
似乎在去年底、今年初,以ChatGPT为代表的生成式AI技术爆发以后,端侧市场的各路参与者都在想办法借生成式AI的东风,比如说PC领域内的芯片企业、OEM厂商都在谈轻薄本能跑生成式AI;就连嵌入式市场做SoC/MPU芯片的企业也在谈生成式AI...
最近联发科发布的天玑9300芯片,在宣传上叫“天玑9300旗舰5G生成式AI移动芯片”——这个词条剖析一下,5G是天玑9000系列的标配了,不用多谈;“旗舰”和“生成式AI”在我们看来特别对应于(1)全大核CPU架构设计,(2)能跑生成式AI。


这两点之所以引人惊叹,一方面在Android手机已经持续了多年的CPU大小核或大中小核设计,Arm的Cortex-A7、A53、A55都是相当经典的小核心设计,也是被市场验证了有效性的方案,而现在去掉小核,对一向沿袭Arm IP的联发科而言是个突破;
另一方面,端侧跑生成式AI这件事本身并不稀奇——真正让人感觉到惊讶的是,联发科表示自家的天玑9300跑70亿、130亿,甚至330亿参数规模LLM不在话下。这对追求低功耗的手机芯片而言,的确是很惊艳的成绩,也让生成式AI在本地推理真正有了价值。
我们主要从这两个方面,来详细看看这次的天玑9300。
天玑9300配置梗概及亮点一瞥
首先照例还是先汇总一下这颗总共堆了227亿晶体管的天玑9300的配置情况,并对照上一代天玑9200。
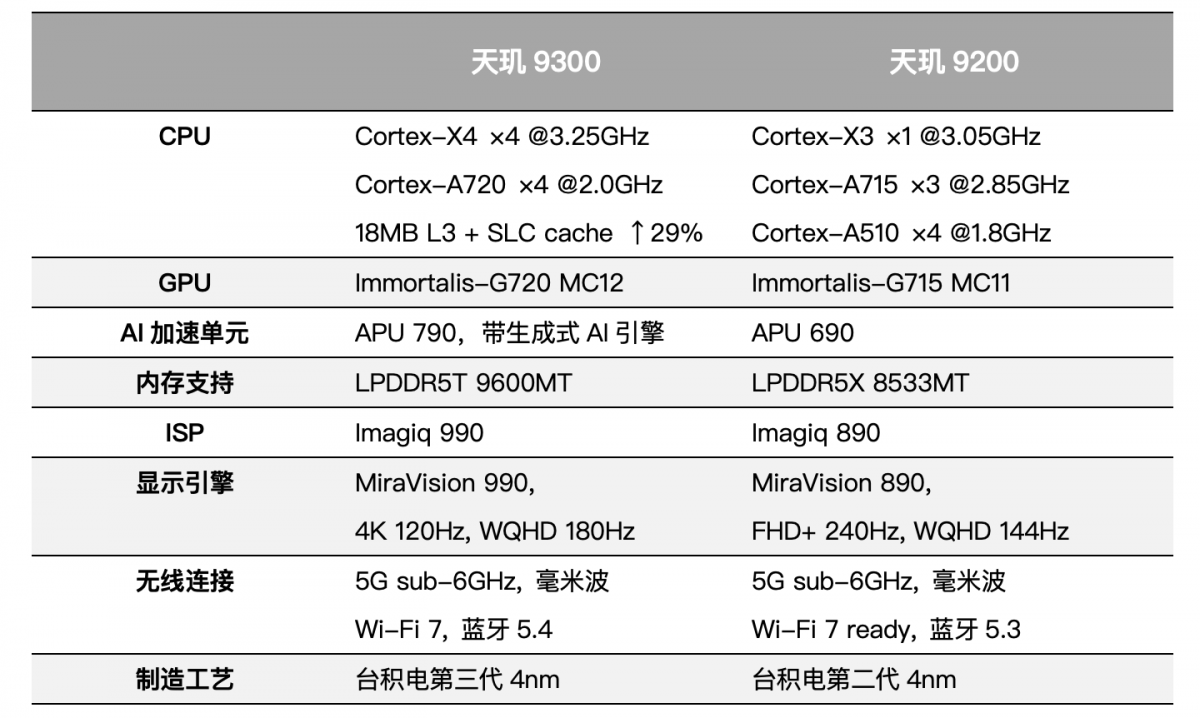
在我们看来这其中有几个亮点。其一当然是去掉小核心集群的CPU,虽然仍然是8核,但是4个Cortex-X4超大核加4个Cortex-A720大核。联发科给的数据是,相比天玑9200的多核峰值性能提升40%,但在达到天玑9200的峰值性能时功耗降低33%;
PPT中更是直接展示了Geekbench 6的多核得分在7500-8000之间,领先于“A公司A系列芯片”和“Q公司23年旗舰芯片”——查一下Geekbench 6的数据库就知道,这俩说的是苹果A17 Pro和高通骁龙8 Gen 3。

虽说这张图的比例尺是以6500分为起点的,柱状条的领先幅度看起来夸张了一点,但的确做到了CPU多核性能的全面领先的。
