐接于零,而Transformer架构则成为大模型中的主流,占比从2019年的26%增长到2022年的49%。“如今,大模型已经并将持续影响半导体行业。” 孙磊说到,华为也在盘古大模型上持续战略投入,推动大模型在计算机视觉、自然语言处理、多模态、智能检测和科学智能等行业的规模应用,“对于想要开发自己大模型的客户,昇腾大模型解决方案可以使能全流程开发与应用创新,鲲鹏HPC解决方案则可以使能软硬件全栈,实现端到端方案。”
AI能否驱动芯片产业链变革?
人工智能如今已经对芯片产业链中的设计、制造、封测和应用环节产生了一定影响。AI+芯片设计已经成为可能,尤其是在多层、3D 堆叠和异构集成等需要密集计算设计的任务中胜过人类,而生成式 AI 也为当今和未来 PCB 日益复杂的布局布线(P&R)问题提供了极具吸引力的解决方案。

AI4C应用研究院院长 管震
“几个月前,有一个用大语言模型成功设计出芯片的案例。”AI4C应用研究院院长 管震 在主题为《AI是否能驱动芯片产业链变革?》的演讲中表示,其实在EDA行业已经有很多成熟方案,可以利用AI来帮助芯片设计,例如Synopsys.AI的Copilot。“在软件行业大模型的应用就更多了,在帮助开发人员理解复杂代码并编写文档、评审代码、提出改进意见并自动生成大量单元测试等方面,大大提升了效率。”
管震强调,大模型应用的潜力应该在“具身智能”上,当整个应用群体都拥有具身智能后,AI就能在社会学、自动驾驶以及群体连接等方面发挥巨大作用。“芯片行业在这波浪潮中的爆发点可能是AI基座,也就是各种大芯片。但在具体应用落地上,可不仅仅是跟ChatGPT聊天这么简单,你首先需要明确需求,准备好供机器学习的数据,对各种大模型进行选择和微调,随后是架构设计、部署优化和用户培训。”可能企业不清楚哪款大模型更适合自己,或是具体怎样用来优化自家流程,这方面AI4C研究院可以提供帮助。
圆桌讨论:AIGC给AI芯片带来的机会和挑战
最后,在主题为《生成式AI应用的爆发,对AI芯片带来哪些机会和挑战?》的圆桌论坛上,主持人AspenCore资深产业分析师黄烨锋,与亿铸科技创始人、董事长兼CEO 熊大鹏博士、芯动科技IP研发副总裁 高专、苹芯科技产品市场总监 王菁 以及 AI4C应用研究院院长 管震,就生成式AI的商机、端侧和云侧生成式AI的区别、盈利模式、本土数据中心大芯片等热点话题展开了深度对话。


