
这次Intel Innovation(英特尔on技术创新大会)上,Intel发布的Meteor Lake处理器里面有一个AI推理加速单元:NPU。这东西对PC究竟有什么用?
这篇文章,我们来聊聊Meteor Lake的NPU(Neural Processing Unit)。此系列文章另外包含Meteor Lake的关键技术点介绍,以及Intel 4制造工艺和Foveros封装技术介绍。
其实在代号为Meteor Lake的酷睿Ultra第1代处理器技术要点介绍里,Intel就明确突出了这代PC处理器在SoC tile部分搭载了NPU单元,用于AI本地推理加速。这算是相当符合潮流的设定吧,一方面在于主流PC处理器供应商普遍开始这么做,另一方面则是今年Intel正在宣导对于端侧设备而言,AI技术的重大价值。

XPU的一个组成部分
其实有关Meteor Lake跑AI的消息,最初是在今年年中就做了预告的。不过当时Intel提的是CPU、GPU、VPU。而且早在Raptor Lake(13代酷睿)时期,Movidius VPU也作为独立芯片,成为13代酷睿笔记本的可选项。
Intel Innovation(英特尔on技术创新大会)前夕的媒体分享会上,Intel提及的这枚NPU可能就是此前所说的VPU。原因很简单。Intel在分享会上,再度提到了用Meteor Lake跑Stable Diffusion的例子,用以体现当前Intel XPU的实践。

这个过程是这样的:Stable Diffusion本身的网络结构分成了几个部分,前端是个文本编码器——文生图首先要输入prompt提示词,例如“带着粉色蝴蝶结的可爱小猫”,则提示文字首先要通过CLIP模型转换到“一个隐藏空间”。
第二步则有两个Unet参与。Intel解释说:“Unet网络结构一个做正向提示词,一个做负向提示词,完成所谓扩散的步骤。这个步骤是比较重载的,在Stable Diffusion的整个处理流程中,是计算量较高的步骤。”“重复大概20步,就能得到质量还不错的图。”
最后一步“还是在隐藏空间,通过图像编码器VAE,还原到像素空间,成为输出的图像”。
这样一套流程,如果都跑在CPU上,Unet+/-迭代20次,大约需要43秒,功耗40W——设定此能效值为单位1。而如果改由GPU来跑,耗时仅需14.5秒,功耗37W。

若将Unet+/-都跑在NPU上(猜测GPU可能参与了编码器工作),则全流程需要20.7秒——虽然速度相比完全由GPU来跑稍慢,但功耗仅10W,能效达成了7.8倍。另外若考虑让GPU跑Unet+,NPU跑Unet-,流程耗时更短,但能效会不及第三种方案。
这个例子Intel前几个月就提过,调度工作由OpenVINO完成,实现在不同处理器上的深度学习部署。可见Meteor Lake上的NPU有可能就是此前宣传中的VPU了。
基于Intel此前一直在宣导XPU的策略,就端侧AI推理这一特性,Intel对于CPU、GPU和NPU的定位分别是下面这样的:

在Intel看来,做AI推理这活儿,三颗U都得参与:要么分工合作,要么选出最适合自己的工作。上个月我们才刚刚报道过,就生成式AI生态构建上,Intel为让CPU去跑生成式AI在做的各种工作。
GPU适合高并发、高吞吐需求的AI工作;顺带给一张GPU支持DP4a指令,每个周期执行64次Int8运算的介绍图(下图)。从Meteor Lake关键技术一文介绍里,应该能预设Meteor Lake核显的AI性能——毕竟这次的矢量引擎相比上一代还是增加了不少的。

而NPU是个低功耗的AI引擎,用于持续性的AI负载,比如说视频会议时,需求AI实现眼神矫正、画面超分或语音降噪之类的工作,则NPU更合适;CPU的特点是响应快,则对于轻量级、低延迟需求的推理工作,就很适用。
有关NPU架构
这次媒体分享会上,Intel还是比较罕见地给出了NPU架构的,只是不知道具体规模如何。NPU首先位于SoC tile之上。既然SoC tile又被Intel称作低功耗岛,那么这片区块的设计必然是冲着低功耗和高能效去的。

