
人工智能(AI)应用通常是利用服务器群或昂贵的现场可编程门阵列(FPGA)来实现,从而需要大量的能耗。而该领域面临的挑战是,在不断增加算力的同时,还要求保持低功耗和低成本。如今,强大的智能边缘计算,使AI应用发生了戏剧性转变。
与传统基于固件的计算相比,基于硬件的卷积神经网络,正以令人印象深刻的速度和能力,迎来计算性能的新时代。新的智能边缘技术,通过赋能传感器节点自主决策,显著降低了对5G和Wi-Fi网络数据传输方面的需求。这为新兴技术和独特的应用提供了动力,而这些技术和应用在以前都是不可能实现的。例如,偏远位置的烟雾/火灾探测、在传感器端即可实现环境数据分析等。如今上述这些应用都已成为现实,而且这些设备都由电池进行常年供电。
带超低功耗卷积神经网络加速器的AI微控制器
MAX78000是一款带有超低功耗CNN加速器的AI微控制器,这是一款先进的系统级芯片。它为资源受限的边缘设备或物联网应用提供了超低功耗的神经网络。此类应用包括对象检测和分类、音频处理、声音分类、噪声消除、面部识别、心率/健康信号分析时序数据处理、多传感器分析和预测性维护等。

图1所示为MAX78000的原理框图。图中可见,该微控制器采用了带浮点单元的Arm®Cortex®-M4F内核,频率高达100MHz。为了给应用程序提供足够的内存资源,此版本的微控制器配有512kB的闪存和128kB的SRAM。它包括多个外部接口,如I²C、SPI和UART,以及对音频应用非常重要的I²S。此外,还有一个集成的60MHz RISC-V核。RISC-V通过把数据从独立的外围模块和存储器(闪存和SRAM)中复制出来,或者把数据复制进去,从而使其成为智能直接存储器访问(DMA)引擎。RISC-V核为AI加速器预处理传感器数据,故在此期间,Arm核可以处于深度睡眠模式。如有必要,推理结果可以通过中断触发Arm核,然后Arm CPU在主应用程序中执行操作,以无线方式传递传感器数据,或通知用户。
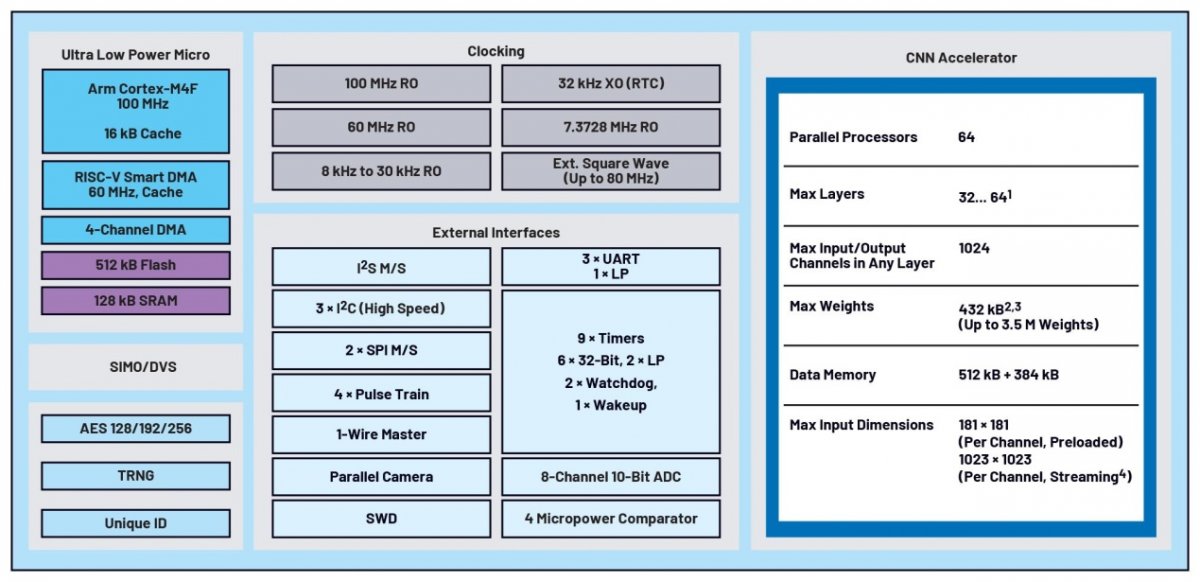
图1:MAX78000原理方框图。
