
去年滴水湖中国RISC-V产业论坛期间,我们还在谈RISC-V应用于HPC高性能计算的可能性——当时论坛主要的RISC-V企业都聚焦于IoT、无线通信等嵌入式应用。
今年的第三届滴水湖中国RISC-V产业论坛,首秀就是Tenstorrent这家做绝对HPC方向的企业——就是那家Jim Keller担纲CEO、含着金汤匙出生的企业;主题演讲还有谈“64位多核服务器CPU”、“12TOPS边缘大算力AP级边缘SoC”等企业,通用计算部分都基于RISC-V。
我们在前不久的《2023年TOP50国产处理器厂商调研与市场分析报告》中也特别就RISC-V指令集对HPC应用的影响做了阐述,包括平头哥、Ventana、Tenstorrent等在内的企业都着眼于基于RISC-V的高性能计算。看起来RISC-V的HPC应用走得顺风顺水。
这与chiplet、先进封装、异构集成作为当前芯片发展的主流,需求绝对的灵活性,而RISC-V以开源和灵活性著称有很大的关系。

Tenstorrent首席CPU架构师练维汉在滴水湖论坛上说,Tenstorrent选择RISC-V就是因为RISC-V本身是开源、可定制,可“产生特定指令集,为应用场景做定制”的,“很多东西不需要考虑法律纠纷,就可以做出想做的改动”,像Arm这样的架构“限制很多——需要问Arm我可不可以这样做,可不可以那样做”,“弹性”是RISC-V的关键优势。这是个参与了苹果A6、A7,甚至M1 CPU架构设计的技术大牛。
这次我们也在论坛现场特别采访了练维汉,关注电子工程专辑微信视频号查看采访视频。基于Tenstorrent就RISC-V CPU和AI芯片的发展思路,我们来尝试看看RISC-V于HPC领域未来可能的发展思路。
“计算要在每个地方发生”
从晶体管诞生开始,大规模集成电路随摩尔定律发展等不同标志性事件的推进,练维汉将这个数字化转型的过程剖成了两条路径,分别是personal computation个人计算,和personal connectivity个人连接:

个人计算涵盖PC的诞生、智能手机的普及、CNN模型爆发,以及当代的ChatGPT大火;个人连接部分则伴随3G、4G、5G的一路发展。“两个东西撞到一起”,产生大量数据、传输大量数据,要求计算大量数据。海量数据产生,就要求海量的算力。
尤其到如今及可预见的近未来,AI时代的到来,要求AI模型做个人计算的个性化或定制化(personalization)。“包括医疗、教育,都要求为个人量身定做。”练维汉说,“这在以前是不可能的,因为并没有这种规模的算力。”
就全社会数字化转型带来的数据量,练维汉给了不少数据,比如说GPT-4达到万亿级别的参数量,比如现在每天产生的数据量已经达成了2.5 x 10^18字节。“有个数据是这样的,如果要把谷歌所有的search inquiry(搜索查询)转为ChatGPT的inquiry结果,需要耗费1000亿美金,电力要增加20倍。”
“如何解决现在的算力问题?可能真的解决不了。除非有fundamental theory(基础理论)的转变,才有可能解决我们面临的海量数据所需的算力问题。”Tenstorrent提出的方案是“compute everywhere”或者说“计算必须在每个地方发生”。
说白了,就是AI驱动的数字化转型大趋势下,计算绝不是只在数据中心位置发生的,要求高能效地解决海量数据算力需求,就需要调用端侧、网络、边缘、服务器等各个位置的算力。“就像有东西接触到皮肤,不可能把所有相关数据都传输给大脑,知觉的部分问题是经过皮肤本地计算的,有用的部分才传给大脑。”
所以需要这样的芯片
在Tenstorrent看来,达成高效的compute everywhere的基础有三点:(1)专用计算提升算力和效率,这一点也某种程度包含了异构,包括通用计算能力;(2)Scalability——架构的可扩展性,或者叫可伸缩性,同时是基于统一架构的扩展和伸缩,“从最简单到最复杂的东西,我们希望一个架构用到所有的应用上”;
(3)“不能太复杂,用最简单的东西去解决同样的问题”,“我们寻求的最终解决方案始终是最精简的”,这应该也是达成scalibility的组成部分。
而满足上述条件的选择,当前最佳大概就是RISC-V指令集。RISC-V的灵活性,是让Tenstorrent施展拳脚,得以基于简化的设计理念、统一架构实现弹性化扩展缩放,并践行异构和专用计算的基础。“当计算非常复杂、多样化(diverse)时,就需要指令集的这些考量。”练维汉说。
这几个理念也是当代加速芯片普遍追求的——比如近一年的Imagination技术研讨会,Imagination就反复在强调采用相对松散、去中心化的结构,统一架构覆盖从手机到数据中心的不同应用。我们前两个月曾特别撰文介绍过Tenstorrent的AI芯片产品,他们的产品基本就是在践行这套理念——尤其近两代产品及未来路线图。
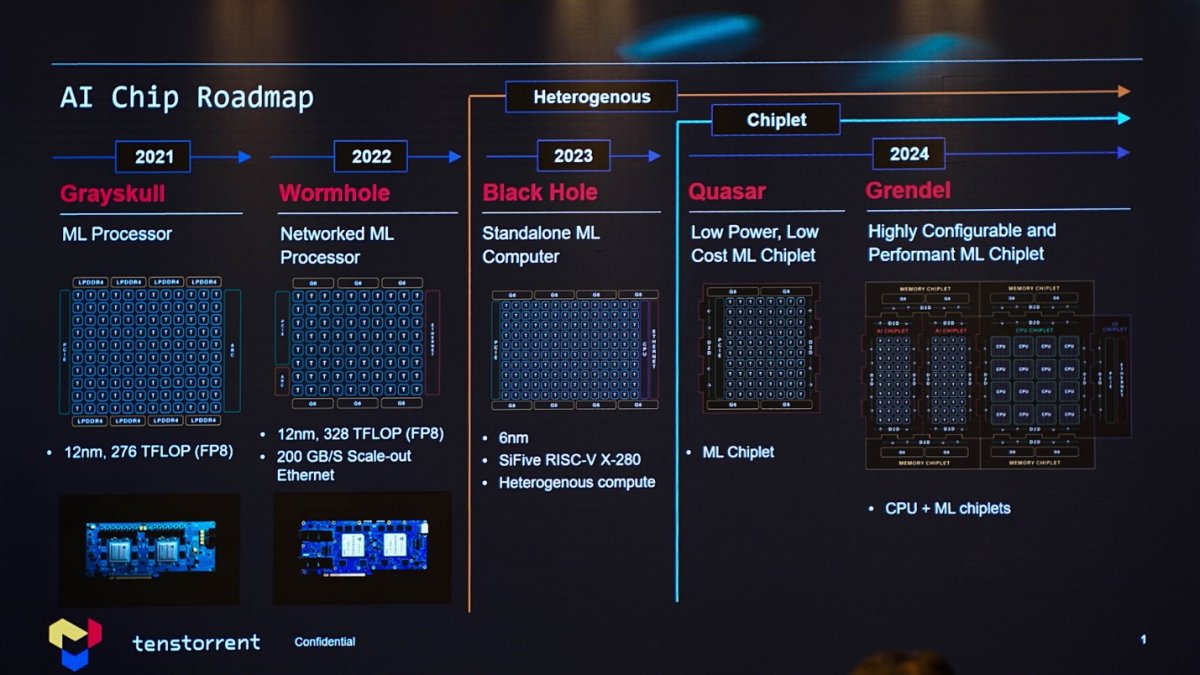
这家公司所推的AI芯片路线图上,从2021年相对纯粹的AI处理器Grayskull;到主要新增以太网口的Wormhole;今年的Black Hole则为芯片新增了companion CPU——初版CPU IP的选择是SiFive X280;但Tenstorrent认为SiFive的方案算力还不够,所以在后续AI芯片产品上选择了自研CPU架构,核心代号Ascalon;再往后,随规模持续扩大势必就要用上chiplet方案了。
所以现在的Tenstorrent公司内部技术团队,1/3的人在做CPU,2/3的人在做AI加速器,练维汉带领的就是CPU团队。“我们公司很特别,Tenstorrent是全球唯一一个既有高性能RISC-V CPU,又有AI机器学习处理器的企业。”其实在去年的RISC-V Summit峰会上,练维汉就提到过CPU在AI计算中扮演着“非常非常重要的角色,尤其在训练方面”。这是CPU也成为Tenstorrent产品布局中重要一环的原因。
AI加速器的可扩展
练维汉提及达成compute everywhere的基础涵盖了三个要素,在我们看来其中的scalability是贯穿了全篇的。既然Tenstorrent的AI芯片既有AI加速器部分,也有CPU部分,那么两者的scalability都很重要。首先是AI加速器部分的可扩展、可伸缩性。
一般强调并行计算的加速器,可扩展实现是现在行业的主流——通常是相同运算单元或核心的加减,来达成算力的弹性缩放——当然其中还涉及互联、一致性等问题。这次练维汉特别谈到了AI加速单元Tensix核心内部结构,在下图中标识为“T”。