NPU这类加速器通常就包括MAC、精度转换之类。其算力主体部分由两个Neural Compute Engine(神经计算引擎)构成;这类专注于并行能力的加速器往往都能相对方便地做模块弹性缩放。

这两个引擎支持Int8, FP16运算,配有专门的data conversion数据转换单元,“支持量化网络的数据类型转换和融合操作”“支持输出数据的重新布局”;硬件层面“支持FP精度下的多种激活函数(avtiviation function)”,如ReLU。
MAC阵列用以支持矩阵乘法和卷积运算,“支持最佳数据重用,以降低功耗”,单个引擎算力2048 MAC/周期。每个引擎配一个DSP,用于更多精度数据的支持。
其余部分包括MMU访问系统内存、DMA直接内存读取、片内存储资源(Scrachpad RAM)。针对类似Resnet50网络达成卷积→ReLU→量化,是个AI加速的标准流程了。
就软件堆栈部分,比较值得一提的是Intel的NPU驱动符合微软MCDM框架(Microsoft Compute Device Manager)。则故此,从Windows的资源管理器里,就能直接看到NPU作为一个计算设备存在,包括其负载情况。
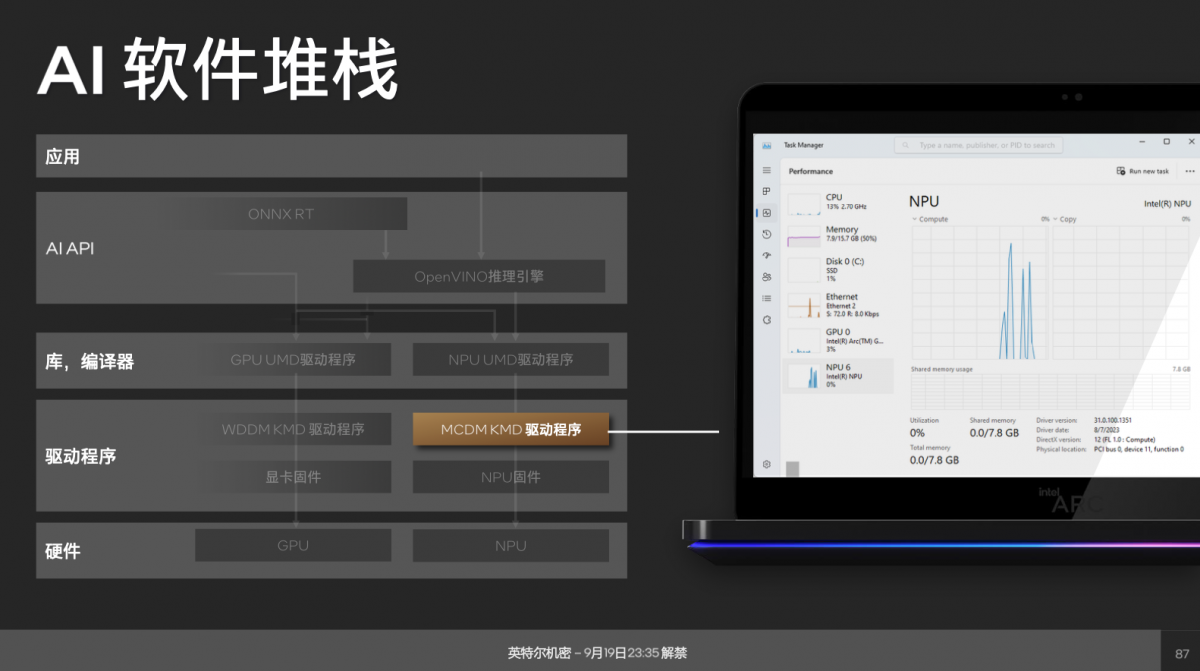
