
在不到五年的时间里,最先进的AI模型规模经历了5000多倍的扩张。很大程度上,这些AI模型依赖基于复杂计算和大量内存的高性能深度神经网络(DNN)。对于拥有海量数据的这类大规模DNN的训练,只能依赖由CPU、GPU或专用芯片等构成的大型计算节点集群才能完成。
智能网络接口卡——SmartNIC,如今已成为现代网络基础设施中的一个关键组件,专门用于增强网络性能、减少延迟和提高整体系统效率。它可以从主CPU中卸载与网络相关的任务,从而为其他关键型操作释放宝贵的处理能力。
在高性能计算(HPC)领域,SmartNIC获得了巨大的吸引力。为了实现最高性能,HPC环境需要高处理能力、高效的数据移动和高速互连。通过提供高级网络功能和专用硬件加速,SmartNIC在HPC应用中表现优异。

提高AI系统效率
当前的各类机器学习发展趋势中,都包含分布式学习,而这类学习通常都采用并行数据训练,每个节点在不同的数据子集上训练模型。基于这些节点训练获得的权重梯度被定期组合,并用于模型权重的更新。
对于在分布式系统上有效扩展AI训练而言,主要目标是在处理计算密集型张量运算时,对计算节点的利用最优化。最新研究出来的一个有潜力的解决方案是,将所有计算节点的all-reduced操作都转移到专门为AI设计的专用NIC上。该类NIC采用FPGA来实现,进而使CPU和NPU能够专注于深度学习和AI计算所必需的张量运算型任务。这样,通过把网络相关的任务交给SmartNIC来处理,可提高整个系统的效率。
随着SmartNIC技术的不断发展,各个行业参与者都积极提出了许多先进的解决方案,以满足云和企业架构不断发展的需求。这些解决方案旨在将网络和安全加速功能汇聚到一个平台中,提高系统的性能和效率。AMD的Alveo U25N就是一个这样的例子。它是一个25GbE SmartNIC平台,专为构建现代数据中心云和企业架构所设计,具有超高吞吐率、小数据包性能、低延迟及可编程网络结构。
除了减轻处理器的负担外,SmartNIC FPGA还可定制,且易于编程。这种灵活性可赋能开发人员根据AI和深度学习工作负载的具体需求,对其功能进行定制。
用于AI的SmartNIC
深度神经网络的指导训练涉及以下几个步骤:
第一步,称为前向传递,DNN对用于以mini-batch输入的输出进行预测,并计算出与ground truth label之间的误差。
接下来,在反向过程中,该误差被传播通过所有层,来计算权重梯度(计算出的信息)。
最后,利用梯度和优化规则来更新权重,将预测误差最小化。对多个mini-batch(一个epoch)重复此过程,直到精度收敛。
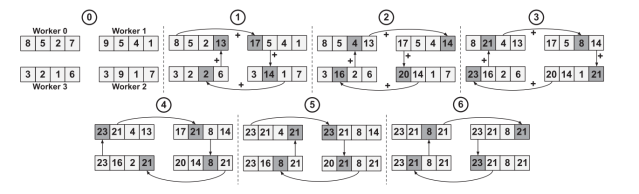
图1:具有四个worker的流水线型ring all-reduce。(来源:《IEEE Computer Architecture L.》)
为了有效训练大型DNN,采用了分布式训练系统。这些系统采用多个worker,这些worker可以是CPU、GPU或专用加速器。这里,选择的解决方案是数据并行化。每个worker采用不同的mini-batch训练模型,并对学到的信息(即实施一次all-reduce操作后的权重梯度)进行定期交换。
Reduction操作可以相互结合和交换,例如求和、最小值或最大值。all-reduce算子是许多并行算法的基本构建块,如分布式排序、矩阵乘法和机器学习。
All Reduce算法广泛应用于并行计算中,将来自多个进程或worker的数据合并到一个统一的阵列中。Worker指的是负责执行SmartNIC架构内特定任务或操作的计算组件或实体,包括CPU核、GPU或专门用于处理网络、卸载和加速功能的其他处理单元。
AI SmartNIC系统架构
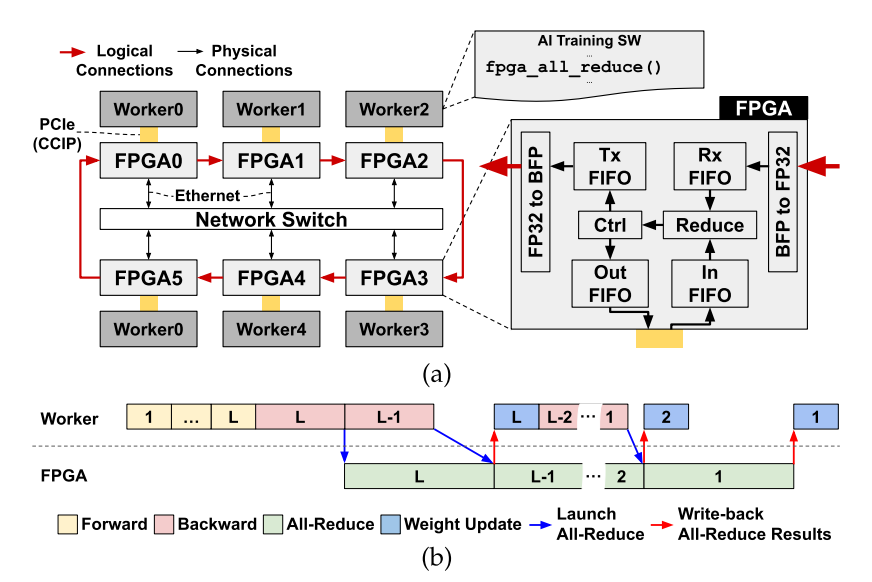