其二是AI加速单元APU 790能跑生成式AI——无论是发布会还是面向媒体的pre-briefing,这次联发科在APU花的篇幅那还真是相当大——APU算是第一次在联发科发布会上这么有排面,甚至是放在GPU前面去谈的,后文也会对此做详述。
其纸面数据主要包括“8倍速生成式AI Transformer算子加速”,“混合精度INT4量化技术”“NeuroPilot Compression内存硬件压缩技术”,2倍整数性能、2倍浮点性能提升,以及45%功耗降低。联发科在发布会上公布的ETHZ AI Benchmark v5.1跑分是2109分。不过媒体沟通会上,联发科也强调如果加上内存测试成绩,系统性能得分会再高出1000+分。毕竟跑大模型本身就非常考验存储性能。

所以实际上,内存方面LPDDR5T-9600MT的支持也算是个亮点。LPDDR5T的“T”最早是今年1月SK海力士宣布旗下的LPDDR5新品带宽达到9.6Gbps,相比LPDDR5X高出13%,所以命名为LPDDR5 Turbo,供电电压在1.01-1.12V范围内。三星和美光应该也有类似产品。
前不久国外媒体报道称,美光LPDDR5X-9600和SK海力士LPDDR5T-9600均验证兼容骁龙8 Gen 3。但在这次天玑9300的媒体沟通会上,联发科方面表示:“9600这个规模,在我们的芯片平台会是全球第一个落地,真正商用的,最终消费者能拿得到的。”并谈到“友商”在设计上实际并未落地,今年内应该也不会出现LPDDR5T-9600的终端产品。
对于LPDDR5T-9600的支持,可能也和生成式AI在这代芯片上的应用有关。因为我们知道,AI大模型对RAM带宽、容量都会有较高的需求。
配置表里的另一个亮点在GPU方面Immortalis-G720 MC12的升级。联发科方面表示,这颗GPU的峰值性能相比天玑9200的Immortalis-G715 MC11提升了46%,达到后者峰值性能时功耗降低40%;而且搬出了相比骁龙8 Gen 3、A17 Pro的两项GFXBench图形测试:
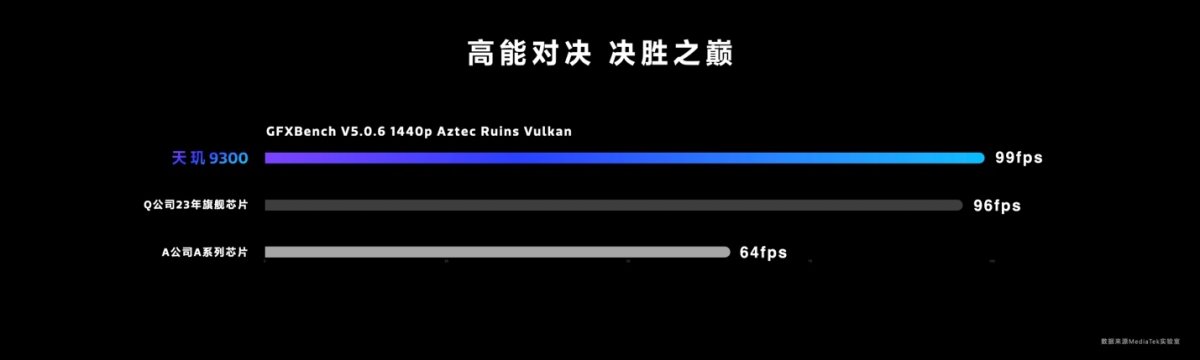

