
这几个月,用笔记本PC跑生成式AI的话题挺热的——芯片厂商普遍都开始往电脑处理器里加专门的NPU单元了,OEM厂商也正为来年AI PC的宣传蓄势待发。
其实这几个月里,Intel不同业务部门的媒体活动,都或多或少把注意力放在AI上。尤其CCG业务,从年初就开始科普没有独显的笔记本PC也能跑生成式AI。我们围绕这个话题也做过不少报道了。应该说,近几个月Intel在AI生态构建方面下的工夫还是相当大的。
过去我们只是见过Intel官方在这方面的演示,从未亲身上手。所以这次,我们自己用一台采用13代酷睿处理器、没有独显的轻薄本(联想Yoga Pro 14s)来真的跑一跑AI和生成式AI,看看效果和体验怎么样,探究AI在PC上的潜力。


PC跑生成式AI的理论基础
迄今仍有不少同学对于端侧PC,尤其轻薄笔记本跑生成式AI这样的大东西是不理解或没有概念的。所谓的“跑AI”,大方向上包含了AI training(训练)和inference(推理)两件事。正儿八经、商用的大模型training一般是要放到服务器集群上去跑的——可以理解为打造一个模型的过程。
这个模型打造好了,就要拿来用了。比如用户要和ChatGPT对话,就是用ChatGPT模型的过程,即为inference。Inference也可能需要相当大的算力,所以我们常能听到GPU或AI芯片厂商面向服务器的“推理卡”——和ChatGPT对话的过程,就是在服务器集群上做inference。
但有不少小模型的inference其实并不需要多高的算力,很多端侧IoT嵌入式设备也强调AI inference特性——这也叫“跑AI”——此前Arm不是还在宣传Cortex-A55 Neon指令集增强的AI推理加速吗。我们说用PC来跑生成式AI,一般是指用PC对生成式模型做AI inference。当然了,“生成式AI”肯定不是低功耗IoT设备小模型的那种量级,所以一定的算力仍然是必须的。
不过像Intel这种厂商宣传PC能跑生成式AI,在我们看来,更多的倒不是去宣扬自家处理器性能有多彪悍,而是Intel为了实现在PC上跑生成式AI,在生态上所做的努力。

虽然近两年电脑CPU性能的确变得越来越彪悍,但作为一种通用处理器,CPU的并行算力还是无法与更专用的处理器相较的。
要在PC CPU上跑生成式AI模型(比如LLM大语言模型、Stable Diffusion),需要经过模型转换、优化、量化等过程。比如前不久Intel宣传的BigDL-LLM库,就用于简化在端侧PC上的LLM大语言模型推理,尤其做量化,用Int4、Int3这样的低精度数据做inference,降低本地硬件资源需求。
那么Intel就需要花不少精力去做这些事,包括各种中间件、库、工具的搭建。这些事实上也成为Intel搭建自家AI生态的重要组成部分。显然让群众基础甚广的PC都跑上AI,自然是其AI生态可扩张的重要一步。
先聊聊笔记本上的酷睿i9-13900H
我们这次跑AI的主角就是联想Yoga Pro 14s(2023款):酷睿i9-13900H的CPU,搭配32GB LPDDR5-6400 RAM,和顶格速度的民用SSD固态。
这台笔记本就体态来看,无论如何都应该算是轻薄本(包括RAM不可更换,IO接口也不多)。其整机厚度与散热设计,就跟去年我们测过的全能本很不一样(下图)。散热孔在整台设备D面,也没有激进的进出风鳍片与格栅。C壳的圆润楔形收边,也让这款笔记本在视觉上看起来更薄。


但其实从性能释放的角度,Yoga Pro 14s又不大像轻薄本。为了喂饱酷睿i9-13900H这颗标压处理器,官配的电源有100W功率(比较贴心的是USB-C口100W供电)。今年Intel在游戏本上主推HX系列(H55)以后,轻薄本都普遍开始用H系列(H45)标压处理器了。而P系列和U系列这类低压和超低压CPU,今年就显得十分罕见。
为了让体验不要显得那么枯燥,除了联想Yoga Pro 14s,我们也拉来了去年体验过的采用12代酷睿的Dell灵越14 Plus,以及此前测试13代酷睿处理器时的台式机(还加了Intel Arc独显)。
一方面可以看看,同样是跑AI,13代酷睿相比12代酷睿有没有进步;另一方面也给各位同学一个大致的概念——即PC跑AI和生成式AI,大约是什么样的量级水平。这三台设备的配置如下(注意,这次我们测试不会用上Dell灵越14 Plus的GeForce RTX 3050独显,因为生态上完全不一样):
 * 测试都基于设备的最强性能模式,如Yoga Pro 14s设定为“超能模式”,而灵越14 Plus设定为“疾速”性能档