图2:(a)系统概述和AI智能NIC架构(b)用于L层MLP训练的执行跟踪示例。(来源:《IEEE Computer Architecture L.》)
图2所示为一个配备有AI SmartNIC的系统,其中每个worker通过PCIe连接到FPGA,而所有FPGA都通过网络交换机互连。将FPGA以环形拓扑结构安置在以太网层级的顶层。
FPGA从本地worker读取权重梯度,并将其存储在输入FIFO中。同时,通过以太网接收来自前一节点的reduction操作结果,并在Rx FIFO中进行缓冲。一旦两个FIFO都准备好了,它们的内容就会出列,并采用FP32加法器实施reduce操作。然后,通过Tx FIFO将结果发送到环中的下一个节点,或者是将该结果作为最终的all-reduce结果,通过一个输出FIFO写回本地worker存储器。
以GPU为中心的SmartNIC
FPGA网络接口卡(FpgaNIC),旨在将GPU的角色从worker转变为网络数据处理的主处理器。在传统的网络架构中,GPU通常充当worker,而CPU承担主处理器角色。但实际上,消耗网络流量最多的却是GPU,所以这是不合理的。FpgaNIC重新将GPU作为主处理器,从而为围绕SmartNIC的设计方案带来了灵活性。该SmartNIC的一个关键功能是能够采用GPU虚拟地址,实现与本地GPU的高效直接通信。通过采用GPU虚拟地址,SmartNIC可以绕过不必要的数据传输,实现与GPU之间的更快、更精简通信。通过这类直接通信,增强了整个系统的性能,并减少了延迟。

图3:试验型配置。(来源:2022 USENIX年会论文)
该SmartNIC采用FPGA,通过PCIe实现SmartNIC和本地GPU之间的直接P2P通信。FpgaNIC的另一个特点是,它可提供100Gb的硬件网络传输能力。这意味着它可以与远程GPU建立高速网络通信,实现跨分布式系统的高效数据传输和协作。SmartNIC充当本地GPU和远程GPU之间的桥梁,简化其间的无缝快速通信。
近年来,行业中已利用SmartNIC相关的最新研发成果,实现了许多设计,其中之一就是专为高频交易业务而开发的SmartNIC平台,该平台由Orthogone和Napatech合作开发,利用FPGA来实现。
通过这一战略合作,将Orthogone的超低延迟(ULL)FPGA IP核及FPGA开发环境与Napatech的可编程SmartNIC相结合,以提供高效的性能和超低延迟的事务数据处理。该合作旨在满足金融科技企业(如贸易公司和投资银行等)的苛刻要求,可提供灵活集成、交钥匙部署选项和硬件的升级适应性。
Achronix半导体最近宣布,其(ANIC)现在已包含400千兆以太网(GbE)连接及PCIe Gen 5.0网络性能。ANIC IP支持400GbE,实现了超快的数据传输速率,支持海量数据的实时处理。这种加速的网络吞吐量,最大限度地提高了应用性能,并显著降低了延迟。采用模块化结构,每个优化的IP块都经过了闭环timing to speed预验证,支持用户根据应用选择所需的SmartNIC组件,以加快设计速度。再加上在IP设计中可动态更改模块功能的部分可重配置能力,从而在现场就可对解决方案进行无缝修改。
随着对高速数据处理的需求持续呈指数级增长,SmartNIC技术已为AI训练和云计算领域中的组网和数据处理取得重大进展铺平了道路。已经证明,这些专用网络接口卡有助于克服现代计算的挑战,实现高效的数据卸载、关键型任务的加速以及与现有基础设施的无缝集成。随着持续的研发,可以期待SmartNIC技术的进一步创新,进而释放新的可能性,推动网络和数据驱动型应用的下一波进步。
(参考原文:an-introduction-to-smartnics-and-their-role-in-hpc)
本文为《电子工程专辑》2023年11月刊杂志文章,版权所有,禁止转载。点击申请免费杂志订阅