我们知道,苹果已经在GPU上挤了两年牙膏,而高通骁龙8 Gen 3的GPU性能升级幅度今年已经算是相当大的,但没想到Immortalis现在能这么争气。这里多提一句,注意上图中的两个测试,Aztec Ruins测试在几何复杂度上会逊于Manhattan,但shader负载高出不少。或可作为Immortalis和Adreno在性能侧重点上的差异比较依据之一。
另外这次天玑9300的GPU光追性能提升了46%,VRS性能提升86%——有关光追支持及天玑图形生态部分,也会在后文提及更多。
天玑9300芯片的其他亮点,还包括ISP升级到Imagiq 990,联发科特别提到AI语义分割视频引擎实现了“16层图像语义分割”,相比其他芯片多了几层;以及“全像素对焦”,“2倍无损变焦”,“OIS光学防抖专核”,并支持“3麦克风高动态录音降噪”。显示引擎、连接等相关的技术升级,这里就不多谈了,其实Wi-Fi 7增强Mtra Range 2.0、双路蓝牙闪连技术等也都算得上亮点。
CPU:“全大核”的存在合理性
今年Arm在新品发布会上谈TCS23方案时,推荐的手机AP SoC,CPU大中小核搭配方式包括了1+3+4,1+5+2,另外就是面向笔记本有10+4+0的新方案。高通显然是选了1+5+2的方案的,也就是1个Cortex-X4超大核,5个Cortex-A720(额外基于频率分了两组)大核,以及2个Cortex-A520小核。
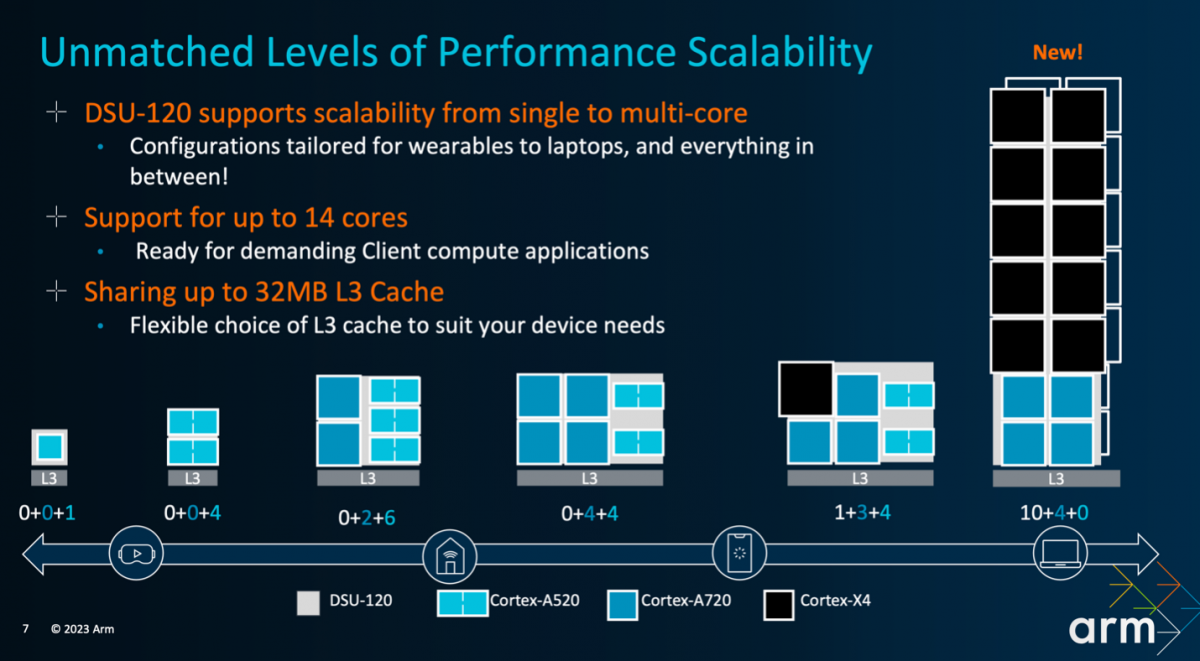
联发科一个也没选,而上了4+4+0的方案——倒更像是笔记本方案的下放。其实在去年联发科就对外表达过在PC平台SoC芯片方面的投入。此前联发科也有面向Chromebook的Kompanio 1380芯片。而在今年5月,电子时报消息称联发科正与英伟达合作,面向笔记本开发Windows on Arm平台产品。
如果此消息可靠,算时间联发科在PC芯片上的成果应该是能够惠及手机平台的(虽然一般我们应该反过来说)。这么看,是否感觉天玑9300在CPU部分的4+4+0方案合理了很多?(尤其搭配LPDDR5T落地,是不是更像那么回事了?)