* 测试都基于设备的最强性能模式,如Yoga Pro 14s设定为“超能模式”,而灵越14 Plus设定为“疾速”性能档
值得一提的是酷睿i9-13900H作为13代酷睿CPU,其实和游戏本市场很火的i9-13900HX差别还是比较大的。后者和桌面端i9-13900K更接近(如上图“参考台式机”)。酷睿i9-13900HX相比i9-13900H,有更多的P-core与E-core核心数,更高的TDP功耗设定。所以如果考虑用今年的游戏本来跑后面的测试,结果应该会更好。
另外,一般我们说13代酷睿用的P-core性能核,是相比前代改良过的Raptor Cove架构,主要表现为cache架构优化,与工艺BKM迭代,所以在CPU能效方面有进步。只不过因为i9-13900H并未像i9-13900HX那样增大L2/L3 cache,所以虽然Dell灵越14 Plus所用的酷睿i7-12700H是12代酷睿,我们仍然可以近似地认为,这两台本子的性能对比,很大程度上是CPU核心频率差异,平台内存带宽与延迟变化(i9-13900H相比12代酷睿支持更高的内存频率),以及OEM厂商系统设计给到的散热与功耗限制差异对比。
就理论性能部分,我们简单跑了一下Cinebench R23测试,给各位同学一个可参考的性能量级水平。这两台笔记本连续不间断跑15轮Cinebench R23多核性能测试,得到如下结果:
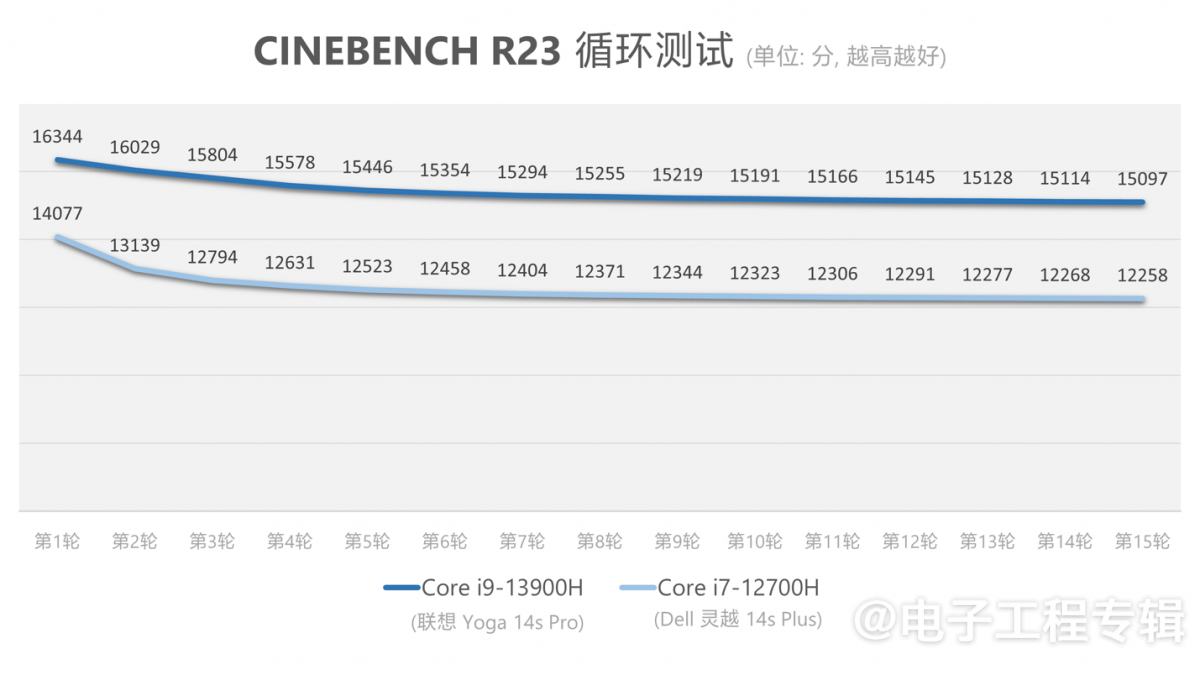
从这项测试来看,Yoga比灵越性能领先约16%左右。这个结果基本符合频率提升带来性能提升的预期。不过i7、i9级别的笔记本标压处理器,性能差异可能更大程度来自于系统设计的差异,而非芯片本身。值得一提的是,Yoga Pro 14s作为轻薄本,竟然还有着更持久的性能发挥,第15轮仍然发挥出了首轮92%的性能;而灵越14 Plus作为全能本,性能则在第15轮测试时掉到了87%。
持续性能对后面的测试是有价值的,比如ETH AI Benchmark一次要跑20分钟,还有相对复杂的Stable Diffusion推理也需要持续性能。那么更持久的性能发挥,在很多AI测试中,也就能表现出更高的综合性能(更短的inference等待时间)。
我们也简单看了看Yoga Pro 14s的性能释放水平,观察4轮Cinebench R23循环测试下,CPU封装功耗与温度变化情况:

可以看出这台笔记本还真的很不像“轻薄本”,系统设计给到的性能发挥相当激进。CPU满载时,封装温度一直在95℃上下波动,前三轮测试封装功耗最高记录能够达到87W——怪不得要配100W的适配器。在我们的印象里,“轻薄本”性能释放应该都在20W左右的水平...
而且就我个人近半个月使用Yoga Pro 14s的体验来看,这台笔记本的噪音和外壳温度控制都非常好,应该是我近些年用过的Windows笔记本中最好的水平。可见芯片之外,系统设计对于体验的影响有多大。
在跑生成式AI前,先来跑个AI Benchmark
到目前为止,在PC上跑AI都没有特别完善的benchmark基准测试工具。今年年中UL Procyon倒是出了个AI Inference Benchmark for Windows。但过去一周我们申请该工具的press license都没有收到回复——直到前两天全部测试结束后,UL Procyon回复了license......所以这次是赶不上了,等下次测试再用吧。
其实去年体验另外一台笔记本时,我们测过ETH(苏黎世联邦理工学院)的AI Benchmark。但这个测试工具的问题是,项目已经3年没有更新,始终停留在alpha阶段,大概已经不能代表现在AI的发展水平。但没办法,在迟迟没有收到UL Procyon的回复之时,也暂时只能考虑用它了。
在尝试跑ETH AI Benchmark的过程里,我们遇到了各种实际问题,比如说它所需的依赖包之一numpy版本过老,以及各种依赖包版本和路径变量等问题。所以这个测试只作为参考。

值得一提的是,我们是在Windows 11的WSL(Windows Subsystem Linux)里面用Ubuntu 20.04.6 LTS系统跑的AI Benchmark测试。一方面是因为此前的文章我们就探讨过,用WSL跑这类测试的效率和性能明显更好;另一方面则是ETH AI Benchmark测试真的太老了,现在直接在Windows里面跑会遇到大量报错,短时间内似乎也很难解决,大概主要还是依赖包的版本问题...