MAX7800x系列微控制器的一个独特功能,是利用硬件加速器单元来执行卷积神经网络推理,这使其架构和外设与标准微控制器相比都有很大不同。该硬件加速器可以支持完整的CNN模型架构以及所有所需参数(权重和偏置)。CNN加速器配备了64个并行处理器和一个集成存储器(其中,442kB用于存储参数,896kB用于存储数据)。由于模型和参数存储在SRAM存储器中,因此可以利用固件对它们进行调整,并实时适配网络。根据模型中使用的权重是1、2、4还是8位,该内存最多可容纳350万个参数。因为存储器能力是加速器的一个组成部分,所以在每次连续的数学运算中,不必通过微控制器总线结构获取参数。由于这类活动延迟大且功耗高,故成本是很昂贵的。神经网络加速器可以支持32层或64层,具体取决于池函数。每层的可编程图像输入/输出最高可达1024×1024像素。
CNN硬件转换:能耗和推理速度比较
CNN推理是一项复杂的计算任务,因为其中含有矩阵形式的大型线性方程。利用Arm Cortex-M4F微控制器的强大功能,可以在嵌入式系统的固件上进行CNN推理。不过,此时也有一些缺点需要考虑到,那就是会消耗大量的能源和时间。这是因为,在微控制器上运行基于固件的推理时,由于需要从存储器中读取计算所需的命令以及相关的参数数据,然后才能写回中间结果。
表1所示为采用三种不同解决方案的CNN推理速度和能耗的比较。该示例模型是利用MNIST开发的。MNIST是一种手写数字识别训练集,它对视觉输入数据中的数字和字母进行分类,以获得准确的输出结果。对每种处理器类型所需的推理时间进行了测量,以确定各类型之间的能耗和速度差异。
表1:利用MNIST数据集进行手写数字识别的三种不同场景中的CNN单次推理时间和能耗
| 处理器类型及场景 | 推理速度(ms) | 单次推理能耗(µWs) |
| (1) MAX32630,固件MNIST | 574 | 22887 |
| (2) MAX78000,硬件MNIST | 1.42 | 20.7 |
| (3) MAX78000,针对低功耗优化过的硬件MNIST | 0.36 | 1.1 |