一般我们说移动平台“小核心”的存在价值是为了省电——主要是低负载区间内保持相比于大核心,更低的功耗和更高的能效;并且以更小的面积换取尽可能高的性能收益。Arm的小核心到现在为止都还是顺序架构,为的就是维系轻量、小尺寸、低功耗。
但实际上,历史上移动平台没有采用“小核心”的先例早就存在。比如说高通早年的CPU自研架构,至少到骁龙820的Kryo时期,都还在坚持同构核心,而不存在什么小核心——也没有在续航方面打多少折扣。而且我们在也此前的分析文章中探讨过,骁龙820的末代自研Kryo架构更多的是生不逢时。
还有个绝佳的例子,虽然我们一直说苹果A系列芯片的CPU是“大小核”异构,但其实人家的“小核心”不仅历史上全程保持着乱序(OoO)设计,而且规模还真是一点都不“小”。比如A15的“小核”性能就超过Cortex-A76,甚至和低频点的Cortex-A78差不多。

全大核带来最显而易见的价值,当然就是多线程性能的显著提升。所以不出意外的,联发科宣布天玑9300相较9200,多核峰值性能提升40%,也领先于苹果和高通今年的竞品。还有包括实验室环境下安兔兔跑分超过220万,都算是宣传佐料。
堆核战术的另一个价值是多任务性能:媒体会上,联发科就提到在《原神》游戏极高画质达成60fps帧率的同时,还能进行微信视频通话。这在传统架构上是很难实现的。
其实这波性能发挥的关键,反倒应该考虑,手机这种小尺寸设备的系统设计是否能全力发挥出天玑9300的全部性能,尤其是4个Cortex-X4大核。这是未来很值得关注的问题。从联发科宣布GB6的性能成绩,以一个区间性能来做对比,可见天玑9300可能会比较考验OEM厂商的系统设计能力。