该测试所依托的TensorFlow库一直在更新:去年8月测的时候还是TensorFlow 2.9,这会儿已经是TensorFlow 2.13了。所以从下面的结果,我们也能看出运行效率相比以前的显著提升。
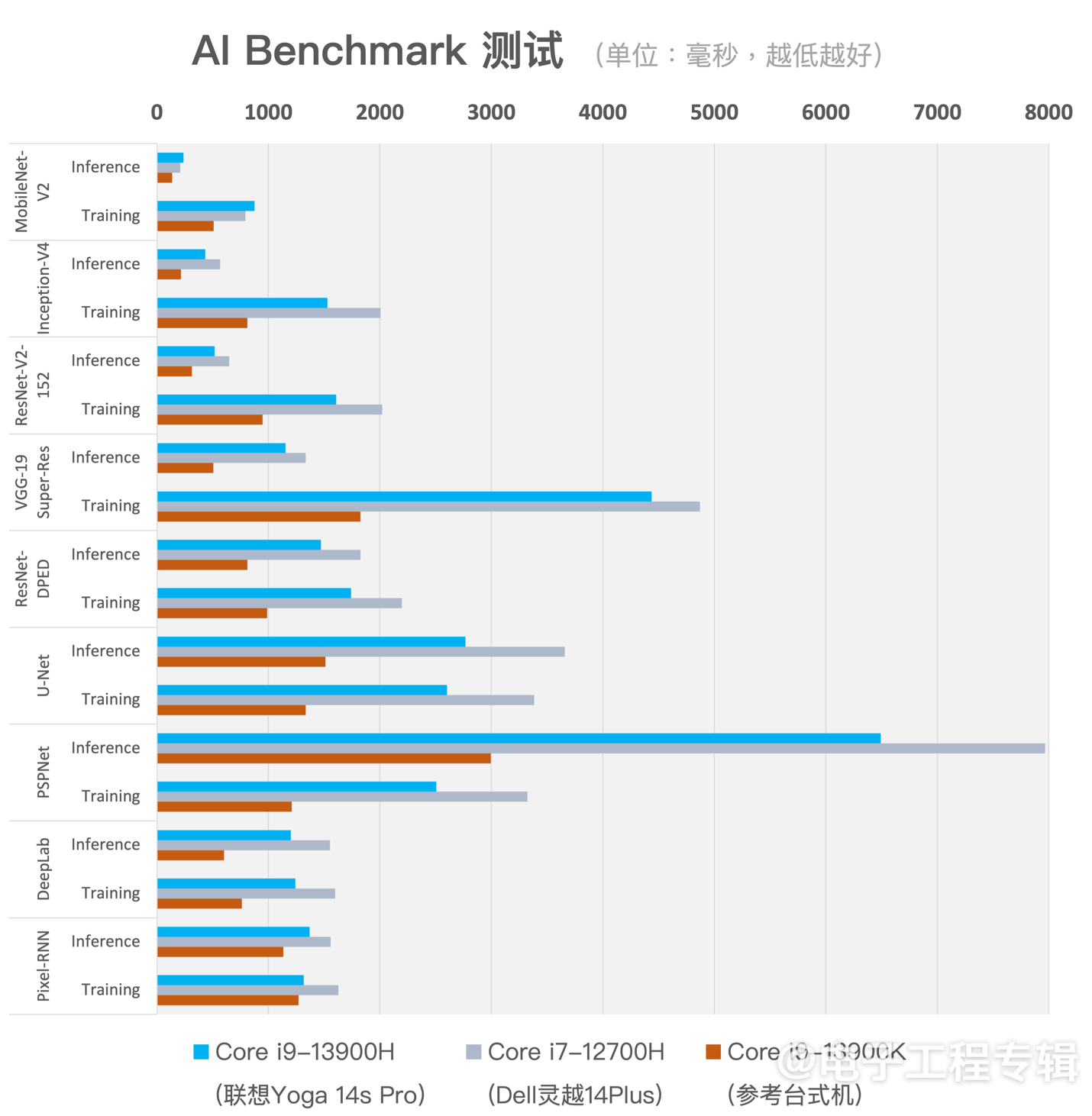
AI Benchmark测试项目比较多,这里只列出了其中9个。一方面可以看出i9-13900H相比i7-12700H,在跑AI的速度上的确还是快了不少的;当然核心数更多、cache更大的i9-13900K则在测试里表现出了碾压级别的性能优势——对于AI这种并行算力需求很大的负载而言,自然是计算单元越多越好。
另一方面,如果跟我们去年8月所做的测试对比,会发现:这次测得的性能成绩,相比去年(去年测了酷睿i9-12900H与i5-1240P)有显著提升。比如像PSPNet、UNet这些子项,inference和training时间都缩短了50%以上。显然这就不是光靠CPU性能提升了,TensorFlow更新应该在其中起到了很大的作用。
在测试的命令行界面里,TensorFlow提示语提到了oneDNN(oneAPI Deep Neural Network库)——去年年中,Intel新闻稿就提到oneDNN的性能优化就默认在TensorFlow 2.9版本中开启了。所以可能部分性能提升是来自Intel这段时间在软件方面的工作——不了解oneAPI是啥的同学,可以去看看Intel在这上面都做了些什么。
但实际上,12代、13代酷睿都并不支持AVX512指令,所以不清楚在CPU的指令执行层面,测试有没有对应的加速。而且我们也留意到TensorFlow的提示语说,部分特定指令的加速支持还需要对TensorFlow做重新编译(包括AVX2?)——因为时间原因,我们也没能来得及这么做。则理论上,这些测试得到的成绩还有进一步的提升空间。
另外,我们也观察了一下在跑AI Benchmark的前4个网络时,CPU封装的温度与功耗变化情况:
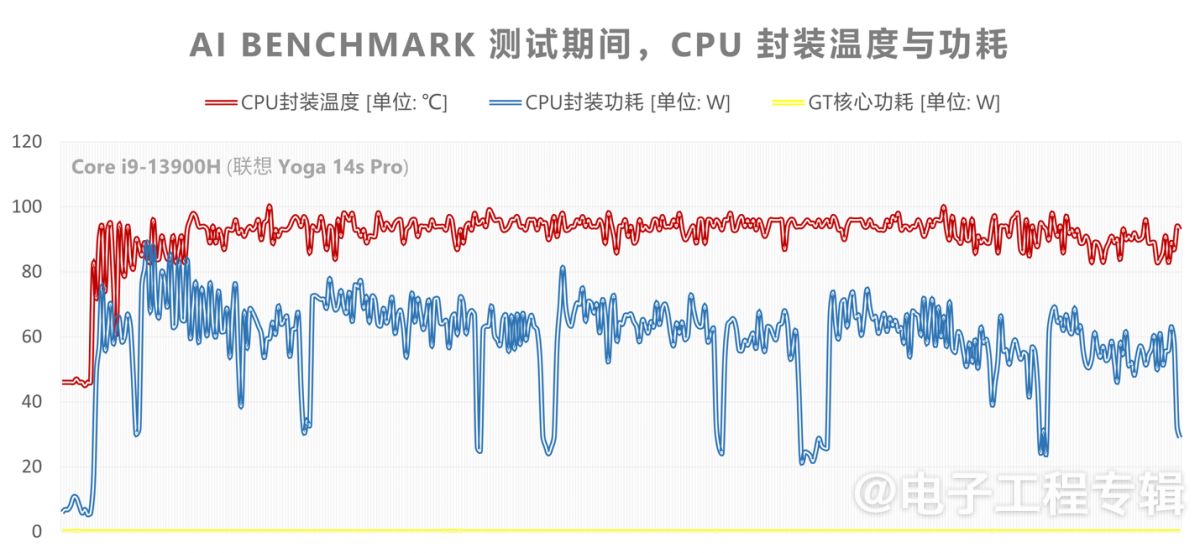
留意最下方那条平直的黄线——它代表核显功耗全程几乎无变化,表明这些测试并没有用到核显加速。就功耗和温度数字来看,AI Benchmark也几乎做到了让CPU满负荷:测试期间14个核心的频率与使用率变化,也可佐证这一点。