在第一个场景中,集成到MAX32630中的Arm Cortex-M4F处理器用于计算推理,该处理器主频为96MHz。在第二个场景中,为了处理计算,采用了MAX78000的硬件CNN加速器。当采用这种具有硬件加速器的微控制器时,推理时间(即在网络输入端呈现视觉数据与输出结果之间的时间差)降低了400倍,亦即推理速度提高了400倍。此外,每次推断所需的能耗要低1100倍。在第三个场景中,MNIST网络被优化至单次推理的能耗最小。在这种情况下,结果的准确性会略有下降(从99.6%下降到95.6%),但网络却要快得多,每次推理只需要0.36毫秒。每次推理的能耗降低到仅1.1µW。在采用两块AA碱性电池(总能量为6Wh)的应用中,推理次数可以达到500万次(电路其余部分消耗的功率可省略)。
这些数据说明了硬件加速计算的威力。对于无法利用连接或需要连续供电的应用来说,硬件加速计算是一种宝贵的工具。在无需大量能源、宽带互联网接入或延长推理时间的前提下,MAX78000实现了边缘处理。
MAX78000 AI微控制器用例示例
MAX78000支持多种潜在应用,这里以宠物门控制为例进行研究。
该用例要求设计一个电池供电的摄像头,自动检测猫何时回家,当猫出现在图像传感器的视野内之后,通过向猫门自动发送一个数字输出来打开猫门,让猫能够进入屋内。
图2描述了该用例的设计框图。在这种情况下,RISC-V核定期打开图像传感器,并将图像数据加载到由MAX78000供电的CNN中。如果识别为猫的概率高于先前定义的阈值,则启开猫门。等猫进来后,系统再次返回待机模式。
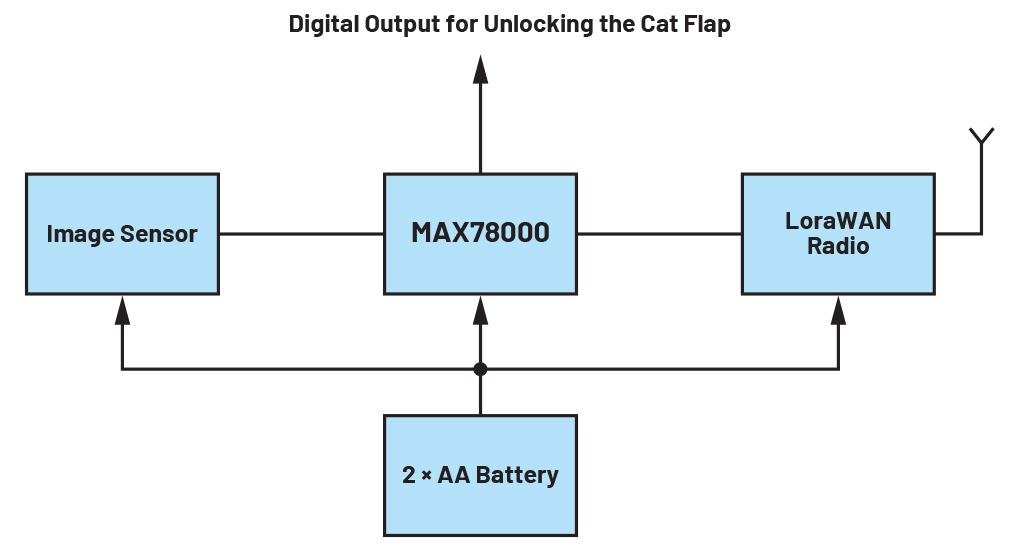
图2:智能宠物门设计方框图。
开发环境和评估套件
开发边缘应用的过程可分为以下几个阶段:
第1阶段:AI——网络定义、训练和量化;
第2阶段:Arm固件——将第1阶段生成的网络和参数植入到C/C++应用程序中,并创建和测试应用程序固件;
开发过程的第一部分涉及AI模型的建模、训练和评估。在这个阶段,开发人员可以利用PyTorch和TensorFlow等开源工具。GitHub存储库提供了全面的资源,可帮助用户来规划AI网络的构建和训练,在考量MAX78000硬件参数时,可利用PyTorch开发环境。存储库中包括一些简单的AI网络以及像面部识别(Face ID)这类的多种应用。