那么接下来的问题就是,去掉了小核,续航和能效还能不能保证?联发科在发布会上给出的解释和逻辑是,“大核做事快,休息快,低功耗”。这个逻辑当然没有问题,也是我们过去经常说的,很多时候不怕功耗高,只要匹配足够强的性能,其实能让任务更快速地完成——苹果以往就是这么做的。
我们说的“功耗”一般是指单位时间内消耗的能量(单位瓦特),而不是完成一件工作消耗了多少能量(单位焦耳)。手机续航考验的实际是所有工作消耗能量的总和;只要不总是处在高功耗状态,“越快做完越省电”。
凭借架构更新与工艺改良,及在高负载区间段的高效表现,天玑9300的功耗也有对应的降低。联发科提到达成天玑9200峰值性能时,天玑9300这边的功耗降低了33%——这是完全符合直觉的,因为更多的大核,在高负载区间段本身就有更高的效率。
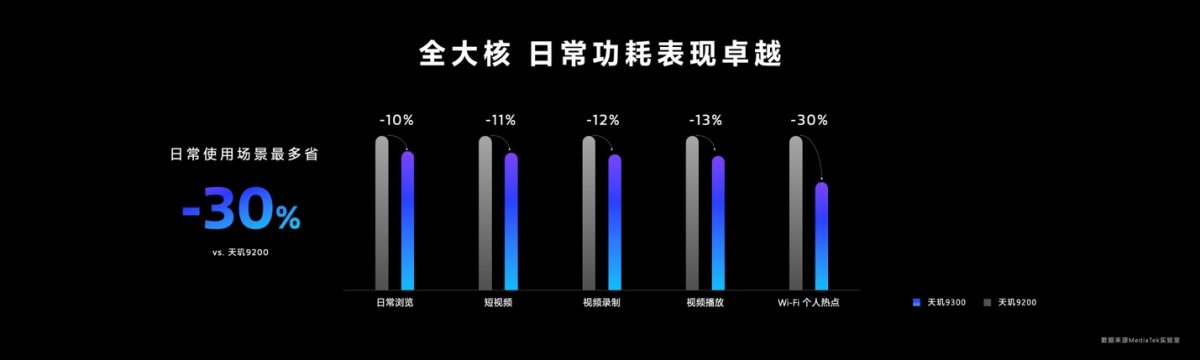
于是也就有了上图各类使用场景下,天玑9300的功耗降低。但其实这仍然不能解释,低负载区间段如何做到低功耗。Arm做这类3-cluster的设计,就是要在不同负载区间内,以不同的核心来解决问题——因为每个核心只在特定性能区间内才达到最高效率,如下图性能与功耗的关系。
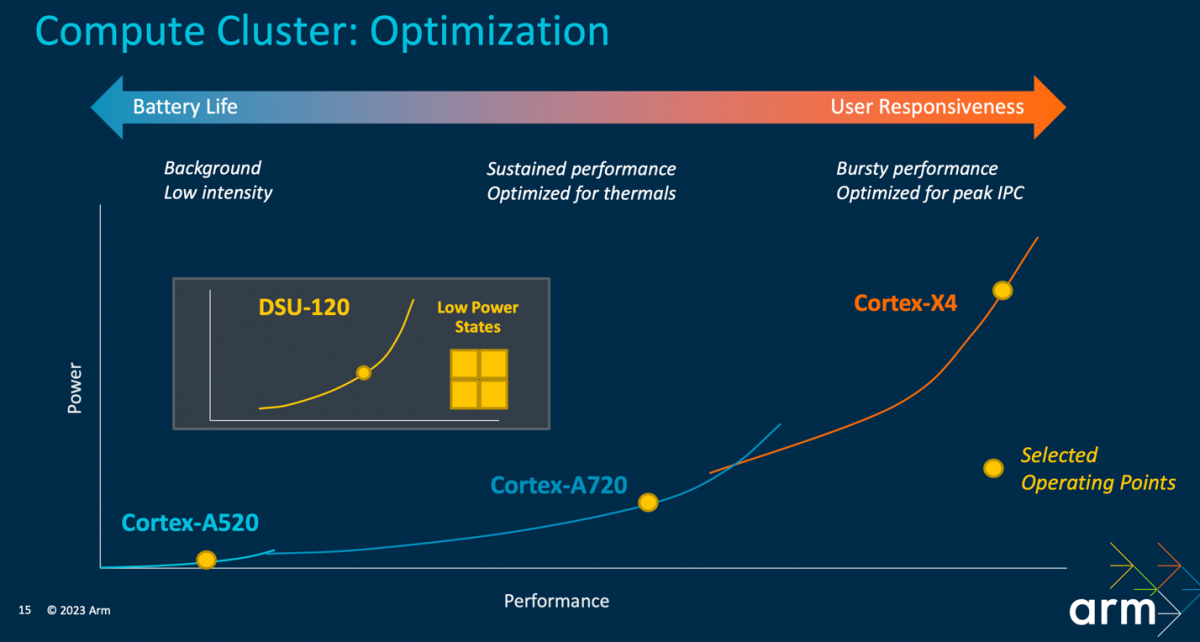
Cortex-A520这种小核就是在低负载区间,达成相比A720和X4更低的功耗。这是Arm设计此类架构的初衷。上面我们谈到的功耗降低,都很难说是低负载区间。所以天玑9300的4+4+0方案,在手机待机及低负载时,如何保证高效呢?