这部分最后汇总AI Benchmark的性能得分:
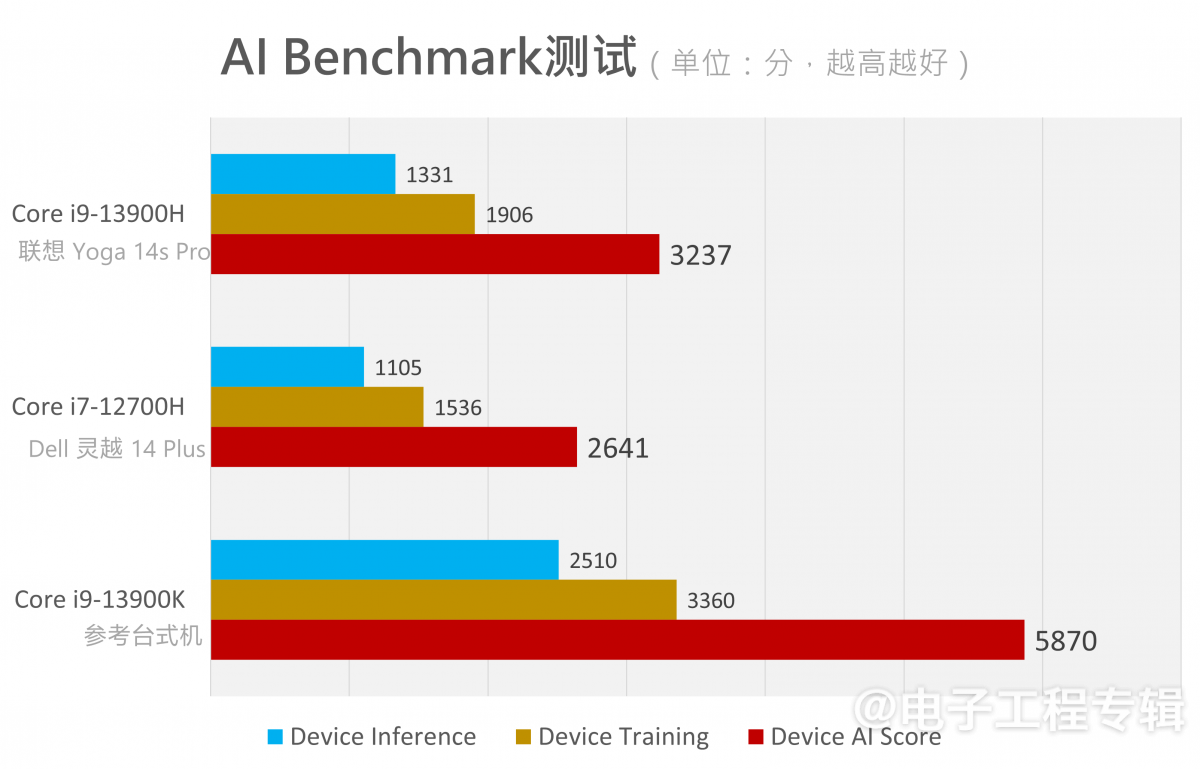
对比去年测的ROG幻16(酷睿i9-12900H),AI Score总分是1956分;今年一台轻薄本就把这个分数提升了65%。看来AI软件与生态的发展的确还是相当迅速的,即便是CPU,即便是ETH AI Benchmark这个长久没有维护的项目。
另外需要提一嘴,上述测试皆限定了WSL子系统的内存容量为12GB。我们也尝试了将内存容量提升到24GB做测试,发现对这些测试的结果几乎没有影响,所以就没有将24GB RAM的结果放上来。
让AI写代码、作图
接下来就该正式跑生成式AI了,无论Stable Diffusion,还是ChatGLM或Llama这些LLM,规模上都一定是上述测试的网络所不能比的。
先谈谈Stable Diffusion,就是现在很火的,输入提示语,就生成图片的模型——这类应用当前在CV领域相当热门。11月份《电子工程专辑》封面故事也将特别去谈生成式AI对于计算机视觉的价值,欢迎届时关注。
其实要在Intel平台上去跑Stable Diffusion,我们发现路径还不少。比如说针对Intel CPU可以用Optimum Intel库加速Stable Diffusion;也可以用Stable Diffusion OpenVINO项目,在Intel GPU上跑Stable Diffusion;另外似乎还有PyTorch Stable Diffusion项目,也可以在Intel CPU、GPU上跑。

基于OpenVINO去跑Stable Diffusion,网上能搜到最常见的方法,应该是装上Python、OpenVINO Notebooks,然后在Jupyter Notebooks里面按照一段段的代码引导,来执行文生图(text-to-image)或者图生图(image-to-image)的inference操作。流程上也不难,但我们没有采用这种方法。