图3所示为PyTorch中典型的AI开发过程。首先,需要对网络进行建模。必须注意的是,并非所有MAX7800x微控制器都具有支持PyTorch环境中所有可用数据操作的硬件。因此,项目中必须首先包含ADI提供的ai8x.py文件。该文件包含采用MAX78000所需的PyTorch模块和运算符。基于这种设置,可以构建网络,然后是利用训练数据进行训练、评估和量化。该步骤的结果是检查点文件,该点文件检查包含用于最终合成过程的输入数据。在最后这一步中,网络及其参数被转换为适合硬件CNN加速器的形式。这里应该提到的是,网络训练可以利用任何PC(笔记本电脑、服务器等)来完成。然而,如果没有CUDA显卡的支持,即使是小型网络,这也可能需要大量时间,几天甚至几周都是完全可能的。
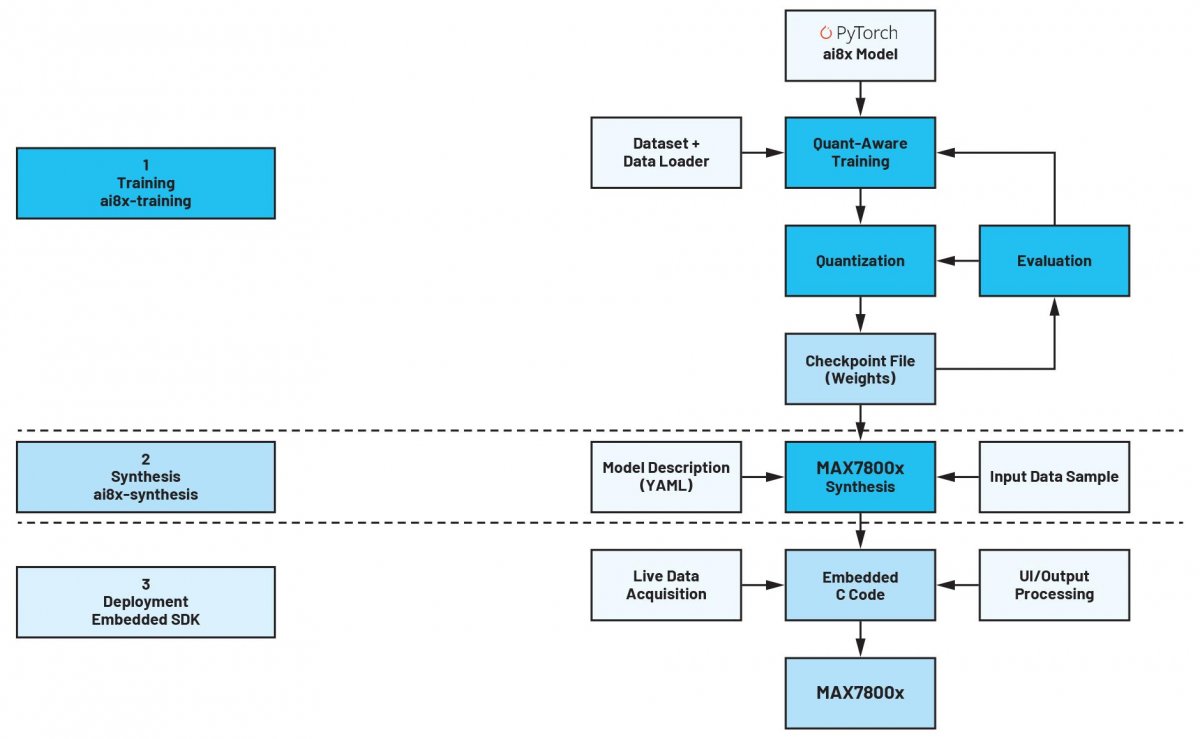
图3:AI开发流程示意图。
在开发过程的第2阶段,应用程序固件是通过将数据写入CNN加速器并读取结果的机制来创建的。通过#include指令,将第一阶段创建的文件集成到C/C++项目中。诸如Eclipse IDE和GNU工具链之类的开源工具,也用于微控制器的开发环境。ADI提供了一个软件开发工具包(Maxim Micros SDK(Windows))作为安装程序,其中已经包含了所有必要的组件和配置。为了简化应用程序的开发过程,该软件开发工具包还包含有各种外围驱动程序、多种示例以及说明。
一旦项目在没有任何错误的情况下被编译和链接,就可以在目标硬件上对其进行评估。ADI为此开发了两种不同的硬件评估平台。图4所示为MAX78000EVKIT。而图5所示则是一款外形稍小的feather评估板,型号为MAX78000FTHR。每块板上都配有一个VGA摄像头和一个麦克风。

图4:MAX78000评估套件。

图5:MAX78000FTHR评估套件。
结论
以前,AI应用需要消耗大量能源的服务器群或昂贵的FPGA阵列来实现。现在,有了带专用CNN加速器的MAX78000系列微控制器,就可以利用单节电池为AI应用长时间供电。这一能效和功耗技术方面的突破,使边缘AI比以往任何时候都更容易实现,并为新的、令人激动的边缘AI应用释放了潜力,而所有这些在以前都是无法想象的。
(参考原文:hardware-conversion-of-convolutional-neural-networks)
本文为《电子工程专辑》2023年10月刊杂志文章,版权所有,禁止转载。点击申请免费杂志订阅