据说特别针对XPU的AI Benchmark基准测试工具已经在路上。未来的PC处理器也要开始卷AI推理能力了。
AI软件堆栈与PC上的实际应用
这里再花点篇幅谈谈Intel于端侧AI生态的软件堆栈。在Windows上做AI应用开发,可选的API算是比较多样,包括了微软的WinML,以及更低层级的DirectML;也可以选择开源的ONNX RT,还有Intel的OpenVINO。
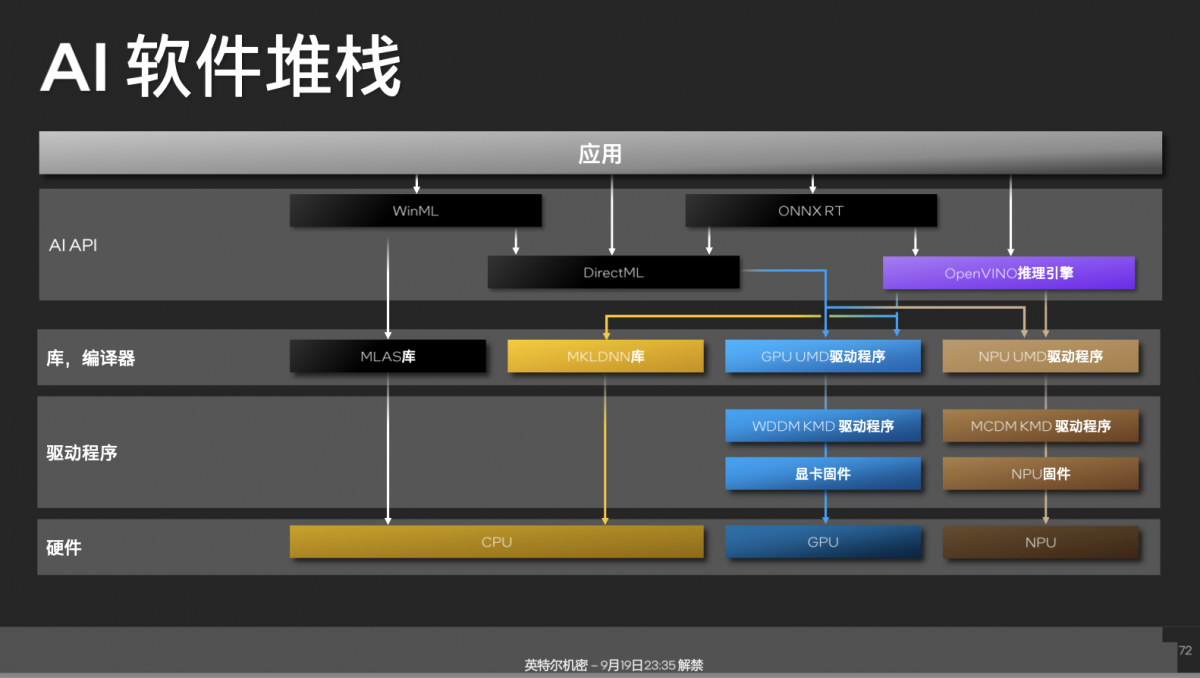
中间层相关的库,以及驱动程序层具体如图。谈个应用案例,Intel和微软合作,在偏上层应用层出了个Windows Studio Effects——相当于一个虚拟摄像头,对原始摄像头的视频做AI处理,可用于背景替换、模糊、人脸追踪等。Windows Studio Effects下层本身是基于OpenVINO的。
对于应用开发者而言,只需要调用Windows Studio Effects,就能直接获得这些效果。比如像微软的Teams就是直接调用Windows Studio Effects,那么这些AI特效实现就能跑在NPU上。其软件栈路径大致如下:
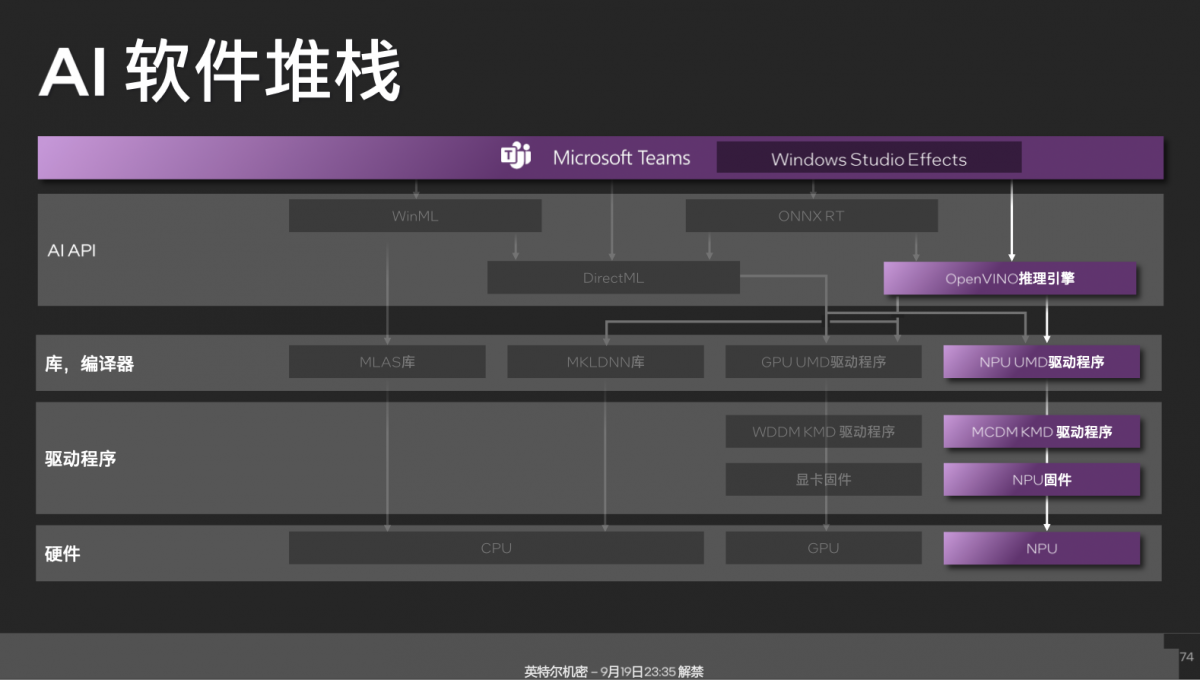