OpenVINO是个啥呢?前不久介绍Metoer Lake NPU的文章里,我们详谈了在面向开发者时,OpenVINO推理引擎相关的AI软件堆栈。它能够将Stable Diffusion或者别的模型转为IR中间表达格式,然后令模型跑在不同的Intel处理器上。
我尝试了我认为最简单的方法,先下载GIMP(一个开源的修图软件),然后装一个OpenVINO AI插件,就能在GIMP里面直接做文生图操作了。这也是今年年初Intel对外宣传轻薄本跑Stable Diffusion时演示的方法。Github上该项目名为OpenVINO-AI-Plugins-GIMP。
另外,Intel做的这个OpenVINO插件不光是有Stable Diffusion,还有包括一些常见的CV应用,比如对象语义分割、超分(super resolution)等;有兴趣的同学可以自己去试一试。

感觉Intel做的这个GIMP插件有一点挺好,即Stable Diffusion的各个组成部分,包括文本编码器、Unet、VAE解码器可以由用户分别指定,是跑在CPU上,还是跑在GPU上(以及未来的NPU上)。因为此前Intel在宣传中就提过,虽说全部跑在GPU上速度很快,但功耗也不低——要达成最优能效,还是得奉行XPU方案。
在我们这台Yoga Pro 14s笔记本上,选择对应的模型,在20次迭代的选项下,输入提示词,输出一张512x512的图片,如果完全用CPU的话大约需要50+秒的时间。下面这些是我们在这台笔记本上,让Stable Diffusion生成的部分图片:

看样子我们写生成提示词的水平还有待加强,毕竟看到网上大家秀的图都那么好看......不过进一步强化模型的话,未来用于辅助设计之类的工作,应该也是相当可期的。而且要知道,这真的就是凭借CPU的算力,在没有VNNI加速、没有GPU加速的情况下,不到1分钟就inference出来的图片。
有人说那为啥不直接用Midjourney这类云服务呢?隐私、安全与网络连接限制是一部分;更重要的是在本地跑的话,模型可自己定制微调,几乎没有限制,这是Midjourney之类的服务做不到的。

没有量化的成绩始终没什么意思。其实Intel为了展示PC平台跑Stable Diffusion和LLM的能力,自己特别做了一站式的图形化演示工具(基于Stable Diffusion webUI)——里面也放了他们做好的模型,点几个按钮就行(如上图)。我们基于Intel提供的这款演示工具,来简单测一测相同条件下,几款参测设备的AI性能水平。