先谈一下我们的猜想。第一是从Cortex-A510开始,Arm的小核设计似乎就进入了某个瓶颈期。A510相比更早A55的效率提升真是一点都不大,性能提升基本是以功耗为代价;而且我们认为其面积效益不够理想。A520对效率问题着重做了改良,包括提升分支预测和数据预取性能,重构了存储子系统,去掉了原本的一些性能加强——比如去掉了一条ALU管线。但我们认为现在Arm的小核已经不复当年的经典。
其次可能和制造工艺有关。联发科在媒体会上说:“这几年我们在做架构设计时,一个比较大的观念转变就是不见得小核就比较省电。”“越往先进制程去,晶体管越小——太小锁不住漏电电流。”“则小核的功耗相比大核未必就会更好。越往后面这个问题会越严重。”“越快把系统关掉,其实比较省电。”
还有一种可能性,是随着移动生态的发展,操作系统与应用设计的耗电模型已经和几年前大不一样。现在芯片的内卷程度,已经到了芯片设计企业普遍会去关心上层细分应用场景。联发科可能在这方面做了更多的工作。
“以军队来讲,你要料敌精准,知道哪个敌人要先干掉,然后快速歼敌。”联发科方面谈到,“我们能够做到的事情是,把关键的一些程序定义出来,快速将其解决掉,接下来军队就能回去休息了。”据说其中也涉及到不少与其生态系统合作伙伴的合作、调优。
“未来我们会做的事情是,在省电的时候能睡得更沉。”“我们花了3年时间去做这件事。除了硬件设计之外,软件、系统设计怎么去找到关键场景做优化,将应用聚集在一起,快速将其执行完毕,快速深层地睡下去。”“这不是个简单的事情,必须从端到端,从硬件到软件到系统全部串在一起。”
“系统背景有很多小小的程序,那些程序跳出来的时候,CPU就会被唤醒——那就一定会有功耗产生——我们要做的是,把系统里面小小的波动,要么把它结合起来,要么拿到旁边,可能用别的硬件或者SCP(system control processor)的方法去做。这就涉及到更细节的如何进一步节省功耗的问题了。这个技术持续地在做提升,我们会一路这样做下去。”
虽然我们对于联发科具体是如何在极低负载区间段确保能效的,仍然不甚明朗,但这段话大约可以表明,联发科应该有在其他方面做技术补充。最后,联发科还多次强调“我们相信全大核架构,明年开始大家都会往这个方向去走”“未来是全大核的世代”。
APU:手机上的生成式AI
天玑9300更新的另一个重点无疑就是APU 790了。从联发科的示意框图来看,APU 790新增了“生成式AI引擎”,很容易让人联想到英伟达在这代Hopper架构中特别加入的Transformer引擎。这是顺应AI时代潮流的做法,相当于在加速器中又加了个更专用的加速器。
媒体沟通会上,联发科谈到APU 790“深度适配Transformer模型”,尤其“优化Softmax + LayerNorm算子,处理速度是上一代的8倍”。因为对Transformer而言,Softmax+LayerNorm占到了其中的大头。

现在我们常说的Transformer结构采用所谓的self-attention(自注意力)机制,捕捉全局相关性、在一个队列内不同element的关系。Softmax函数就用于帮助决策attention的量或者一句话里每个词的重要性。而LayerNorm用于在一个层级上,跨神经元进行数值的nomalization。
以前行业普遍认为Transformer的结构特性更适用于NLP(自然语言处理);而CNN(卷积神经网络)的卷积特性,决定了其擅长图像分类、对象识别之类的视觉型工作。所以很显然LLM大语言模型就以Transformer结构为基础。
2021年Google Research团队发了个paper,他们提出一种解决方案,把一张图像切割成小片,每一片作为一个单字、token,则Transformer就能处理图像相关工作了。Vision Transformer一时也变得很热。像Stable Diffusion这类所谓“多模态模型”多少也都有Transformer结构的影子。这应该也是APU 790强调“生成式AI引擎”的基础。
好像过去我们说LLM、Transformer、生成式AI这些关键词,都会和数据中心集群这种大家伙,或者至少也是TDP数百瓦的旗舰级桌面显卡关联起来。不过这几个月,端侧跑生成式AI的宣传越来越多。不管是手机还是PC,这类端侧设备所谓的“跑AI”或者“运行AI”,一般是指AI推理(inference)。
正儿八经、商用的大模型training还是要放到服务器集群上去跑的——可以理解为打造一个模型的过程。模型打造好了,就要拿来用了——也就是推理的过程。推理有时也需要大算力,比如ChatGPT的AI推理就是在服务器集群上进行的。