其他开发者,比如Adobe倾向于选择DirectML去做各种内容创作的AI实现。Intel说部分视频分析类、图像类应用开始大量基于OpenVINO去做了。上面这些,应该能够给到各位技术爱好者,或开发者以参考;这些也是构建AI生态的重要组成部分。
更多开发生态相关的构成,此前我们谈得也挺多了,这里就不再赘述了。但能看得出来,在Meteor Lake加入NPU以后,配合其他XPU,Intel是期望在端侧将AI技术真正实现普及的,即便这个生态的建设工作现在还算是早期。
“我们现在有超过100多家合作伙伴在做各种各样的终端侧AI应用,丰富PC用户的使用体验。”就CCG业务的生态,主要还是Intel和微软合作构建。
NPU已经支持的神经网络和应用包含如下这些:

“我们感觉终端侧AI目前的发展还是非常快的。我们借助于Meteor Lake引入XPU的能力,让产品能够更好地支撑起整个生态系统;让开发者将一些AI workload在PC端引入,提升用户体验。”
感觉端侧NPU的应用命题并不易解,连苹果做了这么久的NPU,Mac端的AI生态也相当得不丰满。不过Intel这次考虑构建的AI生态是走开放开源路线的,目前等待的大概是开发者真正能够基于酷睿处理器资源所做的爆款,并令其足够成为PC用户的刚需了。