测试分成三轮,每轮给不同提示词(三轮分别生成球场上正在打篮球的男人;月亮上骑着白马的宇航员;桌子上色彩斑斓的芯片......当然实际提示词会更复杂,另外设定了反向提示词,例如不希望篮球场景出现草坪),输出512x512分辨率的图片,50次Unet迭代,选择OpenVINO加速。记录inference花费的时间,三次取平均。
因为首轮inference会涉及到模型优化与加载的过程——这个过程存在的变量比较多,所以以下记录的都是模型加载完成后,第二轮inference的性能成绩。因为OpenVINO也支持GPU加速,所以我们也测了用GPU来跑AI inference的成绩,包括处理器自带的Iris Xe核显,以及台式机上的Arc A750独显。

结果和ETH AI Benchmark是相似的。仅CPU的对比,酷睿i9-13900H(3.12 s/it)比i7-12700H(3.96 s/it)更快;而拥有更多核心数的i9-13900K(1.67 s/it)则是遥遥领先。GPU方面,两台笔记本所用核显规格基本一致,可能i9-13900H的Xe核显频率会略高——所以两者的GPU加速推理性能成绩差不多(1.13 it/s vs 1.04 it/s)。
核显加速的确能够大幅缩短inference的时间,仅需CPU不到1/4的时间就完成了推理工作。当然,这些在Arc A750独显(9.13 it/s)面前都是浮云。听Intel此前媒体沟通会的意思,他们在这类模型的GPU加速支持上,所做的工作还比较初级;未来的软件更新,可能还会带来很大的提升幅度。
注意这个成绩并不能反映CPU、GPU推理Stable Diffusion的绝对性能,也不能反映CPU和GPU的相对性能关系——因为参数设定差异很大时,推理所需花费的时间差别也十分巨大。比如说如果还要做人脸加强修正(Stable Diffusion一般都画不好人脸)和超分,或者增加迭代次数,那么inference的时间会明显拉长数倍。所以上面这个成绩只能反映不同处理器的并行算力存在差异。