比较值得一提的是,初代Grayskull的Tensix核心,内部就有5颗小型的RISC-V处理器:其中两颗是NoC传输和接收,三颗控制核心部分的矩阵与矢量引擎。练维汉说这样一个Tensix核心就是个可扩展的computation element,“甚至小到仅1个processing element也可以function。”
从Tensix IP,到构成chiplet/die,到chiplet构成的系统(system chiplet),最后到服务器节点,都是在体现scalability的特点。

Tenstorrent的这一代Wormhole组成的Nebula以机架系统的4U尺寸存在——板卡层面(N300s/d)可选单芯或双芯方案,板卡以backplane互联;Nebula服务器至多达成32个system chiplet,总共12 PetaFLOPS(BF8)理论算力,6kW功耗。
另外需要提到的是,对应的软件栈也是可扩展的,支持大部分ML框架之类的就不谈了,相同的compiler面向上述的“一个computation element到几万个element”。则Tenstorrent的整体解决方案从低功耗设备,覆盖到数据中心。这是体现弹性可扩展的核心所在。
RISC-V CPU的可扩展
其次就是RISC-V CPU部分的scalability了。有关Ascalon核心设计,我们已经在此前的文章里分享过——这是个基于RISC-V指令集、乱序执行超标量CPU。要说宣传中的前端8-wide宽度(似具体代号为RVA-23),必然是着力于服务器高性能市场的。

之所以如此强调CPU,除了前文提到的CPU对AI计算的重要性,还在于在Tenstorrent看来,维系处理器必要的通用性是一定需要纳入考量的。“AI改变非常快。今年我们说transformers很牛,5年后可能就不一定了。”练维汉强调,“AI computation不能只为现在这一代去做,架构需要有足够的弹性去应付未来所有AI model的需求。”
实际上,根据decode解码宽度,Tenstorrent总共准备了5种不同的CPU微架构,从2-wide到最高性能的8-wide Ascalon。从下面的示意图也不难发现,不同规模的微架构设计达成不同的PPA目标,面向不同的应用。