但小模型的推理其实并不需要太高的算力,就连IoT嵌入式设备很多也强调AI推理特性,这也叫跑AI。天玑9300跑生成式AI指的就是对一定规模的生成式AI模型做推理——这些模型的规模虽然不会大到ChatGPT的程度,但也有一定的量级。
比如联发科在这次的宣传中提到,天玑9300能跑70亿参数的AI大语言模型,20 tokens/秒的生成速度;而且“成功在端侧运行130亿参数AI大语言模型”;并达成“首款移动芯片成功运行330亿参数AI大语言模型”。
其实对后两个规模的LLM宣传,我们并不清楚其运行环境与确切的实用性如何——330亿这个值应该是为了对标骁龙8 Gen 3的100亿参数规模支持能力而提的。
但70亿参数LLM的20 tokens/秒仍然是具备了实用性的——而且联发科也提及与vivo合作实现了70亿参数LLM的端侧落地。可能很多同学对参数规模没什么概念,此前我们体验过用笔记本酷睿处理器,在不用加速器的情况下能跑60亿参数的ChatGLM2、130亿参数的Llama 2、155亿参数的StarCoder——不过要注意,这是纯粹靠CPU跑出来的。在此可作为量级参考。
另外联发科表示天玑9300实现Stable Diffusion“高速生成式AI图像生成”<1秒——这个表达有些模糊,因为Stable Diffusion文生图涉及到迭代次数、图像分辨率等各种问题。
但总的来说,要实现上述量级的模型在手机芯片上跑起来,光靠APU的Transformer模型算子加速其实也还不够。除了在我们看来,全大核CPU以及高频LPDDR5T内存也能帮上忙,联发科还做了其他相关技术的补充。

其一是内存硬件压缩技术NeuroPilot Compression。可量化的数据是LLM 130亿参数大模型原本需求13GB内存,则在加上Android操作系统及其他app保活的内存需求以后,现在旗舰手机的16GB内存也不够用。所以NeuroPilot Compression能够在量化、压缩以后,将其压缩至5GB。
其二在开发生态和工具链上,联发科应当也是需要做不少相关工作的,包括模型量化、优化与转换,最终简化、降低端侧本地推理的性能需求。这其中包括模型方面的合作,这次列举模型相关的合作包括Android AI foundational model,百度文心一言、百川大模型,以及Llama 2,“针对主流大语言模型做深度适配与优化”。具体应当包含了这些模型在端侧的部署。
另外值得一提的是联发科提到“生成式AI端侧‘技能扩充’”,“在大模型的基础上,让端侧的AI学会更多的技能”——NeuroPilot Fusion技能扩充技术,让天玑9300成为“首款支持生成式AI在端侧LoRA融合”的芯片,“基于一个大模型,通过云端的训练,在端侧完成N个功能的融合,赋予大模型更全面的能力。”LoRA(Low-Rank Adaptation)一般用在我们常说的模型fine-tuning上,特点是可减少参数量。这里所说“端侧LoRA融合”的逻辑和流程,我们暂时不是很明晰——从介绍来看,LoRA融合是NeuroPilot开发工具链的一部分。
这部分的最后还是要谈一谈应用。毕竟高喊生成式AI,最终要落地到手机的应用上。联发科现场演示了用天玑9300芯片的手机按照输入的要求生成诗句,生成图片和斗图表情包(叫text-to-meme),以及输入个人照片来生成个人专属风格gif表情包。
另外有个更实用的应用,是与vivo合作打造的AI助理,以对话形式完成工作:比如说语义搜索、画图、文案生成、照片修图、查资料、生成思维导图、一键识屏安排日程等等。

联发科自己列举的生成式AI应用还包括图片的生成式超分(与虹软的合作)、视频通话基于真实人像的3D形象实时生成(与morpho的合作)、夜景照片防眩光(与TETRAS.AI的合作)等等......端侧生成式AI前期的生态理论上又会是相对割裂的,这一时期也是芯片企业需要抓住的时机。联发科在发布会上展示的生态合作伙伴除了前面列举的这些,还包括快手、剪映、美图秀秀、虎牙直播、抖音、爱奇艺、QQ音乐等。
未来手机上的生成式AI技术成果,大概是能在这些应用中逐渐看得到的。真正的杀手级应用,还真得看应用层的这些参与者的点子了——联发科提供的是硬件基础和开发平台。手机用户们可以期待一下。
GPU:这次真的成了