另外,我们也记录了用Yoga Pro 14s笔记本跑一次Stable Diffusion推理工作时,仅用CPU时、以及用GPU核显加速时,IA核心(即CPU核心)与GT核心(即核显)功耗变化情况,可给予各位同学以参考——功耗应该是粗粒度反映处理器资源利用效率的一个参考:

△ 仅使用CPU跑Stable Diffusion时, CPU封装功耗与IA核心功耗变化
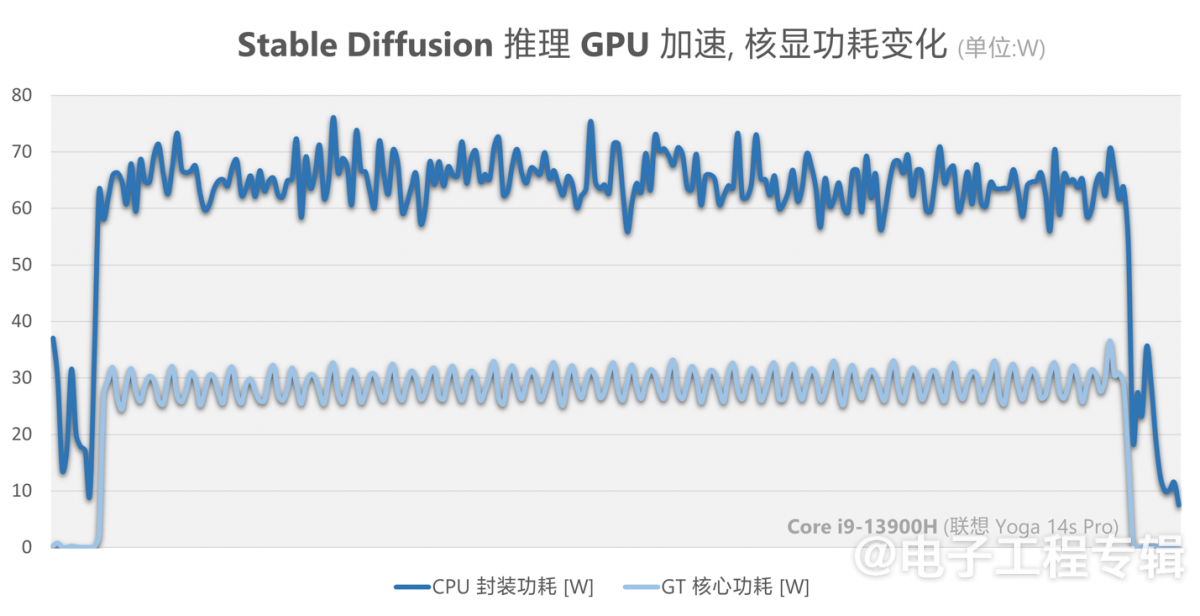
△ 使用GPU加速Stable Diffusion时,CPU封装功耗与GT核心功耗变化
最后就是LLM大语言模型,也就是类似ChatGPT那样的人机文字对话。Intel给出的LLM演示工具包含了3个模型,ChatGLM2-6b,Llama2-13b,StarCoder-15.5b。
这三个模型一方面有着不同规模的参数量(60亿、130亿、155亿);另一方面,ChatGLM用于中文对话,Llama羊驼则是现在相当流行、据说效果堪比ChatGPT的英文对话模型,还有个StarCoder是会写代码的大语言模型。所以我们面向三个模型,问了三个问题,分别如下:
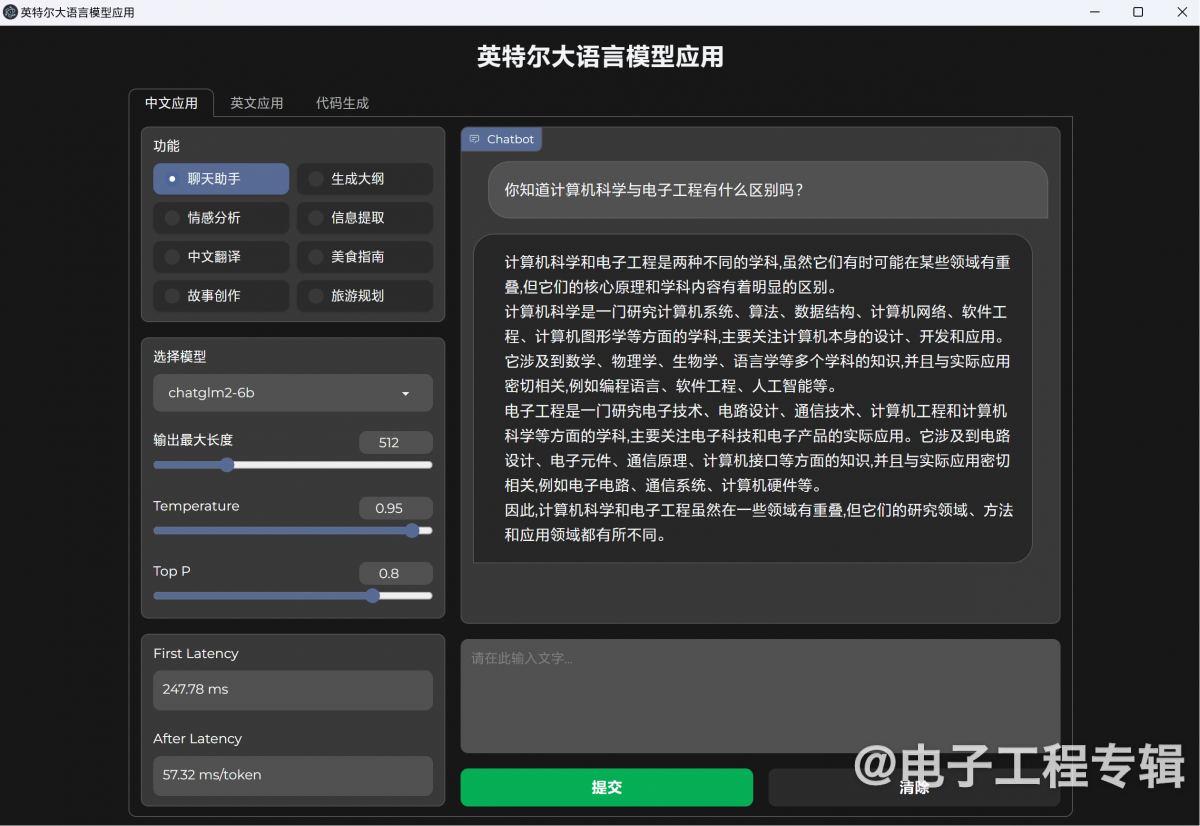
△ 问ChatGLM2-6b,计算机科学与电子工程的区别是什么;
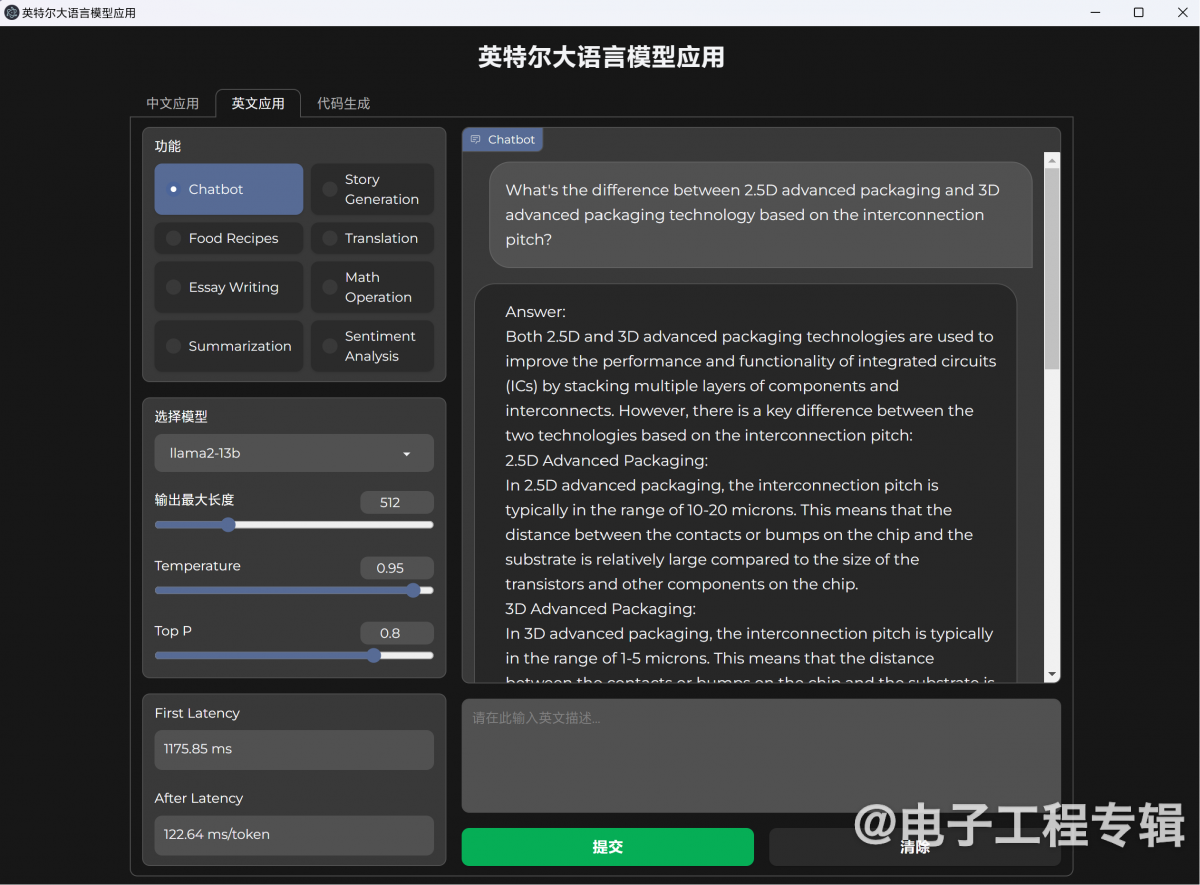
△ 问Llama2-13b,2.5D封装与3D封装的互联间距区别是什么;

△ 让StarCoder-15.5b写一段MySQL代码,创建table,并添加数据;
问答效果还是让人满意的。尤其是Llama2答有关先进封装的问题,回复相当切题,是围绕着我们限定的互联间距来答题的,而不是随随便便说两句2.5D和3D封装的结构差异。
而向StarCoder发出的问题虽然比较简单,但问题长度较长,是细致到建立一个MySQL表,并添加几行数据的逻辑。回复也完全准确,毕竟StarCoder号称是“最先进的代码大模型”。
对于LLM而言,反映硬件算力的维度主要是first latency(首个token生成的时间,单位ms;可以理解为在发出问题后,模型反应需要多久)与after latency(其后平均token生成速率,单位ms/token;可以理解为模型回复时,打字的速度...)。上述三轮问答,我们测试得到的结果如下:
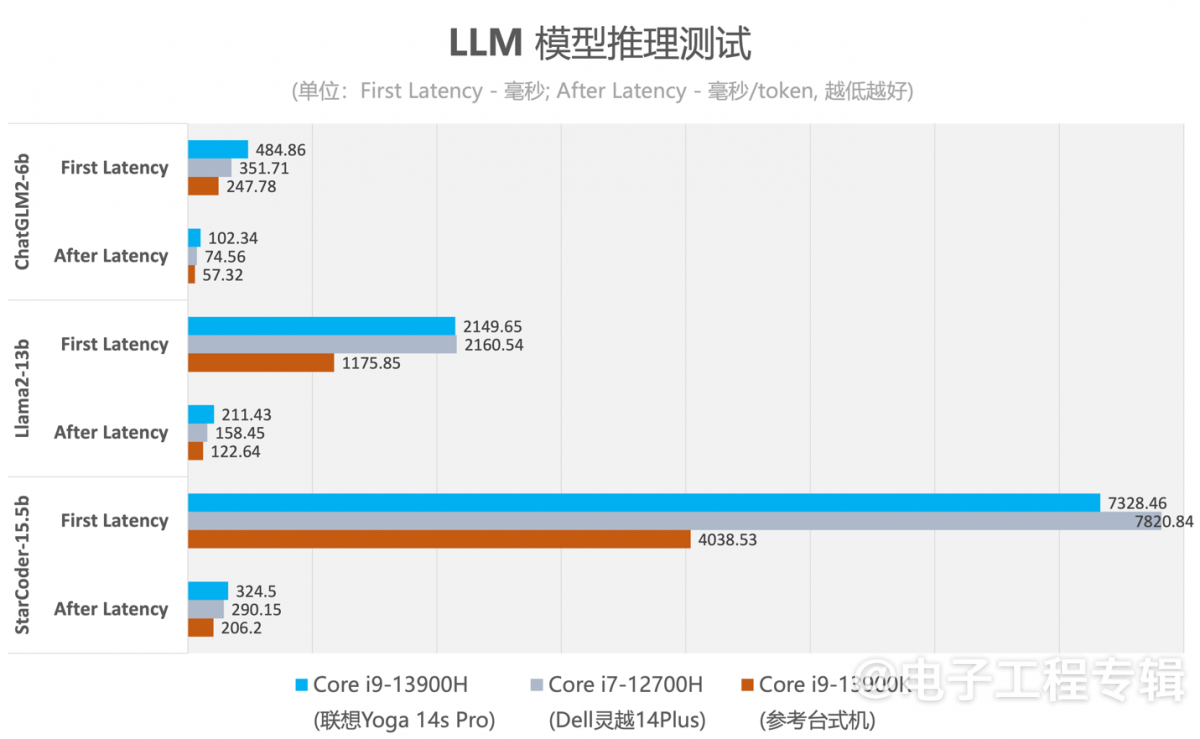
除了最后一个问题问出之后的等待时间达到了7秒,其余问题的first latency都是可接受的;而在首个token出现以后,基于人眼常规的阅读速度,after latency也满足直觉需求。
不过这份数据的参考价值可能更低。主要是因为模型针对相同问题作答的响应时间,每次都不大一样,差别大到无法在少量取样的情况下反映不同硬件的性能差异。除了台式机表现出绝对性能优势外,两台笔记本的表现飘忽不定,一会儿这台强一些,一会儿那台强一些。大概LLM inference的过程存在很多变量,所以这份数据就当是图个乐吧...
这里就不分享跑LLM模型期间的处理器功耗变化了——Intel提供的演示工具没有GPU加速选项,我们也观察了模型inference期间的处理器状态,发现的确没有GPU的参与(在台式机上观察StarCoder模型inference全程,Arc A750显卡的整体功耗都没有波动,或GPU可能参与很少?)。
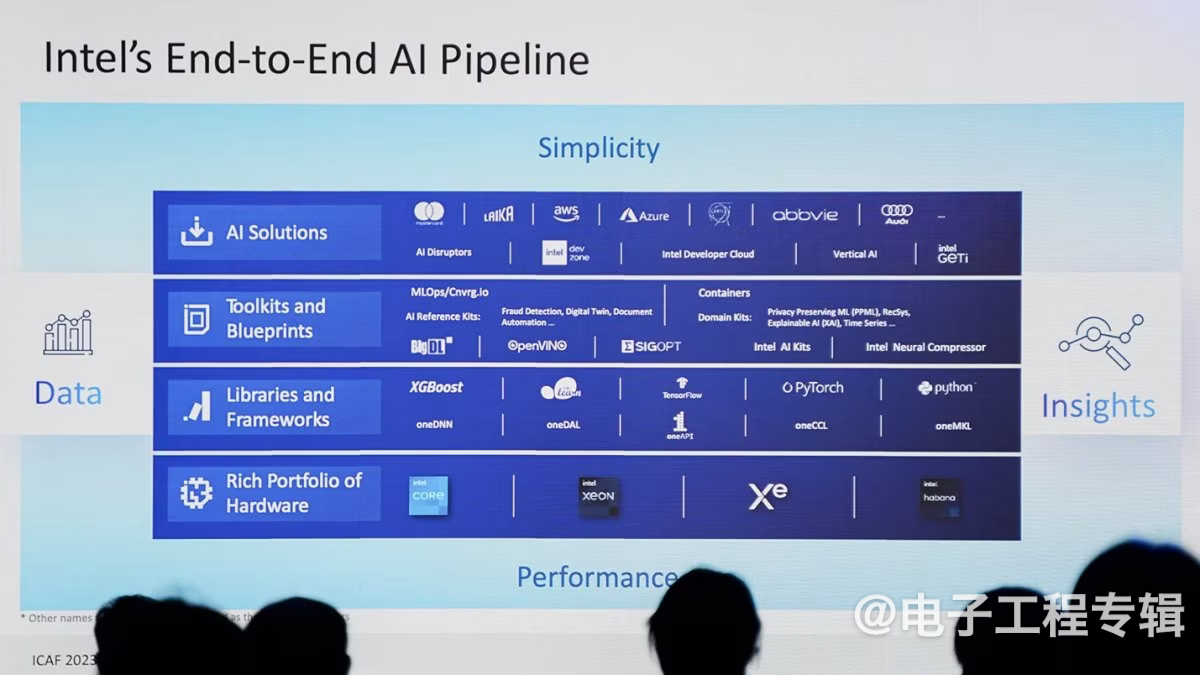
其实PC能跑生成式AI这件事,已经不是什么新闻了。有关生成式AI对于PC的价值,或者在PC上的应用,我们此前也写过不止一两篇文章。而AI PC只是Intel期望构建AI生态的其中一环,端到端的AI pipeline才是Intel着眼的,从云到端,从training到inference,从算力基础到上层解决方案。虽说对Intel而言,这方市场的竞争难度现阶段已然不小,聚拢PC市场基础、扩展软件生态亦有可为。
这篇文章期望给各位读者构建起PC跑生成式AI的基本概念,给对AI感兴趣的同学以基础内容索引。未来我们会持续改进PC平台之上,AI测试的工具与流程;而对于PC的探讨,大概会越来越频繁地提及AI,这也是行业的共识。
- 看得还挺仔细...的确是~~不说我还没发现...
- 问题是,现实中的2.5D封装的典型间距,也不是LLM给出的15-20um吧?包括之前个人试用Bard,Cloud等AI模型的时候,最怕的就是模型一本正经的胡扯,尤其是涉及到具体的数据的时候。