去年我们质疑过,Tenstorrent并非纯粹的IP企业(虽然似乎Tenstorrent也有IP授权业务),同代产品就做这么多IP会不会增加研发投入。这可能和Tenstorrent更具体的业务模式有很大的关系;不过另一方面,从具体的应用示例来看,这样的设定可能还真是需要的。因为Tenstorrent以统一架构、可扩展性覆盖全场景。
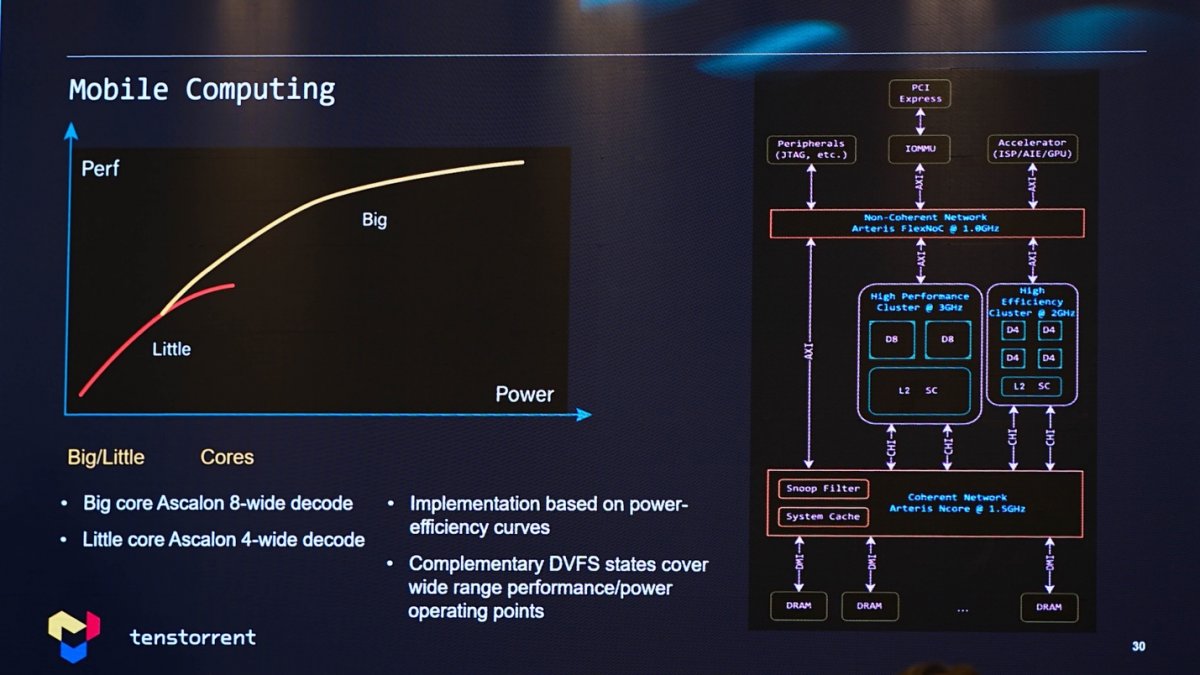
练维汉提到了潜在的移动计算应用场景,也就是手机一类的应用,可布局CPU的大小核异构设计,大核采用8-wide decode方案,而小核选择4-wide decode方案,以实现不同性能与功耗区间的不同曲线和能效。虽然在我们看来,Tenstorrent要进驻移动计算市场会有相当大的难度,但这应当是Tenstorrent以架构设计的scalability覆盖不同应用的体现。
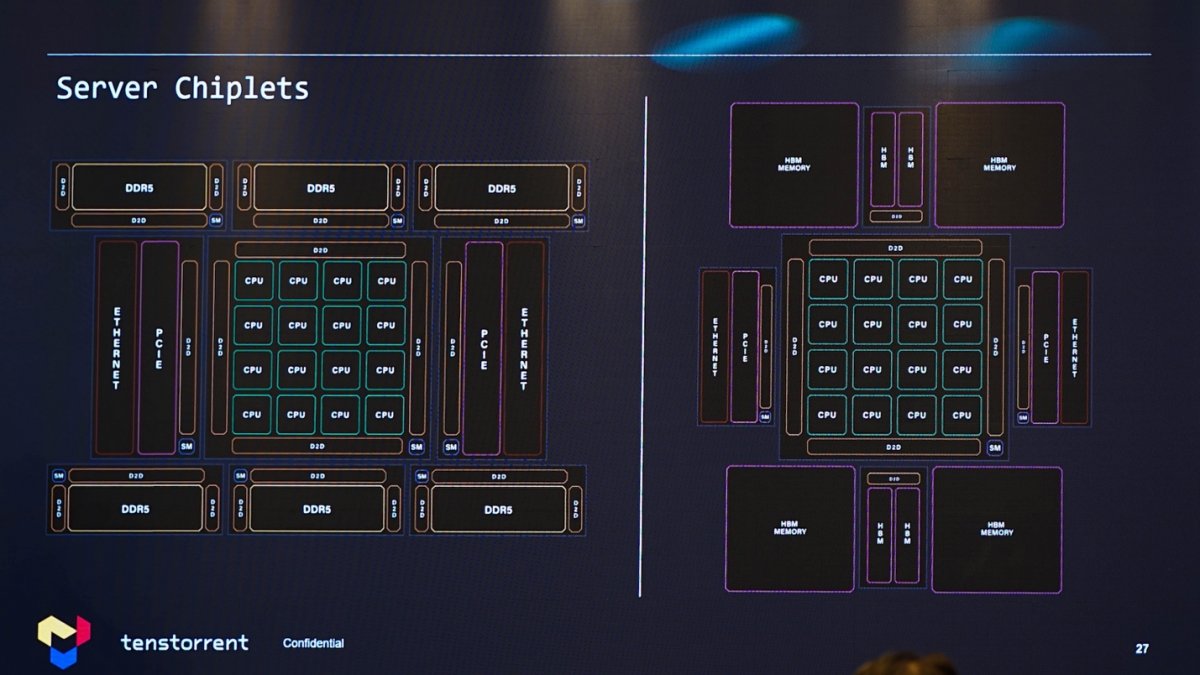
CPU真正的弹性缩放设计,体现在AEGIS chiplet系统架构,基于核心集群构成128个核心的设计。如下图所示,整个系统切分成了4块,每一块都是cc-NUMA结构32个核心。“chiplet本身就是scalable的。”

基于chiplet构成的服务器CPU方案,以及加上AI加速器以后,结构如下:

练维汉用物理学寻求的大一统理论来类比当代数字化转型所需求的统一架构,以及基于统一架构的弹性缩放,用不同算力来覆盖各类场景。统一架构对于端到端的生态发展而言,是个相当优雅的方案——即便到目前为止,半导体行业应当也并不存在任何层级的市场参与者做到自上而下、真正的统一架构。
不过据说需求这种思路的企业相当多,从客户端到服务器,从networking到视频服务器,从可穿戴设备到车载应用。“我们就能够满足这样的需求,这是我们的优势。”
“最初的工业革命是用机器去替代人的体力劳动,而这一次革命是机器替代人的脑力劳动。”这是在Tenstorrent看来,时代赋予的发展机会。“巨量的数据,巨量的连接,对未来计算提出了compute everywhere的需求,寻找scalablity的、统一的架构。”
练维汉谈到,“我觉得现在人类站在了历史风口上,数字正在改变世界,AI正在带来个性化,不管医疗、教育还是其他应用,都能为个人量身定做。”我们可以等等看Tenstorrent这种理想而优雅的AI哲学是否真的适用。