天玑9300发布会第一次让我们感觉到,联发科的产品与技术点讲解根本来不及,因为似乎亮点有些过多了。光是CPU和APU的介绍就花了40+分钟。这就让GPU、ISP之类同样值得着墨的部分,只能相对简略地去谈。这在联发科的手机AP SoC发布会历史上应该是从没有过的。
比如从去年9月起,联发科就相继与Discovery合作摄制纪录片节目,还举办了影展,就让ISP介绍显得更有厚度。但显然在这场发布会上,ISP的风头就彻底被APU盖过了。有关ISP、显示引擎、无线通信支持,双安全芯片,以及联发科常规项目的低功耗配套技术,受限于篇幅也不再赘述。
这里我们最后来聊一聊GPU和联发科的图形生态,毕竟关注天玑芯片的手游用户也相当多。前文已经大致提到了这次联发科给天玑9300选配的是12核Immortalis-G720,峰值性能相较天玑9200提升46%,达到天玑9200最高性能的情况下,功耗低了40%。综合图形性能也强于A17 Pro与骁龙8 Gen 3——这应该是联发科,也是Arm第一次在绝对性能上全面超越了另外两名劲敌。
这个数字比我们预期得要好,因为Arm发布Immortalis-G720时,提到的是平均15%的持续与峰值性能提升。Immortalis-G720在设计上实际更强调的是系统级能效提升,尤其是更低的内存带宽占用——这代架构的DVS(Deferred Vertex Shading)显著降低了带宽需求及游戏中的DRAM功耗占比,平均功耗降低20%。而天玑9300的GPU性能提升,很大程度应该来自于新增的一个核心。

其余数值基本与Arm的宣传相符,包括带宽需求降低、VRS性能提升、MSAA优化等。系统性能数据,联发科在发布会上提到即便是《原神》极高画质下的须弥地图,天玑9300也能在30分钟内跑满60fps;以及840p分辨率极高画质下《星穹铁道》能够满帧运行30分钟。后者是个明显更偏GPU性能发挥的游戏。若非风头被APU抢走,天玑9300的GPU绝对是值得大书特书的。
有关光追,PPT中提到硬件光线追踪性能提升46%。Immortalis在核心架构层面决定了,更多的shader核心就能带来更高的光追性能。
天玑9200的光追性能在Basemark InVitro测试中目前排在了第一(机型大概是即将发布的vivo X100)——Arm此前也在发布会上特别强调了Basemark InVitro的领先。联发科认为,Basemark InVitro是“比较贴近复杂的光追场景”,光追在场景中所占比重较大,可以反映实际光追性能。
从已知测试来看,A17 Pro在3DMark Solar Bay光追测试里有着相比天玑9200更好的性能发挥。基于46%的提升值,天玑9300在这项测试里应当也能拔得头筹。不同测试中的排位差异,可能仍与光追测试是否仅考察光追反射,光栅化在场景中参与度,或是否同时包含更复杂光追测试等状况相关。
可能更多用户就手机游戏光追,更关注的还是游戏支持和生态发展情况。就生态相关问题,联发科宣布天玑9300“首发支持《暗区突围》 60fps光追”,另外《仙剑世界》光追版也准备在天玑平台首发。联发科表示,加入到天玑光追生态的游戏已经有50+款,而且生态做到了Unity, Unreal, Messiah三大引擎的全覆盖。这在手机行业里暂时应该也是独一家。光追终于有用了。

图形生态相关的另一个亮点在于全局光照生态支持,和虚幻引擎、Arm合作,在Unreal 5 Lumen中融入了Vulkan Ray Query+“桌面级渲染Shader Model 5”。具体到与腾讯游戏合作,在《暗区突围》游戏中应用全局光照Smart GI技术。这类技术的普及应该是手游玩家都期望看到的。
此外,图形技术相关更新还包括MAGT游戏自适应调控技术升级为“星速引擎”。据说在应用星速引擎以后,《王者荣耀》实现了15%的功耗降低,载入对局速度提升了30%。从这些数据还是能够看到联发科的图形生态,正在深入影响国内的手游行业的。

未来手机的个性化需求
天玑9300的确从各个维度带来了惊喜。不过最让我们惊喜的仍然是生成式AI在其中的强化。在媒体采访中,联发科对于手机应用生成式AI有个畅想:“手机是随身携带的,它知道你的个性化需求,你的位置在哪儿。在回答你的问题时,可以将全部资讯包含在内,做到个性化的回答,是你真正需要的。”
“生成式AI的手机是充满想象力的。输入是多样性的、复合的,语音、文字、手势等等。”“旗舰机一路走来,大家应该慢慢将它从跑分中脱离出来了。”“生成式AI手机能生成什么、创造什么,这才是更基本的。”
11月13日,vivo X100将首发天玑9300芯片。这可能会是生成式AI手机翻开的新篇章。
